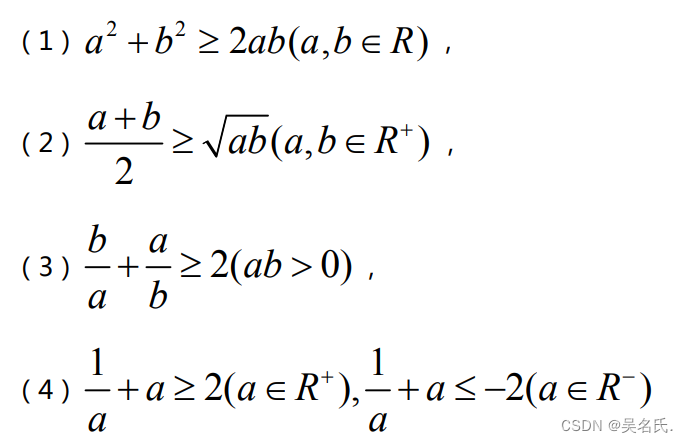前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了机器学习的基本任务、机器学习的一般流程,以及针对过拟合问题的解决方法,包括权重正则化、dropout 正则化、批量归一化、层归一化、权重初始化等。
一、机器学习的基本任务
机器学习的基本任务通常分为 4 大类:监督学习、无监督学习、半监督学习和强化学习。
| 机器学习的基本任务 | 定义、任务、场景 |
|---|---|
| 监督学习 | 定义:使用已知正确答案的示例来训练模型。 任务:分类、回归、目标检测、识别。 场景:根据已有数据,分类或预测新数据。 |
| 无监督学习 | 定义:在无标签的数据集中查找规则的模型。 任务:聚类、降维。 场景:从部分人的身体测量值中算出 XS、S、M、L 和 XL 号衬衫尺码。 |
| 半监督学习 | 定义:结合分类与聚类的思想生成新模型。 任务:自编码、推荐、生成式对抗。 场景:根据已有数据,分类或预测新数据。 |
| 强化学习 | 定义:对没有标注的数据集,根据是否更接近目标来构建模型。 任务:分类、回归。 场景:类似经典的儿童游戏 —— “ hotter or colder ”。 |
1、监督学习
监督学习的特点:给定学习目标,这个学习目标又称为标签、标注或实际值,整个学习过程围绕 如何使预测与目标更接近 而展开。
近年来,随着深度学习的发展,除传统的二分类、多分类、多标签分类外,分类出现了 目标检测、目标识别、图像分割 等新内容。
监督学习的输入数据中有标签或目标值,但在实际生活中,有很多数据是没有标签的,或者标签代价很高。
2、无监督学习
没有标签的数据也可能包含很重要的规则或信息,而从这类数据中学习到一个规则或规律的过程称为 无监督学习 。
在无监督学习中,我们通过推断输入数据中的结构来建模,模型包括 关联学习、降维、聚类 等。
3、半监督学习
半监督学习 是监督学习与无监督学习相结合的一种学习方法,它使用大量的未标记数据,同时由部分标记数据进行模式识别。
1. 自编码器是一种半监督学习,其生成的目标就是未经修改的输入。
2. 语言处理中根据给定文本中词预测下一个词,也是半监督学习的示例。
3. 生成式对抗网络也属于半监督学习,即给定一些真图像或语音,通过生成式对抗网络生成与真图像或语音逼真的图像或语音。
4、强化学习
强化学习 主要包含 4 个元素:智能体 Agent 、环境状态、行动、奖励。强化学习的目标是获得最多的累计奖励。强化学习把学习看作试探评价过程,智能体 Agent 选择一个动作作用于环境,环境在接收该动作后使状态发生变化,同时产生 强化信号(奖或惩)反馈给智能体,再由智能体根据强化信号和环境的当前状态选择下一个动作,选择的原则是使智能体受到正强化(奖)的概率增大。选择的动作不仅影响到当前的强化值,也影响下一时刻的状态和最终的强化值。
强化学习不同于监督学习,主要表现在 教师信号 上。强化学习中由环境提供的强化信号是智能体对所产生动作的好坏的一种评价,而不是告诉智能体如何去产生正确的动作。由于外部环境提供的信息较少,智能体必须靠自身的经历进行学习。通过这种方式,智能体在行动-评价的环境中获得知识,并改进行动方案以适应环境。
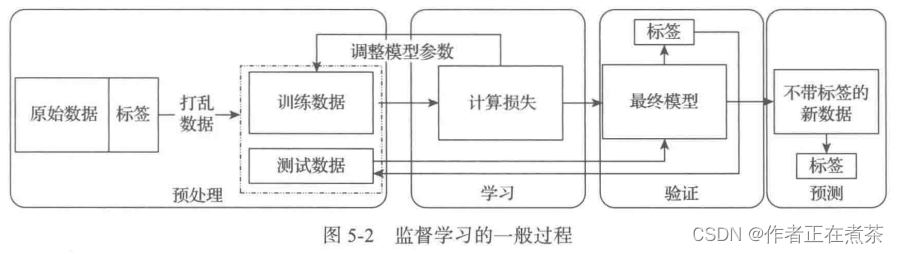
二、机器学习的一般流程
机器学习的流程:明确目标、收集数据、输入数据、数据探索与预处理,然后开始构建模型、训练模型、评估模型、优化模型等。

1、明确目标
明确目标,首先需要明确大方向,比如当前需求是分类问题、预测问题还是聚类问题等。清楚大方向后,需要进一步明确目标的具体含义。如果是分类问题,还需要区分是二分类、多分类还是多标签分类;如果是预测问题,要区别是标量预测还是向量预测;其他方法类似。确定问题,明确目标有助于选择模型架构、损失函数及评估方法等。
当然,明确目标还包含了解目标的 可行性 ,因为并不是所有问题都可以通过机器学习来解决。
2、收集数据
目标明确后,接下来就是收集数据。为了解决这个问题,需要哪些数据?数据是否充分?哪些数据能获取?哪些无法获取?这些数据是否包含我们学习的一些规则等等,都需要全面把握。数据可能涉及不同平台、不同系统、不同部分、不同形式等,对这些问题的了解有助于确定具体数据收集方案、实施步骤等。能收集的数据尽量实现 自动化 、程序化 。
3、数据探索与预处理
收集到的数据不一定规范和完整,这就需要对数据进行初步分析或探索,然后根据探索结果与问题目标,确定数据预处理方案。
数据探索 包括了解数据的大致结构、数据量、各特征的统计信息、整个数据质量情况、数据的分布情况等。为了更好体现数据分布情况,数据可视化是一个不错方法。通过数据探索后,可能会发现不少问题,如存在缺失数据、数据不规范、数据分布不均衡、奇异数据、很多非数值数据、很多无关或不重要的数据等。这些问题直接影响数据质量,所以数据预处理应该是接下来的重点工作。
数据预处理 是机器学习过程中必不可少的重要步骤,特别是在生产环境的机器学习中,数据往往是原始、未加工和处理过的,因此数据预处理常常占据整个机器学习过程的大部分时间。其过程通常包括数据清理、数据转换、规范数据、特征选择等工作。
4、选择模型及损失函数
数据准备好以后,需要根据目标选择模型。可以先用简单或熟悉的方法来选择模型,开发一个原型或比基准更好一点的模型。这个简单模型有助于你快速了解整个项目的主要内容。
- 了解整个项目的可行性、关键点
- 了解数据质量、数据是否充分等
- 为开发一个更好的模型奠定基础
在选择模型时,不存在某种对任何情况都表现很好的算法(这种现象又称为没有免费的午餐)。因此在实际选择时,一般会选用几种不同的方法来训练模型,然后比较它们的性能,并从中选择最优的那个。选择好模型后,还需要考虑以下几个关键点:
- 最后一层是否需要添加 softmax 或 sigmoid 激活层
- 选择合适的损失函数
- 选择合适的优化器
表 5-1 列出了常见问题类型的最后一层激活函数和损失函数的对应关系,仅供大家参考。

5、评估及优化模型
模型确定后,还需要确定评估模型性能的方法,即 评估方法 。评估方法大致有以下三种:
留出法:留出法的步骤相对简单,直接将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个作为测试集。在训练集上训练出模型后,用测试集来评估测试误差,作为泛化误差的估计。还可以把数据分成三部分:训练数据集、验证数据集、测试数据集。训练数据集用来训练模型,验证数据集用来调优超参数,测试集用来测试模型的泛化能力。数据量较大时可采用这种方法。
k 折交叉验证:不重复地随机将训练数据集划分为 k 个,其中 k-1 个用于模型训练,剩余的一个用于测试。
重复的 k 折交叉验证:当数据量比较小、数据分布不很均匀时可以采用这种方法。
使用训练数据构建模型后,通常使用测试数据对模型进行测试,测试模型对新数据的测试效果。如果对模型的测试结果满意,就可以用此模型对以后的数据进行预测;如果测试结果不满意,可以优化模型。优化的方法很多,其中 网格搜索参数 是一种有效方法,当然我们也可以采用 手工调节参数 等方法。如果出现过拟合,尤其是回归类问题,可以考虑 正则化方法 来降低模型的泛化误差。
三、过拟合与欠拟合
在训练模型时,会出现随着训练迭代次数增加或模型不断优化,训练精度或损失值持续改善,测试精度或损失值不降反升的情况。
出现这种情况时,说明优化过度,将训练数据中无关紧要甚至错误的模式也学到了,这就是我们常说的 过拟合问题 。

1、权重正则化
正则化方法是解决过拟合问题的有效方法,不仅可以有效降低高方差,还可以降低偏差。
何为正则化?在机器学习中,很多被显式地减少测试误差的策略统称为正则化。正则化旨在减少泛化误差而不是训练误差。
正则化如何解决模型的过拟合问题?主要是通过正则化使参数变小甚至趋于原点。

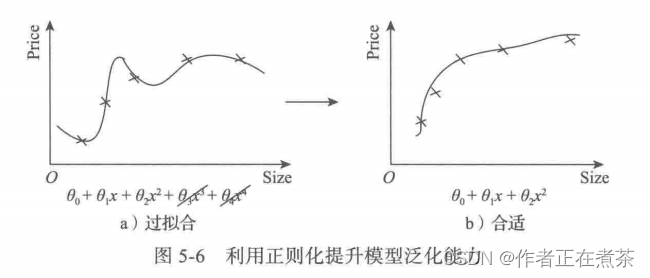
图 5-5 是根据房屋面积 Size 预测房价 Price 的回归模型。其中 c 将噪声数据包括进来了,导致模型很复杂。
如果要降低模型的复杂度,可以通过缩减它们的系数来实现,如把 3 次项、4 次项的系数缩减到接近于 0 即可。
在算法中如何实现呢?这个得从其损失函数或目标函数着手。假设房价 Price 与房屋面积 Size 的回归模型的损失函数为:

这个损失函数是我们的优化目标,我们需要尽量减少损失函数的均方误差。我们对这个函数添加一些正则项,得到如下函数:

这里取 10 000 只是用来代表它是 “ 大值 ” 。现在,如果要最小化这个新的损失函数,就要让 和
尽可能小,接近于 0 。
传统意义上的正则化通常分为 L0 、L1 、L2 、L∞ 等。PyTorch 是如何实现正则化的呢?这里以实现 L2 为例。神经网络的 L2 正则化称为 Weight Decay 权重衰减,torch.optim 集成了很多优化器,如 SGD 、Adadelta 、Adam 、AdaGrad 、RMSprop 等,这些优化器自带参数 weight_decay ,用于指定权值衰减率,相当于 L2 正则化中的 λ 参数。
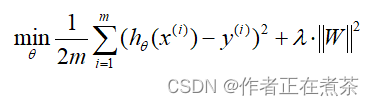
2、dropout 正则化
dropout 是 Srivastava 等人在 2014 年的论文 "Dropout: A Simple Way to Prevent Neural Networks from Overfitting" 中提出的一种针对神经网络模型的正则化方法。那么 dropout 正则化在训练模型中是如何实现的呢?dropout 的做法是在训练过程中按比例随机忽略或屏蔽一些神经元,比例参数可设置。这些神经元被随机 “ 抛弃 ” ,也就是说它们在正向传播过程中对于下游神经元的贡献效果暂时消失,在反向传播时该神经元也不会有任何权重的更新。因此,通过传播过程,dropout 将产生与 L2 范数相同的收缩权重的效果。
随着神经网络模型的不断学习,神经元的权值会与整个网络的上下文相匹配。神经元的权重针对某些特征进行调优,会产生一些特殊化。周围的神经元则会依赖于这种特殊化,如果过于特殊化,模型会因为对训练数据过拟合而变得脆弱不堪。神经元在训练过程中的这种依赖于上下文的现象被称为 复杂的协同适应(Complex Co-Adaptation)。加入了 dropout 以后,输入特征都有可能会被随机清除,所以该神经元不会再特别依赖于任何一个输入特征,也就是说不会给任何一个输入设置太大的权重。网络模型对神经元特定的权重不那么敏感,这反过来又提升了模型的泛化能力,不容易对训练数据过拟合。

dropout 训练所有子网络组成的集合,其中子网络是从基本网络中删除非输出单元构成的。我们从具有两个可见单元和两个隐藏单元的基本网络开始,这 4 个单元有 16 个可能的子集,如图 5-7 的 b 所示,从原始网络中丢弃不同的单元子集而形成的所有 16 个子网络。在这个示例中,所得到的大部分网络没有输入单元或没有从输入连接到输出的路径。当层较宽时,丢弃所有从输入到输出的可能路径的概率会变小,所以,这个问题对于层较宽的网络不是很重要。
较先进的神经网络一般包括一系列仿射变换和非线性变换,我们可以 将一些单元的输出乘零 ,从而有效地删除一些单元。这个过程需要对模型进行一些修改,如径向基函数网络、单元的状态和参考值之间存在一定区别。简单起见,在这里提出乘零的简单 dropout 算法,被简单地修改后,可以与其他操作一起工作。
dropout 在训练阶段和测试阶段是不同的,通常在训练中使用,而不在测试中使用。不过测试时没有神经元被丢弃,此时有更多的单元被激活,为平衡起见,一般将输出按丢弃率 dropout rate 比例缩小。如何或何时使用 dropout 呢?以下是一般原则:
1. 通常丢弃率控制在 20%~50% 比较好,可以从 20% 开始尝试。若比例太低则可能没效果,比例太高则可能导致模型欠拟合。
2. 在较大的网络模型上应用时,更有可能得到更好的效果,且模型有更多的机会学习到多种独立的表征。
3. 在输入层和隐含层都使用 dropout 。对于不同的层,设置的 keep_prob 也不同:对于神经元较少的层,将 keep_prob 设为 1.0 或接近于 1.0 的数;对于神经元多的层,则将 keep_prob 设为 0.5 或更小的数。
4. 增加学习速率和冲量。把学习速率扩大 10~100 倍,冲量值调高到 0.9~0.99 。
5. 限制网络模型的权重。较大的学习速率往往容易导致大权重值。对网络的权重值做最大范数的正则化,被证明能提升模型性能。
我们通过实例来比较使用 dropout 和不使用 dropout 对训练损失或测试损失的影响。数据还是房屋销售数据,构建网络层:
参考代码:GitHub: DL-with-Python-and-PyTorch/blob/master/pytorch-05/pytorch-05-01.ipynb
net1_overfitting = torch.nn.Sequential(torch.nn.Linear(13, 16),torch.nn.ReLU(),torch.nn.Linear(16, 32),torch.nn.ReLU(),torch.nn.Linear(32, 1),
)net1_dropped = torch.nn.Sequential(torch.nn.Linear(13, 16),torch.nn.Dropout(0.5), # drop 50% of the neurontorch.nn.ReLU(),torch.nn.Linear(16, 32),torch.nn.Dropout(0.5), # drop 50% of the neurontorch.nn.ReLU(),torch.nn.Linear(32, 1),
)# 获取测试集上不同损失值
writer.add_scalars('test_group_loss', {'origloss':orig_loss.item(), 'droploss':drop_loss.item()}, epoch)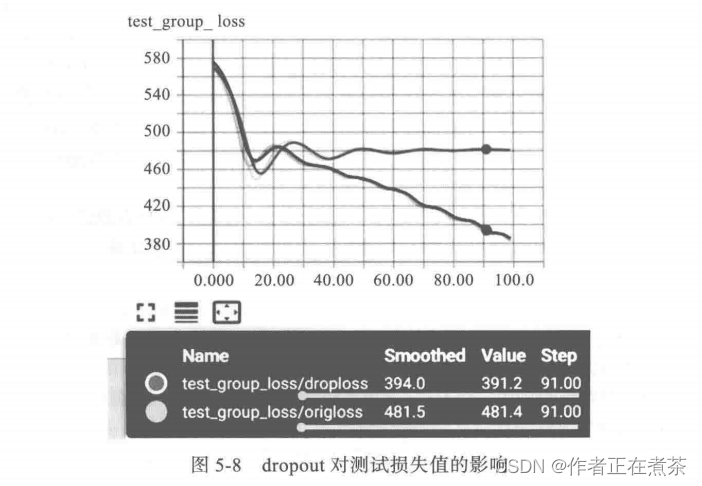
从图 5-8 可以看出,添加 dropout 层,对于提升模型的性能或泛化能力而言,效果还是比较明显的。
3、批量归一化
前面我们介绍了数据归一化,这通常是针对输入数据而言的。但在实际训练过程中,经常出现隐含层因数据分布不均,导致梯度消失或不起作用的情况。如采用 sigmoid 函数或 tanh 函数为激活函数时,如果数据分布在两侧,这些激活函数的导数就接近于 0 ,这样一来,BP 算法得到的梯度也就消失了。如何解决这个问题?
Sergey Ioffe 和 Christian Szegedy 两位学者提出了 批量归一化(Batch Normalization,BN)方法。批量归一化不仅可以有效解决梯度消失问题,还可以让调试超参数变得更加简单,在提高训练模型效率的同时,还可让神经网络模型更加 “ 健壮 ” 。批量归一化是如何做到这些的呢? 我们先来介绍批量归一化的算法流程:

批量归一化是对隐含层的标准化处理,它与输入的标准化处理是有区别的。标准化处理使所有输入的均值为 0 ,方差为 1 ,而批量归一化可使各隐含层输入的均值和方差为 任意值 。实际上,从激活函数的角度来说,如果各隐含层的输入均值在靠近 0 的区域,即处于激活函数的线性区域,将不利于训练好的非线性神经网络,而且得到的模型效果也不会太好。第 3 个公式就起到这个作用,当然它还有还原归一化后的 x 的功能。批量归一化通常作用在非线性映射前,即对 x=Wu+b 做规范化时,在每一个全连接和激励函数之间。何时使用批量归一化呢?一般在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时,可以尝试用批量归一化来解决。另外,在一般情况下,也可以加入批量归一化来加快训练速度,提高模型精度,还可以大大提高训练模型的效率。
批量归一化的具体功能列举如下:
- 可以选择比较大的初始学习率,让训练速度飙涨。以前需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始值很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然,即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性。
- 不用再去理会过拟合中 dropout 、L2 正则项参数的选择问题,采用批量归一化 BN 算法后,你可以移除这两项参数,或者可以选择更小的 L2 正则约束参数了,因为批量归一化 BN 具有提高网络泛化能力的特性。
- 再也不需要使用局部响应归一化层。
- 可以把训练数据彻底打乱。
依旧以房价预测为例,比较添加 BN 层与不添加 BN 层在测试集上的损失值。两种网络结构的代码如下:
net1_overfitting = torch.nn.Sequential(torch.nn.Linear(13, 16),torch.nn.ReLU(),torch.nn.Linear(16, 32),torch.nn.ReLU(),torch.nn.Linear(32, 1),
)net1_nb = torch.nn.Sequential(torch.nn.Linear(13, 16),nn.BatchNorm1d(num_features=16),torch.nn.ReLU(),torch.nn.Linear(16, 32),nn.BatchNorm1d(num_features=32), torch.nn.ReLU(),torch.nn.Linear(32, 1),
)writer.add_scalars('test_nb_loss',{'orig_loss':orig_loss.item(),'nb_loss':nb_loss.item()}, epoch)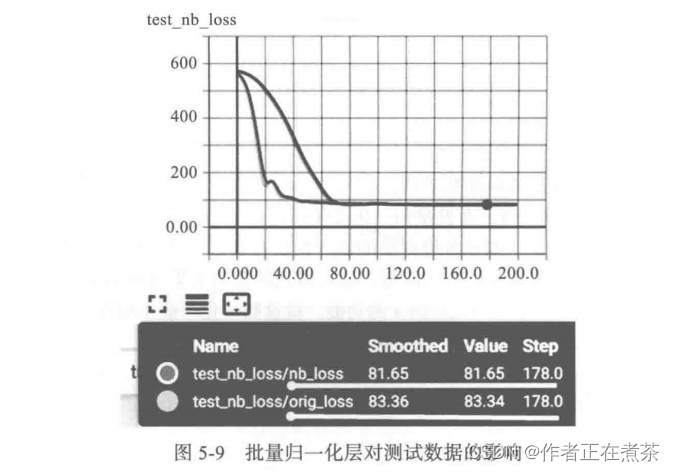
从图 5-9 可以看出,添加 BN 层对改善模型的泛化能力有一定帮助,不过没有 dropout 那么明显。这个神经网络比较简单,BN 在一些复杂网络中的效果会更好。BN 方法对 批量大小(batchsize)比较敏感,由于每次计算均值和方差是单个节点的一个批次上,所以如果批量太小,则计算的均值、方差不足以代表整个数据分布。BN 实际使用时需要计算并且保存某一层神经网络批次的均值和方差等统计信息,对于一个固定深度的正向神经网络,如 深度神经网络 DNN 、卷积神经网络 CNN ,使用 BN 很方便。但对于深度不固定的神经网络,如 循环神经网络 RNN ,BN 的计算很麻烦,且效果也不是很理想。此外,BN 算法对训练和测试两个阶段不一致,也会影响模型的泛化效果。对于不定长的神经网络,人们想到另一种方法,即 层归一化(Layer Normalization,LN)算法。
4、层归一化
层归一化对同一层的每个样本进行正则化,不依赖于其他数据,因此可以避免 BN 中受小批量数据分布影响的问题。不同的输入样本有不同的均值和方差,它比较适合于样本是不定长或网络深度不固定的场景,如 RNN、NLP 等方面。
批归一化 BN 是纵向计算,而层归一化 LN 是横向计算,另外 BN 是对单个节点(或特征)的一个批次进行计算,而 LN 是基于同一层不同节点(或不同特征)的一个样本进行计算。两者之间的区别可用图 5-10 直观表示。

5、权重初始化
深度学习为何要初始化?传统机器学习算法中很多不是采用迭代式优化方法,因此需要初始化的内容不多。但深度学习的算法一般采用迭代方法,而且参数多、层数也多,所以很多算法会在不同程度受到初始化的影响。
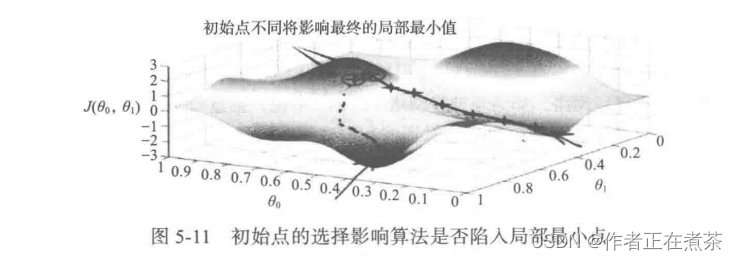
初始化对训练有哪些影响?初始化能决定算法是否收敛,如果初始值过大,可能会在正向传播或反向传播中产生爆炸的值;如果初始值太小,将导致丢失信息。对收敛的算法进行适当的初始化能加快收敛速度。初始点的选择将影响模型收敛是局部最小还是全局最小,如图 5-11 所示,因初始点的不同,导致收敛到不同的极值点。另外,初始化也可以影响模型的泛化。
如何对权重、偏移量进行初始化?初始化这些参数是否有一般性原则?常见的参数初始化方法有零值初始化、随机初始化、均匀分布初始化、正态分布初始化和正交分布初始化等。一般采用正态分布或均匀分布的初始值,实践表明,正态分布、正交分布、均匀分布的初始值能带来更好的效果。
继承 nn.Module 的模块参数都采取了较合理的初始化策略,通常使用其默认初始化策略就够了。当然,如果想修改,PyTorch 也提供了 nn.init 模块,该模块提供了常用的初始化策略,如 xavier、kaiming 等经典初始化策略,使用这些策略有利于激活值的分布,以呈现更有广度或更贴近正态分布。xavier 一般用于激活函数是 S 型的权重初始化,如 sigmoid 、tanh 等激活函数;kaiming 更适合激活函数为 ReLU 类的权重初始化。