(1)数据:
1):随机获取5帧参考帧
2):处理这5帧连续帧,:source_frames:连续5帧的crop_moth
b)audio_list:连续5帧的每一帧对应的5帧音频mel特征
c):refs:fintune 固定参考帧,为video.refs,给这连续5帧每一帧配固定的5帧参考帧。
video.refs 为整段视频的突出表情帧,ref_desc_list = [“闭嘴”, “张嘴”, “嘟嘴”, “半张嘴”, “张大嘴”]
ref_desc_list通过当前帧与ref_normal_landmarks作相似度,计算得来。
d): refs:pretrain 随机5帧参考帧
(2)网络:
N=5
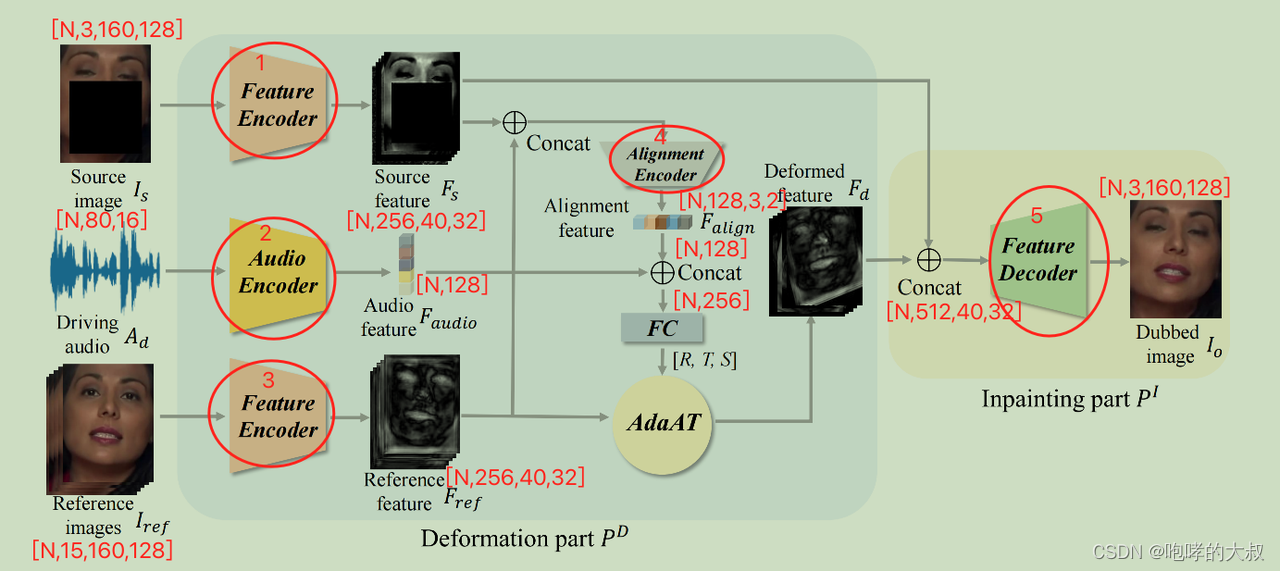
输入:1:source_img:torch.Size([N, 3, 160, 128])。 #一帧带预测嘴型的帧
2:ref_img:torch.Size([N, 15, 160, 128])。#随机参考帧
3:audio_feature:torch.Size([N, 80, 16])
输出:torch.Size([N, 3, 160, 128])
alignment encoder:将两种图片特征concat,在channel维度上拼接后,接到一个下采样16倍的小网络中,然后接一层全连接层,组成1*128维度的特征向量
adaat:空间变形,在人脸姿态检测里面有引用,在特征通道空间中进行仿射变换,【R,T,S】,实现错位图像生成,保证生成的嘴型姿态跟带预测嘴型帧的姿态一致。
(3)损失:
1)Perception loss;2)GAN loss. 3)Lip-sync loss.
分别对应图像特征判别器,音频特征判别器,和音唇同步模型。
输入:随机5帧参考帧reference image,随机一张待生成的mask后的原图source image,source image对应的音频
过程:1)将reference image 与source image均下采样4倍,分别得到[N,256,40,32]的特征图
2)将1)得到的2组特征图,融合对齐,得到特征图3.
3)音频提取的特征,与特征图3融合并进行仿射变换(以前在做人脸重建时会有用到),得到特征图4
4)对特征图4,进行decode,上采样4倍,得到生成的图片。
输出:fake_out
(4)后续loss:
- perceptionLoss
计算fake_out与fake_out原图做一个特征金字塔计算,然后送到vgg中,分别计算图像特征,最后两个特征张量做L1Loss
2)pixelLossL1
计算fake_out与fake_out原图线性插值缩放一定倍数后,做L1Loss
3)两个判别器loss
4)mothloss
计算fake_out嘴部分与fake_out原图嘴部分做perceptionLoss
5)sync_loss
生成的嘴型与对应的音频,送到syncnet中,得到音频特征和嘴型特征,然后做nn.MSELoss()
(5)辅助网络:
1)图片+音频判别器网络:
比较大的一个二分类网络,用来判别生成图和原图的真假
GAN loss=MSE Loss
2)音视频同步网络
通过调节表情特征系数,可以控制嘴型。