在数据科学的世界里,将分析结果快速、直观地呈现给非技术背景的决策者,是一项重要的技能。而Streamlit,这个开源的Python库,正是为此而生。它允许数据科学家和工程师通过少量的代码,快速创建和分享数据应用。今天,我们就来探索Streamlit的魔力,看看它是如何简化我们的工作流程的。
什么是Streamlit?
Streamlit是一个用于快速创建和分享数据应用的开源Python库。它特别适合于数据科学家和工程师,因为它可以让他们用Python语言快速构建交云应用,而无需深入了解前端开发。
Streamlit的原理
Streamlit的工作原理基于Python的Jupyter Notebook。它通过将Python脚本转换为交互式Web应用,让复杂的数据处理和分析过程变得可视化和可交互。Streamlit应用的运行依赖于一个简单的Web服务器,这使得它易于部署和分享。
安装Streamlit
安装Streamlit非常简单,只需要一行命令:
pip install streamlit
基础用法
创建第一个Streamlit应用
创建一个名为app.py的Python文件,然后写入以下代码:
import streamlit as st# 在应用中写入文本
st.write("Hello, Streamlit!")# 创建一个滑块
x = st.slider('Select a value')
st.write('Selected value:', x)
运行这个应用,只需在命令行中输入:
streamlit run app.py
这将启动一个本地Web服务器,并在默认的Web浏览器中打开你的Streamlit应用。
交互式组件
Streamlit提供了多种交互式组件,包括滑块、按钮、选择框等。这些组件可以让用户与应用进行交互,从而动态地改变应用的输出。
滑块(Slider)
x = st.slider('Select a value', min_value=0, max_value=10, value=5, step=1)
下拉菜单(Selectbox)
options = ['option1', 'option2', 'option3']
selected_option = st.selectbox('Choose an option', options)
按钮(Button)
if st.button('Click me!'):st.write('Button was clicked!')
数据可视化
Streamlit与多个数据可视化库兼容,如Matplotlib、Seaborn、Plotly等,可以轻松地将数据可视化结果集成到应用中。
使用Matplotlib
import matplotlib.pyplot as plt
import numpy as npx = np.linspace(0, 10, 1000)
y = np.sin(x)st.pyplot(plt.plot(x, y))
使用Plotly
import plotly.express as pxdf = px.data.iris()
fig = px.scatter(df, x='sepal_width', y='sepal_length')st.plotly_chart(fig)
数据处理
Streamlit也可以用于展示数据处理的过程。例如,你可以展示Pandas DataFrame,并让用户通过交互式组件来过滤数据。
展示DataFrame
import pandas as pddf = pd.read_csv('your_data.csv')
st.dataframe(df)
过滤DataFrame
selected_option = st.selectbox('Choose a column', df.columns)
filtered_df = df[df[selected_option] > st.slider('Select a threshold', min_value=0, max_value=100, value=50, step=1)]
st.dataframe(filtered_df)
结语
以下是文章中提到的所有示例代码的汇总,方便读者复制和运行。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib# 设置matplotlib字体支持中文显示
matplotlib.rcParams['font.family'] = 'SimHei' # 指定字体为SimHei
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号# 加载数据
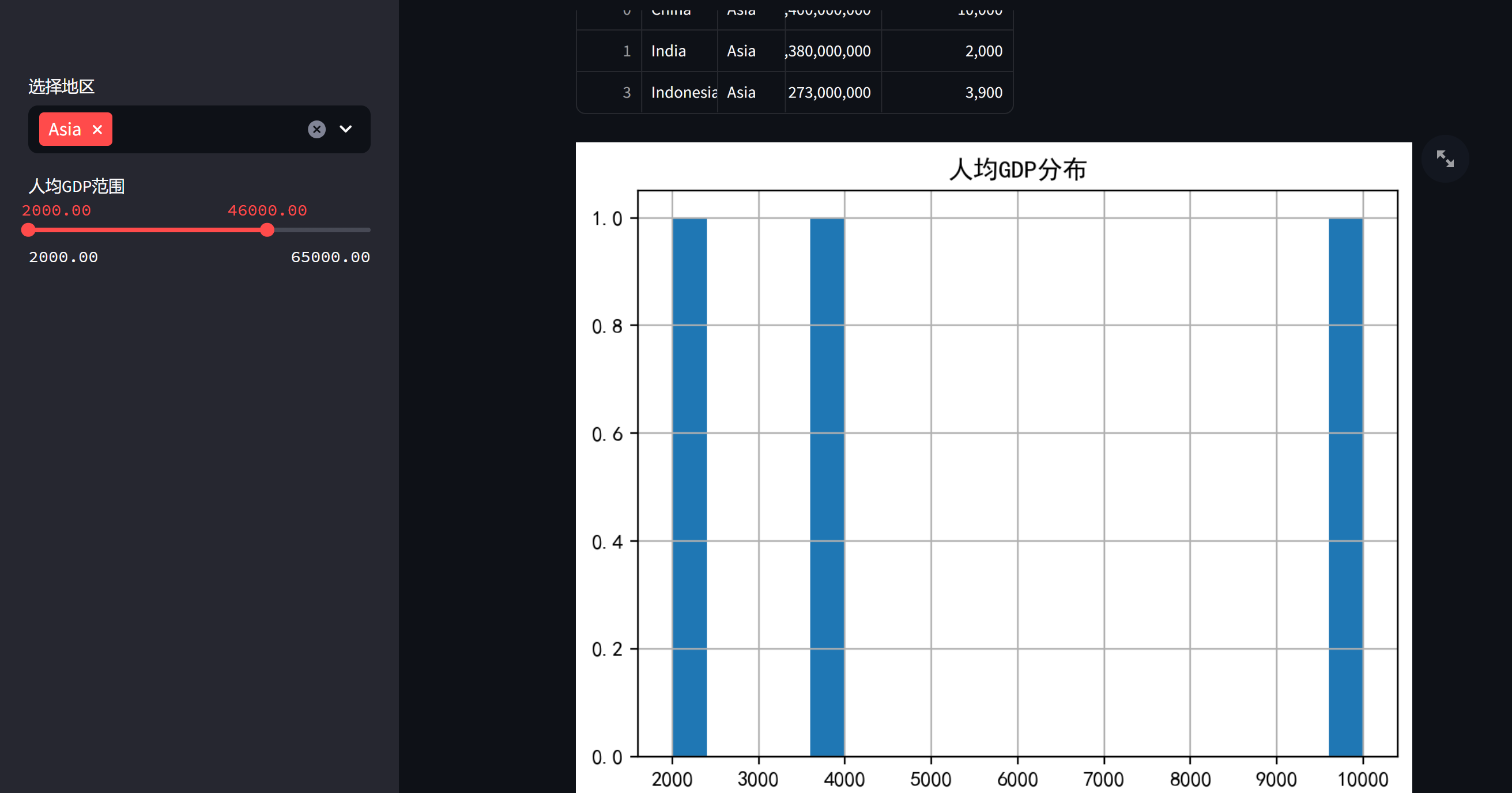
data = pd.read_csv('global_development.csv')# 应用标题
st.title('全球发展数据探索')# 添加筛选器侧边栏
region = st.sidebar.multiselect('选择地区', data['Region'].unique())
gdp_per_capita_range = st.sidebar.slider('人均GDP范围', min_value=float(data['GDP_per_capita'].min()), max_value=float(data['GDP_per_capita'].max()), value=(float(data['GDP_per_capita'].min()), float(data['GDP_per_capita'].max())),step=1000.0) # 确保步长类型为浮点数# 数据筛选
filtered_data = data[(data['Region'].isin(region)) & (data['GDP_per_capita'].between(*gdp_per_capita_range))]# 显示筛选后的数据
st.write(f"筛选后的数据包含 {filtered_data.shape[0]} 条记录")
st.dataframe(filtered_data)# 绘制人均GDP直方图
fig, ax = plt.subplots()
filtered_data['GDP_per_capita'].hist(ax=ax, bins=20)
ax.set_title('人均GDP分布')
st.pyplot(fig)# 人口总和显示
population_total = filtered_data['Population'].sum()
st.write(f"筛选国家的总人口为:{population_total}")
数据文件global_development.csv内容如下:
Country,Region,Population,GDP_per_capita
China,Asia,1400000000,10000
India,Asia,1380000000,2000
United States,North America,330000000,65000
Indonesia,Asia,273000000,3900
Brazil,South America,212000000,6800
Streamlit是一个强大的工具,它让数据科学变得更加简单和有趣。通过这篇文章,我们了解了Streamlit的基本概念、原理以及如何使用它来创建交互式应用。希望这能激发你探索Streamlit的兴趣,让你的数据科学之旅更加顺畅。