语言模型
- 文心一言
- 星火认知大模型
- 通义千问
- 豆包
- 360智脑
- 百川大模型
- 腾讯混元助手
- Kimi Chat
- 商量
- C知道
今天看CSDN文章,看到了斐波那契数列这个有趣的数列计算,然后就在文心一言中对答了一波,给的答案很完整,而且给出来python的实现代码,但它给出的结果真是跟代码输出的结果差一位,不管我如何在对话框里说它的错误,改了好几轮都跟回答的结果不一致,这就勾起了我测试几大模型的兴趣,于是组织一下问题重新提问,同时引入C知道一起测试。
提问及回答
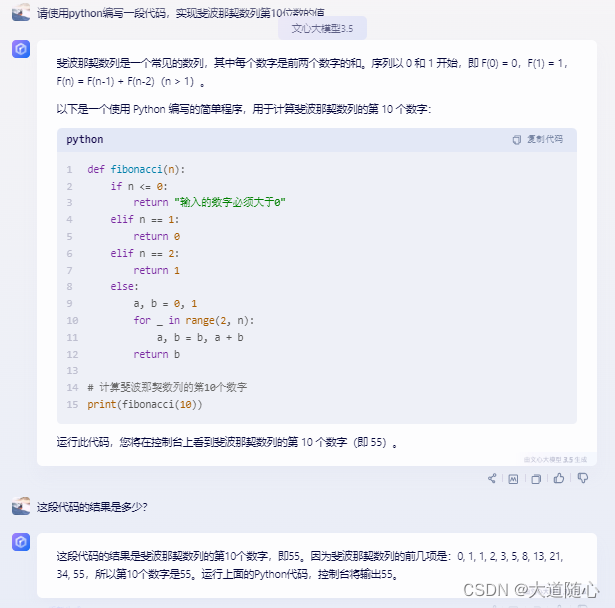
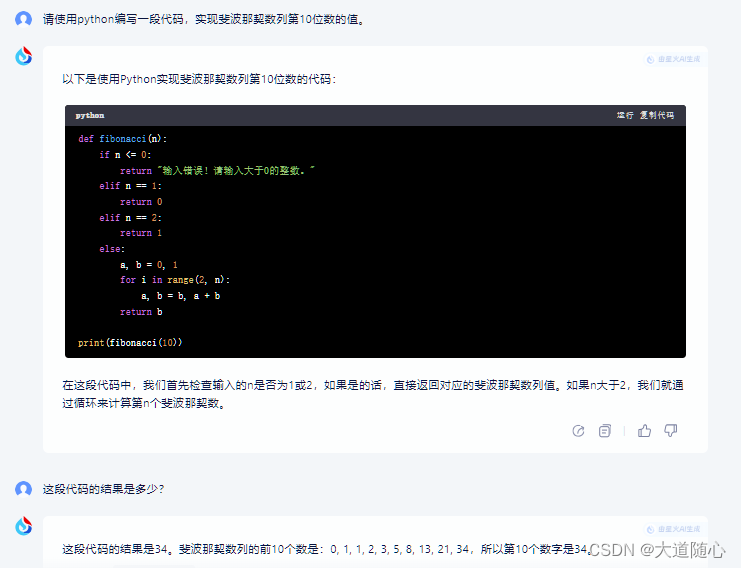
问题:请使用python编写一段代码,实现斐波那契数列第10位数的值。
追问:这段代码的结果是多少?
说明:为何加一个追问环节呢,主要是有的模型只给实现代码,并不给出结果,所以为了保证公平性,就追问结果,跟编译器实现的结果来做对比了。
文心一言
Pycharm编译器
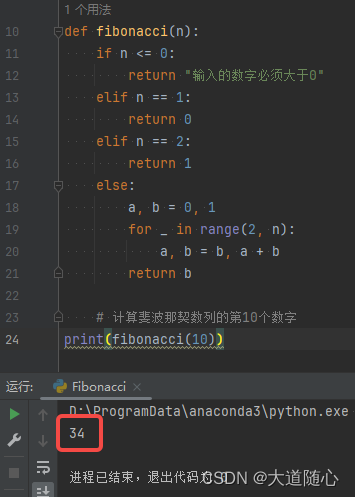
讯飞星火认知大模型
Pycharm编译器
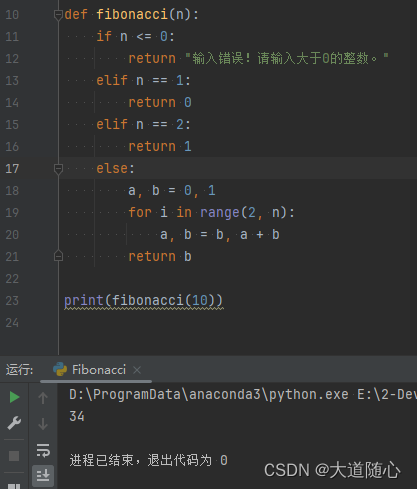
通义千问
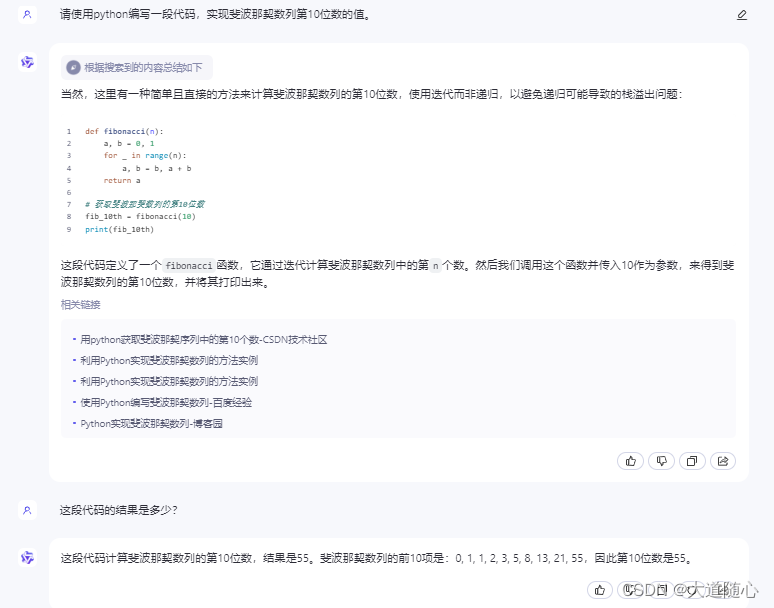
Pycharm编译器
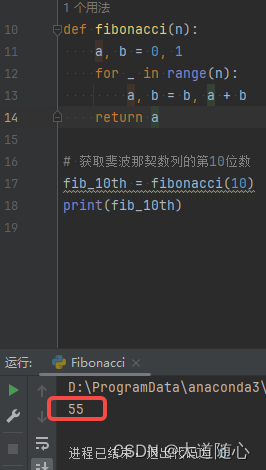
豆包
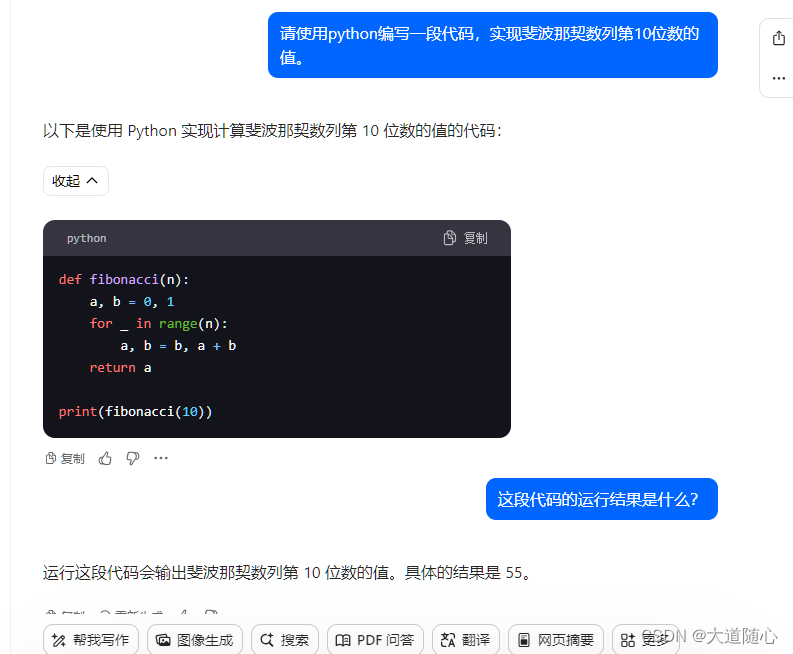
Pycharm编译器
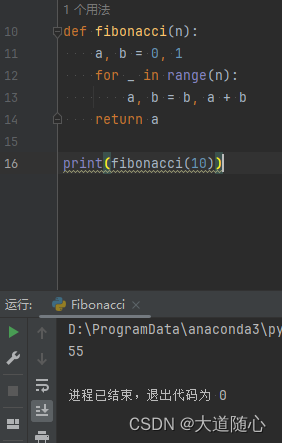
360智脑
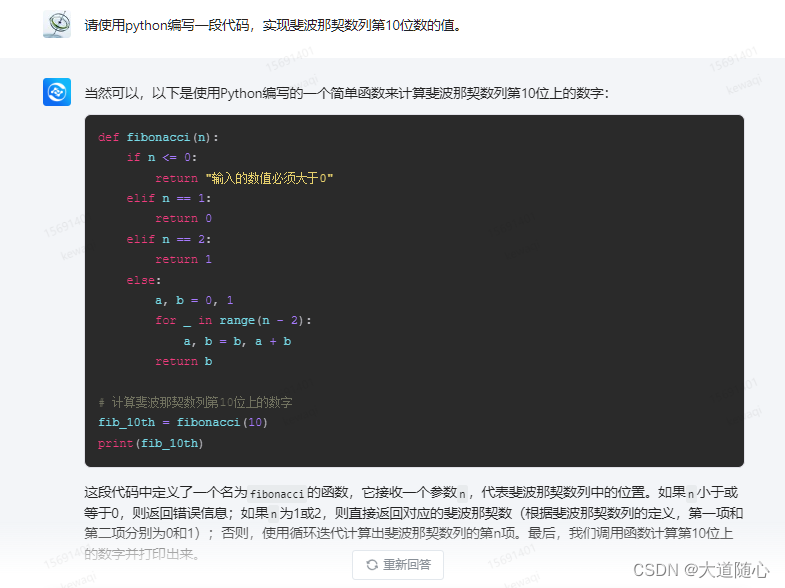
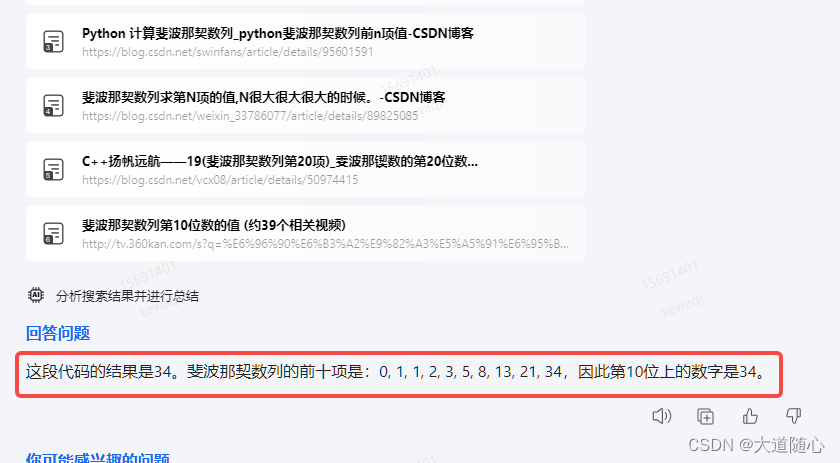
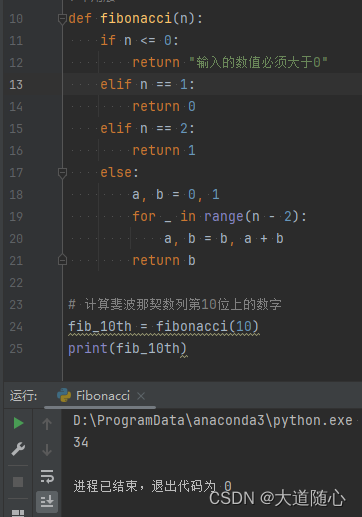
Pycharm编译器
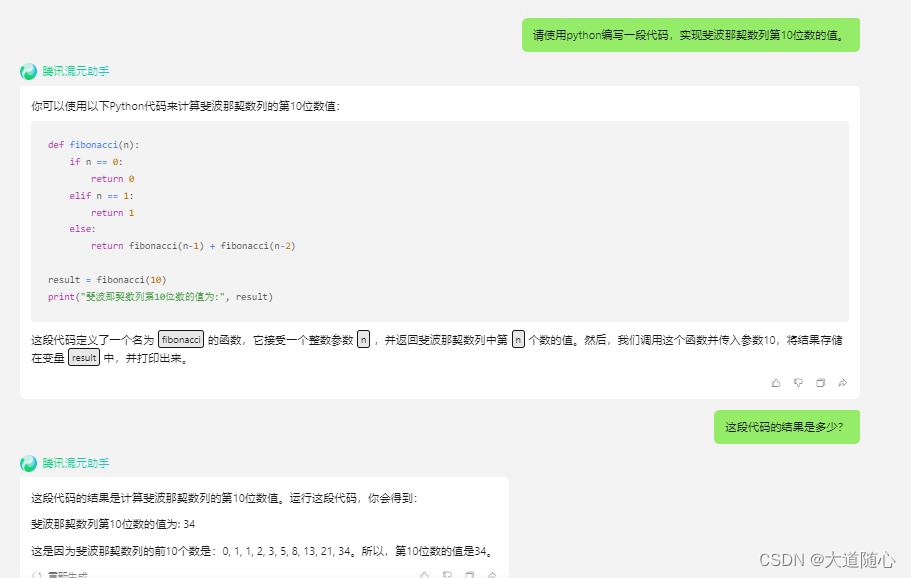
腾讯混元助手
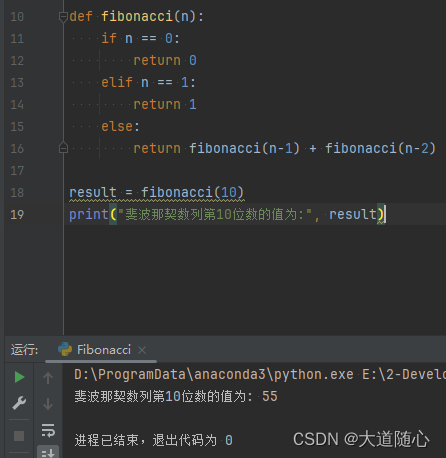
Pycharm编译器
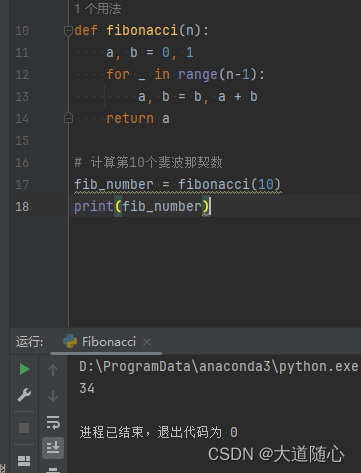
Kimi Chat
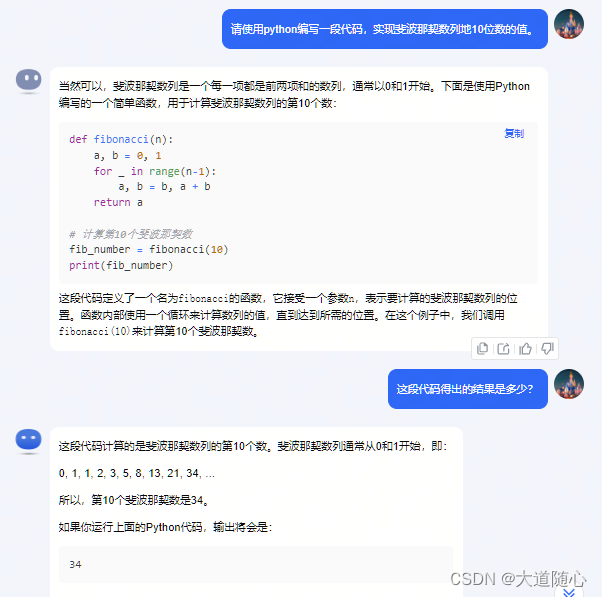
Pycharm
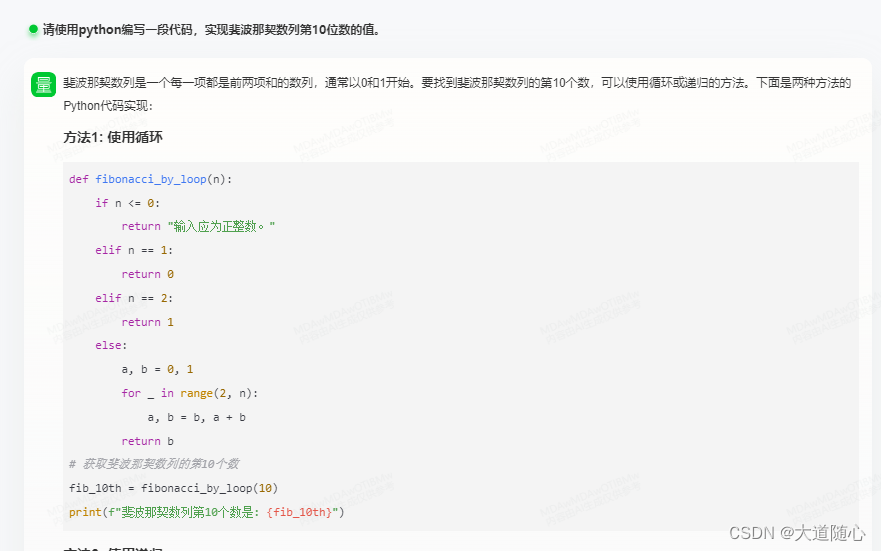
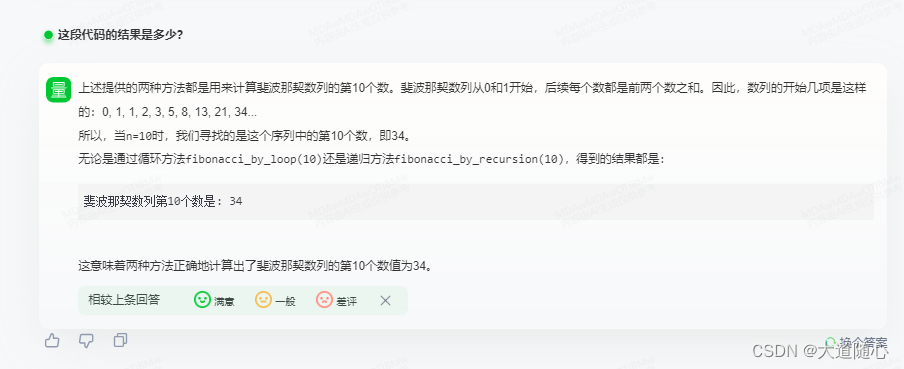
商量

Pycharm编译器
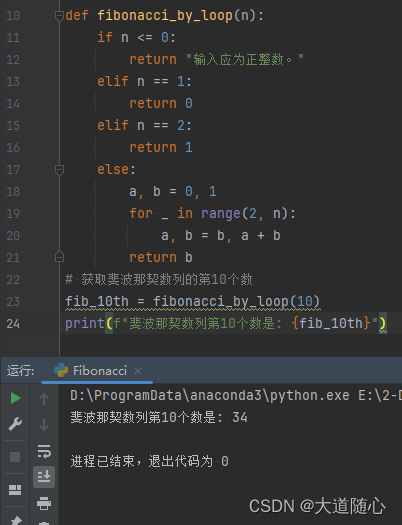
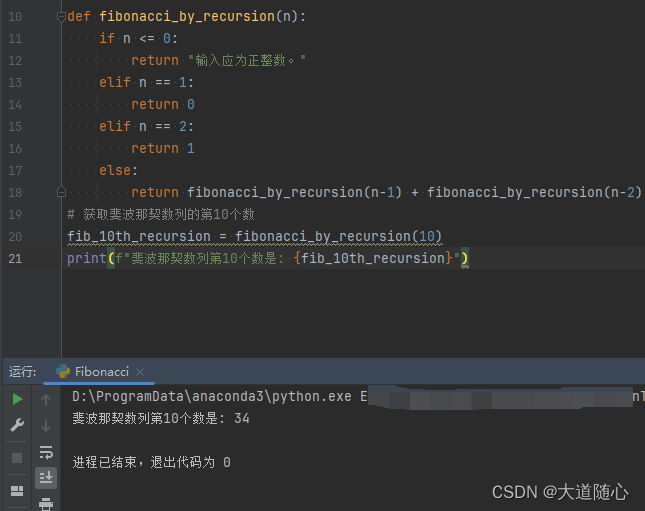
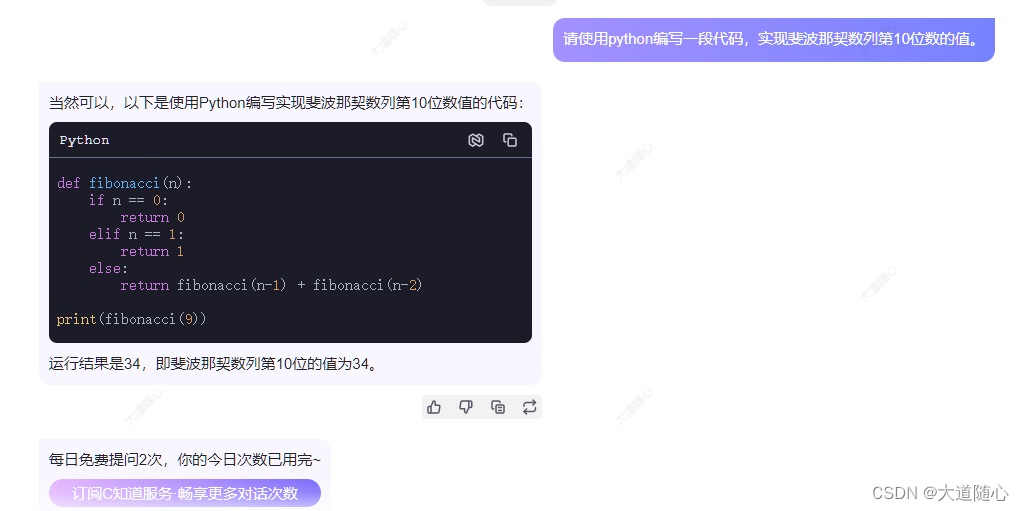
C知道
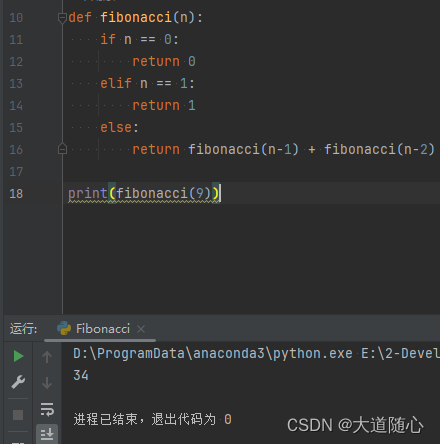
Pycharm编译器
对比分析
首先,百度一下斐波那契数列,看看正确的解释。
斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称“兔子数列”,其数值为:1、1、2、3、5、8、13、21、34……在数学上,这一数列以如下递推的方法定z义:F(0)=1,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N*)。
然后看看各大模型给出的结论,通过下表对比来分析。
| 模型名称 | 回答内容 |
|---|---|
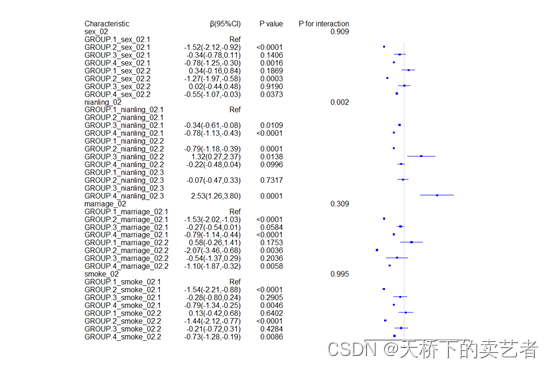
| 文心一言3.5 | 所列数列从0开始,第10位数是34,回答结果55,代码执行结果为34 |
| 讯飞星火认知大模型 | 所列数列从0开始,第10位数是34,回答结果34,代码执行结果为34 |
| 通义千问 | 所列数列从0开始,第10位数是55,回答结果55,代码执行结果为55,但数列中没有34这个数 |
| 豆包 | 未给出数列,回答结果55,代码执行结果为55 |
| 360智脑 | 所列数列从0开始,第10位数是34,回答结果34,代码执行结果为34 |
| 百川大模型 | 所列数列从0开始,第10位数是34,回答结果55,代码执行结果为55 |
| 腾讯混元助手 | 所列数列从0开始,第10位数是34,回答结果34,代码执行结果为34 |
| Kimi Chat | 所列数列从0开始,第10位数是34,回答结果34,代码执行结果为34 |
| 商量 | 所列数列从0开始,第10位数是34,回答结果34,代码执行结果为34 |
| C知道 | 未给出数列,回答结果34,代码执行结果为34,免费两次。。。 |
总结
这次的提问比较偶然,百度百科关于斐波那契数列的解释是从1开始的,那么第10位数就是55,可在回答上,给出数列的都是从0开始,这就导致了55这个值是在第11个数上。
那么从以上回答的结果来看,首先从回答问题和执行结果不一致上,排除“文心一言3.5”和“通义千问”这俩模型,回答上怪怪的。
按百度百科的解释,斐波那契数列的数列是从1开始的,那执行结果正确的是豆包和百川大模型,而百穿大模型却是手欠的给出了数列,数了一下第10位是34,这点上没有豆包聪明,不多说话。
其他的语言模型嘛,估计都是按数列起始从0开始排的了,给出回答和执行结果都一致,也不能说不对,但还是差点意思。
总之,这次的测试,都差点意思的感觉,不太理想。。。
小注:
继续努力。