手动实现简易版RPC(四)
往期内容
-
手动实现简易版RPC(一):RPC简介及系统架构
-
手动实现简易版RPC(二):简单RPC框架实现
-
手动实现简易版RPC(三):mock数据生成
前言
接上几篇博客我们实现了最简易RPC框架,实现了mock数据等,接下来的几期重点在简易版的rpc框架上继续深耕。本文主要介绍简易版RPC 中序列化相关的内容。
在手动实现简易版RPC(一):RPC简介及系统架构中我们简单描述了RPC框架中序列化器相关的内容并成功使用Kryo序列化器作为我们的序列化器。了解到了序列化器的作用:无论是请求或响应,都会涉及参数的传输。而 Java 对象是存活在JVM 虚拟机中的,如果想在其他位置存储并访问、或者在网络中进行传输,就需要进行序列化和反序列化。
但是对于一个完善的 RPC 框架,我们在序列化器这个技术点中还要思考一些问题:
1.有没有更好的序列化器实现方式?
2.如何让使用框架的开发者指定使用的序列化器?
3.如何让使用框架的开发者自己定制序列化器?
带着这几个问题,我们一起来探索。
序列化器的实现方式
所谓更好的序列化器实现方式,无非就是速度快?序列化后序列化结果体积小?等等,这样才能满足传输时高效。
下面简单对比一下常用的序列化器以及他们的优缺点
- Java原生序列化:
- 优点:
- 简单易用:Java对象只需实现
Serializable接口即可进行序列化。 - 跨平台性:序列化的字节流是平台无关的,可以在不同的JVM之间传输数据。
- 简单易用:Java对象只需实现
- 缺点:
- 性能不佳:相对于其他序列化工具,Java原生序列化的性能较差,尤其是在处理大量数据时。
- 安全性问题:Java原生序列化存在反序列化漏洞,可能导致安全风险。
- 序列化后的数据体积较大:可能会导致存储和传输成本增加。
- 优点:
- Kryo序列化:
- 优点:
- 高性能:Kryo通过直接内存访问和使用高效的序列化算法,提供了比Java原生序列化更快的序列化和反序列化速度。
- 低开销:序列化后的字节流体积小,传输和存储开销较低。
- 支持自定义序列化:用户可以根据需求自定义序列化和反序列化逻辑。
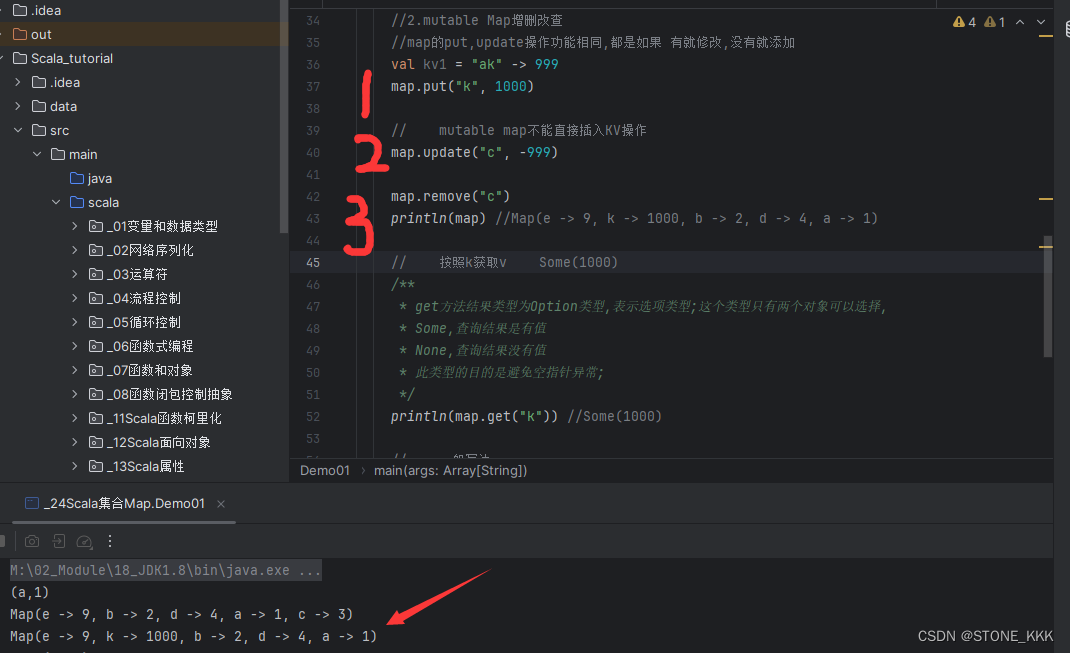
- 缺点:
- 使用复杂度:相对于Java原生序列化,Kryo需要更多的配置和自定义,使用门槛稍高。
- 兼容性:Kryo不是Java标准库的一部分,因此在使用时需要注意与其他系统的兼容性。
- 优点:
- Jackson序列化:
- 优点:
- 适用于JSON数据交换:Jackson主要用于将Java对象转换为JSON格式,适用于Web服务间的数据交换。
- 灵活性:支持复杂的嵌套结构和数据类型,可以方便地处理各种Java对象。
- 活跃的社区支持:Jackson拥有庞大的用户群体和活跃的社区支持,不断更新和优化功能。
- 缺点:
- 传输效率:相比二进制序列化工具,JSON格式的数据体积可能较大,传输效率较低。
- 数据类型限制:JSON本身的数据类型有限,可能无法完全表示Java中所有的数据类型和复杂结构。
- 优点:
- Protocol Buffers(Protobuf):
- 优点:
- 高性能:序列化后的数据体积小,传输速度快。
- 跨语言支持:Protobuf支持多种语言,方便跨语言通信。
- 自动生成代码:可以根据定义的数据结构自动生成序列化和反序列化的代码。
- 缺点:
- 学习成本:需要学习Protobuf的数据定义语法和工具链。
- 使用限制:对于某些复杂的Java对象结构,可能需要进行额外的处理或调整。
- 优点:
- Hessian :
- 优点:
- 轻量级与高效:Hessian采用二进制RPC协议,适合在带宽较小的情况下使用,如手机网络应用。
- 跨语言支持:Hessian支持多种编程语言,如Java、C++、C#等,方便在不同语言间传输数据。
- 协议设计紧凑:Hessian协议设计优化,序列化后数据紧凑,减少带宽消耗。
- 支持复杂数据类型:Hessian支持对象、数组、集合等多种复杂数据类型的序列化。
- 缺点:
- 安全性不足:Hessian传输未加密,不适合对安全性要求高的应用。
- 异常处理机制不完善:Hessian错误提示信息不足,事务处理存在欠缺。
- 版本兼容性问题:使用Hessian时可能遇到与其他库或框架的版本兼容性问题。
- 复杂对象处理挑战:传输复杂对象时可能削弱Hessian的传输优势,并增加客户端代码量。同时,同名成员变量在父类和子类间可能发生覆盖问题。
- 优点:
动态使用序列化器
之前使用序列化器的时候,都是采用硬编码的方式,
// 指定序列化器
final Serializer serializer = new KryoSerializer();
如果想要替换某一个序列化器,那么在使用他的地方都得去修改代码,这个是非常麻烦的。
理想的情况下,我们想要实现的效果就是用户能够自定义进行配置或者自定义序列化器,具体方式可以参考dubbo替换序列化的方式: dubbo替换序列化协议🌐
自定义使用序列化器
如果用户不想使用我们框架中内嵌的一些序列化器,想自定义一个新的序列化器,但是呢又不能改变我们框架的现有逻辑,如果实现这个需求,应该如何实现?

其实思路还是比较简单的:只要我们的 RPC 框架能够读取到用户自定义的类路径,然后加载这个类,作为 Serializer 序列化器接口的实现即可。
那么具体怎么实现他呢?
HERE ARE SOMETHING NEW
在此引入SPI概念:
什么是SPI?
Java SPI(Service Provider Interface)是Java平台的一项特性,它提供了一种服务发现和加载的机制。SPI的核心原理是基于接口编程,允许第三方为某个接口提供实现,并在运行时动态地加载这些实现。这种机制使得Java应用程序能够灵活地扩展其功能,而无需修改原有的代码。
一些应用场景
- 日志框架
- Java SPI在日志框架中的应用非常普遍。以SLF4J(Simple Logging Facade for Java)为例,它允许应用程序在运行时选择不同的日志实现,而无需修改代码。SLF4J定义了一个日志接口,例如
Logger,其中包含了常见的日志方法,如info(),debug(),error()等。然后,不同的日志实现(如Log4j、Logback、JDK Logging等)可以为这个接口提供具体的实现。在运行时,应用程序通过SPI机制加载所需的日志实现,从而实现日志功能的灵活配置和扩展。
- Java SPI在日志框架中的应用非常普遍。以SLF4J(Simple Logging Facade for Java)为例,它允许应用程序在运行时选择不同的日志实现,而无需修改代码。SLF4J定义了一个日志接口,例如
- 数据库驱动加载
- 在Java数据库连接(JDBC)中,SPI也发挥着关键作用。JDBC通过SPI机制加载数据库驱动。具体来说,JDBC定义了一个
java.sql.Driver接口,不同的数据库厂商(如MySQL、Oracle、SQL Server等)会为这个接口提供实现,并将这些实现打包成jar文件。这些jar文件会放在类路径下,并在META-INF/services目录下包含一个文件,文件名为java.sql.Driver,文件内容是实现该接口的类的全限定名。当应用程序需要连接到数据库时,JDBC会扫描这些文件并加载相应的驱动实现,从而实现数据库连接的建立。
- 在Java数据库连接(JDBC)中,SPI也发挥着关键作用。JDBC通过SPI机制加载数据库驱动。具体来说,JDBC定义了一个
如何实现
1-系统实现
-
基本原理
- 在Java中,SPI的使用方式通常如下:首先定义一个接口,然后在项目的
src/main/resources/META-INF/services目录下创建一个以该接口全限定名命名的文件。文件内容是实现该接口的具体实现类的全限定名。当程序运行时,JVM会查找并加载这些实现类。 - Java SPI的实现原理基于Java类加载机制和反射机制。当使用
ServiceLoader.load(Class<T> service)方法加载服务时,会检查META-INF/services目录下是否存在以接口全限定名命名的文件。如果存在,则读取文件内容,获取实现该接口的类的全限定名,并通过Class.forName()方法加载对应的类。在加载类之后,ServiceLoader会通过反射机制创建对应类的实例,并将其缓存起来。
- 在Java中,SPI的使用方式通常如下:首先定义一个接口,然后在项目的
-
应用到项目
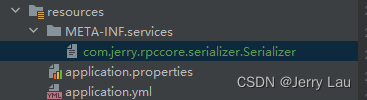
- 首先在
ape-rpc-core模块下的resources目录下新建META-INF文件夹,在其下面建立services文件后,在services下创建文件com.jerry.rpccore.serializer.Serializer(这儿这个文件名,是你的接口全限定名命名的文件的类路径)
-
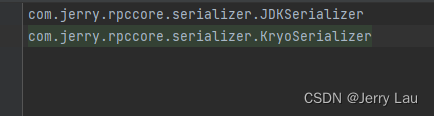
文件中的类容,就写接口实现类的类路径
-
然后就可以通过ServiceLoader.load()获取相应的接口实现,然后可以直接调取方法。
Serializer serializer = null;ServiceLoader<Serializer> load = ServiceLoader.load(Serializer.class); for (Serializer serializer1 : load) {serializer = serializer1;System.out.println(serializer); } System.out.println(load);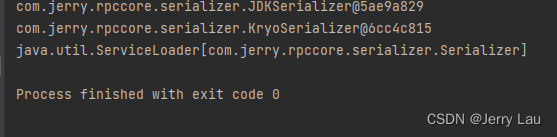
- 首先在
2-自定义实现
使用系统自带的spi虽然简单,但是如果我们想定义更多的接口及其实现类,就不能从框架中决定使用哪一个了,也就不能完成用户通过配置指定某个序列化的功能。
所以我们可以通过自定义spi ,可以灵活的通过配置,加载到某个实现类
比如读取一下配置文件,可以获取到一个map<序列化名,序列化实现类对象>,之后不就可以通过配置,获取到相关的实现类对象了
#系统内置序列化器配置参数
jdk:com.jerry.rpccore.serializer.JDKSerializer
hessian:com.jerry.rpccore.serializer.HessianSerializer
json:com.jerry.rpccore.serializer.JsonSerializer
kryo:com.jerry.rpccore.serializer.KryoSerializer
具体实现
1-多种序列化器的实现
之前我们实现了JDK以及Kryo序列化器,接下来我们实现Json以及Hessian序列化器
- 首先引入pom相关依赖
<!-- https://mvnrepository.com/artifact/com.caucho/hessian --><dependency><groupId>com.caucho</groupId><artifactId>hessian</artifactId><version>4.0.66</version></dependency>
-
然后可以在
serializer序列化器目录下分别实现这几种序列化器,关于序列化器的代码,可以自行百度或者用ai生成。- json序列化器:这个玩意儿比较复杂,需要考虑一些对象转换兼容性的问题,比如Object类型数组在转化后会丢失类型。
代码如下:
package com.jerry.rpccore.serializer;import com.fasterxml.jackson.databind.ObjectMapper; import com.jerry.rpccore.model.RpcRequest; import com.jerry.rpccore.model.RpcResponse;import java.io.IOException;/*** Json 序列化器**/ public class JsonSerializer implements Serializer {private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();@Overridepublic <T> byte[] serialize(T obj) throws IOException {return OBJECT_MAPPER.writeValueAsBytes(obj);}@Overridepublic <T> T deserialize(byte[] bytes, Class<T> classType) throws IOException {T obj = OBJECT_MAPPER.readValue(bytes, classType);if (obj instanceof RpcRequest) {return handleRequest((RpcRequest) obj, classType);}if (obj instanceof RpcResponse) {return handleResponse((RpcResponse) obj, classType);}return obj;}/*** 由于 Object 的原始对象会被擦除,导致反序列化时会被作为 LinkedHashMap 无法转换成原始对象,因此这里做了特殊处理** @param rpcRequest rpc 请求* @param type 类型* @return {@link T}* @throws IOException IO异常*/private <T> T handleRequest(RpcRequest rpcRequest, Class<T> type) throws IOException {Class<?>[] parameterTypes = rpcRequest.getParameterTypes();Object[] args = rpcRequest.getArgs();// 循环处理每个参数的类型for (int i = 0; i < parameterTypes.length; i++) {Class<?> clazz = parameterTypes[i];// 如果类型不同,则重新处理一下类型if (!clazz.isAssignableFrom(args[i].getClass())) {byte[] argBytes = OBJECT_MAPPER.writeValueAsBytes(args[i]);args[i] = OBJECT_MAPPER.readValue(argBytes, clazz);}}return type.cast(rpcRequest);}/*** 由于 Object 的原始对象会被擦除,导致反序列化时会被作为 LinkedHashMap 无法转换成原始对象,因此这里做了特殊处理** @param rpcResponse rpc 响应* @param type 类型* @return {@link T}* @throws IOException IO异常*/private <T> T handleResponse(RpcResponse rpcResponse, Class<T> type) throws IOException {// 处理响应数据byte[] dataBytes = OBJECT_MAPPER.writeValueAsBytes(rpcResponse.getData());rpcResponse.setData(OBJECT_MAPPER.readValue(dataBytes, rpcResponse.getDataType()));return type.cast(rpcResponse);} }- hessian序列化器
package com.jerry.rpccore.serializer;import com.caucho.hessian.io.HessianInput; import com.caucho.hessian.io.HessianOutput;import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.IOException;/*** Hessian 序列化器*/ public class HessianSerializer implements Serializer {@Overridepublic <T> byte[] serialize(T object) throws IOException {ByteArrayOutputStream bos = new ByteArrayOutputStream();HessianOutput ho = new HessianOutput(bos);ho.writeObject(object);return bos.toByteArray();}@Overridepublic <T> T deserialize(byte[] bytes, Class<T> tClass) throws IOException {ByteArrayInputStream bis = new ByteArrayInputStream(bytes);HessianInput hi = new HessianInput(bis);return (T) hi.readObject(tClass);} }
2-动态使用序列化器
- 首先建立序列化器名称的常量,使用接口类型实现
/*** @version 1.0* @Author jerryLau* @Date 2024/4/9 16:33* @注释 系列化键值对常量*/
public interface SerializerKeys {String JDK = "jdk";String HESSIAN = "hessian";String JSON = "json";String KRYO = "kryo";
}
- 建立序列化器工厂
对于序列化器而言,是可以重复使用,没有必要用一次就创建一个新的对象,所欲可以使用工厂模式+单例模式简化创建序列化对象的操作
序列化工厂代码如下,优先使用Map存储相关的序列化对象信息
package com.jerry.rpccore.serializer;import com.jerry.rpccore.utils.SPIloaderUtils;/*** @version 1.0* @Author jerryLau* @Date 2024/4/29 16:33* @注释 序列化工厂 用于获取系列化器*/
public class SerializerFactory {/**** 序列化器映射表*/private static final Map<String, Serializer> SERIALIZER_MAP = new HashMap<String, Serializer>() {{put(SerializerKeys.JDK, new JDKSerializer());put(SerializerKeys.KRYO, new KryoSerializer()); put(SerializerKeys.HESSIAN, new HessianSerializer());put(SerializerKeys.JSON, new JsonSerializer());}};/*** 默认序列化器 JDK序列化器*/private static final Serializer DEFAULT_SERIALIZER = new JDKSerializer();/*** 获取序列化器** @param key 序列化器名称* @return 序列化器*/public static Serializer getInstance(String key) {if (key == null) {return DEFAULT_SERIALIZER;}return SPIloaderUtils.getInstance(Serializer.class, key);}}- 在全局配置中配置初始化默认的序列化器
.../**** 默认序列化器* 默认使用jdk序列化器*/private String serializer = SerializerKeys.JDK;
...
- 动态获取序列化器
之前在动态代理的位置,手动指定使用哪一种序列化器,现在要将之前代码中的手动设置序列化器的部分,修改成为 使用工厂+读取配置来获取实现类
主要涉及的类有两个
rpccore模块中的:ServiceProxy
producer模块中的:HttpServerHandler
// 指定序列化器final Serializer serializer = SerializerFactory.getInstance(RPCGlobalConfHolder.getRpcConfig().getSerializer());
3-自定义序列化器
使用自定义的 SPI机制实现,支持用户自定义序列化器并指定键名
- 指定 SPI 配置目录
系统内置的 SPI机制会加载 resources 资源目录下的 META-INF/services 目录,那我们自定义的序列化器可以如法炮制,改为读取 META-INF/rpc 目录。
还可以将 SPI 配置再分为系统内置 SPI 和用户自定义 SPI,即目录如下:
- 用户自定义 SPI:META-INF/rpc/customd :用户可以在该目录下新建配置
- 系统内置 SPI:META-INF/rpc/systemd:RPC 框架自带的实现类,比如我们之前开发好的 JdkSerializer 。
这样一来,所有接口的实现类都可以通过 SPI动态加载,不用在代码中硬编码 Map 来维护实现类了。编写一个系统扩展配置文件,内容为我们之前写好的序列化器。
文件名称为 com.jerry.rpccore.serializer.Serializer,
代码如下:
#系统内置序列化器配置参数
jdk:com.jerry.rpccore.serializer.JDKSerializer
hessian:com.jerry.rpccore.serializer.HessianSerializer
json:com.jerry.rpccore.serializer.JsonSerializer
kryo:com.jerry.rpccore.serializer.KryoSerializer
- 手动实现SpiLoader,进行配置文件的加载
所谓SpiLoader相当于是一个工具类,主要目的是加载用户自定义的序列化器配置或者系统内置的序列化器配置
其主要功能如下:
1.用 Map 来存储已加载的配置信息 键名 => 实现类 。
2.扫描指定路径,读取每个配置文件,获取到 键名 =>实现类 信息并存储在 Map 中。
3.定义获取实例方法,根据用户传入的接口和键名,从 Map 中找到对应的实现类,然后通过反射获取到实现类对象。可以维护一个对象实例缓存,创建过一次的对象从缓存中读取可。
具体代码如下:
package com.jerry.rpccore.utils;import cn.hutool.core.io.resource.ResourceUtil;
import com.jerry.rpccore.serializer.Serializer;
import lombok.extern.slf4j.Slf4j;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;/*** @version 1.0* @Author jerryLau* @Date 2024/4/30 8:54* @注释 SPI加载器工具类* <p>* 加载系统以及用户自定义的SPI实现类*/
@Slf4j
public class SPIloaderUtils {/**** 存储已加载的SPI实现类 接口名 -> 实现类名 -> 实现类*/private static Map<String, Map<String, Class<?>>> SPI_MAP = new ConcurrentHashMap<String, Map<String, Class<?>>>();/**** 存储已实例化的SPI实现类(避免重新创建) 接口名 -> 实现类名 -> 实现类实例*/private static Map<String, Object> SPI_INSTANCE_MAP = new ConcurrentHashMap<String, Object>();/**** 系统初始化时,加载系统默认的SPI实现类目录*/private static final String SPI_DEFAULT_PATH = "META-INF/rpc/systemd/";/**** 用户自定义的SPI实现类目录*/private static final String SPI_USER_PATH = "META-INF/rpc/customd/";/**** 扫描路径*/private static final String[] SCAN_PATHS = {SPI_DEFAULT_PATH, SPI_USER_PATH};/**** 动态加载的类列表*/private static final List<Class<?>> CLASS_LIST = Arrays.asList(Serializer.class);/**** 加载所有SPI实现类*/public static void loadAllSPI() {for (Class<?> clazz : CLASS_LIST) {log.info("load all SPI class");loadSPI(clazz);}}/****获取某个接口的实例* @param tClass* @param KEY* @return* @param <T>*/public static <T> T getInstance(Class<T> tClass, String KEY) {String tClassName = tClass.getName();Map<String, Class<?>> stringClassMap = SPI_MAP.get(tClassName);if (stringClassMap == null) {//未获取到SPI实现类throw new RuntimeException(" SPIloader: not found SPI implement class for " + tClassName);}if (!stringClassMap.containsKey(KEY)) {throw new RuntimeException(" SPIloader: tClass " + tClassName + " not found key " + KEY);}//获取要加载的实现类型Class<?> aClass = stringClassMap.get(KEY);//判断是否已经实例化过String name = aClass.getName();if (!SPI_INSTANCE_MAP.containsKey(name)) {//未实例化过,实例化并放入缓存try {Object instance = aClass.newInstance();SPI_INSTANCE_MAP.put(name, instance);} catch (Exception e) {throw new RuntimeException(" SPIloader: create instance error " + e.getMessage());}}return (T) SPI_INSTANCE_MAP.get(name);}/**** 加载SPI实现类* @param clazz SPI接口类*/public static Map<String, Class<?>> loadSPI(Class<?> clazz) {log.info("load SPI implement class for " + clazz.getName());HashMap<String, Class<?>> keyClassMap = new HashMap<>();for (String scanPath : SCAN_PATHS) {//扫描SPI实现类System.out.println("scanPath + clazz.getName():"+scanPath + clazz.getName());List<URL> resources = ResourceUtil.getResources(scanPath + clazz.getName());for (URL resource : resources) {try {InputStreamReader inputStreamReader = new InputStreamReader(resource.openStream());BufferedReader bufferedReader = new BufferedReader(inputStreamReader);String line;while ((line = bufferedReader.readLine()) != null) {if (line.startsWith("#")) {continue;}String[] split = line.split(":");if (split.length == 2) {String key = split[0].trim();String className = split[1].trim();try {Class<?> aClass = Class.forName(className);keyClassMap.put(key, aClass);} catch (ClassNotFoundException e) {throw new RuntimeException(e);}}}bufferedReader.close();inputStreamReader.close();} catch (IOException e) {log.error("load SPI implement class error " + e.getMessage());throw new RuntimeException(e);}}}SPI_MAP.put(clazz.getName(), keyClassMap);return keyClassMap;}
}
上述代码中,虽然提供了 loadAllSPI 方法,扫描所有路径下的文件进行加载,但其实没必要使用。更推荐使用 loadSPI 方法,按需加载指定的类。
注意,上述代码中获取配置文件是使用了ResourceUtil.getResources ,而不是通过文件路径获取。因为如果框架作为依赖被引入,是无法得到正确文件路径的,
- 重构序列化器工厂
将之前的自定义的map修改成为加载序列化器
/**** 序列化器映射表*/
// private static final Map<String, Serializer> SERIALIZER_MAP = new HashMap<String, Serializer>() {{
// put(SerializerKeys.JDK, new JDKSerializer());
// put(SerializerKeys.KRYO, new KryoSerializer());
// put(SerializerKeys.HESSIAN, new HessianSerializer());
// put(SerializerKeys.JSON, new JsonSerializer());
// }};static {SPIloaderUtils.loadSPI(Serializer.class);}
使用静态代码块,在工厂首次加载时,就会调用 Spiloader 的 load 方法加载序列化器接口的所有实现类,之后就可以通过调用 getlnstance 方法获取指定的实现类对象了。
测试
application.properties 改用如下配置
RPC.name=apeRpc
RPC.version=V0.0.2
RPC.serverPort=8080
RPC.mock=false
RPC.serializer=hessian
启动生产者和消费者发现能够获取到配置的序列化器,同时可以正常交互

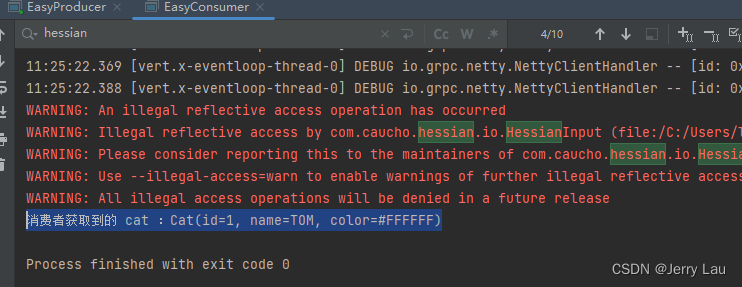
至此,我们实现了简易版的PRC框架中的自定义序列化器功能
码字不易,希望大家能够一键三连🌝⭐🌟
代码仓库 ape-rpc: 轮子项目,手动实现rpc github🌐 || ape-rpc: 轮子项目,手动实现rpc gitee🌐