前言
今天来把数仓数据同步解决掉,前面我们已经把日志数据到 Kafka 的通道打通了。

1、实时数仓数据同步
关于实时数仓,我们的 Flink 直接去 Kafka 读取即可,我们在学习 Flink 的时候也知道 Flink 提供了 Kafka Source,所以这里不需要再去添加什么额外的配置。
2、离线数仓数据同步
Flink 可以从 Kafka 中读取数据,可是 Hive 不行啊,Hive 是从 Hadoop HDFS 中读取数据,所以的离线数仓需要进行一些配置。
2.1、用户行为日志数据同步
2.1.1、数据通道选择
用户行为数据由 Flume 从 Kafka 直接同步到 HDFS,由于离线数仓采用 Hive 的分区表按天统计,所以目标路径要包含一层日期。

这里,我们的 hive 分区表需要按天分区,那就需要我们 Flume 从 Kafka 读取到的数据包含 Event Header 信息(hdfs sink 默认就是按照 event header 中的 timestamp 来落盘的),但是我们上游把用户行为日志传输到 Kafka Channel 的时候,我们设置了 parseAsFlumeEvent=false,这就导致存储在 Kafka Channel 中的日志只有 Event Body,没有 Event Header。应该怎么把 Kafka Channel 中的数据读取写入到 HDFS 而且还能够给日志数据增加一个 header,我们有两种选择方案:
1. 如果我们选择了 Kafka Channel 做数据源(我们之前说 Kfaka Channel 一共有 3 种结构:source -> kafka channel 、source -> kafka channel -> sink、kafka channel -> sink),选择了 kafka channel -> sink 结构的话,kafka channel 自己会封装一个 header 发送给 sink,但是这个 header 没有时间信息(timestamp),Event Body 中也可以有时间信息(要求我们日志时产生给每一条日志添加时间信息),但是我们不可以在 kafka channel 和 hdfs sink 之间设置拦截器去提取 body 中的时间信息(因为自定义拦截器只能在 source 和 channel 之间使用),所以这种结构无法实现。
2. 上一种方案如果可以实现的话,我们就省去了 source 读取,可惜上一种结构无法实现,除非把上游的 parseAsFlumeEvent 设置为 true 。所以我们只能再开一个完整的 flume 作业去 kafka 读取,即 kafak source -> file channel -> hdfs sink。
2.1.2 日志消费Flume配置概述
按照规划,该 Flume 需将 Kafka 中 topic_log 的数据发往 HDFS。并且对每天产生的用户行为日志进行区分,将不同天的数据发往HDFS不同天的路径。
这里我们选择Kafka Source、File Channel(数据比较重要的话一般都用 file channel)、HDFS Sink。

2.1.3、Flume 配置文件
# 定义组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1# 配置sources
a1.sources.r1.channels = c1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics = topic_log
a1.sources.r1.kafka.consumer.group.id = topic_log
a1.sources.r1.batchSize = 2000
a1.sources.r1.batchDurationMillis = 1000
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.lyh.gmall.interceptor.TimestampInterceptor$Builder# 配置channels
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.useDualCheckpoints = false
a1.channels.c1.dataDirs = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 3# 配置 sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1kafka source 配置:
- 我们知道,flume 每发送一次数据需要满足的条件是数据量达到 batchSize 条,或者时间达到 batchDurationMillis 。所以这里 batchDurationMillis 的配置尽量和系统达到 batchSize 的时间相近。比如每 2s 生成 2000 条的数据,那我们这里的 batchDurationMillis 最好就配置为 2000
- kafka.topics 和 kafka.topics.regex 这两个配置虽然都被加粗,但是只需要配置一个即可。
- kafka.consumer.group.id(默认为 flume),这里我们尽量配置 kafka 消费者组和业务名一样,因为我们实际项目中可能会有很多业务,如果这几个业务都需要消费这个 topic,但是如果不配置消费者组id,那么这些业务的消费者就会默认被分配到一个消费者组(flume 组),而一个 topic 的一个分区只能被一个消费者组的一个消费者所消费(我们这里的主题 topic_log 并只有一个分区),这样的话,只有一个业务的消费者可以消费到,而别的业务的消费者消费不到。
file channel 配置:
- checkpointDir:flume 的 file channel 有一个索引机制,它会把读取到的索引保存到内存当中去,但是防止数据丢失,还会再备份一次,这里就是配置备份的路径。
- useDualCheckpoints(默认为 false):表示是否开启二次备份。因为一次备份即使保存在磁盘,还是有出问题的可能,如果配置这个参数为 true 则必须配置参数 backupCheckpointDir
- backupCheckpointDir:这个参数就是配置二次备份的地址。
- dataDirs:flume 的多目录存储,可以把数据存储在服务器的多个磁盘上
- maxFileSize:我们的 file channel 是要写入文件的,这里配置的是这个文件的最大大小
- capacity:file channel 容纳数据条数的限制,默认最多 100w 条
- keep-alive:我们的 file channel 中的数据如果满了的时候,source 是写不进去的,这就需要回滚,还需要 kafka source 再从 kafka 去读一次,这样条浪费性能了。这个参数的作用是等一会,等到 channel 腾出一定空间之后再写进去。
hdfs sink 配置:
- hdfs.path:我们的 hdfs 保存路径中包含 %Y-%m-%d ,这意味这这个文件夹中保存的是一天的数据内容,如果我们有要求保存几个小时的内容,就需要设置 round 参数。
- round(默认是 false):flume 做的是离线的数据传输,我们的日志会每隔一定时间进行落盘。要精确到小时分钟或秒的话,就需要设置 roundValue 和 roundUnit 参数。比如每 6 个小时进行一次落盘的话,我们首先把路径改为 %Y-%m-%d/%h ,然后 roundValue 设置为 6,roundUnit 设置为 hour。
- roundValue:时间值
- roundUnit:时间单位
- rollInterval:hdfs 数据块滚动间隔(默认是 30s,单位是秒),同样我们最好设置这个采纳数的时间刚好差不多生成一个块大小(128MB)
- rollSize:基于文件的大小进行滚动(一般我们配置为 134217728 也就是 128MB)
- rollCount:基于 event 的条数进行滚动(一般设置为 0,因为用数据条数不太好控制文件的大小)
注意:rollInterval、rollSize、rollCount 如果都设置为 0 则代表该配置参数不生效。配置不当很容易造成大量小文件问题(危害:hdfs中一个文件在namenode中占用 150kb、一个文件会生成一个 map task )。
1. 数据漂移问题
当我们有数据比如在 23:59:59 经过 3s 才能发送到 kafka source,这时 kafka source 会在 event header 中封装一个 timestamp 信息,但是这时封装的 timestamp 已经到第二天了。

所以解决的办法就是,利用 flume 的自定义拦截器去把 kafka source 中 event body 的时间信息读取出来,封装到 header 当中去,这样就不会造成落盘错误了:

2. 编写拦截器
package com.lyh.gmall.interceptor;import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;public class TimestampInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {// 1. 获取 header 和 body 中的数据Map<String, String> headers = event.getHeaders();String log = new String(event.getBody(), StandardCharsets.UTF_8);// 2. 解析 log(json) 中的 ts 字段String ts = JSONObject.parseObject(log).getString("ts");// 3. 把解析出来的 ts 值放到 header 中headers.put("timestamp",ts);return event;}@Overridepublic List<Event> intercept(List<Event> list) {for (Event event : list) {intercept(event);}return list;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new TimestampInterceptor();}@Overridepublic void configure(Context context) {}}
}
完了重新打包到 hadoop104 下 flume 的 lib 目录下
2.1.4、日志消费测试
1. 启动 Zookeeper、Kafka
2. 启动hadoop102的用户日志采集脚本
f1.sh start这样我们的用户行为日志就被 flume 采集到了 kafka
3. 在 hadoop104 从kafka 采集日志到 hdfs
bin/flume-ng agent -n a1 -c conf/ -f job/warehouse/kafka_to_hdfs_log.conf -Dflume.root.logger=INFO,console4. 模拟数据生成
mklog.sh5. 测试结果

可以看到,用户行为日志被成功上传到了 hdfs。
2.1.5、日志启停脚本
我们在 hadoop102 编写一个脚本 f2.sh:
#!/bin/bashcase $1 in
"start")echo " --------启动 hadoop104 日志数据flume-------"ssh hadoop104 "nohup /opt/module/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.9.0/conf -f /opt/module/flume-1.9.0/job/warehouse/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")echo " --------停止 hadoop104 日志数据flume-------"ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac2.2、业务日志数据同步
对离线数仓来说,业务数据一般都是按天来进行同步的;但对实时数仓来说,来一条业务数据就必须马上同步。所以对于离线数仓,我们可以不使用 MaxWell ,而是通过 DataX 每天全量采集到数仓。
2.2.1 数据同步策略概述
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再对数据进行分析统计。
为保证统计结果的正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数仓的计算周期通常为天,所以数据同步周期也通常为天,即每天同步一次即可。
数据的同步策略有全量同步和增量同步。
全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式。就相当于每天进行一次 select * from xxx;

那我们的历史数据(比如今天全量同步后,今天之前的数据就是历史数据)就没有意义了吗?其实我们并不会立即删除历史数据,因为数据是有价值的,我们既可以分析其中的变化,也可以作为备份以防不测。
增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。

2.2.2 数据同步策略选择
两种策略都能保证数据仓库和业务数据库的数据同步,那应该如何选择呢?下面对两种策略进行简要对比。
| 同步策略 | 优点 | 缺点 |
| 全量同步 | 逻辑简单 | 在某些情况下效率较低(比如我的一张表大小10亿条,但是我每天只增加一条)。例如某张表数据量较大,但是每天数据的变化比例很低,若对其采用每日全量同步,则会重复同步和存储大量相同的数据。 |
| 增量同步 | 效率高,无需同步和存储重复数据 | 逻辑复杂,需要将每日的新增及变化数据同原来的数据进行整合,才能使用 |
根据上述对比,可以得出以下结论:
通常情况,业务表数据量比较大,优先考虑增量,数据量比较小,优先考虑全量;具体选择由数仓模型决定。
| 大表 | 变化多 | 全量 |
| 大表 | 变化少 | 增量 |
| 小表(比如省份表) | 变化多 | 全量 |
| 小表 | 变化少 | 全量 |

我们一般把全量同步的表叫做维度表,把增量同步的表叫做事实表。
2.2.3 数据同步工具概述
数据同步工具种类繁多,大致可分为两类,一类是以 DataX、Sqoop 为代表的基于Select查询的离线、批量同步工具,另一类是以 Maxwell、Canal 为代表的基于数据库数据变更日志(例如MySQL 的 binlog,其会实时记录所有的 insert、update 以及 delete操作)的实时流式同步工具。
全量同步通常使用 DataX、Sqoop 等基于查询的离线同步工具。而增量同步既可以使用DataX、Sqoop等工具,也可使用 Maxwell、Canal 等工具,下面对增量同步不同方案进行简要对比。
| 增量同步方案 | DataX/Sqoop | Maxwell/Canal |
| 对数据库的要求 | 原理是基于查询,故若想通过select查询获取新增及变化数据,就要求数据表中存在create_time、update_time等字段,然后根据这些字段获取变更数据。 | 要求数据库记录变更操作,例如MySQL需开启binlog。 |
| 数据的中间状态 | 由于是离线批量同步,故若一条数据在一天中变化多次,该方案只能获取最后一个状态,中间状态无法获取。 | 由于是实时获取所有的数据变更操作,所以可以获取变更数据的所有中间状态。 |
接下来我们选择用 DataX 来做全量数据的同步工作,用 Maxwell 来做增量数据的同步工作。
2.2.4、全量数据同步
全量表数据由 DataX 从 MySQL 业务数据库直接同步到 HDFS,具体数据流向如下图所示:

1. DataX 配置文件
回顾我们执行 DataX 脚本的命令:
python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json我们是通过把配置写进一个 json 文件然后执行的,所以这里,我们需要全量同步的表共 15 张,也就意味着需要写 15 个 json 配置文件,但是毕竟开发中不可能 100个、1000个表我们也都一个个手写,所以这里我们通过一个 python 来自动生成:
vim ~/bin/gen_import_config.py# ecoding=utf-8
import json
import getopt
import os
import sys
import MySQLdb#MySQL相关配置,需根据实际情况作出修改
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "123456"#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "hadoop102"
hdfs_nn_port = "8020"#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/opt/module/datax/job/import"def get_connection():return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)def get_mysql_meta(database, table):connection = get_connection()cursor = connection.cursor()sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"cursor.execute(sql, [database, table])fetchall = cursor.fetchall()cursor.close()connection.close()return fetchalldef get_mysql_columns(database, table):return map(lambda x: x[0], get_mysql_meta(database, table))def get_hive_columns(database, table):def type_mapping(mysql_type):mappings = {"bigint": "bigint","int": "bigint","smallint": "bigint","tinyint": "bigint","decimal": "string","double": "double","float": "float","binary": "string","char": "string","varchar": "string","datetime": "string","time": "string","timestamp": "string","date": "string","text": "string"}return mappings[mysql_type]meta = get_mysql_meta(database, table)return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)def generate_json(source_database, source_table):job = {"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": mysql_user,"password": mysql_passwd,"column": get_mysql_columns(source_database, source_table),"splitPk": "","connection": [{"table": [source_table],"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,"fileType": "text","path": "${targetdir}","fileName": source_table,"column": get_hive_columns(source_database, source_table),"writeMode": "append","fieldDelimiter": "\t","compress": "gzip"}}}]}}if not os.path.exists(output_path):os.makedirs(output_path)with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:json.dump(job, f)def main(args):source_database = ""source_table = ""options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])for opt_name, opt_value in options:if opt_name in ('-d', '--sourcedb'):source_database = opt_valueif opt_name in ('-t', '--sourcetbl'):source_table = opt_valuegenerate_json(source_database, source_table)if __name__ == '__main__':main(sys.argv[1:])由于需要使用Python访问Mysql数据库,所以需安装驱动,命令如下:
sudo yum install -y MySQL-python脚本使用说明:
python gen_import_config.py -d database -t table测试一下:
python gen_import_config.py -d gmall -t base_province

注意: 这里的 hdfswriter 的 writeMode = append,这个值的意思是即使这个目录下存在文件也继续写入。除了这个参数外,还可以设置 writeMode = nonConflict,这个值的意思是,如果发现目录下有文件则停止写入,直接报错。
可以看到,生成的 json 配置文件需要我们后期指定 datax 命令时再提供一个 targetdir 参数,也就是同步到我们 HDFS 的哪个目录下。
测试一下这个配置文件能不能用:
bin/datax.py -p"-Dtargetdir=/base_province" job/import/gmall.base_province.json
查看 hdfs 端:


这个配置文件没有 where 限制,所以这里是 34 条数据,到这里,说明我们用脚本生成的配置文件是可以正常用的。
2. DataX 配置文件生成脚本
上面我们用一个 python 脚本来生成 json 文件,生成好的 json 文件还需要通过 shell 脚本去调用执行 DataX 任务,所以我们这里编写一个 Shell 脚本:
vim ~/bin/gen_import_config.sh#!/bin/bashpython ~/bin/gen_import_config.py -d gmall -t activity_info
python ~/bin/gen_import_config.py -d gmall -t activity_rule
python ~/bin/gen_import_config.py -d gmall -t base_category1
python ~/bin/gen_import_config.py -d gmall -t base_category2
python ~/bin/gen_import_config.py -d gmall -t base_category3
python ~/bin/gen_import_config.py -d gmall -t base_dic
python ~/bin/gen_import_config.py -d gmall -t base_province
python ~/bin/gen_import_config.py -d gmall -t base_region
python ~/bin/gen_import_config.py -d gmall -t base_trademark
python ~/bin/gen_import_config.py -d gmall -t cart_info
python ~/bin/gen_import_config.py -d gmall -t coupon_info
python ~/bin/gen_import_config.py -d gmall -t sku_attr_value
python ~/bin/gen_import_config.py -d gmall -t sku_info
python ~/bin/gen_import_config.py -d gmall -t sku_sale_attr_value
python ~/bin/gen_import_config.py -d gmall -t spu_info赋予 gen_import_config.sh 执行权限后,执行脚本,生成配置文件
gen_import_config.sh
3. 全量数据同步脚本
#!/bin/bashDATAX_HOME=/opt/module/datax# 如果传入日期则do_date等于传入的日期,否则等于前一天日期
if [ -n "$2" ] ;thendo_date=$2
elsedo_date=`date -d "-1 day" +%F`
fi#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {hadoop fs -test -e $1if [[ $? -eq 1 ]]; thenecho "路径$1不存在,正在创建......"hadoop fs -mkdir -p $1elseecho "路径$1已经存在"fs_count=$(hadoop fs -count $1)content_size=$(echo $fs_count | awk '{print $3}')if [[ $content_size -eq 0 ]]; thenecho "路径$1为空"elseecho "路径$1不为空,正在清空......"hadoop fs -rm -r -f $1/*fifi
}#数据同步
import_data() {datax_config=$1target_dir=$2handle_targetdir $target_dirpython $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config
}case $1 in
"activity_info")import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date;;
"activity_rule")import_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_date;;
"base_category1")import_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_date;;
"base_category2")import_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_date;;
"base_category3")import_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_date;;
"base_dic")import_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_date;;
"base_province")import_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_date;;
"base_region")import_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_date;;
"base_trademark")import_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_date;;
"cart_info")import_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_date;;
"coupon_info")import_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_date;;
"sku_attr_value")import_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_date;;
"sku_info")import_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_date;;
"sku_sale_attr_value")import_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_date;;
"spu_info")import_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date;;
"all")import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_dateimport_data /opt/module/datax/job/import/gmall.activity_rule.json /origin_data/gmall/db/activity_rule_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_category1.json /origin_data/gmall/db/base_category1_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_category2.json /origin_data/gmall/db/base_category2_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_category3.json /origin_data/gmall/db/base_category3_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_dic.json /origin_data/gmall/db/base_dic_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_province.json /origin_data/gmall/db/base_province_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_region.json /origin_data/gmall/db/base_region_full/$do_dateimport_data /opt/module/datax/job/import/gmall.base_trademark.json /origin_data/gmall/db/base_trademark_full/$do_dateimport_data /opt/module/datax/job/import/gmall.cart_info.json /origin_data/gmall/db/cart_info_full/$do_dateimport_data /opt/module/datax/job/import/gmall.coupon_info.json /origin_data/gmall/db/coupon_info_full/$do_dateimport_data /opt/module/datax/job/import/gmall.sku_attr_value.json /origin_data/gmall/db/sku_attr_value_full/$do_dateimport_data /opt/module/datax/job/import/gmall.sku_info.json /origin_data/gmall/db/sku_info_full/$do_dateimport_data /opt/module/datax/job/import/gmall.sku_sale_attr_value.json /origin_data/gmall/db/sku_sale_attr_value_full/$do_dateimport_data /opt/module/datax/job/import/gmall.spu_info.json /origin_data/gmall/db/spu_info_full/$do_date;;
esac
这里 hadoop fs -test -e /base_province 会有一个返回值,我们需要通过 echo $? 来查看,当返回 0 时代表目录存在,当返回 1 时代表目录不存在。

这里 hadoop fs -count /base_province 作用是查看目录属性,第一个数字代表目录数(包括自己),第二个参数是该目录下的文件数,第三个参数是该目录的总大小(字节),第四个参数是当前的目录名。
测试同步脚本:
mysq_to_hdfs_full.sh all 2020-06-14 查看结果: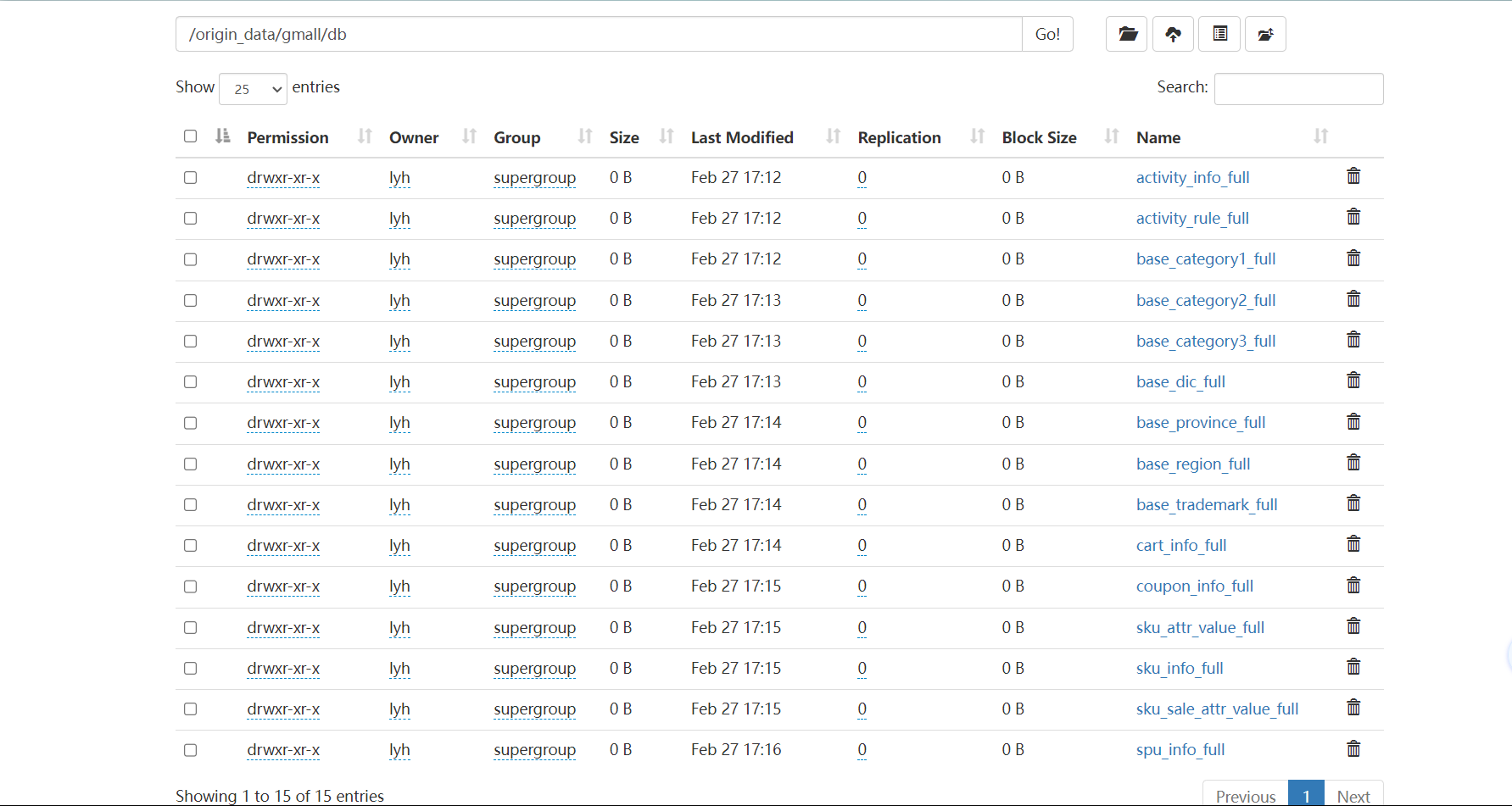
 我们共同步了 15 张表,通过这个命令可以看到,该目录下目录数为 31 除了本目录和子目录下的日期目录外刚好 15 个目录,文件数也刚好 15 个。
我们共同步了 15 张表,通过这个命令可以看到,该目录下目录数为 31 除了本目录和子目录下的日期目录外刚好 15 个目录,文件数也刚好 15 个。
2.2.5、增量数据同步
需要全量同步的表我们已经同步完了,接下来就剩增量同步的表了,比如一些订单表它会不断的生成数据。

1. Flume 配置
Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSink,Channel选用FileChannel。
需要注意的是, HDFSSink需要将不同mysql业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。关键配置如下:
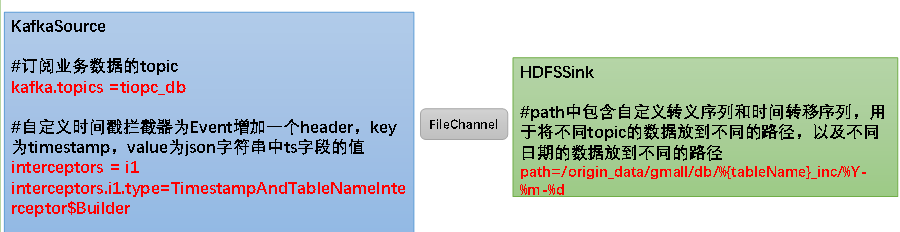
也就是说,首先,我们需要从 kafka 读取时,通过 flume 的拦截器给 Event 增加一个 header 信息,在这里把 json 时间信息(因为 Maxwell 是以 json 格式写到 Kafka 的)提取出来,为的是解决数据漂移的问题。
其次,在 hdfssink 中我们需要声明写入的文件目录,这个文件目录的格式必须和我们上面全量同步的格式一样,带有日期信息。

这里还需要注意的是,我们 flume kafka source 的 timestamp 字段需要的是一个 13 位的数据,但是我们 kafka 中的 ts 字段是一个 10 位的数字,所以我们在编写拦截器的时候需要把秒级别转为毫秒级别。
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = topic_db
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.lyh.gmall.interceptor.TimestampAndTableNameInterceptor$Buildera1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume-1.9.0/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume-1.9.0/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1souce 配置:
这里,我们设置 kafak.consumer.group.id = topic_db ,把这个参数值设置为业务名称,防止多个消费者冲突(因为 flume 默认的消费者组是 flume)。这里的 setTopicHeader = true 和 topicHeader = topic 指的是我们的 flume event 中 event header 的信息,这里的意思是设置数据头中包含 topic 的信息(这里的 key 就是 topic value 是 topic_db)。
channel 配置:
channel 这里需要注意的是就是检查点目录的名称不能和之前的冲突,之前我们在全量数据同步用户行为日志数据的时候,在 hadoop104 的 flume 作业中设置了检查点为 behavior1。

sink 配置:
这里除了设置输出的 hdfs 路径必须包含日期之外,主要就是滚动策略的配置,我们要防止小文件的问题。
编写拦截器:
package com.lyh.gmall.interceptor;import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;public class TimestampAndTableNameInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {// 1. 把 body 中的 timestamp 和 table 字段提取出来 放到 headerMap<String, String> headers = event.getHeaders();String log = new String(event.getBody(), StandardCharsets.UTF_8);// 2. 解析 log 中的 ts 和 table 字段JSONObject json = JSONObject.parseObject(log);String ts = json.getString("ts");String table = json.getString("table");// 3. 把 ts 和 table 字段放到 header 中的 tableName 和 timestamp 字段headers.put("tableName",table);headers.put("timestamp",ts + "000");return event;}@Overridepublic List<Event> intercept(List<Event> list) {for (Event event: list)intercept(event);return list;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new TimestampAndTableNameInterceptor();}@Overridepublic void configure(Context context) {}}}
打包放到 hadoop104 上 flume 的 lib 目录下,开始测试:
打通通道
myhadoop start
zk start
kf.sh start
mxw.sh start启动 flume 作业:
[lyh@hadoop104 flume-1.9.0]$ bin/flume-ng agent -n a1 -c conf/ -f job/warehouse/kafka_to_hdfs_db.conf -Dflume.root.logger=INFO,console模拟业务数据生成:
cd /opt/module/db_log/
java -jar gmall2020-mock-db-2021-11-14.jar查看 hdfs:

可以看到,其中带 inc 后缀的都是我们增量同步进来的数据。

增量同步文件数 = 总文件数 - 全量同步文件数 = 27 - 15 = 12 ,没有问题
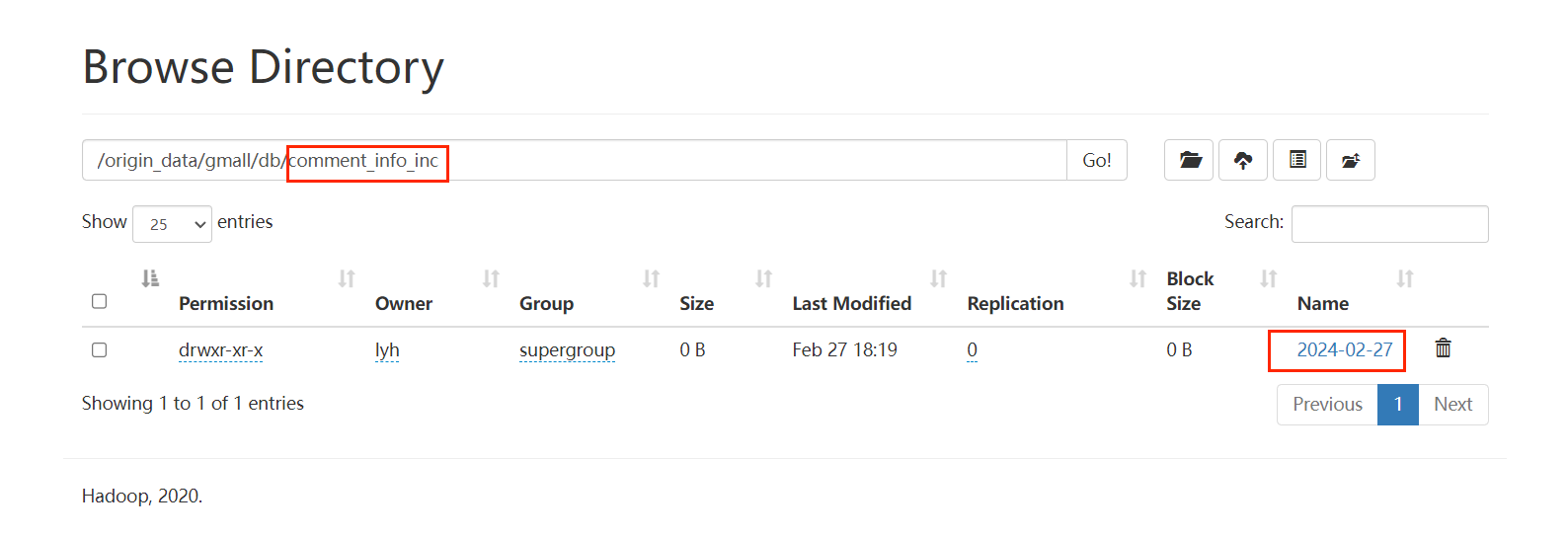
这里存在一个问题:我们之前在拦截器中设置了 event header 中的 timestamp 为 kafka 中的数据t ts 字段的时间信息,但是这里却依然是我们机器的时间,这是因为我们 java -jar 操作数据库的时间就是我们服务器当前的时间,所以导致 Maxwelll 读取 binlog 后的数据就是当前服务器的时间。具体解决办法看下面的 Maxwell 配置。
2. 编写增量数据同步脚本
vim f3.sh#!/bin/bashcase $1 in
"start")echo " --------启动 hadoop104 业务数据flume-------"ssh hadoop104 "nohup /opt/module/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.9.0/conf -f /opt/module/flume-1.9.0/job/warehouse/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")echo " --------停止 hadoop104 业务数据flume-------"ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac3. Maxwell 配置
这里主要是解决时间戳的问题:
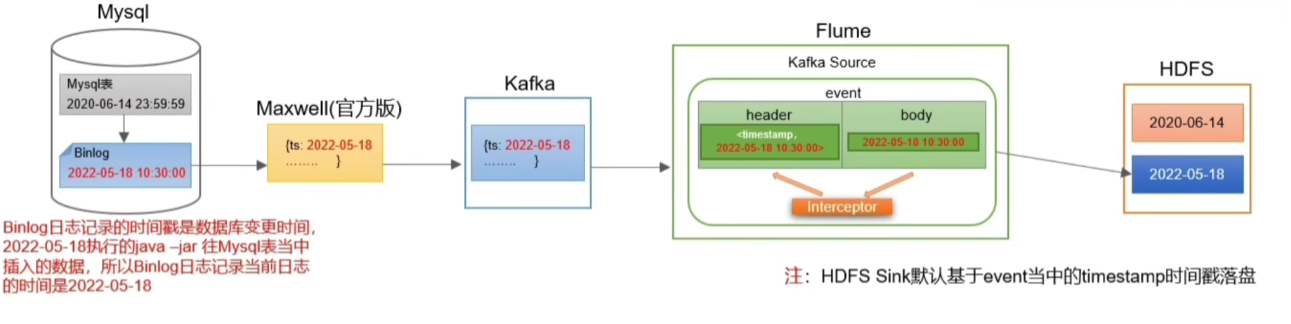
生产环境中是不会有这个问题的,这里我们用的是 经过修改源码的 Maxwell,所以只需要修改一下配置文件即可:
cd /opt/module/maxwell-1.29.2/
vim config.properties添加配置:
mock_date=2020-06-14
4. 增量表首日全量同步
增量表本来就存在一些数据,但是 Maxwell 在监听的 binlog 的时候是不知道的,所以我们还需要全量同步一次增量表中的历史数据。但是我们用哪个工具呢,我们知道,Maxwell 也可以做全量,DataX也可以。这里我们选择 Maxwell ,因为 DataX 同步到 HDFS 的文件是一个以特定字符分割的文件,而 Maxwell 同步到 HDFS 的文件是 json 格式的,所以我们肯定是希望保存到 HDFS 后的数据格式都是一致的,那我们就自然会联想到学习 Maxwell 说的 bootstrap,它是 Maxwell 的一张元数据表。
编写初始化脚本:
vim mysql_to_kafka_inc_init.sh#!/bin/bash# 该脚本的作用是初始化所有的增量表,只需执行一次MAXWELL_HOME=/opt/module/maxwell-1.29.2import_data() {$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}case $1 in
"cart_info")import_data cart_info;;
"comment_info")import_data comment_info;;
"coupon_use")import_data coupon_use;;
"favor_info")import_data favor_info;;
"order_detail")import_data order_detail;;
"order_detail_activity")import_data order_detail_activity;;
"order_detail_coupon")import_data order_detail_coupon;;
"order_info")import_data order_info;;
"order_refund_info")import_data order_refund_info;;
"order_status_log")import_data order_status_log;;
"payment_info")import_data payment_info;;
"refund_payment")import_data refund_payment;;
"user_info")import_data user_info;;
"all")import_data cart_infoimport_data comment_infoimport_data coupon_useimport_data favor_infoimport_data order_detailimport_data order_detail_activityimport_data order_detail_couponimport_data order_infoimport_data order_refund_infoimport_data order_status_logimport_data payment_infoimport_data refund_paymentimport_data user_info;;
esac测试:
f3.sh start
mysql_to_hdfs_full_init.sh all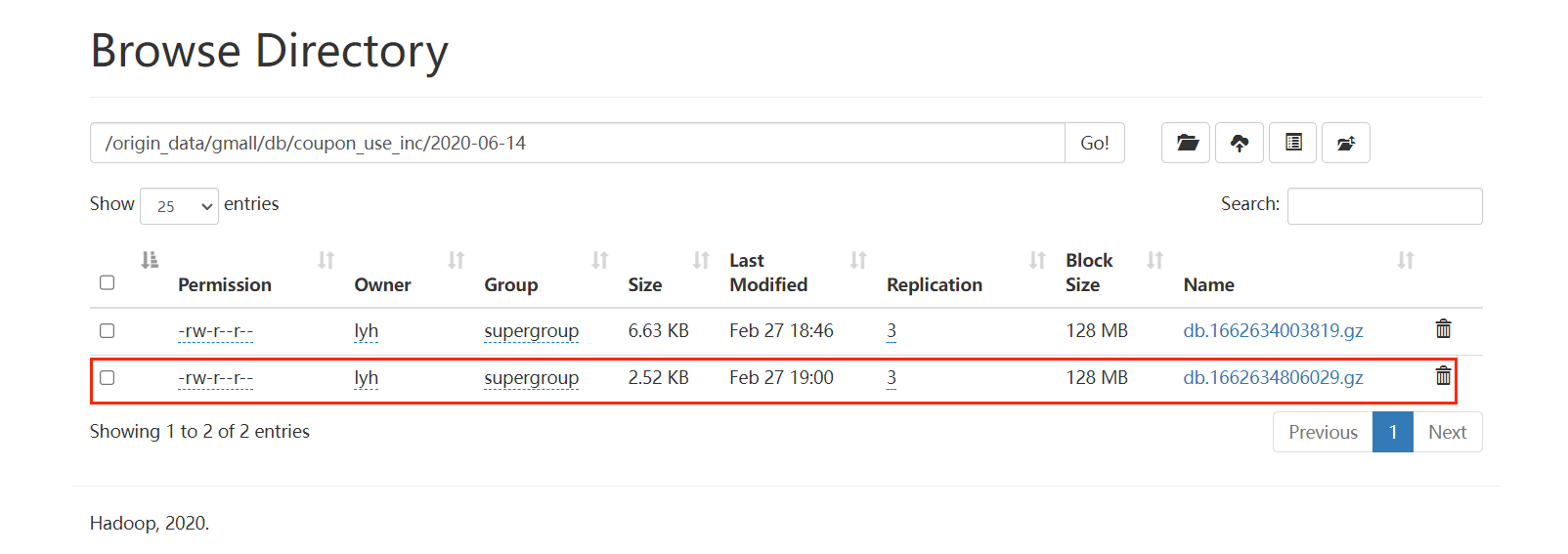
这里需要牢记 Maxwell 可以既做全量又做增量为什么还需要 DataX,这是因为 DataX 对于全量同步更加专业,因为它可以进行一些流控,而且支持更多的数据源并且支持并发。所以 Maxwell 只在初始化同步历史数据的时候用一下,所以不用担心它的性能问题。
2.3、采集通道启/停脚本
这里只是为了方便学习的时候用的,生产环境千万不敢用:
#!/bin/bashcase $1 in
"start"){echo ================== 启动 集群 ==================#启动 Zookeeper集群zk start#启动 Hadoop集群myhadoop start#启动 Kafka采集集群kf.sh start#启动采集 Flumef1.sh start#启动日志消费 Flumef2.sh start#启动业务消费 Flumef3.sh start#启动 maxwellmxw.sh start};;
"stop"){echo ================== 停止 集群 ==================#停止 Maxwellmxw.sh stop#停止 业务消费Flumef3.sh stop#停止 日志消费Flumef2.sh stop#停止 日志采集Flumef1.sh stop#停止 Kafka采集集群kf.sh stop#停止 Hadoop集群myhadoop stop#停止 Zookeeper集群zk stop};;
esac
总结
现在是2024-2-27 19:28 。
到这里,我们的数仓数据同步工作就都做完了,包括全量用户行为日志的同步(用户行为日志数据并没有增量同步)、增量业务数据的同步、全量业务数据的同步以及业务数据的历史数据初始化全量同步。
接下来就是关于数仓的知识的学习了,这部分也将是最最重要的!不管是理论还是建模方法和编程实践。
今天额外的好消息就是四级终于过了,这就剩下了很多时间去专心技术啦!


![[HackmyVM]靶场 Azer](https://img-blog.csdnimg.cn/direct/e09d0b346e634b3b9ec057c982739e97.png)