目录
- Redis的修改配置启动以及参数调优
- Redis的常用基本操作
- Redis运维监控命令
- Redis的配置的动态更新和写入
- Redis的多用户管理
- Redis的慢日志
- Redis禁用危险命令和压测工具
- Redis持久化存储
- 1.Redis的RDB持久化存储
- 2.Redis的AOF持久化存储
- Redis的主从复制
- redis的哨兵实现主从自动切换
- 搭建redis的主从实验
- redis cluster集群搭建和高可用故障切换演示
- 增加搭建3从集群,实现redis高可用
- redis cluster集群增加节点和删除节点
Redis的修改配置启动以及参数调优
Redis配置简化
cp /etc/redis.conf /etc/redis.conf.bak
sed -i "/^#/d; /^$/d' /etc/redis.conf #把配置文件中#和空格删除掉
Redis配置更改
vim /etc/redis.conf
bind 0.0.0.0 #注意公网开放时候,尽量不要监听所有网卡ip,一般就配置自己业务
port 6379
dir /data/redis #存放数据的目录
requirepass redispwd #验证密码
pidfile "redis.pid" #默认会在dir配置路径的当前路径下
logfile "redis.log" #日志文件的位置,可修改
daemonize yes #以后台进程启动
启动redis:
#redis-server /etc/redis.conf
Redis启动的系统参数调整
调整最大文件打开数(文件句柄)vim /etc/security/limits.conf
* - nofile 65535 退出终端重新登录生效 ulimit -n 查看
内核参数修改
vim /etc/sysctl.conf
net.core.somaxconn = 10240 #调大somaxconn参数
vm.overcommit_memory = 1 #这个如果没修改,可能会引起redis的数据丢失,参数很
然后运行sysctl -p刷新生效
重启redis,查看日志,观察优化后的情况,报错告警都消失
pkill redis
redis-server /etc/redis.conf
tail -f /data/redis/redis.log
如果redis是源码编译安装的话,是不能用systemctl管理的,就要进行一下配置,而yum安装就没有这些问题了
Systemctl管理Redis:
vim /usr/lib/systemd/system/redis.service
[Unit]
Description=redis
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /etc/redis.conf
[Install]
WantedBy=multi-user.target
systemctl daemon-reload #加载改配置文件
Redis的常用基本操作
1.redis-cli使用和认证登录
客户端工具redis-cli登录
redis-cli #默认127.0.0.1 6379
redis-cli -h redis的ip
redis-cli -h xxx -p xXX
redis的认证
>auth redispwd #登录redis后做认证
redis-cli -a redispwd #登录+认证
redis的几种数据类型:
字符串;列表;集合
Redis运维监控命令
1).查看key
RANDOMKEY #随机获取一个key
KEYS * #查看所有key,注意阻塞,如果key量特别大时候,容易卡死阻塞,上千万上百万时候容易阻塞
SCAN 0 #建议使用,每次获取11个key,可以循环获取,直到获取所有key#从编号0开始,中间会有一个编号提示(类似索引编号),按编号提示依次循环获取,直到编号为O即表示获取完所有的key
使用Shell批量写入数据并获取
for i in $(seq-w 50);do redis-cli -a redispwd set name${i]}test${i}; redis-cli -a redispwd get name$(1); done 2>/dev/null
2).监控命令
redis-cli -a redispwd --stat #监控Redis状态
显示多少个key(是把所有数据库的key都加起来)内存占用多少客户端有多少redis的requests请求数是多少connections是多少连接
–多几个客户端,多增加几个key就可以马上发现
redis-cli -a redispwd monitor #监控数据操作
交互式阻塞状态,当有对数据进行操作时候会记录
–操作的命令,增加,删除数据等都会监控到
redis-cli -a redispwd info #查看相关信息
Redis的配置的动态更新和写入
动态更新密码
Redis的多用户管理
ACL LIST #列出所有用户,默认用户是default
ACL getuser default #查看default用户的相关信息,default对所有key,所有命令均有权限,最高权限,是默认用户
127.0.0.1:6379> ACL CAT #查看用户的权限1) "keyspace"2) "read"3) "write"4) "set"5) "sortedset"6) "list"7) "hash"8) "string"9) "bitmap"
10) "hyperloglog"
案例:创建一个test用户,并为他分配读写的权限
127.0.0.1:6379> SET name1 n1
127.0.0.1:6379> SET name2 n2
127.0.0.1:6379> set k1 v1
127.0.0.1:6379> set k2 v2
127.0.0.1:6379> ACL SETUSER test on >testpwd ~name* +get #对name开头的key有读写权限
127.0.0.1:6379> ACL SETUSER test on >testpwd ~name* +@read
127.0.0.1:6379> ACL GETUSER test
验证登录,验证权限
[root@redhat ~]# redis-cli --user test --pass testpwd
127.0.0.1:6379> GET name1
"n1"
127.0.0.1:6379> GET k1
(error) NOPERM this user has no permissions to access one of the keys used as arguments
Redis的慢日志
问题:假如有人反馈redis慢,如何进行排查?
- 系统资源情况
- 查着慢日志情况
查看慢日志的默认配置
CONFIG GET slow* #查看慢日志的配置
- “slowlog-max-len”
- “128” #最多记录128个
- “slowlog-log-slower-than”
- “10000” #默认超过10毫秒就会记录
产生慢日志
KEYS * #查询一次(在数据量大的情况下不建议使用改命令)
KEYS *
…可以多查询几次,多获取几条慢日志
查询慢日志
SLOWLOG get #默认获取最近10条
SLOWLOG get 5 #获取5条
SLOWLOG len #慢日志量,查看慢日志的条数
SLOWLOG reset #清空慢日志
Redis禁用危险命令和压测工具
Redis危险的命令有哪些?
FLUSHALL 会清空Redis所有数据
FLUSHDB 会清除当前DB所有数据
KEYS * 在键过多的时候使用会阻塞业务请求,比如有上千万数据时候,该命令会阻塞卡住
Redis禁用危险命令的配置
禁用需要修改redis的配置文件,然后重启redis
vim /etc/redis.conf
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command KEYS ""
测试命令是否失效
keys*
发现运行不了
flushall
运行不了
Redis的压测工具
压测工具,基本对redis里的每一个命令都会进行测试一遍,
redis-benchmark -a redispwd #用默认的并发50个,一共10万个请求对redis进行压测
redis-benchmark -a redispwd | tee /tmp/a.log #将测试的结果输出到一个log文件
redis-benchmark -a redispwd -n 10
#用默认的并发50个,一共10个请求对redis进行压测
Redis持久化存储
Redis持久化存储的两种方式
RDB方式RDB存储是Redis实现的一种存储机制(默认开启)
AOF方式 AOF存储方式,直接把操作的命令记录下来,保存到一个文件里,类似mysql的binlog日志(默认关闭)
1.Redis的RDB持久化存储
Redis默认是开启了RDB快照方式,提供持久化存储的功能
如果只让Redis做缓存的服务,不需要持久化时候,也可以关闭所有存储功能
Redis的RDB存储方式的配置,默认是开启的
config get dir #查看存储设置的路径
1) "dir"
2)"/data/redis"
config get dbfilename #查看rdb存储的文件名,默认是dump.rdb文件
1 ) "dbfilename"
2) "dump.rdb"
#该文件可以保证redis的数据不丢失
config get save #查看rdb默认的存储机制配置
3600 1 300 100 60 10000#3600s(1个小时)1(key的一个变化)300(5分钟)100(key的变化) 60s(1分钟)10000(key的变化)key的变化越快,保存的就越频繁。60s中 key变化了10000个,那么我1分钟就会给你存上,1小时才变化一个key,就1小时给你存一次更新得越频繁,保存得越频繁。另外,关闭redis服务器会立马触发rdb存储
通过修改配置文件关闭rdb持久化;
#vim /etc/redis.conf
save "" #添加注释下面的
#save 3600 1
#save 300 100
#save 60 10000
删除dump.rdb文件后,重启服务,添加数据,再退出重启服务,发现数据没有被保存
2.Redis的AOF持久化存储
AOF存储默认是关闭的
AOF存储是把命令直接写入到文件中,文件会不断扩大
1).开启AOF前先关闭RDB(一般建议关闭,持久化存储用其中一种就行),也能同时配置,同时配置AOF优先生效
vim /etc/redis.conf
取消掉
save ""
#添加
#注释下面的:
#save 3600 1
#save 300 100
#save 60 10000
开启AOF
修改 redis.conf 配置文件:
- 通过修改redis.conf配置中`appendonly yes`来开启AOF持久化
- 通过appendfilename指定日志文件名字(默认为appendonly.aof)
- 通过appendfsync指定日志记录频率
Redis的主从复制
1.Redis单台服务器时的缺点
1、如果持久化,单台数据有丢失风险
2、读写压力都集中在一台上
2.Redis的主从复制概念
Redis的主从就是多台Redis数据一致
主服务器可用来写入和读取,从服务器仅用来读取,可以通过读写分离,降低写服务器的压力
3.Redis的主从搭建
主redis的配置:
vim /etc/redis.conf
除了默认配置外,需要确定一下下面的配置:
bind 0.0.0.0
port 6379
dir "/data/redis" 数据目录
requirepass "redispwd" 登录验证密码
pidfile "redis.pid" pid文件
logfile "redis.log" 日志文件
daemonize yes 是否允许后台运行
从redis的配置:
vim /etc/redis.conf
除了默认配置外,需要确定一下下面的配置
bind 0.0.0.0
port 6379
dir "/data/redis"
requirepass "redispwd" #从redis自己的密码,一般也和主设置的相同
pidfile "redis.pid"
logfile "redis.log"
daemonize yes
#注意:从redis需要增加下面这两项:
slaveof 192.168.27.128 6379 #指定主redis的ip和端口
masterauth "redispwd" #指定主redis的密码
4、主从redis的启动:
启动主redis: # redis-server /etc/redis.conf
启动从redis: # redis-server /etc/redis.conf
验证redis主从:在主redis上写入数据,在从redis上查看数据是否能同步过来
redis的哨兵实现主从自动切换
127.0.0.1:6379> info #info命令可查看相关的信息
2.哨兵Sentinel实现主从自动
Redis主从配置后,当主挂掉后,业务会有异常
Redis提供Sentinel工具实现主从自动切换,实现redis的高可用
Sentinel的启动和观察
#redis-sentinel /etc/sentinel.conf
主挂掉后,从库自动提升为主库主恢复后,自动转为从库,预防来回切换。
要求主从都需要设置masterauth 连接主redis的密码
因为是高可用模式,主也有可能宕机,当它宕机后,即使再恢复后也是作为从角色,为了防止作为从角色时候,连接主时候认证不了,需要提前加上连接主服务器的认证密码
3.哨兵Sentinel高可用模式搭建(1主2从3哨兵)
为了防止哨兵的单节点故障,一般哨兵也做成高可用形式,即多个哨兵同时监控redis的状态,当其中于个哨兵故障时候,其他哨兵也能继续监控,为了方便哨兵的选举,一般哨兵也是设置成奇数个。一般3个哨兵就没问题。
注意:一般哨兵的部署尽量不要和redis部署在同一台,防止这一台机器挂了后,redis和哨兵同时挂掉,哨兵起不到哨兵的作用了。当然多台机多个哨兵时候也不影响,一台哨兵挂了,还有其它哨兵。
规划:
192.168.27.128主redis哨兵1
192.168.27.129 从1redis哨兵2
192.168.27.130从2redis哨兵3
搭建redis的主从实验
1).先搭建redis的主从(1主2从)
注意:主redis上配置文件中也需要加上配置:因为是高可用模式,主也有可能宕机,当它宕机后,即使再恢复后也是作为从角色为了防止作为从角色时候,连接主时候认证不了,需要提前加上连接主服务器的认证密码
2).配置3哨兵
vim /etc/sentinel.conf #3个哨兵机器配置都一样,可用scp命令复制过去
bind 0.0.0.0
daemonize yes
port 26379
dir "/tmp"
logfile "sentinel.log"
sentinel monitor testmaster 192.168.27.128 6379 2
sentinel auth-pass testmaster redispwd
sentinel down-after-milliseconds testmaster 5000
sentinel failover-timeout testmaster 18000
配置文件说明:
#port 26379哨兵的一个端口
#testmaster是随便起的一个名字,连接的主redis的是:192.168.27.128,2是代表有2个哨兵认为master有问题才会切换
#redispwd是连接主redis的密码,5000是5秒没响应认为主挂了
#18000是从提升为主的超时时间18s(可适当调大)
3).启动3哨兵
redis-sentinel /etc/sentinel.conf 3台都是指定配置文件启动# ps -ef |grep sentinel 3台查看进程
4).验证哨兵实现的高可用redis
a).停止主redis服务 192.168.27.128机器停止主redis
systemctl stop redis
b).查看从2redis的配置文件也自动修改成了指定了新主的ip(哨兵模式让配置文件会帮我们自动修改)
c).当主redis恢复,自动作为从服务器,指向新的主redis
redis cluster集群搭建和高可用故障切换演示
1.Redis主从模式和cluster分片集群区别
redis主从模式,是所有Redis数据一致,但是key过多了会影响性能
cluster分片集群,可以将数据分散到多个Redis节点,数据分片存储,能够提高redis的吞吐量
2.Redis Cluster集群特点
数据分片
多个入口
故障自动切换
3.Redis cluster集群的搭建架构
Redis集群至少需要三主三从
三从是保证主有问题时能够切换
(Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器)
4.Redis自带集群搭建
a).目录和机器规划:
三主:192.168.85.133:7000 192.168.85.134:7001 192.168.85.128:7002
三从: 192.168.27.128:8000(7002的从)192.168.27.129:80d(7000的从) 192.168.27.130:8002(7001的从)
(2).创建3主集群,在任何一个节点上操作都可以
做实验之前,防火墙需要关闭
[root@localhost ~]# mkdir redis-7000 创建redis的配置目录,一台主机上创建2个,模拟两个redis实例,以这种方式创建其他的目录
[root@localhost ~]# cp -p /etc/redis/redis.conf redis-7000/ #把自带的配置copy过来
[root@localhost ~]# cp -p /etc/redis/redis.conf redis-7000/
[root@localhost ~]# sed -i '/^#/d;/^$/d' redis-7000/redis.conf #这是为了删除注释,空格等信息。
vim redis-7000/redis.conf
bind 0.0.0.0
port 7001
requirepass "redhat"
masterauth "redhat"
protected-mode yes
port 7001
daemonize yes 后台运行
cluster-enabled yes 开启集群
dir "redis_data" 数据目录[root@localhost ~]# scp redis-7000/redis.conf root@192.168.85.128:/root/redis-7002 通过scp把配置文件传到其他主机上
==进入redis配置文件的目录下启动==
[root@localhost ~]# redis-server redis.conf 以其他配置文件运行
[root@localhost redis-7001]# ps -ef | grep redis 检查redis启动成功没有
[root@localhost ~]# redis-cli -a redhat --cluster create 192.168.85.133:7000 192.168.85.134:7001 192.168.85.128:7002 ----》创建集群
注意:在这里需要注意的是,配置其实跟主从复制的配置差不多,需要注意的就是端口和cluster-enabled yes要打开,并且daemonize yes也要打开,这是后台运行的方式,里面的日志文件,pid文件可以随便改,但是dir 这个数据目录必须得先创建,不然启动不了。
supervised systemd 给这个注释掉,出现以下错误
1639:M 01 Feb 2024 08:42:09.056 # systemd supervision error: NOTIFY_SOCKET not found!
1639:M 01 Feb 2024 08:42:09.056 * Saving the final RDB snapshot before exiting.
1639:M 01 Feb 2024 08:42:09.056 # systemd supervision error: NOTIFY_SOCKET not found!

(3).查看3主集群:在任何一 个节点上操作都行,下 面以7000端口这个redis为例查看集群信息
redis-ci -a redispwd p 7000 cluster infor
redis-cli -a redispwd -p 7000 cluster nodes # 注意slot分配
(4).集群操作, 在集群中写入数据 在任何一个节点作为入口都可以,下面以133:7000端口的redis为例写入数据
集群操作需要加-c参数
redis-cli -p 7000 -a redispwd #不加-c参数,表示不是以集群方式写入,无法写入
redis-cli -p 7000 -a redispwd c #增加-c参数,表示是以集群方式写入,可以写入
演示:
[root@localhost ~]# redis-cli -a redhat -c -p 7000
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:7000> set k1 v1
-> Redirected to slot [12706] located at 192.168.85.128:7002
OK
192.168.85.128:7002> set k2 v2
-> Redirected to slot [449] located at 192.168.85.133:7000
OK
增加搭建3从集群,实现redis高可用
(1).先启动3个从redis 192.168.85.133:8000 192.168.85.134:8001 192.168.85.128:8002
跟上面的三个主集群的节点一样的操作,把redis服务先启动起来
(2)分别给3个主节点添加从库,在任何一节操作即可,下面以在133:7000的redis为例操作
别忘了上面的主从的规划,主要是为了避免一台机器坏了,主从都没了的原因。
redis-cli -a redhat -p 7000 cluster nodes #查看集群的各个节点状态和master-id
redis-cli -a redhat --cluster add-node --cluster-slave --cluster-master-id 7000的master-id 192.168.85.134:8001(从) 192.168.85.133:7000(主)
[root@localhost ~]# redis-cli -a redhat --cluster add-node --cluster-slave --cluster-master-id c00652087cdc8c9d7537563949f0780e3350cacd 192.168.85.134:8001 192.168.85.133:7000
[root@localhost ~]# redis-cli -a redhat --cluster add-node --cluster-slave --cluster-master-id 86a81b6f4fb4aebbdef19d1668e031d82207b5c5 192.168.85.128:8002 192.168.85.134:7001
[root@localhost ~]# redis-cli -a redhat --cluster add-node --cluster-slave --cluster-master-id eda711f63ded3ab7f8fd5967c9a2c3aa187cf4d8 192.168.85.133:8000 192.168.85.128:7002
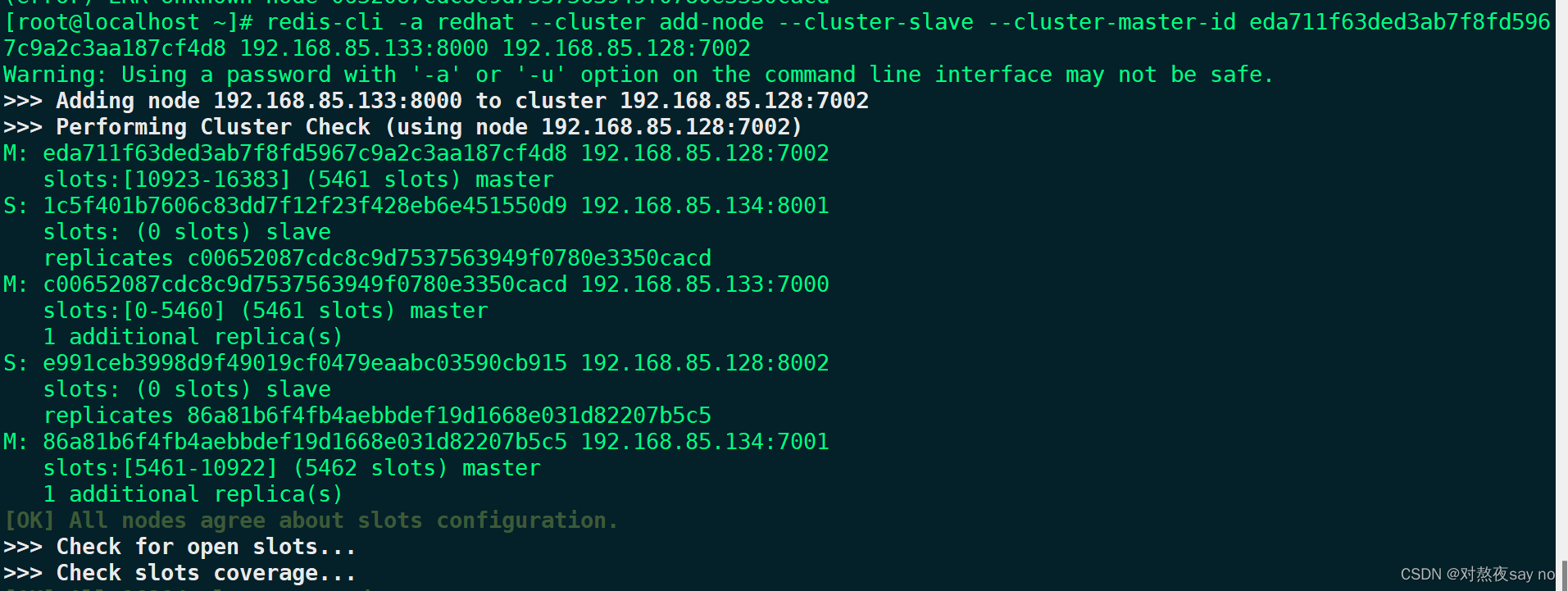
查看各个节点
[root@localhost ~]# redis-cli -a redhat -p 7000 cluster nodes
从库手动提升为主库的方法,登录到从库: CLUSTER FAILOVER
该实验就完成了,实验结果:某个主节点挂掉之后,从节点会在一定的时间内提升为主节点,主节点的数据就会在从节点被显示出来,如果挂掉的主节点恢复之后,那它将会成为从节点,可以通过手动提库的方法把他变成主节点,之后查到的数据就是主节点的了。
redis cluster集群增加节点和删除节点
1、增加一个主从节点:
IP地址:192.168.85.129/24
以7003为主节点,8003为从节点
配置跟上面一样的,先把redis服务启动起来!
完成:
[root@manged redis-8003]# ps -ef |grep redis
root 3158 1 0 14:50 ? 00:00:00 redis-server 0.0.0.0:7003 [cluster]
root 3197 1 0 14:52 ? 00:00:00 redis-server 0.0.0.0:8003 [cluster]
root 3203 1619 0 14:52 pts/0 00:00:00 grep --color=auto redi
2、在redis集群中加入一个新的主节点(在任意一台集群的节点操作即可,此处在133:7000的节点操作)
注意在集群的节点上操作改命令
redis-cli -a redhat --cluster add-node新节点ip:新节点端口 集群任意主节点ip:集群任意主节点对应端口
[root@localhost ~]# redis-cli -a redhat --cluster add-node 192.168.85.129:8003 192.168.85.133:7000
2、在redis集群中加入一个新的从节点(在任意一台集群的节点操作即可,此处在133:7000的节点操作)
redis-cli -a redhat --cluster add-node --cluster-slave --cluster-master-id 00585d07fb653e86e6ff75180f7d1097c8353301 192.168.85.129:8003 192.168.85.129:7003
查看集群节点信息:发现新增加主从节点没有问题,原来主节点都分配了槽位,但新主节点没有分配槽位,所以也不会有数据
redis-cli -a redispwd -p 7000 cluster nodes
3.给新加主redis分配槽位(在集群中任何一个节点操作即可,此处以133:7000节点上操作)
注意槽位分配,可以将某个节点槽位分到新节点,也可将所有主节点再做一个平均分配,此处是从133:7000主节点的槽位移动到新主节点- -部分) redis-cli -a redispwd --cluster reshard 192.168.27.133:7000 #连接集群中任意一个节点的redis