01 Python操作Kafka基础教程
创建ZooKeeper容器
docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper
创建Kafka容器
语法是:
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=[你的IP地址]:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://[你的IP地址]:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
我的虚拟机IP是192.168.31.86,所以我的命令是:
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.31.86:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.31.86:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
安装可视化工具
下载UI工具:https://kafkatool.com/download2/offsetexplorer_64bit.exe
下载好以后按照默认进行安装。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
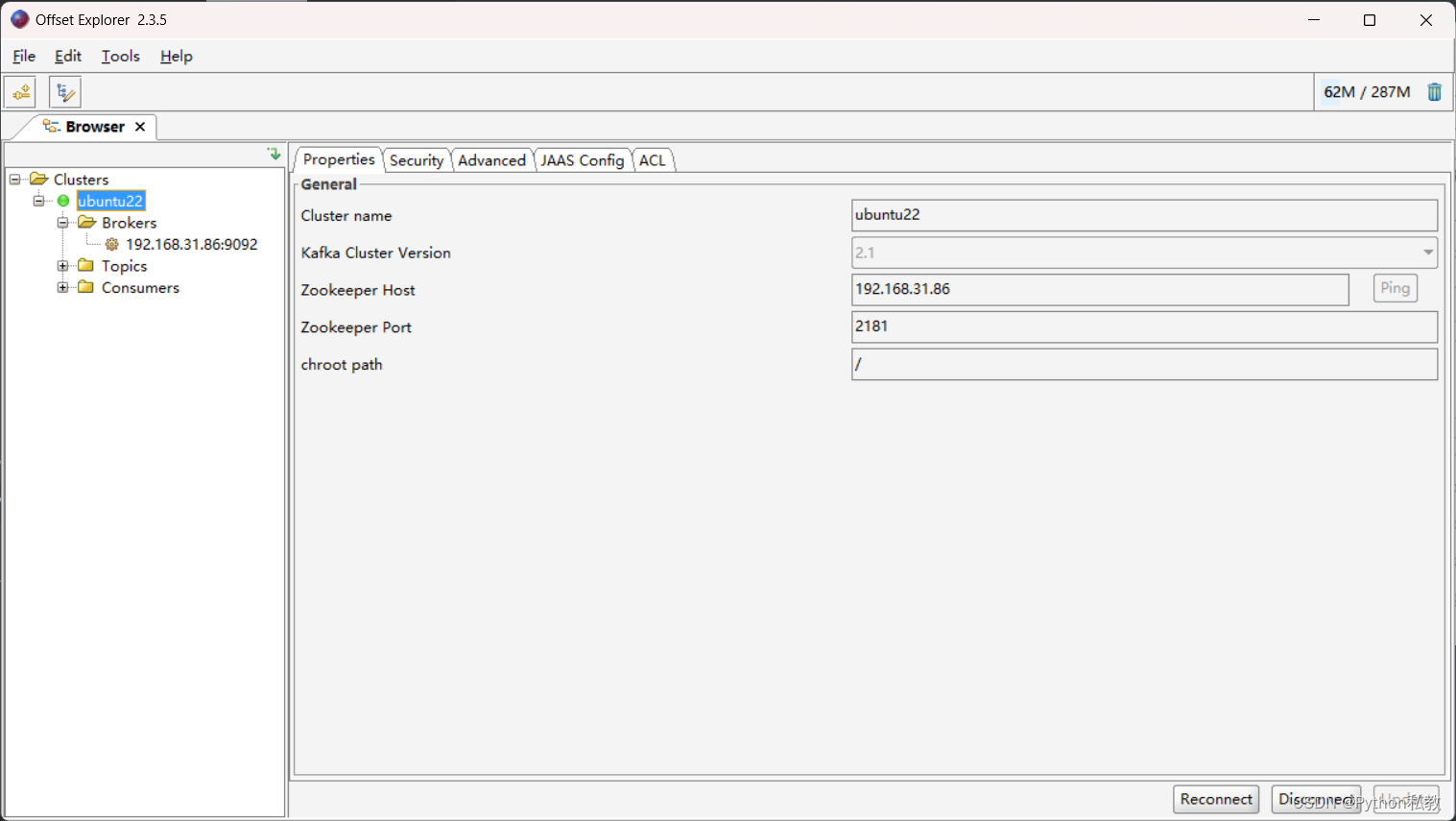
连接Kafka
搜索软件并打开:
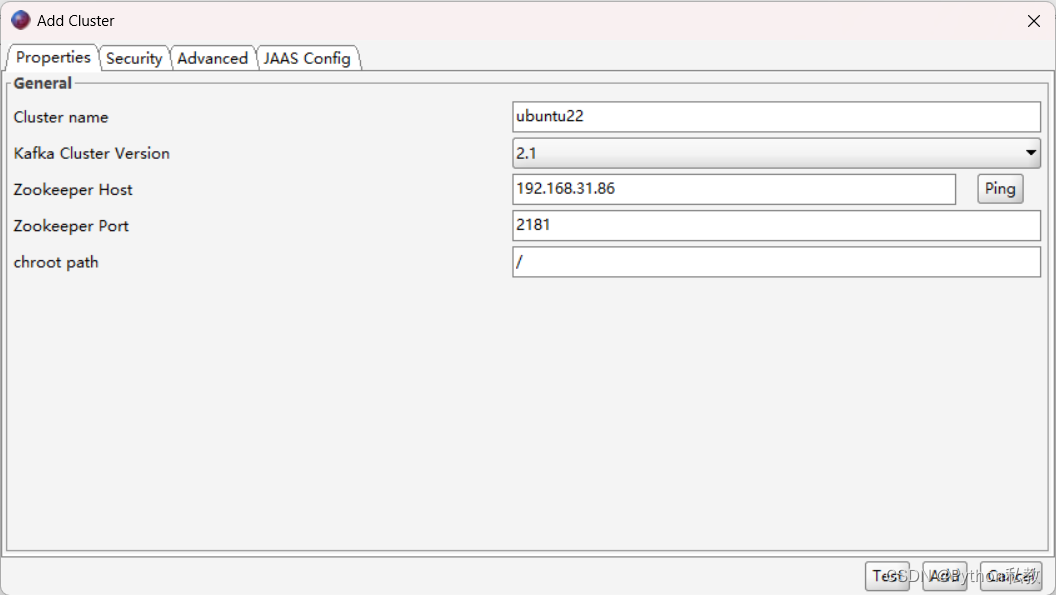
配置zookeeper:
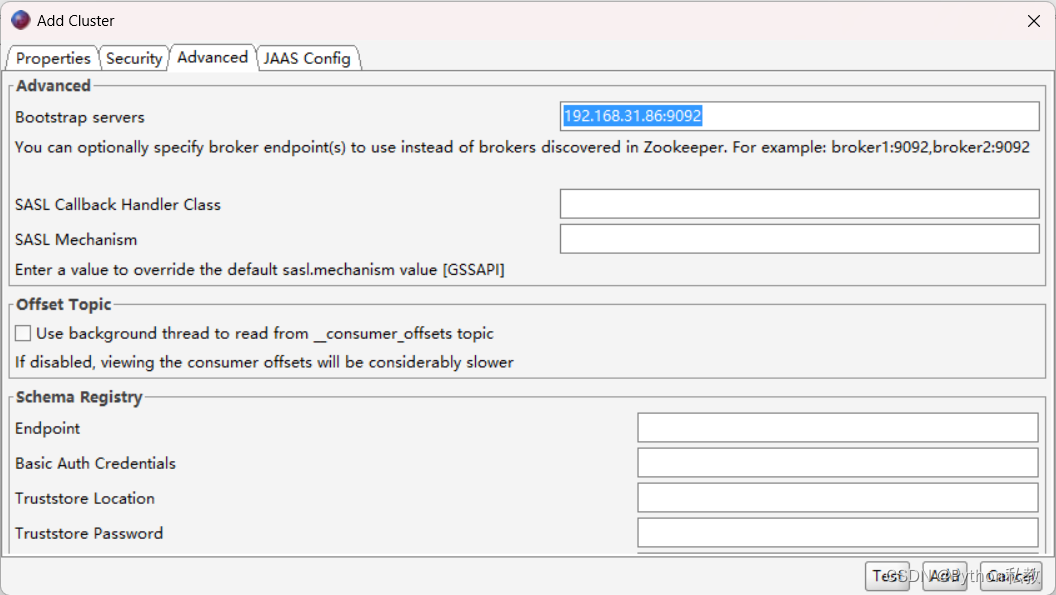
配置Kafka:
点击Test测试按钮,测试是否能够连接Kafka:
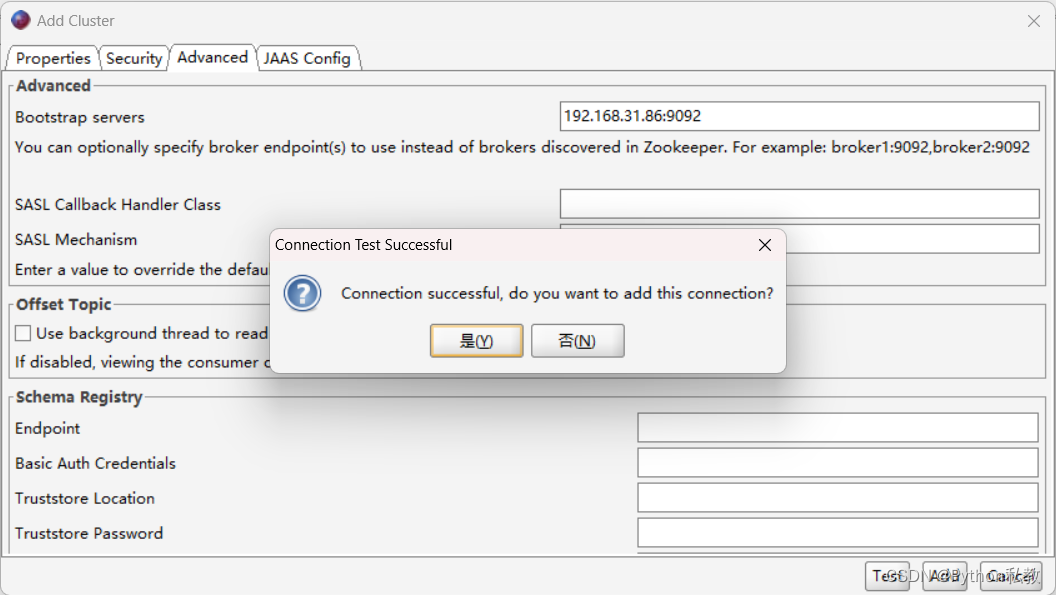
点击是,然后就成功的使用客户端连接上Kafka了。
安装依赖
安装Python3.8
安装:
pip install kafka-python==2.0.2
发布和消费json数据
生产者
from kafka import KafkaProducer
import json# 创建生产者
producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'),bootstrap_servers=['127.0.0.1:9092']
)# 要提交的消息
msg_dict = {"operatorId": "test", # 公交公司ID"terminalId": "123", # 设备Id"terminalCode": "123", # 设备编码(使用车辆ID)"terminalNo": "1", # 同一车辆内terminal序号从1开始
}# 向指定的主题发送消息
producer.send("text1", msg_dict)
producer.close()
消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer('text1', bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
for msg in consumer:print(msg.value.decode())
发布和消费文本数据
生产者
from kafka import KafkaProducer# 创建生产者
producer = KafkaProducer(value_serializer=lambda v: v.encode('utf-8'),bootstrap_servers=['127.0.0.1:9092']
)# 向指定的主题发送消息
producer.send("text1", "你好")
producer.close()消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer('text1', bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
for msg in consumer:print(msg.value.decode())发布和消费键值对文本数据
生产者
from kafka import KafkaProducer# 创建生产者
producer = KafkaProducer(key_serializer=lambda v: v.encode('utf-8'),value_serializer=lambda v: v.encode('utf-8'),bootstrap_servers=['127.0.0.1:9092']
)# 向指定的主题发送消息
producer.send("text1", key="msg", value="你好")
producer.close()消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer('text1', bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
for msg in consumer:print("key=", msg.key.decode())print("value=", msg.value.decode())发布和消费键值对JSON数据
生产者
from kafka import KafkaProducer
import json# 创建生产者
producer = KafkaProducer(key_serializer=lambda v: json.dumps(v).encode('utf-8'),value_serializer=lambda v: json.dumps(v).encode('utf-8'),bootstrap_servers=['127.0.0.1:9092']
)# 向指定的主题发送消息
key = {"a": 1}
value = {"b": 2}
producer.send("text1", key=key, value=value)
producer.close()消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer('text1', bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
for msg in consumer:print("key=", msg.key.decode())print("value=", msg.value.decode())发布和消费压缩文本数据
生产者
from kafka import KafkaProducer# 创建生产者
producer = KafkaProducer(value_serializer=lambda v: v.encode('utf-8'),bootstrap_servers=['127.0.0.1:9092'],compression_type='gzip', # 通过此参数声明要压缩数据传输
)# 向指定的主题发送消息
producer.send("text1", "你好")
producer.close()消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer('text1', bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
for msg in consumer:print(msg.value.decode())同时消费多个主题
生产者
from kafka import KafkaProducer# 创建生产者
producer = KafkaProducer(value_serializer=lambda v: v.encode('utf-8'),bootstrap_servers=['127.0.0.1:9092']
)# 向指定的主题发送消息
producer.send("text1", "你好")
producer.send("text2", "你好")producer.send("text1", "你好1")
producer.send("text2", "你好1")producer.send("text1", "你好2")
producer.send("text2", "你好2")producer.close()消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer(bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
consumer.subscribe(["text1", "text2"])
for msg in consumer:print(msg)print(msg.topic)print(msg.value.decode())获取发布结果
生产者
from kafka import KafkaProducer# 创建生产者
producer = KafkaProducer(value_serializer=lambda v: v.encode('utf-8'),bootstrap_servers=['127.0.0.1:9092']
)# 向指定的主题发送消息
feature = producer.send("text1", "你好")# 会阻塞,直到发送成功
print(feature.get(timeout=60))producer.close()消费者
from kafka import KafkaConsumer# 创建消费者
consumer = KafkaConsumer("text1", bootstrap_servers='127.0.0.1:9092')# 不停的消费数据
for msg in consumer:print(msg.topic)print(msg.value.decode())