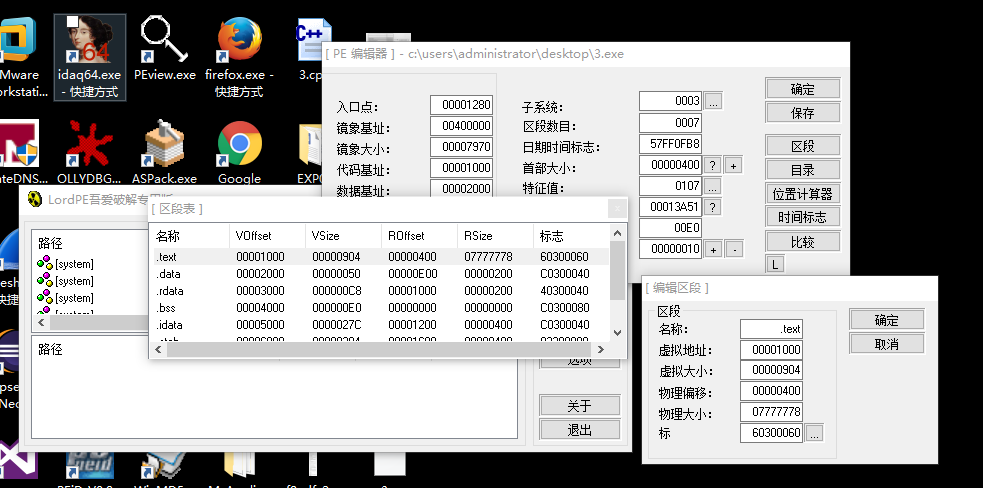
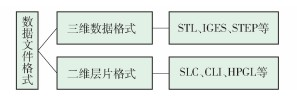
1. 对程序来说CPU是什么
问题:
- 程序是什么?
指示计算机每一步动作的一组指令 - 程序是由什么组成的?
指令和数据 - 什么是机器语言?
CPU可以直接识别并使用的语言 - 正在运行的程序存储在什么位置?
内存 - 什么是内存地址?
内存中,用来表示命令和数据存储位置的数值 - 计算机的构成元件中,负责程序的解释和运行的是哪个?
CPU负责解释和运行最终转换成机器语言的程序内容
1.1 CPU 的内部结构解析
芯片制作流程-视频揭秘芯片是怎样炼成的

图1-1 程序运行流程示例
寄存器: 暂存指令、数据等处理对象
控制器: 把内存上的指令、数据等读入寄存器
运算器: 运算从内存读入寄存器的数据
时钟: 负责发出CPU开始计时的时钟信号

图1-2 CPU的四个构成部分
1.2 CPU 是寄存器的集合体
了解寄存器的意义:程序是把寄存器作为对象来描述的
汇编: 将汇编语言编写的程序转化成机器语言的过程
反汇编: 机器语言程序转化成汇编语言程序的过程
编译: 高级编程语言编写的程序转换为机器语言的过程
编译器: 用于将高级语言转换为机器语言的转换程序
CPU 程序处理流程:
- 高级语言程序编译后转化成机器语言
- 通过CPU内部的寄存器来进行运算和存储处理
表1-1 寄存器的主要种类和功能
| 种类 | 功能 |
|---|---|
| 累加寄存器 | 存储执行运算的数据和运算后的数据 |
| 标志寄存器 | 存储运算处理后的 CPU 的状态 |
| 程序计数器 | 存储下一条指令所在内存的地址 |
| 基址寄存器 | 存储数据内存的起始地址 |
| 变址寄存器 | 存储基址寄存器的相对地址 |
| 通用寄存器 | 存储任意数据 |
| 指令寄存器 | 存储指令,CPU内部使用,无法通过程序对该寄存器进行读写操作 |
| 栈寄存器 | 存储栈区域的起始地址 |
CPU 是寄存器的集合体
 图 1-3 程序员眼中的 CPU(CPU是寄存器的集合体)
图 1-3 程序员眼中的 CPU(CPU是寄存器的集合体) 1.3 决定程序流程的程序计数器
- CPU 每执行一个指令,程序计数器的值就会自动加1
- CPU 的控制器会参照程序计数器的数值,从内存中读取命令并执行
1.4 条件分支和循环机制
顺序执行: 按照地址内容的顺序执行指令条件分支: 根据条件执行任意地址的指令循环: 重复执行同一地址的指令
1.5 函数的调用机制
函数调用处理: 是通过把程序计数器的值设定成函数的存储地址来实现的call指令: 会把调用函数后要执行的指令地址存储在名为栈的主存内return命令: 把保存在栈中的地址设定到程序计数器中

图 1-4 程序调用函数示例
1.6 通过地址索引和索引实现数组
- 使用
基址寄存器和变址寄存器对主存上特定的内存区域划分,实现类似于数组的操作 - CPU 会把基址寄存器+变址寄存器的值解释为实际查看的内存地址
- 变址寄存器的值相当于高级编程语言程序中数组的索引功能

图1-5 综合使用地址和索引来决定实际地址
1.7 CPU 的处理其实很简单
表1-2 机器语言指令的主要类型和功能
| 类型 | 功能 |
|---|---|
| 数据转送指令 | 寄存器和内存、内存和内存、寄存器和外围设备之间的数据读写操作 |
| 运算指令 | 用累加寄存器执行算术运算、逻辑运算、比较运算和移位运算 |
| 跳转指令 | 实现条件分支、循环、强制跳转等 |
| call/return指令 | 函数的调用 / 返回调用前的地址 |
2. 数据是用二进制数表示的
问题:
- 32 位是几个字节?
4字节 - 二进制数
01011100转换成十进制是多少?
92 - 二进制数
00001111左移两位后,会变成原数的几倍?
4倍 - 补码形式表示的8位二进制数
11111111,用十进制数表示的话是多少?
-1 - 补码形式表示的8位二进制数
10101010,用16位二进制数表示的话是多少?
1111111110101010 - 反转部分图形模式时,使用的是什么逻辑运算?
XOR运算
在C和Java等高级语言编写的程序中,数值、字符串和图像等信息在计算机内部都是以二进制数值的形式来表现的
2.1 用二进制数表示计算机信息的原因
- 计算内部是由 IC 这种电子部件构成的
- CPU 和内存也是 IC 的一种
- IC 所有的引脚只有直流电压 0V 或 5V 两个状态,即IC的一个引脚,只能表示两个状态
 图 2-1 IC 的一个引脚表示二进制的 1 位
图 2-1 IC 的一个引脚表示二进制的 1 位
2.2 什么是二进制数
十进制是以10为基数的计数方法,二进制是以2为基数的计数方法
2.3 移位运算和乘除运算的关系
- 二进制左移后会变成原来的2倍、4倍、8倍
- 二进制右移后会变成原来的1/2倍、1/4倍、1/8倍
2.4 便于计算机处理的”补数“
- 表示有符号数时,二进制的最高位为符号位
- 符号位为0表示正数,符号位为1表示负数
补数: 用正数表示负数- 计算机在做减法时实际上是用正数表示负数进行加法运算
补数求解的变换方法: 取反 + 1
2.5 逻辑右移和算术右移的区别
- 左移:低位补 0
- 右移:分为逻辑右移和算数右移
- 逻辑右移:高位补 0
- 算数右移:高位补符号位补充
- 符号扩充:以8位二进制数为例,在保持不变的前提下将器转化成16位和32位的二进制数。
- 实现符号扩充:用符号位填充高位
3. 计算机进行小数运算时出错的原因
3.1 将 0.1 累加 100 次得不到 10
float sum = 0;
for(i = 1; i <= 100; i++){sum += 0.1;
}
printf("%f\n",sum)// 10.000002
若要解释上述结果,需要了解计算机内部是如何处理小数的
3.2 用二进制数表示小数
将 1011.0011二进制小数转化为十进制数

图 3-1 二进制数小数转换成十进制数的方法
3.3 计算机运算出错的原因
有一些十进制小数如0.1无法转换成二进制小数
表3-1 小数点后4位能够用二进制数表示的数值,二进制数是连续的,十进制是非连贯的
| 二进制数 | 对应的十进制数 |
|---|---|
| 0.0000 | 0 |
| 0.0001 | 0.0625 |
| 0.0010 | 0.125 |
| 0.0011 | 0.1875 |
| 0.0100 | 0.25 |
| 0.0101 | 0.3125 |
| 0.0110 | 0.375 |
| 0.0111 | 0.4375 |
| 0.1000 | 0.5 |
| 0.1001 | 0.5625 |
| 0.1010 | 0.625 |
| 0.1011 | 0.6875 |
| 0.1100 | 0.75 |
| 0.1101 | 0.8125 |
| 0.1110 | 0.875 |
| 0.1111 | 0.9375 |
十进制数0.1转换成二进制后,会变成0.00011001100...(1100循环)这样的循环小数
同无法用十进制数表示1/3是一样的道理
3.4 什么是浮点数
浮点数指用符号、尾数、基数和指数四部分来表示的小数
计算机内部使用二进制数,所以基数为2

图 3-2 浮点数的表现形式(由符号、尾数、基数、指数四部分构成)
举例:像0.12345x10(3)和0.12345x10(-1)这样使用与实际小数点位置不同的书写方法来表示小数的形式称为浮点数
4. 熟练使用有棱有角的内存
问题:
- 有十个地址信号引脚的内存 IC 可以集成指定的地址范围是多少?
用二进制数来表示的话是 0000000000 ~ 1111111111 (用十进制数来表示的话是 0 ~ 1023) - 高级编程语言中的数据类型表示的是什么?
占据内存区域的大小和存储在该内存区域的数据类型 - 在32位内存地址的环境中,指针变量的长度是多少位?
32位 - 与物理内存有着相同构造的数组的数据类型长度是多少?
1字节 - 用LIFO方式进行数据读写的数据结构称为什么?
栈 - 根据数据的大小链表分叉成两个方向的数据结构称为什么?
二叉查找树
4.1 内存的物理机制很简单
内存: 实际上是一种名为内存IC的电子原件
-
内存包括 DRAM、SRAM、ROM 等多种形式,但从外部看,其基本机制都是一样的
-
内存IC中有电源、地址信号、数据信号、控制信号等用于输入输出的大量引脚(IC引脚),通过为其指定地址,来进行数据的读写

图 4-1 向内存 IC 中写入和读取数据的方法 -
通常情况下,计算机使用的内存IC中会有更多的地址信号引脚
-
内存IC内部有大量可以存储8位数据的地方,通过地址指定这些场所后即可进行数据的读写
4.2 内存的逻辑模型是楼房
- 编程语言中的数据类型表示存储的是何种类型的数据,从内存来看,就是占用的内存的大小
- 通过指定其类型(变量的数据类型等),也可以实现以特定字节数为单位来进行读写
低字节序: 把多字节数据的低位字节存储在内存低位地址的方式高字节序: 把数据的高位字节存储在内存低位的方式
4.3 简单的指针
指针:指针也是一种变量,所表示的不是数据的值,而是存储着数据的内存地址
char *d; //char 类型的指针 d 的定义
short *e; //short 类型的指针 e 的定义
long *f; //logn 类型的指针 f 的定义- 通过使用指针,可以对任意指定地址的数据进行读写

图 4-2 指针数据类型表示一次可以读写的长度
4.4 数组是高效使用内存的基础
数组: 指多个同样数据类型的数据在内存中连续排列的形式
4.5 栈、队列以及环形缓冲区
LIFO: 栈使用后入先出方式FIFO: 队列使用先入先出方式
4.6 链表使元素的追加何删除更容易
链表: 在数组的各个元素中,除了数据的值外,通过为其附带上下一个元素的索引,即可实现链表
4.7 二叉查找树使数据搜索更有效
-
二叉查找树: 在链表的基础上往数组中追加元素时,考虑数据的大小关系,将其分为左右两个方向的表现形式 -
若接下来的值比先前保存的数值大的话,就将其放到右边,否则放到左边
 图 4-3 二叉查找树的模型
图 4-3 二叉查找树的模型 -
使用二叉查找树时,当目标数据比现在读出来的数据小时,就可以转到左侧,反之目标数据较大时即可转到链表的右侧
5. 内存和磁盘的亲密关系
问题:
- 存储程序方式指的是什么?
在存储装置中保存程序,并逐一运行的方式 - 通过使用内存来提高磁盘访问速度的机制称为什么?
Disk Cache 磁盘缓存 - 把磁盘的一部分作为假想内存来使用的机制称为什么?
虚拟内存 - Windows 中,在程序运行时,存储着可以动态加载调用的函数和数据的文件称为什么?
DLL文件 - 在 EXE 程序文件中,静态加载函数的方式称为什么?
静态链接 - 在 Windows 计算机中,一般磁盘的1个扇区是多少字节?
512字节
重点:
- 计算机的5大部件:输入装置、输出装置、存储器、运算器和控制器
- 内存和磁盘都被归类为存储部件
- 内存:利用电流来实现存储
- 磁盘:利用磁效应来实现存储
- 从存储容量来看:内存高速高价,磁盘低速廉价
- 计算机系统中,高速小容量内存和低速高容量磁盘进行协同作业
- 下文中,内存主要指主内存(负责存储CPU中运行的程序指令和数据的内存),磁盘主要是指硬盘
5.1 不读入内存就无法运行
为什么程序必须要加载到内存后才能运行?- 负责解析和运行程序内容的CPU,需要通过内部的程序计数器来指定内存地址,才能读出程序
- 即使CPU可以直接读出并运行磁盘中保存的程序,由于磁盘读取速度慢,程序的运行速度还是会降低
5.2 磁盘缓存加快了磁盘访问速度
磁盘缓存: 把从磁盘中读取的数据存储到内存空间中的方式

图 5-1 磁盘缓存提高访问速度的机制
- 应用缓存实例:Web浏览器中使用缓存
- Web浏览器是通过网络来获取远程Web服务器的数据并将其显示出来的
- 在显示较大的图片等文件时,会花费不少时间
- Web浏览器把获取的数据暂时保存在磁盘中,在需要时再显示磁盘中的数据
- 即把低速的网络数据保存到相对高速的磁盘中
5.3 虚拟内存把磁盘作为部分内存来使用
-
磁盘缓存: 将内存当作磁盘来用 -
虚拟内存: 把磁盘的一部分作为假想内存来使用 -
虚拟内存的工作机制:正在运行的程序必须保存在内存中,为了实现虚拟内存,就必须把实际内存(物理内存)的内容,和磁盘上的虚拟内存的内容进行部分置换,并同时运行程序
-
Windows提供了虚拟内存机制作为操作系统,采用分页式虚拟内存方式
-
虚拟内存的方法有
分页式和分段式两种分页式: 在不考虑程序构造的情况下,把运行的程序按照一定大小的页进行分割,并以页为单位在内存和磁盘间进行置换Page In: 把磁盘的内容读出到内存Page Out: 把内存的内容写入磁盘
分段式: 把运行的程序分割成以处理集合及数据集合等为单位的段落,然后再以分割后的段落为单位在内存和磁盘之间进行数据置换

图 5-2 分页式虚拟内存的机制
-
查看windows虚拟内存的设定

图 5-3 查看虚拟内存的设定
5.4 节约内存的编程方法
- 虚拟机无法彻底解决内存不足问题:
- 磁盘虚拟内存能避免因内存不足导致应用无法启动的问题
- 使用虚拟内存时发生的
Page In和Page Out伴随着低速的磁盘访问 - 在这个过程中应用的运行会变得迟钝起来
- 为了从根本上解决内存不足问题,需要增加内存容量,或尽量把运行的应用文件变小
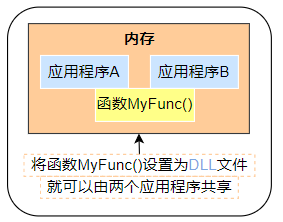
图 5-4 进行动态链接的话即可节约内存
- 把应用文件变小的编程方法:
- 通过
DLL文件实现函数共有DLL(Dynamic Link Library)文件:程序运行时课动态加载Library(函数和数据的集合)的文件- 多个应用可以共有同一个
DLL文件,达到节约内存的效果 - 可执行文件
.exe文件,动态链接库文件.dll文件 - 使用
DLL文件的一个优点是,可在不变更EXE文件的情况下,只通过升级DLL文件即可
- 通过调用
_stdcall来减小程序文件的大小
- 通过
5.5 磁盘的物理结构
- 软盘: 盘片上涂有一层磁性材料,是记录数据的介质
- 硬盘: 由一个或多个铝制或玻璃制的碟片组成,碟外覆盖有铁磁性材料

图 5-5 软盘 磁盘的物理结构: 指磁盘存储数据的形式,磁盘通过把其物理表面划分成多个空间来使用磁盘划分空间的方式: 扇区方式和可变长方式扇区方式: windows 所使用的硬盘和软盘采用的都是扇区方式磁道: 磁盘表面被分成若干同心圆的空间扇区: 磁道按固定大小(能储存的数据长度相同)划分成的空间

图 5-6 扇区方式的磁盘物理构造
- 扇区是磁盘进行物理读写的最小单位
簇: windows 在逻辑方面对磁盘进行读写的单位是扇区整数倍
补充:现在的电脑硬盘从C盘开始,因为A盘、B盘是DOS时代为软盘命名的,虽然现在已经不适用1.44M的软盘了,但是其命名却被保留了。
6. 亲自尝试压缩数据
问题:
- 文件存储的基本单位是什么?
1字节 - 文件内容用
数据的值 x 循环次数来表示的压缩方法是RLE算法还是哈夫曼算法?
RLE BMPBITMAP格式的图像文件是压缩过的吗?
没有压缩过- 可逆压缩和非可逆压缩的不同点是什么?
压缩后的数据能复原的是可逆压缩
如JPEG格式的压缩后不会让人感到不自然,是因为使用了非可逆压缩
6.1 文件以字节为单位保存
- 文件中存储数据的单位是字节
文本文件:文件中存储的数据是文字图像文件:文件中存储的数据是图形- 文件中字节数据都是连续存储的
6.2 RLE算法的机制
- RLE (Run Length Encoding,行程长度编码),常被用于压缩传真图像等
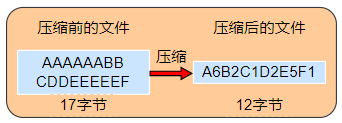
图 6-1 通过数据的重复次数来实现压缩的 RLE 算法
6.3 RLE算法的缺点
- 不适合文本文件的压缩:实际的文本文件中,同样字符多次重复出现的情况并不多见
6.4 通过莫尔斯编码看哈夫曼算法的基础
- 莫尔斯编码:根据日常文本中各字符的出现频率来决定表示各字符的编码的数据长度
表 6-1 莫尔斯编码和位长
| 字符 | 对应的位数据 | 位长 |
|---|---|---|
| A | 10 1 1 | 4位 |
| B | 1 10 10 10 1 | 8位 |
| C | 1 10 10 1 101 | 9位 |
| D | 1 10101 | 6位 |
| E | 1 | 1位 |
| F | 10 10 1 10 1 | 8位 |
| 字符间隔 | 0 0 | 2位 |
1:短点、1 1:长点、0:短点和长点的分隔符
- 对文本
AAAAAABBCDDEEEEEF利用莫尔斯编码进行压缩- A * 16 + B * 2 + C * 1 + D * 2 + E * 5 + F * 1 + 字符间隔 * 16
- 4 * 16 + 8 * 2 + 9 * 1 + 6 * 2 + 1 * 5 + 8 * 1 + 2 * 16
- [106位] = 14 字节
- 压缩比率:14/17 = 82%
6.5 用二叉树实现哈夫曼编码
- 哈夫曼算法:根据数据出现的频率按照一定的规则编码
表 6-2 出现频率和编码(方案)
| 字符 | 出现频率 | 编码(方案) | 位数 |
|---|---|---|---|
| A | 6 | 0 | 1 |
| E | 5 | 1 | 1 |
| B | 2 | 1 0 | 2 |
| D | 2 | 1 1 | 2 |
| C | 1 | 1 0 0 | 3 |
| F | 1 | 1 0 1 | 3 |
- 上述方案存在的问题:
1、0、0这3个编码不确定是EAA还是BA - 如果不加入用来区分字符的符号,这个编码就无法使用
- 使用
哈夫曼树构造编码体系,即使在不使用字符区分符号的情况下,也可以构建能够明确进行区分的编码体系

图 6 - 2 哈夫曼树的编码顺序
7. 程序是在何种环境中运行的
问题:
- 应用的运行环境,指的是什么?
操作系统和计算机本身(硬件)的种类
应用的运行环境通常是用类似于Windows(OS)和AT兼容机(硬件)这样的OS和硬件的种类来表示的
原型机:IBM生产的采用Intel公司生产的芯片作为CPU的计算机
兼容机:除此之外的其他公司生产的计算机 - Macintosh 用的操作系统(MacOS),在AT兼容机上能运行吗?
不同的硬件种类需要不同的操作系统
IBM PC兼容机,是指与IBM的PC机兼容的个人电脑
到1990年代初,个人电脑市场上仅剩下IBM PC兼容机和麦金塔电脑(Macintosh)两个主要系列 - Windows 上的应用,在 MacOS 上能运行吗?
应用是为了在特定操作系统上运行而作成的 - FreeBSD 提供的 Ports,指的是什么?
通过使用源代码来提供应用,并根据运行环境及逆行整合编译,从而得以在该环境下运行的机制
FreeBD是一种Unix操作系统。通过在各个环境中编译Ports中公开的代码,就可以执行由此生成的本地代码了
FreeBD 能为不同架构的计算机系统提供不同程序的支持 - 在 Macintosh 上可以利用的 Windows 环境模拟器称为什么?
Virtual PC for Mac
模拟器是指在Macintosh上提供虚拟的Windows环境 - Java 虚拟机的功能是什么?
运行Java应用的字节代码
只要分别为各个环境安装专用的Java虚拟机,同样的字节代码就能在各个环境下运行了
7.1 运行环境 = 操作系统 + 硬件
- 同一类型的硬件可以选择安装多种操作系统,如,同样的AT兼容机中,既可以安装Windows,也可以安装Linux等操作系统
- AT兼容机:可以和IBM开发的PC/AT在硬件上互相兼容的计算机的总称
- x86 微处理器:Intel 的微处理器是按照
8086、80286、80386、80486、Pentium...这样的顺序不断升级的。因这些型号后面都带有86,所以总称为x86 - 本地代码:机器语言的程序,Windows 应用程序的本地代码,通常是 EXE
- 源代码:文本文件在任何环境下都能显示和编辑,通过对源代码进行编译得到本地代码
7.2 Windows 克服了 CPU 以外的硬件差异
- 在 Windows 的应用软件中,键盘输入、显示器输出等并不是直接向硬件发送指令,而是通过向Windows发送指令来间接实现的
- MS-DOS 应用大多都是不经过操作系统而直接控制硬件的,而Windows应用则基本上都是由Windows来完成对硬件的控制
- MS-DOS:一般使用命令行界面来接受用户的指令
7.3 不同操作系统的 API 不同
- API:(Application Programming Interface) 系统调用,是应用调用操作系统功能的手段
- Windows 及 Linux 系列操作系统的 API 提供了任何应用程序都可以利用的函数组合
- 不同操作系统的API是有差异的,因此将同样的应用程序移植到其他操作系统时,就必须要重写应用中利用到API的部分
- 键盘输入、鼠标输入、显示器输出、文件输入输出等同外围设备进行输入输出操作的功能都是通过API提供的
- 同类型操作系统下,不管硬件如何,API基本上没有差别。因此针对某特定操作系统的API所编写的程序,在任何硬件上都可以运行
7.4 利用虚拟机获得其他操作系统环境
- 虚拟机软件:即使不通过移植,也可以使用别的方法来运行其他操作系统的应用
7.4 提供相同运行环境的 Java 虚拟机
- Java :能够提供不依赖于特定硬件及操作系统的程序运行环境
- Java 作为编程语言的Java
- Java 作为程序运行环境的Java
- 字节代码:Java编译后生成的不是特定CPU使用的本地代码,而是名为字节代码的程序
- Java 虚拟机:字节代码的运行环境,Java虚拟机是一边把Java字节代码逐一转换成本地代码一边运行的
- Java虚拟机(java.exe)是将字节代码变换成x86系列的CPU适用的本地代码,然后由x86系列CPU负责实际的处理
- 从操作系统方面来看,Java虚拟机是一个应用;从Java应用方面来看,Java虚拟机就是运行环境
- Java运行速度慢的原因:Java虚拟机每次运行时都要把字节代码变换成本地代码
7.5 BIOS 和引导
- BIOS : Basic Input/Output System
- BIOS 存储在 ROM 中,是预先内置在计算机主机内部的程序
- BIOS 除了键盘、磁盘、显卡等基本控制程序外,还有启动 “引导程序” 的功能
- 引导程序:存储在启动驱动器起始区域的小程序
- 开机流程:
- BIOS 会确认硬件是否正常运行,没有问题的话会启动引导程序
- 引导程序的功能是把硬盘等记录的OS加载到内存中与逆行
- OS 并不能启动自己,而是通过引导程序来启动
8. 从源文件到可执行文件
问题:
- CPU 可以解析和运行的程序形式称为什么代码?
本地代码,通过编译源代码得到本地代码 - 将多个目标文件结合生成EXE文件的工具称为什么?
链接器,通过编译和链接,得到EXE文件 - 扩展名为 .obj 的目标文件的内容,是源码还是本地代码?
.c文件编译得到.obj目标文件,目标文件的内容是本地代码 - 把多个目标文件收录在一起的文件称为什么?
库文件,链接器会从库文件中抽取出必要的目标文件并将其结合到EXE文件 - 仅包含Windows的DLL文件中存储的函数信息的文件称为什么?
导入库,把导入库的信息结合到 EXE 文件中,这样程序在运行时就可以利用DLL内的函数了 - 在
程序运行时,用来动态申请分配的数据和对象的内存区域形式称为什么?
堆,堆的内存空间会根据程序的命令进行申请及释放
8.1 计算机只能运行本地代码
- 即使是用不同编程语言编写的代码,转换成本地代码后,也都变成同一种语言(机器语言)来表示了
8.2 本地代码的内容
- Windows 中 EXE 文件的程序内容,使用的就是本地代码
- 计算机是把所有的信息作为数值的集合来处理的,计算机指令也是数值的罗列
- 也即本地代码的真面目是数值的罗列
8.3 编译器负责转换源代码
编译器:把高级编程语言编写的源代码转换成本地代码的程序- 每个编写源代码的编程语言都需要其专门的编译器
- 编译器将源代码转换为本地代码的过程:
- 读入代码内容
- 语法解析、句法解析、语义解析等
- 生成本地代码
- CPU类型不同,本地代码的类型也不同,因而编译器不仅和编程语言的种类有关,和CPU的类型也是相关的
- 交叉编译器:生成和运行环境中的CPU不同的CPU所使用的本地代码
8.4 仅靠编译是无法得到可执行文件的
链接:本地文件无法直接运行,为了得到可以直接运行的EXE文件,编译后还需要进行"链接"处理- 把多个目标文件结合,生成1个EXE文件的处理就是链接
链接器:运行连接的程序
8.5 启动及库文件
库文件:把多个目标文件集成保存到一个文件的形式- 链接器指定库文件后就会从中把需要的目标文件抽取出来,并同其他目标文件结合生成 EXE 文件
- 外部符号:其他目标文件中的变量或函数
- 标准函数:不是通过源代码形式而是通过库文件形式和编译器一起提供的函数
- 使用库文件的原因:
- 简化为链接器的参数指定多个目标文件的这一过程
- 在链接调用了数百个标准函数的程序时,就要在链接器的命令行中指定数百个目标文件
- 利用存储着多个目标文件的库文件,只需要在链接器的命令行中指定几个库文件
- 通过以目标文件的形式或集合多个目标文件的库文件形式来提供函数,就可以不用公开标准函数的源代码内容
- 简化为链接器的参数指定多个目标文件的这一过程
8.6 DLL 文件及导入库
API:Windows 以函数形式为应用提供了各种功能,这些形式的函数称为 APIDLL:Dynamic Link Library ,DLL文件是程序运行时动态结合的文件- Windows中API的目标文件并不是储存在通常的库文件中,而是存储在DLL文件的特殊库文件中
- 导入库:库文件中目标函数的实体并不存在,库文件知识记录了目标文件所在的DLL文件以及DLL文件的文件夹信息
- 通过结合导入库文件,执行时从DLL文件中调出的目标函数就会和EXE文件进行结合
- 静态链接库:存储着目标文件的实体,并直接和 EXE 文件结合的库文件
代码清单 8-1 求解平均值的程序
#include <windows.h>
#include <stdio.h>
//消息框的标题
char* title = "示例程序1";
//返回两个参数的平均值的函数
double Average(double a, double b){return (a + b) / 2;
}
//程序运行启始位置的函数
int WINAPI WinMain(HINSTANCE h, HINSTANCE d, LPSTR s, int m){duble ave; //保存平均值的变量char buff[80]; //保存字符串的变量//求解 123,456 的平均值ave = Average(123, 456);//编写显示在消息框中的字符串sprintf(buff, "平均值 = %f", ave);//打开消息框MessageBox(NULL, buff, title, MB_OK);return 0;
}
c0w32.obj 由 Borland C++ 提供,在文件夹 C:\Borland\bcc55\lib 文件夹下

图 8 - 1 Windows中的编译和链接机制
8.7 可执行文件运行时的必要条件
-
程序运行时变量及函数的实际内存地址?
- 本地代码在对程序中记述的变量进行读写时,是参照数据存储的内存地址运行命令的
- 在调用函数时,程序的处理流程会跳转到存储着函数处理内容的内存地址上
-
EXE本地代码程序并没有指定变量及函数的实际内存地址!
- EXE 文件中给变量及函数分配了虚拟的内存地址
- 程序运行时,虚拟的内存地址会转换成实际的内存地址
再配置信息:链接器会在EXE文件的开头追加转换内存地址所需的必要信息
-
再配置信息
- 变量和函数的相对地址
- 相对地址表示相对于基点地址的偏移量

图 8-2 链接后的 EXE 文件的构造
-
变量组和函数组:在源代码中,虽然变量及函数时在不同位置分散记述的,但是在链接后的 EXE 文件中,变量及函数就会变成一个连续排列的组
8.8 程序加载时会生成栈和堆
- 栈和堆的内存分配:程序加载到内存后会额外生成两个组,栈和堆
- 栈:用来存储函数内部临时使用的变量(局部变量),以及函数调用时所用的参数的内存区域
- 堆:用来存储程序运行时的任意数据及对象的内存领域
- 栈和堆需要的内存空间是在 EXE 文件加载到内存后开始运行时得到分配的
- 局部变量和全局变量:
- 局部变量:只在调用函数时存在于内存中的变量
- 全局变量:程序运行时一直存在于内存中的变量
- 栈和堆的异同:
- 相同点:内存空间都是在程序运行时得到申请分配的。在高级编程语言中,编译器会自动生成指定栈和堆大小的代码
- 不同点:内存的使用方法
- 栈:
- 对数据进行存储和舍弃的代码是由编译器自动生成的
- 使用栈的数据内存空间,每当函数被调用时都会得到申请分配,并在函数处理完后自动释放
- 堆:
- 堆的内存空间要根据程序员编写的程序,来明确进行申请分配或释放
内存泄露:C及C++,没有在程序中明确释放堆的内存空间,即使在处理完毕后,该内存空间仍会一直残留
- 栈:
9. 操作系统和应用的关系
问题
- 监控程序的主要功能是什么?
程序的加载和运行 - 在操作系统上运行的程序称为什么?
应用或应用程序 - 调用操作系统功能称为什么?
系统调用 system call - GUI 是什么的缩写?
Graphical User Interface (图形用户界面)
显示器中显示的窗口及图标等通过鼠标点击可以直接操作的用户界面 - WYSIWYG 是什么的缩写?
What You See Is What You Get (所见即所得)
可以直接将显示器中显示的内容在打印机上打印出来
9.1 操作系统功能的历史
-
监控程序:仅具有加载和运行功能,通过事先启动监控程序,程序员可以根据需要将各种程序加载到内存中运行

图 9-1 初期的操作系统 = 监控程序 + 基本的输入输出程序 -
dump 是指把文件的内容,每个字节用2位十六进制数来表示的方式
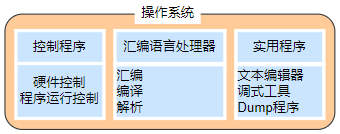
图 9-2 操作系统是多个程序的集合体
9.2 系统调用和高级编程语言的移植性
- 系统调用:应用对操作系统的功能进行调用
- 操作系统的硬件控制功能,通常是通过一些小的函数集合体的形式来提供的
- 这些函数及调用函数的行为统称为系统调用
- 移植性:同样的程序在不同的操作系统下运行时需要花费的时间等,费时越少说明移植性越好
10. 通过汇编语言了解程序的实际构成
问题:
- 本地代码的指令中,表示其功能的英文缩写称为什么?
助记符 - 汇编语言的源代码转换成本地代码的方式是什么?
汇编器 - 本地代码转换成汇编语言的源代码的方式是什么?
反汇编 - 汇编语言的源文件的扩展名,通常是什么格式?
.asm,assembler 汇编器 - 汇编语言程序中的段定义指的是什么?
构成程序的命令和数据的集合组 - 汇编语言的跳转指令,是在何种情况下使用的?
将程序流程跳转到其他地址时
10.1 汇编语言和本地代码是一一对应的
本地代码:数值的罗列汇编语言:使用助记符的编程语言- 从本地代码到汇编语言:在本地代码中附带上表示其功能的英语单词的缩写
- 在加法运算的本地代码中加上 add
- 在比较运算的本地代码中加上 cmp

- dword ptr(double word pointer):从指定的内存地址读出 4 字节的数据
- 若指定了用
[ ]围起来的内容,[ ]中的值则会被解释为内存地址
上述7B 00 00 00对应于7Bh,因为是 4 字节的数据
10.2 不会转换成本地代码的伪指令
- 汇编语言的构成:转换成本地代码的指令和针对汇编器的
伪指令构成
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
伪指令:负责把程序的构造及汇编的方法只是给汇编器(转换程序)
上述segment和ends即为伪指令段定义:由伪指令segment和ends围起来的部分,指的是命令和数据等程序的集合体的意思
_TEXT:指令的段定义
_DATA:被初始化(有初始值)的数据的段定义
_BSS:尚未初始化的数据的段定义
10.3 汇编语言的语法是"操作码 + 操作数"
- 操作码:指令动作
- 操作数:指令对象
- 汇编语言中的操作码和操作数
- 操作码:类似于 mov 这样的指令
- 操作数:指令队形的内存地址及寄存器
- 从汇编语言到本地代码:被转换成CPU可以直接解析运行的二进制的操作码和操作数
- CPU处理时指令和数据的迁移:内存到CPU内部的寄存器
表10 - 1 x86 系列 CPU 的主要寄存器
| 寄存器名 | 名称 | 主要功能 |
|---|---|---|
| eax | 累加寄存器 | 运算 |
| ebx | 基址寄存器 | 存储内存地址 |
| ecx | 计数寄存器 | 就算循环次数 |
| edx | 数据计数器 | 存储数据 |
| esi | 源基址寄存器 | 存储数据发送源的内存地址 |
| edi | 目的基址寄存器 | 存储数据发送目标的内存地址 |
| ebp | 扩展基址指针寄存器 | 存储数据存储领域基点的内存地址 |
| esp | 扩展栈指针寄存器 | 存储栈中最高数据的内存地址 |
10.4 临时确保局部变量用的内存空间
为什么局部变量只能在定义该变量的函数内进行引用呢?
- 局部变量只是在函数处理运行期间临时存储在寄存器和栈上
- 函数内部利用的栈,在函数处理完毕后会恢复到初始状态,而寄存器也可能会被用于其他目的
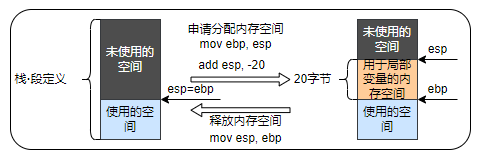
图 10-1 用于局部变量的栈空间的申请分配和释放
11. 硬件控制方法
问题:
- 在汇编语言中,是用什么指令来同外围设备进行输入输出操作的?
IN指令和OUT指令 - I/O是什么的缩写?
Input/Output - 用来识别外围设备的编号称为什么?
I/O地址或I/O端口号,所有连接到计算机的外围设备都会分配一个I/O地址编号 - IRQ是什么的缩写?
Interrupt Request,用来执行硬件中断请求的编号 - DMA是什么的缩写?
Direct Memory Access,不经过CPU中介处理,外围设备直接同计算机的主内存进行数据传输 - 用来识别具有DMA功能的外围设备的编号称什么?
DMA通道,像磁盘这样用来处理大量数据的外围设备都具有 DAM 功能