什么是stl文件
STL(Stereolithography)文件,由3D Systems于1987年创建,并且已被广泛用作全行业3D打印机模型的标准文件。它有一些别的首字母缩写词如“标准三角语言(Standard Triangle Language)”,“标准曲面细分语言(Standard Tessellation Language)”、“立体光刻语言(STereolithography Language)”和“(立体光刻曲面细分语言)”。它被广泛用于快速成型、3D打印和计算机辅助制造(CAM)。STL文件仅描述三维物体的表面几何形状,没有颜色、材质贴图或其它常见三维模型的属性。STL格式有文字和二进码两种型式。二进码型式因较简洁而较常见。
ascii格式的stl文件
ascii格式的stl文件,文本的本质是二进制数据,ascii格式的模型文件其实是二进制数据转化为文本类型的字符串,然后再从这个文本类型的字符串中按照一定的规则提取文件数据。用户在浏览器端上传ascii格式的stl文件:
- 假设我们有一个type=“flie”的input标签,用户通过这个标签选中一个ascii格式的stl文件(用户在打开的文件窗口中选中文件并点击确定,这个时候文件的元信息对象会被添加到input的dom节点的files这个属性中),浏览器规定js不能直接操纵用户本地的文件数据,只能通过浏览器间接的读取和写入文件。
- 我们把拿到的文件元信息对象成为fileobj,我们需要用FileReader这个接口通过fileobj把模型文件读取为arraybuffer类型,代码如下。
const fileReader = new FileReader();fileReader.onerror = function ( event ) {console.error( '读取用户本地模型文件转化为数据缓冲区arraybuffer的过程中出现了错误,报错路径e.target.error', event );};fileReader.onload = function () {// 读取用户本地数据转化为arraybuffer成功,转化的数据存放在result中;const stlArrayBuffer=this.result;};//这个是从input的dom节点中的files中获取到的文件的元信息对象,fileReader.readAsArrayBuffer( fileobj );
- 判断这个文件是文本类型的文件还是二进制类型的文件,判断文件是二进制还是文本类型的文件有两种判断方法,第一种是判断这个文件满足不满足文本文件的格式,这个判断方法最简单:代码如下:
const dataview=new DateView(arraybuffer);这个arraybuffer就是通过上边的步骤解析得到的字节数组。
//ascii格式的文件开头前五个字符一定是solid。我们可以根据这个来判断for ( let i = 0; i < 5; i ++ ) {if ( 'solid'.charCodeAt( i ) !== dataview.getUint8( i ) ) {return true;}}
第二种方法是判断文件是否满足二进制文件的格式规则,代码如下:
const dataview = new DataView( data );//这个是二进制的stl文件每个三角面占用的字节数目,第一个是三角面法向量,第二个是三个顶点的9个坐标值,第三个是三角面的颜色值(32*32*32来表示rgb三色外加一个比特位来判断是否是有效的颜色值,加起来一共是两个字节)const face_size = ( 4 * 3 ) + ( ( 4 * 3 ) * 3 ) + 2;//获取模型三角面数目,二进制文件用第81~84这四个字节来表示该模型文件中三角面的数目,const n_faces = dataview.getUint32( 80, true );//根据三角面数目反推二进制文件的大小,然后比较推算出来的二进制文件的大小是否等于实际的模型文件大小,相等的情况下就是二进制文件const expect = 80 + 4 + ( n_faces * face_size );if ( expect === dataview.byteLength ) {return true;}
通过这个步骤我们可以判断文件是否是文本类型的模型文件。
4.通过上边的步骤我们判断出文件是文本类型的文件;接下来我们把文件的arraybuffer转化为文本字符串。现在大多数浏览器都提供专门的文本解码器接口(TextDecoder),在没有文本解码器的情况下我们可以使用fromCharCode这个方法来把二进制数据转化为文本字符串,使用第二种方法有很多要注意的地方,具体代码如下:
//所谓的文本类型文件其实就是使用ascii字符来描述文件信息,上边我们拿到了文件的二进制数据arraybuffer,arraybuffer就像nodejs中的buffer一样,可以简单理解为数据缓冲区,arraybuffer不能直接操作,需要通过dataview或者类型数据来对他进行操作,因为文本字符串一个字符需要8个比特位来存储,所以我们把arraybuffer转化为Uint8Array类型;const uint8 = new Uint8Array( arraybuffer );let result = '';//如果浏览器提供文本解码器的请况下推荐使用文本解码器,文本解码器解析10多兆的文件大概需要9毫秒左右(我的电脑配置是i7-8700k),自己手动转化的情况下,就拿下边的方法来说,目前大概需要90毫秒。如果不进行优化的情况下,大概需要1000多毫秒。if ( typeof TextDecoder === 'undefined' ) {result = new TextDecoder().decode( uint8 );} else {const length = uint8.length;// js中的字符串的值是不能改变的,也就是说字符串一旦创建,他们的值就不能改变,要改变某个变量保存的字符串,首先要销毁原来的字符串,然后再用另外的一个包含新值的字符串来填充该变量。本质上字符串的值不是直接存储在栈里边的;fromCharCode这个方法经过大概的测试,一次最多接收的参数的数目大概是12万多一点,超出这个范围就会报出超过最大调用栈大小的错误;对于有强迫症的我比较喜欢用65535这个数值。如果我们每次传一个参数的情况下,10兆文件就需要解析1000多毫秒,如果使用数组的join方法的情况下大概是几百毫秒;for ( var i = 0; i < length; i += 65535 ) {if ( length - i < 65535 ) {result += String.fromCharCode.apply( null, uint8.slice( i, length - i ) );}result += String.fromCharCode.apply( null, uint8.slice( i, i + 65535 ) );}}
- 从ascii的字符串中提取模型文件数据,文本类型的stl文件的接口很简单,开始一个solid声明加名字,结尾是一个endsolid字符标识加名字,简单的格式介绍如下所示:
//开头的文件声明
solid name//facet~endfacet之间表示的是一个完整的三角面的信息,文本类型的stl文件其实就是用这段文本循环表示出模型所有的三角面(下边normal表示三角面的法向量,vertex表示三角面三个顶点的坐标,解析这个结构其实就是使用正则提取相应的数据)facet normal nx ny nz outer loopvertex v1x v1y v1zvertex v2x v2y v2zvertex v3x v3y v3zendloopendfacet......
endsolid name
知道了模型文件存储数据的大概格式;接下来使用正则提取这些模型数据,代码如下:
const data="第三步获得的文本字符串";
// 对于stl的ascii形文件数据,内部都是一个一个的面的文本,我们开始时不知道三角面的数据, ascii格式的stl模型数据没有颜色数据,只有顶点数据和面法向量数据。const bufferGeometry = new THREE.BufferGeometry();const patternFace = /facet([\s\S]*?)endfacet/g;const patternNormal = /normal[\s]+([+-]?(?:\d*)(?:\.\d*)?(?:[eE][+-]?\d+)?)[\s]+([+-]?(?:\d*)(?:\.\d*)?(?:[eE][+-]?\d+)?)[\s]+([+-]?(?:\d*)(?:\.\d*)?(?:[eE][+-]?\d+)?)/g;const patternVertex = /vertex[\s]+([+-]?(?:\d*)(?:\.\d*)?(?:[eE][+-]?\d+)?)[\s]+([+-]?(?:\d*)(?:\.\d*)?(?:[eE][+-]?\d+)?)[\s]+([+-]?(?:\d*)(?:\.\d*)?(?:[eE][+-]?\d+)?)/g;const vertices = [];const normals = [];const normal = new THREE.Vector3();let result;try {while ( ( result = patternFace.exec( data ) ) !== null ) {const text = result[ 0 ];while ( ( result = patternNormal.exec( text ) ) !== null ) {normal.x = parseFloat( result[ 1 ] );normal.y = parseFloat( result[ 2 ] );normal.z = parseFloat( result[ 3 ] );}while ( ( result = patternVertex.exec( text ) ) !== null ) {vertices.push( parseFloat( result[ 1 ] ), parseFloat( result[ 2 ] ), parseFloat( result[ 3 ] ) );normals.push( normal.x, normal.y, normal.z );}}bufferGeometry.attributes.position = new THREE.Float32BufferAttribute( vertices, 3 );bufferGeometry.attributes.normal = new THREE.Float32BufferAttribute( normals, 3 );} catch ( error ) {console.error( '文件解析的过程中出现错误,该文件虽然有3d模型的后缀,但是内部的数据结构可能不是3d模型的数据结构', error );return false;}return bufferGeometry;
- 通过上边四个步骤,我们得到了buffergeometry的threejs的数据类型,threejs从112版本就把原来的geometry这个类型删除掉了,之前的geometry性能很低。buffergeometry就是模型的几何结构数据。有了模型的几何结构,我们就可以去计算模型的体积和表面积。threejs中的几何结构的面一定是三角形的,并且用于打印的stl模型只能是水密的流形(manifold),水密就是简单理解就是把一个矿泉水瓶放进水中,矿泉水瓶就是水密的模型,把瓶盖拧开放进去,就不是水密性的模型。
(矿泉水瓶这个例子可能会存在一个误解,就是模型内部不能是空的,我们可以把一个渔网模型丢在水中,渔网模型能够占据了一定的体积,他也是水密性的模型,水密,watertight,也可以通俗的说是“封闭的”或“不漏水的”。水密的意思是3D模型必须是一个边界完整的整体,如果模型有漏洞,打印机无法辨认边界,则不能打印)
流形这个概念自己百度吧,在threejs中的标准的合格的模型一定是流形的模型。对于得到的buffergeometry这个数据,他满足流形和水密性的情况下,我们可以计算这个用于打印的符合打印规则的几何结构的准确的表面积和体积;对于流形并且水密性的模型,我们可以使用极坐标积分的方法去计算模型的体积,对于那种不是水密性的模型,我们可以使用蒙特卡洛算法去求这个几何结构的体积。这个地方仅给出极坐标求体积的方法,同时给出了计算模型的表面积的方法(其实就是所有三角面的面积之和),代码如下:
// 计算模型的体积和表面积const bufferGeometry="第四步解析出来的模型的threejs的buffergeometry";var x1, x2, x3, y1, y2, y3, z1, z2, z3, a, b, c, s;var totalVolume = 0, totalArea = 0;try {var _array = bufferGeometry.getAttribute( 'position' ).array;for ( var i = 0, _length = _array.length; i < _length; i += 9 ) {//一个三角面的9个坐标x1 = _array[ i ];y1 = _array[ i + 1 ];z1 = _array[ i + 2 ];x2 = _array[ i + 3 ];y2 = _array[ i + 4 ];z2 = _array[ i + 5 ];x3 = _array[ i + 6 ];y3 = _array[ i + 7 ];z3 = _array[ i + 8 ];// 这个是极坐标积分求体积的体积计算方法。该方法是同通过几何来计算一个模型的体积,计算出来的体积是唯一的,也就是这个模型的唯一的真实的体积值。但是使用该方法的前提是这个模型必须是水密性的流形的模型。对于不满足条件的模型,计算出来的体积大概接近真实值。totalVolume += x2 * y3 * z1 + x3 * y1 * z2 + x1 * y2 * z3 - x1 * y3 * z2 - x2 * y1 * z3 - x3 * y2 * z1;// 经过多次测验,发现下边这三种写法几乎没有性能上边的差异;// a =Math.sqrt(Math.pow((x1-x2),2)+Math.pow((y1-y2),2)+Math.pow((z1-z2),2));// b =Math.sqrt(Math.pow((x2-x3),2)+Math.pow((y2-y3),2)+Math.pow((z2-z3),2));// c =Math.sqrt(Math.pow((x3-x1),2)+Math.pow((y3-y1),2)+Math.pow((z3-z1),2));a = Math.sqrt( ( x1 - x2 ) ** 2 + ( y1 - y2 ) ** 2 + ( z1 - z2 ) ** 2 );b = Math.sqrt( ( x2 - x3 ) ** 2 + ( y2 - y3 ) ** 2 + ( z2 - z3 ) ** 2 );c = Math.sqrt( ( x3 - x1 ) ** 2 + ( y3 - y1 ) ** 2 + ( z3 - z1 ) ** 2 );// a =Math.sqrt((x1-x2)*(x1-x2)+(y1-y2)*(y1-y2)+(z1-z2)*(z1-z2));// b =Math.sqrt((x2-x3)*(x2-x3)+(y2-y3)*(y2-y3)+(z2-z3)*(z2-z3));// c =Math.sqrt((x3-x1)*(x3-x1)+(y3-y1)*(y3-y1)+(z3-z1)*(z3-z1));s = ( a + b + c ) / 2;totalArea += Math.sqrt( s * ( s - a ) * ( s - b ) * ( s - c ) );}} catch ( error ) {console.error( '模型在计算体积的过程中出现错误,可能是传入的参数类型不正确', error );return false;}//totalVolume ,totalArea
7.渲染解析出来的stl模型;渲染这个模型需要threejs的渲染器(webglrender)、场景(scene)、相机(camera)、灯光(light)、网格模型(mesh)、网格模型材质(material)。看到这篇文章,应该都是或多或少的了解threejs。这里就不对这些概念做介绍了。下边给出一份渲染模型并导出一张模型的外观图片的代码:
const bufferGeometry="这个是第四步解析得到的buffergeometry";var material = new THREE.MeshPhongMaterial({color:0x0x0066cd});var mesh = new THREE.Mesh( bufferGeometry, material );//在threejs中坐标系是y轴朝上,在别的3d软件中的坐标系是z轴朝上;这个地方要做一下转变mesh.useQuaternion = true;var axis = ( new THREE.Vector3( 100, 100, 100 ) ).normalize();var angle = Math.PI / 0.3;var q = ( new THREE.Quaternion() ).setFromAxisAngle( axis, angle );mesh.quaternion.copy( q );mesh.castShadow = true;mesh.receiveShadow = true;//我们放到场景中的模型,需要根据模型的长宽高去设定相机的位置和角度,灯光的位置和角度。var maxlong = Math.max( bufferGeometry.boundingBox.max.x, bufferGeometry.boundingBox.max.y, bufferGeometry.boundingBox.max.z );var totalChaValue = Math.abs( bufferGeometry.boundingBox.max.x - bufferGeometry.boundingBox.max.y ) + Math.abs( bufferGeometry.boundingBox.max.x - bufferGeometry.boundingBox.max.z ) + Math.abs( bufferGeometry.boundingBox.max.y - bufferGeometry.boundingBox.max.z );if ( maxlong > totalChaValue ) {maxlong *= 1.5;}var scene = new THREE.Scene();var camera = new THREE.PerspectiveCamera( 90, 1, 1, 10000 );camera.position.set( maxlong / 1.6, maxlong / 1.6, maxlong * 1.3 );camera.lookAt( 0, 0, 0 );scene.add( camera );var pointlight = new THREE.PointLight( 0xffffff, 0.5 );//这个地方其实就是迷惑性的代码,maxlong&0的值为pointlight.position.set( 0, 0, maxlong );camera.add( pointlight );var directionallight = new THREE.DirectionalLight( 0xffffff, 0.75 );directionallight.position.set( maxlong / 2, maxlong, maxlong * 2 );directionallight.position.normalize();camera.add( directionallight );var ambientlight = new THREE.AmbientLight( 0x404040 );camera.add( ambientlight );scene.add( mesh );var renderer = new THREE.WebGLRenderer( {antialias: true,precision: 'highp',alpha: true,premultipliedAlpha: false,stencil: false,preserveDrawingBuffer: true,maxLights: 1} );renderer.setSize( 800, 800 );renderer.setClearColor( 0x000000 );renderer.render( scene, camera );从场景中导出base64的该视角下的图片var _base64img = renderer.domElement.toDataURL( 'image/png' );return _base64img;到这个地方,文本类型stl文件的解析、计算表面积体积、渲染取图的大概流程介绍结束;
二进制格式的stl文件
二进制格式的stl文件,通过上边的前三个步骤我们可以区分二进制模型文件和文本模型文件。二进制文件中数据按固定的格式存放。开头有80个字节的标头(用来记录该文件的名字和模型的整体的颜色),紧接着是4个字节的无符号整数(记录的是该模型=文件三角面的数目),后边跟着的是50个字节为一个整体的三角面信息知道数据末尾,文件时以小端序存数数据(little-endian),每一个50个字节记录的三角面信息的结构如下:
//第一个数据表示三角面的法向量normal,法向量和顶点数据用float32的数据类型存储,49到50字节用来简单的存储顶点的颜色(16个比特位),3*5+1=16的方式存储颜色信息,最后的1个比特位用来确定该顶点颜色是否有效;0~31《=》0~256(rgb)nx(float32)ny(float32)nz(float32)v1x(float)v1y(float)v1z(float)v2x(float)v2y(float)v2z(float)v3x(float)v3y(float)v3z(float)+uint16;1、从文件标头中读取文件的颜色信息,标头中会有color=“rgba”存储颜色值。使用上边介绍的把二进制转化为文本字符串的方法把二进制文件类型的stl文件的标头转化为字符串,然后使用正则取出这些颜色值。这个颜色值可能存在也可能不存在。
2、获取三角面的数目,提前创建好字节固定长度的类型数组(类型数组的性能要远远的高于js的可变长度数组,对于文件的解析,尽量使用类型数组);这块代码如下:
//创建数据视图来操作arraybuffer(字节数组,也可称作缓冲区数据);const reader = new DataView( data );//根据二进制文件的存储规则我们知道第81~84四个字节存储着模型的三角面数目,通过这个获取二进制模型有多少个三角面const faces = reader.getUint32( 80, true );const dataOffset = 84;const faceLength = 12 * 4 + 2;//这个是顶点数组和法向量数组的索引。在threejs中,每一个顶点有三组数据,顶点位置数据,顶点法向量数据,顶点颜色数据,这三组数据一一对应。顶点颜色数据可有可无,顶点位置数据是基本的,顶点法向量数据也是必须的(如果没有顶点法向量数据,模型就无法参与方向光的关照计算和阴影计算,模型看起来就是单一的环境光颜色)let vertexIndex = 0;const bufferGeometry = new THREE.BufferGeometry();const vertices = new Float32Array( faces * 3 * 3 );const normals = new Float32Array( faces * 3 * 3 );
- 一般来说,模型颜色对于3d打印机来说没有什么实际意义。这个地方就不提取模型颜色了(二进制文件标头存储着模型的整体颜色,每个三角面的数据体中第49、50这两个字节存储的是0~31的rgb的颜色,最后一个比特位是确定这个颜色是否是有效的,顶点没有可以使用的有效的颜色,可以给这个顶点使用模型整体的颜色数据,如果没有模型颜色的整体数据那就不使用颜色数据)。简化的代码如下所示(没有提取模型颜色):
//这个地方的代码紧接着上一步的代码
for ( let face = 0; face < faces; face ++ ) {//dataOffset是字节数组中的顶点数据的偏移量(去掉文件标头的80个字节和三角面数目的四个字节),第二个数据是每个三角面数据占用50个字节(上边有对这50个自己的结构的详细的介绍);const start = dataOffset + face * faceLength;const normalX = reader.getFloat32( start, true );const normalY = reader.getFloat32( start + 4, true );const normalZ = reader.getFloat32( start + 8, true );for ( let i = 1; i <= 3; i ++ ) {const vertexstart = start + i * 12;vertices[ vertexIndex ] = reader.getFloat32( vertexstart, true );vertices[ vertexIndex + 1 ] = reader.getFloat32( vertexstart + 4, true );vertices[ vertexIndex + 2 ] = reader.getFloat32( vertexstart + 8, true );normals[ vertexIndex ] = normalX;normals[ vertexIndex + 1 ] = normalY;normals[ vertexIndex + 2 ] = normalZ;vertexIndex += 3;}}bufferGeometry.attributes.position = new THREE.BufferAttribute( vertices, 3 );bufferGeometry.attributes.normal = new THREE.BufferAttribute( normals, 3 );return bufferGeometry;
这个地方就把二进制的stl文件中的顶点数据和法向量数据提取完毕生成了一个threejs的buffergeomtry对象,下边的渲染和上边的文本文件解析的后边的步骤一样。

在这个地方附上一个3d打印的图片(从魔猴网扣过来的);

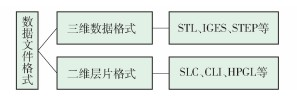
3d打印常见的数据格式;
3D 打印技术诞生于 19 世纪末,随着科学技术的不断发展,在汽车、航空航天、医疗、军工、艺术设计、建筑等方面均有着广阔的应用价值及前景. 在世界各国家和地区,3D 打印技术已受到广泛关注,并取得长足的发展. 2013 年,中国科技部在《3D 打印技术发展综述报告》中指出将支持3D 打印相关的设计方法研究,并将其作为未来 5 年的技术方向和重点之一,该技术被提升到国家战 略性发展规划中. 3D 打印技术作为快速成型技术的一种,也被 称为增材制造( additive manufacturing,AM) ,是先 进制造技术的重要组成部分. 该技术以数字化模型文件为基础,通过逐层打印、层层累积的策略来 制造三维实体 . 与传统技术相比,3D 打印技术 具有诸多优势. 首先,数字化的成型基础可省去多 种传统制造步骤,从而减少制造时间,拓宽设计空 间;其次,增材制造的方式避免了材料浪费,实现 了能源节约. 增材制造是多种技术的统称,根据使用材料的 不同 可 分 为 以 下 几 种: 熔 融 沉 积 制 造 ( fused deposition modeling, FDM ) 、 选 区 激 光 烧 结 ( selective laser sintering, SLS ) 、 叠 层 制 造 (laminated object manufacturing,LOM) 、光固化成 型(stereolithograph apparatus,SLA) 和选区激光熔 化(selective laser melting,SLM) 等. 由于所有技 术工艺均以数字化模型文件为基础,在 3D 打印的 整个制造过程中都需要进行大量的数字化模型文件 的准备及处理,所以,不同的数据文件格式会直接影 响加工过程和加工效果. 因此,研究 3D 打印过程中 的数据文件格式是十分必要的. 这里主要介绍了 3D 打印过程中的数据文件格 式,包括三维数据文件格式( STL、IGES、STEP)、二 维层片文件格式(SLC、CLI、HPGL)以及新型的数据 文件格( 式AMF、3MF、RP),并对其各自的优缺点进 行了分析和比较。
- 三维模型数据的获取
三维数据模型的获取是 3D 打印技术的基础和 关键技术之一,目前获取三维模型的方式主要有正 向设计数据和逆向工程数据. 2. 1 正向设计数据 正向设计是指通过三维设计软件进行的设计, 这是最重要、应用最广泛的数据来源 . 3D 打印使用的软件设计方法主要分为实体建 模和曲面建模. 实体建模一般适用于制造领域和工 业设计,主要是对形状规则的物体进行建模,对于形 状不规则的、精细的、复杂的设计有些不能很好的胜 任,如设计复杂的动漫形象;而曲面建模正好相反. 目前一般的设计软件都是综合这 2 种建模方法来得 到最理想的设计效果. 使用较多的三维设计软件主 要 有AutoCAD、 Catia、 Delcam、 Pro / E、 Solidedge、 MDT、UG 等 .
- 逆向工程数据
逆向工程(reverse engineering,RE)是将目标三 维实体通过相关的数据采集转变为概念模型,并在 此基础上进行后续创作,又称反向工程或反求工程. 逆向工程主要包括:采集数据、处理数据、重构曲面和三维建模. 首先处理采集到的数据,而后对 处理完的有限点云数据进行曲面重构和三维建模. 数据采集的主要方法包括:三坐标测量仪法 、激 光 三 角 形 法、 投 影 光 栅 法 、 CT ( computed tomography ) 扫 描、 核 磁 共 振 法 ( magnetic resonance imaging, MRI ) 以 及 自 动 断 层 扫 描 法[21] . CT 扫描是通过逐层扫描物体来获取截面数 据的. 而后将 CT 扫描得到的 DICOM 数据导入 Mimics、Geomagic、Imageware、Surfacer 等软件中进行 设计优化,最后根据所建模型的用途输出相应的格 式文件. 利用 Surfacer 软件进行优化设计时, 利用 鼠标对图像进行切割,提取外形轮廓,而后进行相关 的设计处理,最终输出相应的数据文件格式,一般为 STL 格式. 核磁共振技术是 1973 年开始应用于医 学领域的,该技术主要是基于拉莫尔定理,从测得的 信号中对某种参数及其相关的图像进行重现恢复. 自动断层扫描法是通过对样件进行逐层的机械式切 削来自动摄取每一层轮廓影像,再通过对轮廓影像 进行分析来提取相应的轮廓数据。
- 3D 打印技术中的数据文件格式
如图所示,3D 打印中的数据文件格式主要分 为 2 类: CAD 三维数据文件格式和二维层片文件格 式. CAD 三 维 数 据 文 件 格 式 包 括: STL ( stereo lithography) 、 STEP ( standard for the exchange of product modal data ) 、 IGES ( initial graphics exchange specification ) 、 LEAF ( layer exchange ASCII format ) 、 RPI ( rapid prototyping interface) 、LMI( layer manufacturing interface) 等;二维层片文件格式包括:SLC( stereo lithography contour) 、CLI( common layer interface) 、HPGL (Hewlett-Packard graphics language) 等. 其中 STL 是最早用于 CAD 与 CAPP 间数据交换的文件格式, 并且得到了广泛的应用. 目前,3D 打印系统大部分 都是基于 STL 格式设计的。
除此之外,为了更真实地描述 3D 打印模型,新 型的数据文件格式 AMF( additive manufacturing file format) 、3MF(3D manufacturing format) 、RP 等 也被提出。
经过 20 多年的发展,3D 打印技术不断地走向 成熟,在打印精度与打印材料等方面都有较大提高, 但仍存在一系列问题,因此 3D 打印技术依然拥有 非常大的潜力. 3D 打印整个制造过程中涉及大量 的数字化模型文件的准备及处理,不同的模型文件 的类型对加工过程和加工效果均有很大的影响。3D 打印过程中的三维模型数据可通过正向设 计和逆向工程等 2 种方式获得. 3D 打印过程中的 数据文件格式主要分为 2 类:CAD 三维数据文件格 式(STL、IGES、STEP、LEAF、RPI、LMI 等) 和二维层 片文件格式(SLC、CLI、HPGL 等). 出现最早的 STL 文件格式是应用最广泛的数据交换格式,但是 STL 文件格式也有自身的缺点:数据量极大;在数据的转 换过程中有时会出现错误;有冗余现象;采用三角形 面片的格式去逼近整个实体存在逼近误差,因此在 实际应用中会有很多限制. 针对 STL 文件格式存在 的这些缺点,新型的数据文件格式 AMF、3MF、RP 等 进行了相关的优化. 其中,AMF 数据文件格式引入 曲面三角形,利用各个顶点法线或切线方向来确定 曲面曲率,在进行数据处理切片时,曲面三角形可进 行细分,由此获得理想精度. 因此,AMF 格式包含的 工艺信息更全、文件体积更小、模型错误更少;3MF 数据文件格式可以描述一个模型内在和外在的信 息,具有较好的互操作性和开放性,简单易懂,可用 来解决其他广泛使用的文件格式固有的问题;RP 文 件中的数据采用先进的压缩算法进行压缩,大大减 小了文件的大小;此外,RP 在文件自身方面使用最 先进的加密算法,在用户层面使用自定义密码,大大 提高了文件的安全性. 这是 STL 文件无法实现的。结合 3D 打印的发展现状,作者认为新型数据 文件格式未来的发展方向必然是数据量小、精度高、 安全性高. 同时,应该建立一个统一的数据文件格 式标准,实现数据共享,减少数据文件格式转换带来 的数据丢失及错误等,以此来提高产品的质量以及 稳定性.(这个总结从别的地方copy的);