一、获取索引 index
import pandas as ps
import numpy as npa1 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"],index=["a","b"])
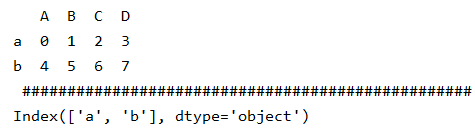
print(a1,"\n","#"*50)# A B C D
# a 0 1 2 3
# b 4 5 6 7print(a1.index,"\n","#"*50) # 获取a1的行索引# Index(['a', 'b'], dtype='object')
二、设置索引 index
import pandas as ps
import numpy as npa1 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"],index=["a","b"])
print(a1,"\n","#"*50)# A B C D
# a 0 1 2 3
# b 4 5 6 7a1.index = ["x","z"] # 指定a1的行索引
print(a1,"\n","#"*50)# A B C D
# x 0 1 2 3
# z 4 5 6 7
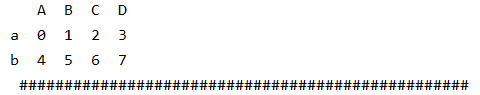
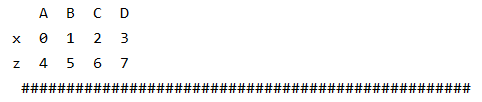
三、重设索引 reindex()
import pandas as ps
import numpy as npa1 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"],index=["a","b"])
print(a1,"\n","#"*50)# A B C D
# a 0 1 2 3
# b 4 5 6 7print(a1.reindex(["x","y"]),"\n","#"*50) # 重新设置index(因为本身没有y索引的一行,故全为NaN)# A B C D
# x 0.0 1.0 2.0 3.0
# y NaN NaN NaN NaN

四、将列索引下的元素设置为行索引 set_index()
import pandas as ps
import numpy as npa1 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"],index=["a","b"])
print(a1,"\n","#"*50)# A B C D
# a 0 1 2 3
# b 4 5 6 7print(a1.set_index("A",drop=False),"\n","#"*50) # 将某列索引下的元素设置为行索引(内部参数drop等于假时被设置为索引的那一列元素将不会消失,为真时将会消失)
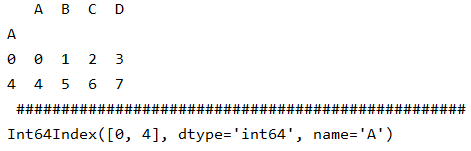
print(a1.set_index("A").index,"\n","#"*50) # 输出设定后的索引# B C D
# A
# 0 1 2 3
# 4 5 6 7
五、去除重复的元素 unique()
import pandas as ps
import numpy as npa2 = ps.DataFrame(np.ones(8).reshape((2,4)),columns=["A","B","C","D"]) # 设置一个全为1的2*4的二维数组
print(a2,"\n","#"*50)# A B C D
# 0 1.0 1.0 1.0 1.0
# 1 1.0 1.0 1.0 1.0a2 = a2.set_index("A",drop=False) # 将A索引下的元素设置为行索引(索引可为相同的值)
print(a2,"\n","#"*50)print(a2.loc[1.0,"A"].unique(),"\n","#"*50) # unique()方法过掉重复的元素

六、复合索引 set_index([])
import pandas as ps
import numpy as npa2 = ps.DataFrame(np.ones(8).reshape((2,4)),columns=["A","B","C","D"]) # 设置一个全为1的2*4的二维数组(重新赋值)
a2 = a2.set_index(["A","B"],drop=False) # 复合索引,可以将多列设置为索引
print(a2,"\n","#"*50,"\n",a2.index) # 输出a2和它的索引

1、复合索引查找数值 loc
import pandas as ps
import numpy as npa3 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"])
print(a3,"\n","*"*50)
a3 = a3.set_index(["A","B"],drop=False) # 复合索引,可以将多列设置为索引
print(a3,"\n","*"*50)# A B C D
# A B
# 0 1 0 1 2 3
# 4 5 4 5 6 7print(a3.loc[0].loc[1,"C"],"\n","*"*50) # 通过loc方法一层一层索引到需要的数值


1、复合索引查找数值 swaplevel() + loc
import pandas as ps
import numpy as npa3 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"])
print(a3,"\n","*"*50)
a3 = a3.set_index(["A","B"],drop=False) # 复合索引,可以将多列设置为索引
print(a3,"\n","*"*50)# A B C D
# A B
# 0 1 0 1 2 3
# 4 5 4 5 6 7print(a3.swaplevel(),"\n","*"*50) # swaplevel() 将内索引和外索引调换位置# A B C D
# B A
# 1 0 0 1 2 3
# 5 4 4 5 6 7print(a3.swaplevel().loc[1,"C"]) # 用swaplevel() 方法调换了内外索引后就可以直接使用loc索引到需要的数值了