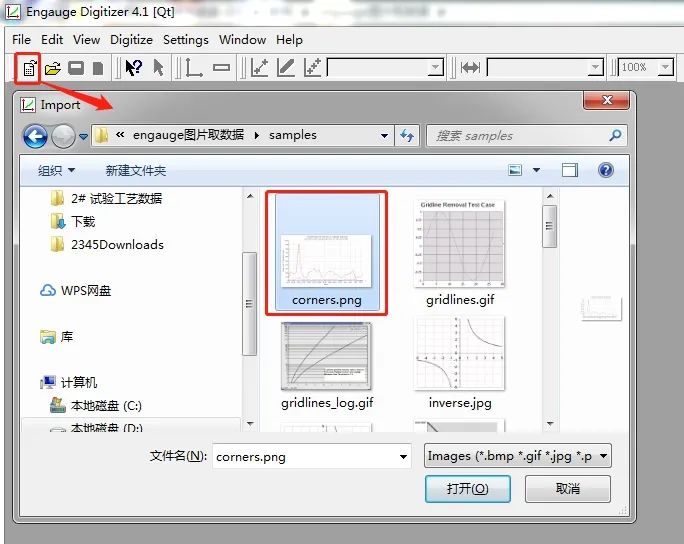
CDA数据分析师 出品
当你想对时间序列数据做分类时,有两种选择,一个是用时间序列特定的方法,比如说说LSTM模型。另外一种方法就是来从时间序列中提取特征从而将这些特征用在有监督的模型上。在这篇文章中,我们来看下如何使用tsfresh包自动的提取时间序列数据。
这份数据的来源是 。这个网站中提供对很多数据集有高精度的模型,如何有兴趣的,可以去详细了解一下。时间序列比一般标准的目标要难一些,这是因为在时间序列里的数据本身每个样本就不是独立的,两个时间上月接近的样本,就越有相关性。比如说温度,如果今天的温度问20度,那明天更加有可能是15或者25度,而不是5或者35度。
这表明这我们不能用常见的分类器来拟合数据,因为对于普通的分类器来说,数据的假设前提都是需要是样本和样本是独立的。并且更重要的是,有的和时间相关的数据集有更加复杂的结构,一个样本包含了多个特征,比如说温度,湿度,分速等等。
虽然说时间序列的数据很特别,但是我们可以使用特征提起的方法将一个序列降低到一个点。比如说,如果我们现在是在对一个月内的天气相关的数据做处理,我们可以使用以下多个特征:
- 最小最大温度
- 温度平均值
- 温度方差
- 最小最大湿度
这里只是给出了几个例子而已,当然了这里可以有很多种特征,将他们全部列举出来会特别麻烦,幸运的是,有一个tsfresh包,可以自动的提取出很多特征。
tsfresh包在提取出的众多的特征中,需要选取其中最为相关的,最具有预测能力的特征。并且为了防止过拟合,需要首先对数据集做切分,并且只对训练集做特征选择,否则会造成过拟合的问题。tsfresh包使用的是成对检验法来做特征选择的。
我们先来从 数据列表列提取3个时间序列数据集,FordA, FordB, 和Wafre.并且这些数据集中提取特征。首先我们需要将这些1维的数据给上下拼接起来。
In [9]: d.head()Out[9]: 0 1 2 30 1.01430 1.0143 1.01430 1.014301 -0.88485 -1.0375 -0.97771 -1.016902 0.58040 0.5804 0.59777 0.597773 -0.88390 -1.0371 -0.97998 -1.012104 1.10500 1.2856 1.19630 1.25610
需要使用stack做一次拼接
d = d.stack()d.index.rename([ ‘id’, ‘time’ ], inplace = True )d = d.reset_index()
得出以下的结果
In [11]: d.head()Out[11]: id time 00 0 0 1.01431 0 1 1.01432 0 2 1.01433 0 3 1.01434 0 4 1.0143
特征提取的工作量是非常大的,所以tsfresh使用分布计算的方法来高效的做特征提取。另外一种方式就可以直接设置n_jobs为1。具体代码为以下
f = extract_features( d, column_id = “id”, column_sort = “time” )# Feature Extraction: 20it [22:33, 67.67s/it]
这个时候f中有一些特征是空值,可以使用tsfresh提供的impute函数过滤掉这些特征
impute( f )assert f.isnull().sum().sum() == 0
当做特征选择的时候,有一个fdr_level超参数,这指的是所有不相关特征占总体的理论期望阈值,默认值为5%,也就是从生产的特征中,删除掉最不相关的特征,且这部分特征占总比的5%。有的时候我们还是需要加大这个值到0.5,甚至0.9,从而可以选取最重要的特征,并且防止纬度灾难。
In [2]: run select_features.pyloading data/wafer/features.csvselecting features…selected 247 features.saving data/wafer/train.csvsaving data/wafer/test.csv
当数据训练好之后,则就可以开始使用逻辑回归等分类器来对模型做拟合了。