如何用java爬取网页源代码
分为3个步骤:
- 分析实现方式
- 代码展示
- 结果展示
1、分析
以b站为例 抓取b站的源代码是这样的
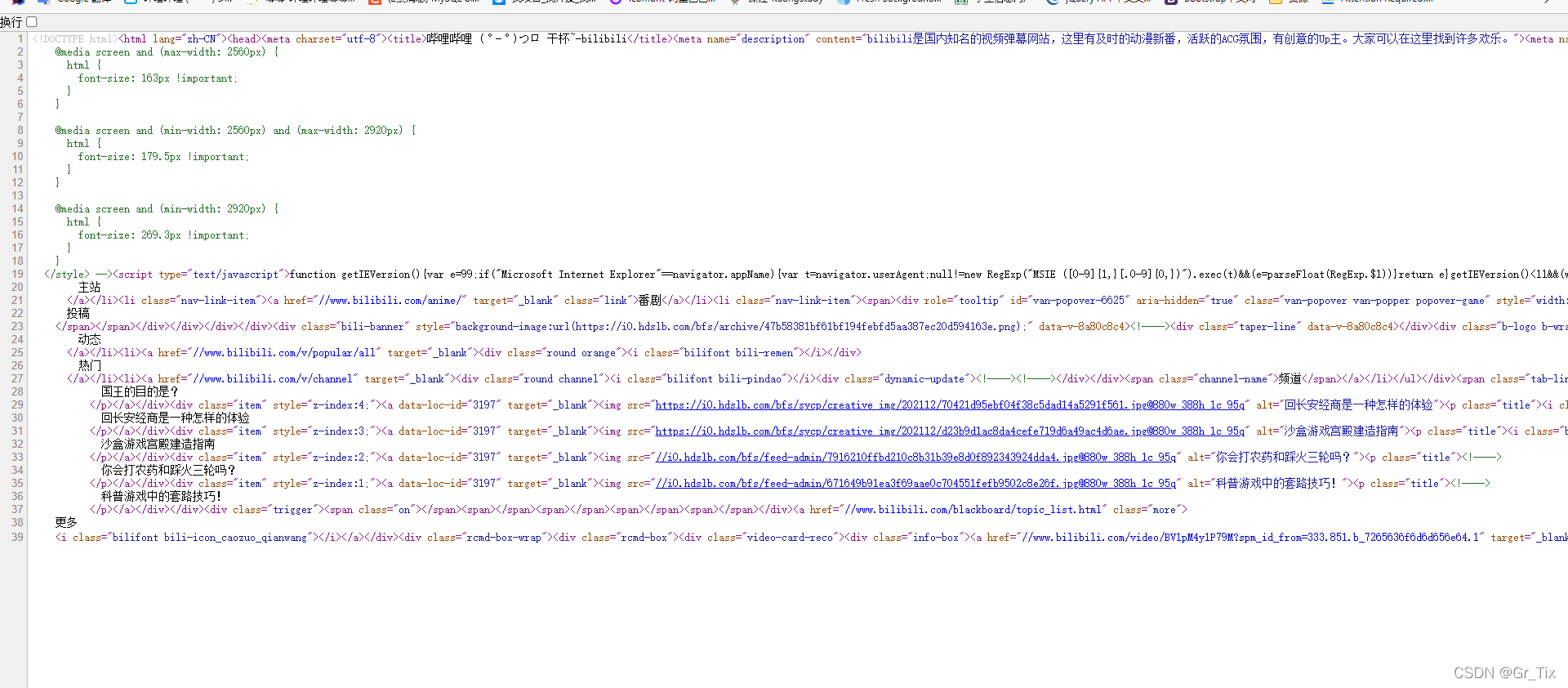
那么我可以用URL对象获取HttpURLConnection对象
HttpURLConnection对象:它继承自URLConnection,可用于向指定网站发送GET请求、POST请求。
调用URL中的 openConnection()再通过强转获得连接对象HttpURLConnection
HttpURLConnection 向网页发送请求然后我们读取网页的源代码
在我们发送请求的时候可能有些网址会报一个错误:Server returned HTTP response code: 403 for URL
这个错误的意思大概就是服务器的安全设置不接受Java程序作为客户端访问
这个时候我们需要进行安全设置:
//这个方法是HttpURLConnection中的方法 参数内容具体什么意思我也不知道,反正就是设置安全性
setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
既然说到读取 那么就需要InputStream输入流 在HttpURLConnection有个 getInputStream()方法 可以获取我们的输入流对象
获取到了输入流就等于是已经拿到了源码
下面展示代码 我会把捕获到的源码写入到txt文件中
2、代码展示
main方法
public static void main(String[] args) throws Exception{getURLData("https://www.bilibili.com/","utf-8");
}
getURLData是我自己定义的方法 我是在方法中实现获取源码
getURLData 方法
static void getURLData(String Url, String coding) throws Exception {//创建URL对象 参数设置需要爬取的网址 也就是我们方法传过来的参数URL url = new URL(Url);//得到一个HttpURLConnection 对象HttpURLConnection huc = (HttpURLConnection) url.openConnection();//防止出现Server returned HTTP response code: 403 for URL 的错误//也就是服务器的安全设置不接受Java程序作为客户端访问 所以我们进行安全设置huc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");//通过HttpURLConnection获得输入流对象InputStream is = huc.getInputStream();//使用缓冲字符输入流获取源码 设置编码BufferedReader r = new BufferedReader(new InputStreamReader(is,coding));String line;//写入文件中BufferedWriter bw = new BufferedWriter(new FileWriter("E:\\1、idea项目\\算法和数据结构\\Demo\\src\\test\\_爬网址源码\\1.txt"));//readLine()一次读一行 while ((line = r.readLine()) != null){bw.write(line);//读完一行就换行bw.newLine();//清空缓冲区bw.flush();}//关闭资源bw.close();r.close();is.close();
}
3、结果展示
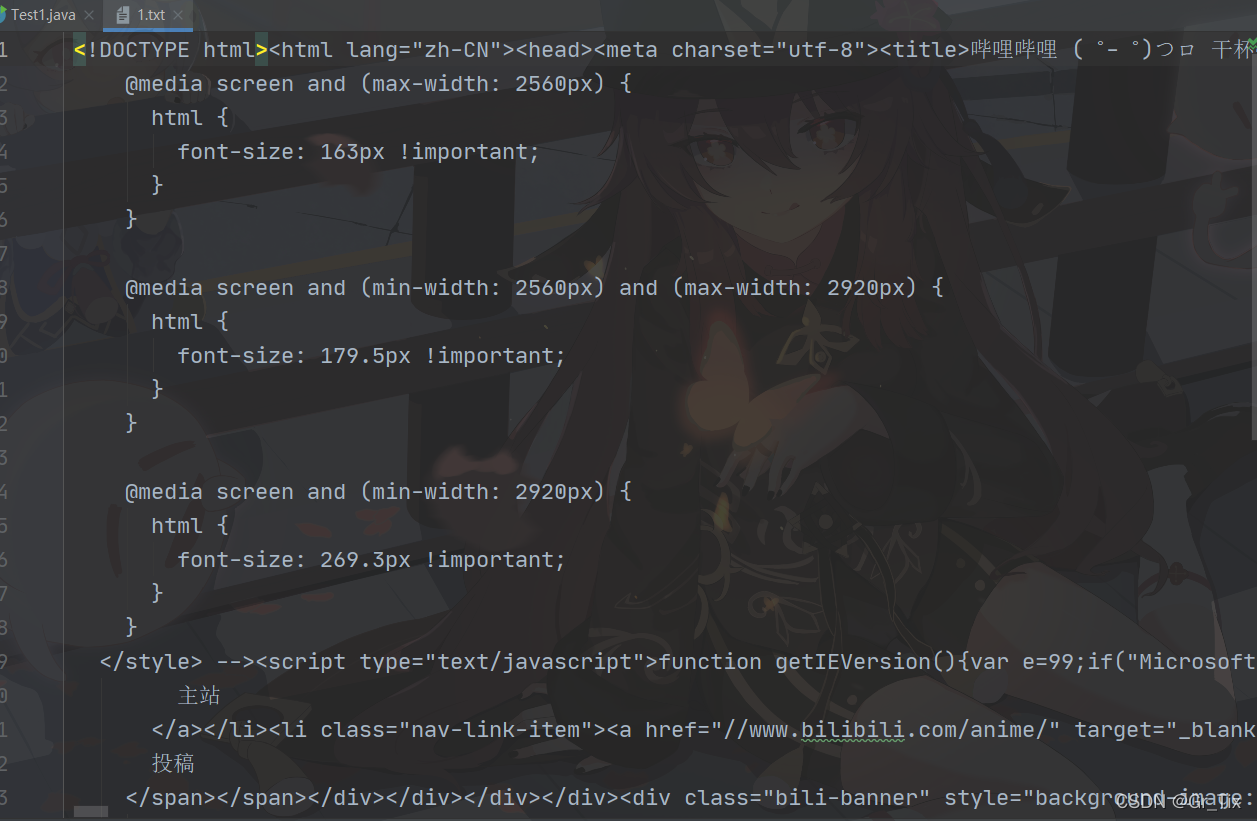
这样我们就获得了b站的源代码,如果想要只爬取自己想要的数据
那么对数据(字符串)进行一个过滤就行了
学会了的点个赞吧~