发现用python用requests在百度中获得的代码有乱码
import requests
# 0.通过如下代码,会发现获取的网页源代码出现乱码
url = 'https://www.baidu.com'
res = requests.get(url).text
print(res)

出现乱码
查看python获得的编码格式
import requests
# 0.通过如下代码,会发现获取的网页源代码出现乱码
url = 'https://www.baidu.com'
res = requests.get(url).text
print(res)# 1.编码分析
# 1.1 查看Python获得的网页源代码的编码方式,其编码方式为ISO-8859-1
url = 'https://www.baidu.com'
code = requests.get(url).encoding
print('通过Python获得的网页源代码的编码方式为:' + code)

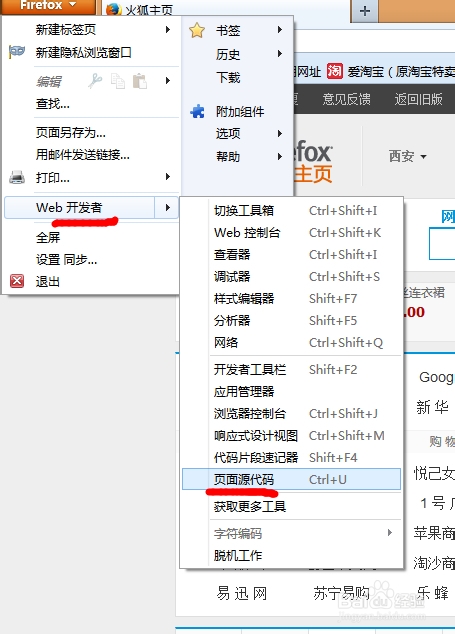
网页获取的格式
按F12在head中查看

发现为utf-8编码需要转码
import requests
# 0.通过如下代码,会发现获取的网页源代码出现乱码
url = 'https://www.baidu.com'
res = requests.get(url).text
print(res)# 1.编码分析
# 1.1 查看Python获得的网页源代码的编码方式,其编码方式为ISO-8859-1
url = 'https://www.baidu.com'
code = requests.get(url).encoding
print('通过Python获得的网页源代码的编码方式为:' + code)# 1.2 查看网页实际的编码方式,通过F12查看,展开最上方的head标签(head标签里主要用来存储编码方式、网站标题等信息),
# 其中<meta charset="编码方式">中存储着网页实际的编码方式,可以看到网页实际的编码方法为utf-8
# 2.重新编码及解码
url = 'https://www.baidu.com'
res = requests.get(url).text
res = res.encode('ISO-8859-1').decode('utf-8')
print(res) # 此时便已经可以解决数据乱码问题了
还有gbk的编码格式
其它情况的完整代码如下:
# =============================================================================
# 5.2 数据乱码常规处理方法 by 王宇韬 代码更新:www.huaxiaozhi.com 资料下载区
# =============================================================================import requests
# 0.通过如下代码,会发现获取的网页源代码出现乱码
url = 'https://www.baidu.com'
res = requests.get(url).text
print(res)# 1.编码分析
# 1.1 查看Python获得的网页源代码的编码方式,其编码方式为ISO-8859-1
url = 'https://www.baidu.com'
code = requests.get(url).encoding
print('通过Python获得的网页源代码的编码方式为:' + code)# 1.2 查看网页实际的编码方式,通过F12查看,展开最上方的head标签(head标签里主要用来存储编码方式、网站标题等信息),
# 其中<meta charset="编码方式">中存储着网页实际的编码方式,可以看到网页实际的编码方法为utf-8
# 2.重新编码及解码
url = 'https://www.baidu.com'
res = requests.get(url).text
res = res.encode('ISO-8859-1').decode('utf-8')
print(res) # 此时便已经可以解决数据乱码问题了# 注意,如果有的网站的实际编码方式为gbk,则在decode解码的时候需要把utf-8换成gbk
# 补充知识点:encode()编码函数与decode()解码函数
# encode()编码函数
res = '华小智' # 中文字符串
res = res.encode('utf-8') # encode编码将中文字符串转为二进制
print(res)# decode()解码函数
res = b'\xe5\x8d\x8e\xe5\xb0\x8f\xe6\x99\xba' # 二进制字符
res = res.decode('utf-8') # decode解码将二进制字符转为字符串
print(res)# 3.数据乱码万金油的解决办法
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}url = 'https://www.baidu.com'
res = requests.get(url).text
# res = requests.get(url, headers=headers).text # 这里加headers能获取更多的网页源代码
try:res = res.encode('ISO-8859-1').decode('utf-8') # 方法3
except:try:res = res.encode('ISO-8859-1').decode('gbk') # 方法2except:res = res # 方法1
print(res) # 可以在源代码里搜索“百度”检验爬取成功