python爬取原创力文档并且保存为pdf文件(部分版保姆级
文章目录
- *python爬取原创力文档并且保存为pdf文件*(部分版保姆级
- 前言
- 一、爬取背景?
- 二、正(bai)式(piao)操作
- 1.安装库
- 2.导入项目所需库
- 3.正文开始
- 3.2检查文档并分析
- 3.2对网页进行抓包分析
- 3.3爬虫构造
- 爬虫三部曲(一):请求数据
- 爬虫三部曲(二):解析数据
- 爬虫三部曲(三):保存数据下载图片
- 3.4图片转pdf
- 获取完整版输入关键字爬取此关键字的所有文档代码
- 总结
前言
此文仅供学习参考,切记不可商用!!!,
有完整版输入想要爬取的关键词,
即可下载原创力文档里面的所有有关此关键词的所有文档,
但考虑到人数过多可能对原创力服务器压力过大,就不做全部解析
只对爬取单个文档进行介绍,如果想获取完整版代码,
请关注微信公众号***【小码鱼】***联系我获取,
里面可以查看有关python 或arduino诸多
相关案例和教程,分享更多干货。FF
提示:以下是本篇文章正文内容,下面案例可供参考,不可商用,转载请注明出处。此文纯属分享爬虫思路,大家还是要支持版权。
一、爬取背景?
今天因为想找一份资料,去到百度一搜,发现原创力文档里面有我想要的内容,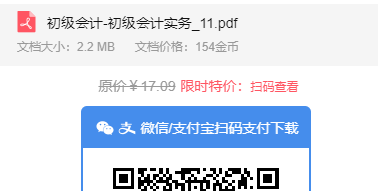
但好家伙居然要扫码支付才能下载文档,
💢💢💢这对技术人能忍?

对一个深度白嫖技术人想要的东西怎么能付费呢?
话不多说,说干便干
进入我们的正(bai)式(piao)操作。
二、正(bai)式(piao)操作
1.安装库
此文所需要的库有pil ,os,re,requests,Beautifulsoup,json:
其中os为python自带库无需安装
其余库皆可使用 pip install xxx
例如:
pip install PIL
pip install bs4
pip install re
pip install requests
pip install json
2.导入项目所需库
代码如下(示例):
import urllib.request as ur#下载图片
import requests#网络请求
import re#正则匹配
import json#提取api数据
import time#时间库
from PIL import Image#处理图片
import os#文件操作
该处为本文所需要的库函数。
3.正文开始
3.2检查文档并分析
首先我们打开我们想要下载的的文档,
然后鼠标右键点击文档页面
检查查看源代码,也可以直接按f12
打开源代码后我们点左上角
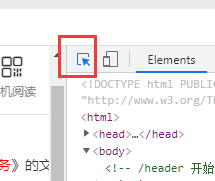
点击按钮变为蓝色后,用鼠标点击页面图片快速找到页面图片源码所在在位置。
我们点击后发现源码位置定位到了一条不相关语句,

我们点开上方div前的小三角看一下,
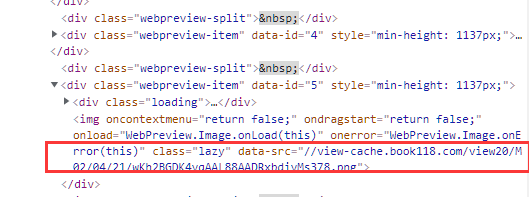
看到源码里的<img标签,里面包含了一串链接
猜想这就是图片链接吧
我们双击此链接crtl+c把此链接复制到浏览器新页面打开发现此图片就是我们检查元素的图片,
(这里可能不是你点击检查的图片,但在同一个文档里),找到链接后就好办了
接下来
我们回到文档界面在文档链接前面加上view-source:查看文档源代码

按下回车出现如图所示界面

然后我们按下ctrl+F对页面元素进行查找刚才复制的图片链接
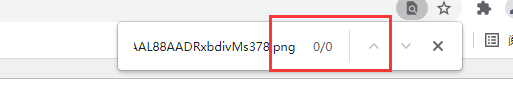
发现在源码里找不到图片的链接,这说明此文档为动态加载,遇到动态加载怎么办呢?
这就需要我们对浏览器进行抓包分析。
3.2对网页进行抓包分析
回到源码界面点击network选项卡
然后鼠标点击js选项按下F5刷新页面对动态请求抓包
刷新之后我们一个一个请求进行查看注意点到preview选项卡
然后我们看到最下面一个带有html?的请求打开之后是一些链接,对链接复制到新的页面进行查看发现正是我们想要的图片的链接(下面链接打开为上方图片内内容)

发现链接之后我们就要去查看它得到这些链接的请求方式我们切换回到headers选项卡

对requests_url复制到新的浏览器页面进行查看
打开后发现是一串像json的数据

里面包含了需要的图片链接,好了万事俱备,就该来构造我们的爬虫了
3.3爬虫构造
爬虫三部曲(一):请求数据
请求第一步是要先构造我们的链接

?后面为链接的参数有些东西不是必须的所以我们只保留关键链接和重要参数
可以构造一个名为params的字典把参数存进去,其中重要参数有

然后就是爬虫头伪装 user_agent,cookie,refer
最终代码为这个样子
seeion=requests.Session()#这里用来存储状态
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.124 Safari/537.36 qblink wegame.exe WeGame/5.0.4.8192 QBCore/3.70.101.400 QQBrowser/9.0.2524.400','Host': 'openapi.book118.com','Cookie': 'CLIENT_SYS_UN_ID=wKh2CmE56HRuhr8Wq5haAg==; __yjs_duid=1_64509509bcfb3fb3252e11a3c6ae100d1631186596044; EXAMINE_CLOSE=true; 30d8fb61e609cac11=1631694291%2C1; 0ab7d33081eeb=arduino; input_search_logs=a%3A4%3A%7Bi%3A0%3Ba%3A2%3A%7Bs%3A8%3A%22keywords%22%3Bs%3A7%3A%22arduino%22%3Bs%3A4%3A%22time%22%3Bi%3A1631773441%3B%7Di%3A1%3Ba%3A2%3A%7Bs%3A8%3A%22keywords%22%3Bs%3A11%3A%22arduino+%E8%BD%A6%22%3Bs%3A4%3A%22time%22%3Bi%3A1631675780%3B%7Di%3A2%3Ba%3A2%3A%7Bs%3A8%3A%22keywords%22%3Bs%3A13%3A%22arduino%E5%B0%8F%E8%BD%A6%22%3Bs%3A4%3A%22time%22%3Bi%3A1631510790%3B%7Di%3A3%3Ba%3A2%3A%7Bs%3A8%3A%22keywords%22%3Bs%3A15%3A%22%E5%8E%9F%E5%88%9B%E5%8A%9B%E6%96%87%E6%A1%A3%22%3Bs%3A4%3A%22time%22%3Bi%3A1631510773%3B%7D%7D; PREVIEWHISTORYPAGES=45138893_2,147911206_1,188979028_19,51185244_20,202962949_1,154525691_24,189956752_8,332281980_2,332281917_1,181595818_1,80027377_8,137736285_5,334760271_1,315218716_4,355261628_4,285194752_2,282245445_1,196615342_1,139214192_1,182435414_5,129025809_3,232954297_5,280705767_1,97510779_3,130246177_5,139213526_1,161582380_3,314355454_5,316143061_1,396617400_52,331274945_13; Book118UserFlag=%7B%22189956752%22%3A1631517003%2C%22154525691%22%3A1631594623%2C%22202962949%22%3A1631675567%2C%2251185244%22%3A1631769644%2C%22322848463%22%3A1631769625%2C%22188979028%22%3A1631772185%2C%22204014911%22%3A1631698444%2C%22147911206%22%3A1631772464%2C%22108286410%22%3A1631772597%2C%22196615342%22%3A1631772638%2C%2249734221%22%3A1631772769%2C%2245138893%22%3A1631772821%2C%22158815913%22%3A1631772856%2C%22326438730%22%3A1631772911%2C%2230197720%22%3A1631772973%2C%22181696486%22%3A1631773001%2C%2247453316%22%3A1631773114%2C%22175196219%22%3A1631773136%2C%2244149489%22%3A1631773172%2C%22213873416%22%3A1631773198%2C%22139213526%22%3A1631773535%2C%22139213527%22%3A1631774577%2C%22139213516%22%3A1631773643%2C%22313170487%22%3A1631774036%2C%22402633267%22%3A1631774055%2C%22161582380%22%3A1631774086%2C%22100771870%22%3A1631774196%2C%22368624467%22%3A1631774882%2C%22115786411%22%3A1631778328%2C%22108799065%22%3A1631781985%7D; Book118UserFlag__ckMd5=7019befe3e43e8d4; 94ca48fd8a42333b=1631781985%2C38; PHPSESSID=6s0jc7b05ri57u2ljv9k6a34j4; Hm_lvt_f32e81852cb54f29133561587adb93c1=1631592934,1631675567,1631769615,1631784629; s_rfd=cdh%3D%3E27a30245%7C%7C%7Ctrd%3D%3Emax.book118.com%7C%7C%7Cftrd%3D%3Ebook118.com; s_m=cdh%3D%3E27a30245%7C%7C%7C-1242275241%3D%3Ebanner_search_history_href%7C%7C%7C-1858228461%3D%3Esearch_filter_item_href; d6b93d63cc960c878126=1631786728%2C2; s_v=cdh%3D%3E27a30245%7C%7C%7Cvid%3D%3E1631185013201896616%7C%7C%7Cfsts%3D%3E1631185013%7C%7C%7Cdsfs%3D%3E7%7C%7C%7Cnps%3D%3E26; s_s=cdh%3D%3E27a30245%7C%7C%7Clast_req%3D%3E1631786729%7C%7C%7Csid%3D%3E1631786729611771331%7C%7C%7Cdsps%3D%3E0; Hm_lpvt_f32e81852cb54f29133561587adb93c1=1631786729'}
params = {'project_id': '1','aid': '373546591','view_token':'Jrxk0TZavDl4C7d00hM3ehM_BwD0Hqxy','page': '1',}
response=seeion.get('https://openapi.book118.com/getPreview.html',headers=headers,params=params)
print(response.text)最后对结果打印,有以下结果返回
jsonpReturn({"status":200,"message":"ok","data":{"1":"\/\/view-cache.book118.com\/view20\/M02\/04\/21\/wKh2BGDK4vqAdKReAADvZpnNeCo015.png","2":"\/\/view-cache.book118.com\/view20\/M02\/04\/21\/wKh2BGDK4vqAFHYXAAEDFQL_F-k232.png","3":"\/\/view-cache.book118.com\/view20\/M02\/04\/21\/wKh2DmDK4vqAT2YkAADP1CFIgL0666.png","4":"\/\/view-cache.book118.com\/view20\/M00\/04\/21\/wKh2DmDK4vqAU5YRAAEGgF2iW6g406.png","5":"\/\/view-cache.book118.com\/view20\/M02\/04\/21\/wKh2BGDK4vqAAL88AADRxbdivMs378.png","6":"\/\/view-cache.book118.com\/view20\/M03\/04\/21\/wKh2DmDK4vqALLouAAD2s6favDc952.png"},"pages":{"preview":"18","actual":"18","filetype":"pdf"}});有了链接就要对链接进行解析,清洗获得我们想要的东西。
爬虫三部曲(二):解析数据
首先对我们请求返回的数据通过正则表达式去除不相关元素清洗得到json格式的数据
json_data=re.search(r'jsonpReturn\((.*?)\);',response.text).group(1)#这里前面一个括号也是需要去除的内容所以需要用转义字符给他忽略
jsons=json.loads(json_data)
print(jsons['data'])#这里对json数据里的链接进行提取
打印结果如下图所示:为一个字典格式
{'1': '//view-cache.book118.com/view20/M02/04/21/wKh2BGDK4vqAdKReAADvZpnNeCo015.png', '2': '//view-cache.book118.com/view20/M02/04/21/wKh2BGDK4vqAFHYXAAEDFQL_F-k232.png', '3': '//view-cache.book118.com/view20/M02/04/21/wKh2DmDK4vqAT2YkAADP1CFIgL0666.png', '4': '//view-cache.book118.com/view20/M00/04/21/wKh2DmDK4vqAU5YRAAEGgF2iW6g406.png', '5': '//view-cache.book118.com/view20/M02/04/21/wKh2BGDK4vqAAL88AADRxbdivMs378.png', '6': '//view-cache.book118.com/view20/M03/04/21/wKh2DmDK4vqALLouAAD2s6favDc952.png'}对字典进行遍历,我们便得到了我们想要的图片的链接序号和链接`
urls=jsons['data']
for i in urls.items():print(i)('1', '//view-cache.book118.com/view20/M02/04/21/wKh2BGDK4vqAdKReAADvZpnNeCo015.png')
('2', '//view-cache.book118.com/view20/M02/04/21/wKh2BGDK4vqAFHYXAAEDFQL_F-k232.png')
('3', '//view-cache.book118.com/view20/M02/04/21/wKh2DmDK4vqAT2YkAADP1CFIgL0666.png')
('4', '//view-cache.book118.com/view20/M00/04/21/wKh2DmDK4vqAU5YRAAEGgF2iW6g406.png')
('5', '//view-cache.book118.com/view20/M02/04/21/wKh2BGDK4vqAAL88AADRxbdivMs378.png')
('6', '//view-cache.book118.com/view20/M03/04/21/wKh2DmDK4vqALLouAAD2s6favDc952.png')
但只有六页图片的链接,但我们需要的文档总共有18页,不可能就下载六页吧!
欸,不急我们接着往下看。我们继续去抓包,看看下面的图片是由哪里的链接加载来的。
点击继续预览同时看源码部分多了一些请求链接,我们打开下一个跟这个有点相似的小兄弟
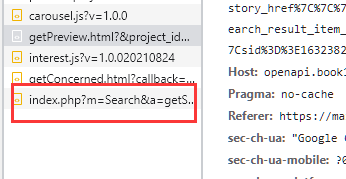
对他进行检查发现这两家伙只是page 后面的参数不一样
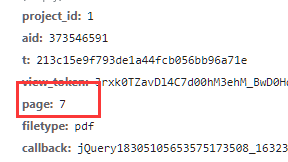
既然只有这一部分不一样那我们就对他进行构造,怎样构造呢?我们前面说过参数是可以写在params字典中的,那我们就设置一个循环让它遍历
for page in range(1,19,6):#这里第二个参数为你需下载文档的总页数加一params = {'project_id': '1','aid': '373546591','view_token':'Jrxk0TZavDl4C7d00hM3ehM_BwD0Hqxy','page': page,}response=seeion.get('https://openapi.book118.com/getPreview.html',headers=headers,params=params)json_data=re.search(r'jsonpReturn\((.*?)\);',response.text).group(1)jsons=json.loads(json_data)urls=jsons['data']for i in urls.items():print(i)
但可能因为请求速度过快的原因后面加载不出数据

这里的话我们可以加一个延时,但延时太鸡肋,没多大用
所以我们对代码进行修改一下判断请求后的字典里有没有数据,如果没有就再次请求
请求直到成功为止
ef url_requests():response=seeion.get('https://openapi.book118.com/getPreview.html',headers=headers,params=params)json_data=re.search(r'jsonpReturn\((.*?)\);',response.text).group(1)jsons=json.loads(json_data)urls=jsons['data']if urls.get(str(page))=='':print('再次请求:')return url_requests()else:return urlsurls=url_requests()for i in urls.items():print(i)获取到连接之后,我们就要把链接图片保存到本地
爬虫三部曲(三):保存数据下载图片
这里我们使用了urllib库函数
一行代码对图片进行保存
ur.urlretrieve(img_url,'{}.png'.format(i[0]))
到此为止下载图片完整代码如下
import requests
import re
import json
import os
import urllib.request as urfile_path=input("请输入你要保存文档的绝对路径:")
file_name=input("请输入你要保存文档的名字:")
save_path=os.path.join(file_path,file_name)
seeion=requests.Session()
headers = {'User-agent': 换成你自己的'Host': 'openapi.book118.com','Cookie': 这里请换成你自己的
}
for page in range(1,19,6):params = {'project_id': '1','aid': '373546591','view_token':'Jrxk0TZavDl4C7d00hM3ehM_BwD0Hqxy',#这里记得修改自己想下文档'page': page,}def url_requests():response=seeion.get('https://openapi.book118.com/getPreview.html',headers=headers,params=params)json_data=re.search(r'jsonpReturn\((.*?)\);',response.text).group(1)jsons=json.loads(json_data)urls=jsons['data']if urls.get(str(page))==None:print('再次请求:')return url_requests()else:return urlsurls=url_requests()for i in urls.items():img_url = 'https:' + i[1]if os.path.exists(save_path):os.chdir(save_path)else:os.makedirs(save_path)#这里用来判断存储路径存不存在,存在的话切换工作路径,不存在创建再切换os.chdir(save_path)try:ur.urlretrieve(img_url,'{}.png'.format(i[0]))except:print(str(i[0]) + '图片下载出错')然后图片就都被下载到了文件夹里就像这个样子

有了图片呢我们就需要把他转变为pdf并且把图片删除仅保留pdf版本
3.4图片转pdf
path = os.path.join(file_path,file_name)name = file_nameimg_list = [] # 创建打开后的图片列表filename=os.listdir(path)filess=sorted(filename,key=lambda x:int(x[0:-4]))for files in filess:if files.endswith('png'):file = os.path.join(path, files) # 遍历所有图片,带绝对路径img_open = Image.open(file) # 打开所有图片if img_open.mode != 'RGB':img_open = img_open.convert('RGB') # 转换图像模式img_list.append(img_open) # 把打开的图片放入列表try:os.remove(file)#删除图片except:print(file)pdf_name = name + '.pdf' # pdf文件名img_2 = img_list[0] img_open_list = img_list[1:]img_2.save(path + pdf_name, "PDF", resolution=100.0, save_all=True,append_images=img_open_list)print('pdf文件已经保存在' + path + '目录下!')
最后每次想要下载一个网页总要去找aid,view_token实在太麻烦 所以作者对源码进行了整理 每次只要输入链接和保存地址即可以自动下载并生成pdf
如有需要的小伙伴可以关注我的微信公众号【小码鱼】回复【原创力源码】获取

获取完整版输入关键字爬取此关键字的所有文档代码
关注微信公众号【小码鱼】联系我获取,
同时能获得更多有用的python,c++,arduino知识,
以及各种好玩的python代码
小白也可以在上面学到更多的有用知识哦!
共同学习,共同进步,有问题可以找我多多交流哦!!!!