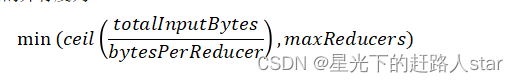很酷哦!
不过,对我这个选择恐惧症来说,也很纠结…
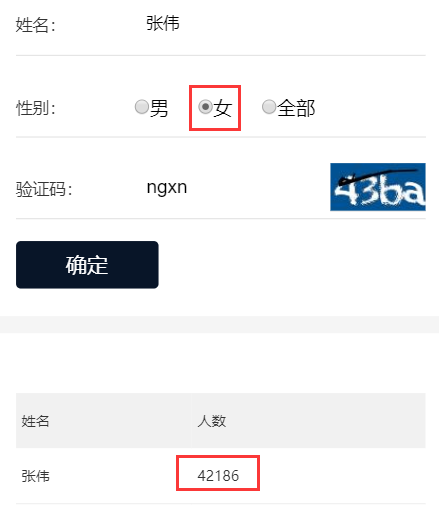
我们先看一下有哪些要求吧?
中草药名?人参?西洋参?还有啥???
作为一个不怎么吃药的非医学生,这题真的超纲了呀。我只能求助度娘。
但是有个问题,我会百度,别人也会百度呀。
那这些好听的名字,我估计大半都被人用去了。
不行,我一定要取一个独一无二的名字!
这些人为挑选出来的名字代表了大众普遍的审美
我要做颜色不一样的烟火
我要自己筛选~
素材呢?素材自己爬一下呗。
本次使用的是Python(编译器是pyhcarm)
作为一个python新手
虽说这次任务是为了取名字
但更重要的也是为了练习一下自己刚学习的python
我发现,看书看视频
这些单纯索取的学习方式不太适合我 : (
目标驱动法才更使得我有学习的动力 : )
我挑选的网站是“中药网”(侵删!)
(http://m.zhongyoo.com/)
切换到“查询”页面,一共有65页
每页有13种中草药(除了最后一页只有8种)
国际惯例,第一步右击“检查”,找中草药的名字在哪块:
看样子是在class=t的位置,再看一下其他的中药名,也都在这个位置,那就get吧。
1res=requests.get(‘http://m.zhongyoo.com/name/page_1.html’)
2res.encoding='gbk'
3soup=BeautifulSoup(res.text,'html.parser')
4
5plant_names=[]
6names=soup.select('.t')
7for name in names:
8 plant_names.append(name.text)
没错,7行就爬下了这一页的所有名字。
观察一下第1页网址:http://m.zhongyoo.com/name/page_1.html
观察一下第2页网址:http://m.zhongyoo.com/name/page_2.html
观察一下第3页网址:http://m.zhongyoo.com/name/page_3.html
区别在哪呀?小学生都能看出来,在倒数第6个字符!从1变成了2再变成了3。
发现了这个规律,我们就能愉快地利用函数来爬后面几页的名字啦。参数自然就是从1变到65的变量啦。
不得不说
控制台不断弹出来的“第X页数据摘取完毕!”这些话
真的太治愈了哈哈哈
此画面引起极端舒适!
然后我们就如愿得到这840个名字啦!
(部分结果)
BUT!
正当我美滋滋准备导出数据开始挑选的时候
我“一不小心”点进一个中草药的链接里面去
发现……
???还有别名??
也行吧,那就别名也爬一下…
既然是点进每一个链接才能查找到“别名”的数据,那么在起始页不仅要爬名字,还要将每个链接都抓取出来。“检查”了一下,发现链接位置和之前的名字不太一样:
搞不太清楚具体在哪里,因为不在普通的‘text’里面,我只能另辟蹊径,尝试一下正则表达式把地址找出来(天呐,其实我这个没玩过……但是迟早要学的,那就是现在吧!)
通过临时学习,我模仿了一下,我发现!正则表达式!真的很好用!真香!
1pattern = re.compile(r'http:.*?.html')
2plant_links = pattern.findall(html_sample)放到前面的函数里面,蹭蹭蹭,每一类中草药的名字和具体链接就出来啦!
有了链接就可以开始爬具体页面的别名了。
跟之前差不多的步骤,我再次用了正则表达式:查查筛筛扣扣拆拆合合,艰难而成功地找出来所有的别名:
1def getPlantBynames(url):2 res=requests.get(url)3 res.encoding='gbk'4 html_sample=res.text5 soup=BeautifulSoup(html_sample,'html.parser')6 header=soup.select('.art_1')7 bynames=header[0].text.replace("\n", "").replace('\t', '').strip()89 result=[]
10 if re.search('【别名】.*?【英文名】', bynames) is not None:
11 single_name = re.search('【别名】.*?【英文名】', bynames).group()[4:-8]
12 result.extend(single_name.split('、'))
13 return result方法肯定有很多种,我…下次再学!
然后呢,我们再把这个获取别名的函数放进刚刚的大函数里面,就可以在获取链接之后直接把链接当作参数用到这个函数里面,结果不用再导出链接,直接把“本名”和“别名”输出就好了。不瞒你们说,有四千多个名字!
我们先来瞧一瞧古人起名字都喜欢用什么字吧!
以前用过R语言做词云
现在为了学习我决定尝试用python
虽然语法不太一样
但是思想大致一样
我又看到了似曾相识的“jieba”:
1names=str()2for name in df['name']:3 names=names+name45result=jieba.cut(names,cut_all=True)6789cloud_text="".join(result)
10fre= Counter(cloud_text)
11
12mask = np.array(Image.open('flower.jpg')) # 定义词频背景
13 wc = wordcloud.WordCloud(
14 font_path='Hiragino Sans GB.ttc', # 设置字体格式
15 mask=mask, # 设置背景图
16 max_words=200, # 最多显示词数
17 max_font_size=150 # 字体最大值
18)
19
20wc.generate_from_frequencies(fre) # 从字典生成词云
21image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
22wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
23plt.imshow(wc) # 显示词云
24plt.axis('off') # 关闭坐标轴
25plt.show() # 显示图像
26wc.to_file('plant_names_pic.png')(学习这个大概花了我一半的时间,因为脑子一直没转过弯来)
词频top如下:
词云结果如下:
果然频率最高的就是那些“花”啊“草”的
比较令我意外的是“子”出现的频率很蛮高的
我个人觉得名字带“子”的还蛮好听的~
好了,现在开始回归正题,找花名!
用万能excel筛选出长度为2的名字
还有一千多个满足要求的!
之前吧,觉得百度出来的选择太少了
很容易和别人选得一样,没意思;
现在吧,选择倒是有很多
但是眼睛看看也很累诶~
删除掉自己名字里确切不想要的的一些字:
草,花,山,石,红,老,麻,菊,藤……
还剩好几百个名字……
那筛选出一些自己觉得比较好听的字
看看有没有适合的名字:
带“白的”:
带“苏”的:
带“青”的:
带数字的:
内心bb:看着吧,觉得都挺不错,但仔细看看,又觉得都不咋滴……
看来,对我这种选择恐惧症来说
不管是一千个选择还是两个选择,我都选不粗来!
我看呀,最好就是只给我一个选项!
什么“我来教你如何从四千个名字中挑选出最适合自己的花名”
我教不了!
886!
对了,有没有善良的人…给我一点点名字的建议…
不然我就决定叫“柚子”了
因为我家乡盛产文旦!
什么?柚子不是中草药?
无所谓啦,反正hr说了
一般水果都可以入药的!(逃…
﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌﹌
生活不易,必须多才多艺。
生活不易,必须多才多艺。
数据很多,Yura分析跟你说。
不定期更新数据分析小文章
请大家多多关注多多点赞多多转发:)
关注我