在感知系统中,我们与外部合作者一起创建逼真的 3D 人类,其行为可以像虚拟世界中的真实人类一样。这项工作在今天有许多实际应用,并且对于元宇宙的未来至关重要。但是,在感知系统中,我们的目标是科学的——通过重现人类行为来理解人类行为。
“我无法创造的东西,我就不明白。”理查德·费曼
我们在新环境中感知行为的能力对于我们的生存至关重要。如果我们能够在虚拟人类中重现这种能力,我们将拥有一个可测试的自我模型。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
我们的方法具有三个相互关联的支柱:捕获、建模、合成。我们的方法首先捕捉人类、他们的外表、他们的动作和他们的目标。利用这些捕获的数据,我们对人们的外表和行动方式进行建模。最后,我们在 3D 运动场景中合成人类并评估他们的真实程度。
我们的 ICCV 2021 论文提供了这种方法和当前技术水平的精彩快照。我将尝试将它们放在下面的上下文中。
1、捕获
为了了解人类,我们需要捕捉(Capture)他们的形状和动作。在捕获过程中,总是需要在数据的质量和数量之间进行权衡。在实验室中,我们可以捕获精确、高质量的数据,但数量始终有限。因此,我们也在野外进行捕捉,并不断开发新方法来从图像和视频中估计人体姿势和形状 (HPS)。在 ICCV,我们有使用这两种方法的论文。
1.1 实验室捕获
论文: Solving SOMA: Solving Optical Marker-Based MoCap Automatically
捕捉人体动作的“黄金标准”是基于标记的动作捕捉 (mocap)。为了发挥作用,动作捕捉流程将原始、稀疏的 3D 点云转换为可用数据。
第一步是通过将 3D 点分配到人体上的特定标记位置来清理和“标记”数据。标记后,人们就可以“解决”引起运动的身体。捕获大量动作捕捉数据的一个关键障碍是标记过程,即使采用最好的商业解决方案,仍然需要手动干预。被遮挡的标记和噪声会引起问题,特别是当人们使用新颖的标记集或人类与物体交互时。

在 ICCV,我们通过 SOMA 解决了这个问题,它采用原始点云并使用基于 Transformer 的堆叠注意力机制自动对其进行标记。该方法可以纯粹基于合成数据进行训练,然后应用于具有不同数量点的真实动作捕捉点云。
使用 SOMA,我们能够自动将 SMPL-X 身体拟合到以前从未处理过的原始动作捕捉数据,因为它太耗时了。我们已将其中一些数据添加到 AMASS 数据集中。
论文: Tofu:Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
同样,面部捕捉数据对于构建真实的人类模型至关重要。与动作捕捉不同,人们通常捕捉密集的 3D 面部几何形状。变得有用,例如对于机器学习,原始 3D 面部扫描需要在称为配准的过程中与模板网格对齐。使用传统方法进行注册可能会很慢且不完美。

在 ToFu(多视图拓扑一致的面)中,作者描述了一个推断 3D 几何结构的框架,该框架使用体积表示生成拓扑一致的网格。这与之前基于 3D“可变形模型”的工作不同。 ToFu 采用了一种新颖的渐进式网格生成网络,该网络将“面部的拓扑结构嵌入到特征体积中,从几何感知的局部特征中采样”。 ToFu 使用从粗到细的方法来获取细节,并且还“捕获孔隙级几何细节的位移图”。
1.2 野外捕获
论文: PARE: Part Attention Regressor for 3D Human Body Estimation
为了捕捉比实验室中更复杂、更真实的行为,我们需要在 2D 视频中跟踪 3D 人类行为。人体姿势和形状估计方面取得了快速进展,但现有的 HPS 方法仍然很脆弱,特别是在存在遮挡的情况下。在 PARE 中,我们提出了一种新颖的可视化技术,显示了现有方法对遮挡的敏感程度。利用这一点,我们发现小的遮挡会对身体姿势产生长期影响。

论文: SPEC: Seeing People in the Wild with an Estimated Camera
对遮挡的鲁棒性并不是限制 HPS 方法准确性的唯一因素。当前的方法通常假设弱透视相机模型并估计相机坐标系中的 3D 主体。这会导致许多问题,特别是当图像存在明显的透视缩短时,这在人物图像中很常见。为了解决这个问题,我们训练了 SPEC,它使用透视相机并估计世界坐标中的人。

我们的第一步是创建一个具有地面真实相机参数的渲染图像数据集,我们用它来训练一个名为 CamCalib 的网络,该网络可以从单个图像中回归相机视场、俯仰和滚动。
然后,我们训练一个新的 HPS 回归网络,将相机参数与图像特征连接起来,并使用它们来回归身体形状和姿势。这会提高 3DPW 等数据集的准确性。
我们还引入了两个新的数据集,其中包含地面真实姿势和具有挑战性的相机视图。 SPEC-MTP 使用 CVPR’21 TUCH 论文中的“模仿姿势”想法来捕捉真人,但将该想法扩展到捕捉相机校准。 SPEC-SYN 使用 AGORA 数据集的渲染方法,但具有更具挑战性的相机姿势,会导致透视缩短。
论文: Learning To Regress Bodies From Images Using Differentiable Semantic Rendering
在训练 PARE 和 SPEC 等 HPS 回归器时,我们通常依赖 2D 图像关键点,有时依赖 3D 关键点或 HPS 参数。图像中还有更多信息,但尚未被利用。例如,当前的 3D HPS 模型“穿着最少”,但真实图像中的人通常穿着衣服。在这里,我们展示了了解图像中的服装可以帮助我们训练神经回归器,从而更好地估计 HPS。
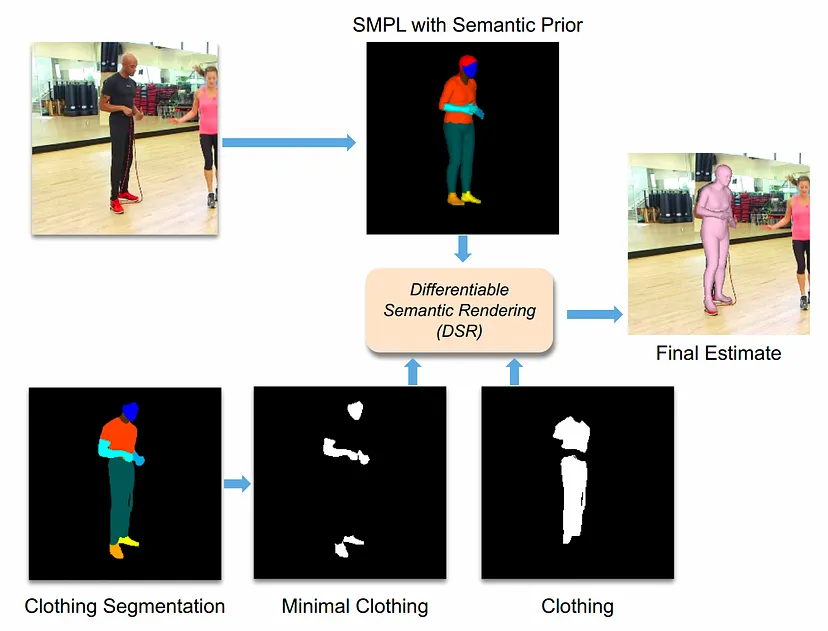
关键思想是在训练期间利用有关服装的信息。例如,在身体显示皮肤的区域中,我们期望身体与图像轮廓紧密贴合。然而,在有衣服的区域,我们希望身体适合在衣服区域内。
我们使用 Graphonomy 将输入图像分割为服装区域,但我们如何将身体与服装联系起来?为此,我们再次利用 AGORA 数据集。
具体来说,我们计算 AGORA 中所有 3D 穿着身体的语义服装分割,并将其投影到地面实况 SMPL-X 身体的 3D 网格上。由此,我们学习了一个简单的每个顶点先验,它捕获每个顶点被每个服装标签标记的可能性。然后,我们定义新的损失,利用这一先验来确定穿衣和不穿衣服的区域。当使用服装信息进行训练时,生成的模型比基线更准确,我们发现它可以更好地将身体定位在衣服内。
论文: Monocular, One-Stage, Regression of Multiple 3D People
上述每一篇论文都解决了从 RGB 人体捕获中的一个重要问题,但每种方法都假设已从图像中检测到并裁剪了人物。然后将裁剪后的图像输入神经网络,神经网络对姿势和形状参数进行回归。
SPEC 朝着使用整个图像迈出了一步,因为它使用完整图像来估计相机参数,并利用这些参数来估计裁剪中人物的姿势。但是,我们认为完整图像中包含更多信息,并且这个两阶段过程(检测然后回归)缓慢且脆弱。当图像中存在明显的人与人遮挡时尤其如此。在这种情况下,紧密的边界框可能包含多个人,而没有足够的上下文来区分他们。
相反,在 ROMP 中,我们主张一种处理整个图像的单阶段方法,可以利用完整的图像上下文,并且在同时估计许多人时非常有效。
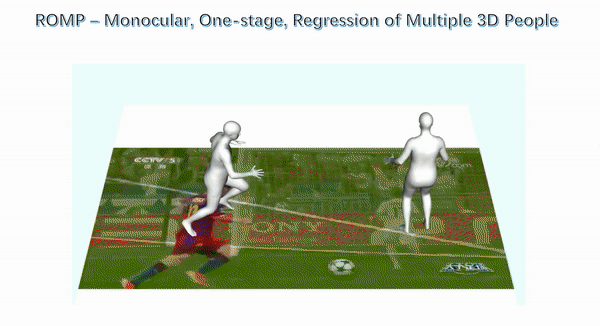
ROMP 不检测边界框,而是使用像素级表示并同时估计身体中心热图和网格参数图。身体中心热图捕获身体以特定像素为中心的可能性。我们采用一种新颖的排斥术语来处理高度重叠的物体。参数图也是一个像素级图,包括相机和 SMPL 模型参数。然后,我们从身体中心热图进行采样,并从参数图中的位置获取 3D 身体的参数。 ROMP 实时运行并同时估计多人的姿势和形状。我们认为这就是未来——为什么要关注剪短的人呢?我们希望估计场景中的每个人,并允许网络在此过程中利用所有图像线索。
2、建模
捕获数据只是构建虚拟人的第一步。建模(Modeling)采用我们捕获的数据并将其转换为可以控制、采样和动画的参数模型。
我们的建模工作重点是学习人体形状(以及它如何随姿势变化)和人体运动。从形状开始,我们观察到现有的 3D 人体模型(例如 SMPL)基于固定的 3D 网格拓扑。虽然这对于某些问题来说是理想的,但它缺乏表达复杂的衣服和头发的能力。现实的人类化身需要更丰富、更复杂的表现。扩展网格来做到这一点具有挑战性,因此我们一直在探索基于隐式曲面和点云的新方法。
论文: SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes
神经隐式表面方法使用神经网络以连续且与分辨率无关的方式表示 3D 形状。例如,该网络表示占用情况或到身体表面的有符号距离。给定 3D 空间中的任何点,函数(即网络)表示该点是在形状内部还是外部,或者返回到表面的有符号距离。然后,实际表面被隐式定义为函数场的零水平集。由于神经网络非常灵活,它们可以学习穿着衣服的人的复杂几何形状。这很棒,因为它为我们提供了一种从捕获的数据中学习穿着人员的形状模型的方法,而无需绑定到 SMPL 网格。
然而,将这一想法应用于人体等铰接结构并非易事。现有方法学习向后扭曲场,将变形(姿势)点映射到规范点。然而,这是有问题的,因为向后扭曲场依赖于姿态,因此需要大量数据来学习。为了解决这个问题,SNARF 通过在没有直接监督的情况下学习前向变形场,将多边形网格的线性混合蒙皮 (LBS) 的优点与神经隐式曲面的优点结合起来。该变形场是在规范的、与姿势无关的空间中定义的,从而能够泛化到看不见的姿势。仅从姿势网格学习变形场具有挑战性,因为变形点的对应关系是隐式定义的,并且在拓扑变化下可能不是唯一的。我们提出了一种前向蒙皮模型,该模型使用迭代根查找来查找任何变形点的所有规范对应关系。我们通过隐式微分导出分析梯度,从而能够通过骨骼变换从 3D 网格进行端到端训练。
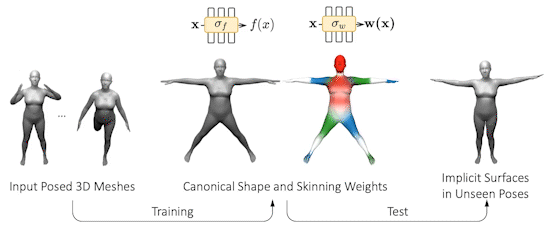
与最先进的神经隐式表示相比,SNARF 可以更好地泛化到未见过的姿势,同时保持准确性。我们在具有各种和看不见的姿势的(穿着衣服的)3D 人类的挑战性场景中展示了我们的方法。
论文: The Power of Points for Modeling Humans in Clothing
我们认为隐式表面令人兴奋,但目前它们有一些局限性。因为它们是新的,所以不能与任何现有的图形技术即插即用,而现有的图形技术在 3D 网格上投入了大量资金。例如,现在你无法在游戏引擎中使用隐式虚拟人类。要使用它们,您必须首先从隐式曲面中提取网格,例如使用行进立方体。我们认为 3D 身体的“最终”模型尚未被发现,因此我们通过探索替代方案来保持我们的选择余地。
例如,一种非常古老且简单的表示方式被证明特别强大——3D 点云。与隐式曲面一样,点云没有固定的拓扑,如果你愿意拥有大量点,则分辨率可以是任意的。此类模型非常轻量级且易于渲染,并且与现有工具更加兼容。但有一个问题:它们本质上是稀疏的,并且表面不明确。经过这些点的 3D 表面是隐式的。这实际上与隐式表面非常相似,可以使用神经网络来学习。

最近有很多关于使用点云来学习 3D 形状表示(例如 ShapeNet 中的表示)的工作。现在有许多深度学习方法可以使用点云学习 3D 形状,但使用它们来建模铰接式和非刚性物体的工作较少。为了解决这个问题,我们创建了一个新的基于点的人体模型,称为 PoP,用于“点的力量”。
PoP 是一种神经网络,采用新颖的局部服装几何特征进行训练,可以捕捉不同服装的形状。该网络根据多种类型服装、多种身体、多种姿势的 3D 点云进行训练,并学习对与姿势相关的服装变形进行建模。几何特征可以进行优化,以适应以前未见过的穿着衣服的人的扫描,使我们能够对一个人进行单次扫描并为其制作动画。这是创建可以插入元宇宙的虚拟人类的重要一步。
论文: Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
为了创造虚拟人类,我们需要将他们的动作建立在语言基础上。也就是说,我们需要将人们如何移动与他们移动的原因联系起来。驱动他们行为的目标是什么?先前关于人体运动合成的许多工作都集中在时间序列预测上。即,给定一系列人体运动,产生更多的运动。虽然很有趣,但这并不是我们需要的核心。我们需要给代理一个目标或一个行动,然后让他们执行此操作。这种表演的长度和表演方式应该是可变的。例如,如果我说“挥手再见”,化身可能会用右手或左手这样做。自然变化是现实主义的关键。
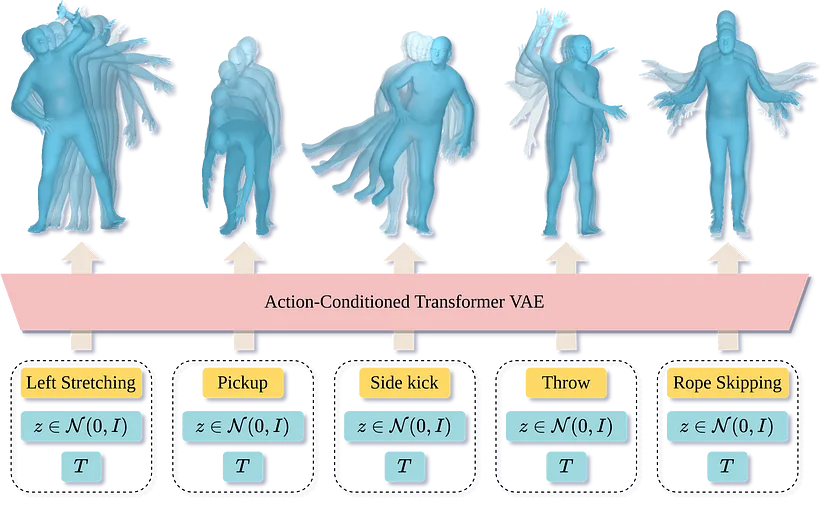
为了解决这个问题,我们训练了 ACTOR,它能够根据动作标签生成不同长度的真实且多样化的人体运动序列。与完成或扩展运动序列的方法相比,此任务不需要初始姿势或序列。 ACTOR 使用生成变分自动编码器 (VAE) 学习人类动作的动作感知潜在表示。通过从这个潜在空间中采样并通过一系列位置编码查询一定的持续时间,我们合成了以动作为条件的可变长度运动序列。
具体来说,我们设计了一个基于 Transformer 的架构,对从动作识别数据集估计的参数化 SMPL 人体模型序列进行编码和解码。我们在 NTU RGB+D、HumanAct12 和 UETC 数据集上评估了我们的方法,并在多样性和真实性方面展示了相对于现有技术的改进。
3、合成
我们如何知道我们是否捕获了正确的数据以及我们的模型是否“良好”?我们的假设是,如果我们能够产生现实的人类行为,那么我们就完成了我们的工作。
请注意,我们距离创造出像人一样行为的真正真实的虚拟人类还有很长的路要走。事实上,这是一个“AI complete”的问题,需要智能体具有“心理理论”。虽然完整的解决方案仍然是一个梦想,但我们可以取得短期内有用的具体进展。
论文: Stochastic Scene-Aware Motion Prediction
在与 Adobe 同事的精彩合作中,我们开始将所有内容整合到一个名为 SAMP 的系统中。 SAMP 使用我们所知道的一切来创建一个虚拟人,该虚拟人可以在新场景中计划其行动,并在场景中移动并与物体交互以实现目标,同时捕捉人类行为中存在的自然变化。 SAMP 建立在我们的动作捕捉工具、我们之前在捕捉人体场景交互 (PROX) 方面的工作以及最近将静态人体放入 3D 场景(PSI、PLACE 和 POSA)方面的工作之上。

SAMP 代表场景感知运动预测,是一种数据驱动的随机运动合成方法,可对目标对象执行给定动作的不同方式进行建模。 SAMP 泛化到不同几何形状的目标对象,同时使角色能够在杂乱的场景中导航。为了训练 SAMP,我们收集了涵盖各种坐姿、躺姿、行走和跑步风格的动作捕捉数据,并使用 MoSh++ 将 SMPL-X 身体拟合到其中。然后,我们通过改变对象的大小和形状来增强这些数据,然后使用逆运动学调整人体姿势以保持身体与对象的接触。
SAMP 包括 MotionNet、GoalNet 和 A* 路径规划算法。 GoalNet 经过训练可以理解对象的可供性。我们用有关人类如何与其交互的信息来标记训练数据;例如他们可以以不同的方式坐在或躺在沙发上。网络学习随机生成新对象的交互状态。 MotionNet 是一种自回归 VAE,它采用目标对象、先前的身体姿势和潜在代码并生成下一个身体姿势。 A* 算法规划从起始姿势到目标对象的路径并生成一系列路径点。然后,SAMP 在这些目标状态之间生成运动。
SAMP 产生看起来很自然的动作,并且角色可以避开障碍物。如果多次生成相同的动作,角色将表现出自然的可变性。虽然还有很多工作要做,但 SAMP 朝着将逼真的虚拟人类放入新颖的 3D 场景中并仅使用高级目标来指导它们迈出了一步。
论文; Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
随着我们改进身体形状和运动模型,我们将遇到现实主义的新障碍。使用现有的图形渲染方法创建逼真的虚拟人仍然具有挑战性,并且需要经验丰富的艺术家。以同样的方式,我们用 SOMA 等神经网络取代捕获,用 SNARF 或 PoP 等神经网络取代 3D 形状模型,我们可以用神经网络取代经典的图形渲染管道。 SPICE 朝这个方向迈出了一步,它获取一个人的单张图像,然后真实地重新放置或动画化它们。通过从图像开始然后改变它,我们保持了真实感。但是,即使我们生成像素,我们的 3D 身体模型也发挥着至关重要的作用。
从单个图像合成具有新颖姿势的人的图像是一项高度模糊的任务。大多数现有方法需要配对训练图像;即同一个人穿着相同衣服、摆出不同姿势的图像。然而,使用配对数据获得足够大的数据集具有挑战性且成本高昂。以前放弃配对监督的方法缺乏现实性。 SPICE(Self-supervised Person Image CrEation)是一种可以与监督方法竞争的自监督方法。

每个三元组由源图像(左)、目标姿态的参考图像(中)和目标姿态的生成图像(右)组成
实现自我监督的关键洞察是通过多种方式利用有关人体的 3D 信息。
首先,休息时3D身体形状必须保持不变。其次,以 3D 形式表示身体姿势可以推理自遮挡。第三,在休息之前和之后可见的 3D 身体部位应该具有相似的外观特征。
经过训练后,SPICE 会拍摄一个人的图像,并以新的目标姿势生成该人的新图像。
SPICE 在 DeepFashion 数据集上实现了最先进的性能,与之前的无监督方法相比,FID 分数从 29.9 提高到 7.8,并且性能与最先进的监督方法 (6.4) 相似。
尽管仅在静态图像上进行训练,但 SPICE 还可以在给定输入图像和一系列姿势的情况下生成时间连贯的视频。
4、结束语
下一步是什么?我们将在 ICCV 所做的基础上继续改进我们的捕获、建模和合成方法。贯穿我们所有工作的一个关键主题是
构建你需要的内容并使用你构建的内容。
用行业术语来说,我们“吃自己的狗粮”。你在这里看到的所有内容都建立在我们之前所做的事情的基础上,你可以期待未来的工作以我们的 ICCV 工作为基础。
尽管该领域取得了进展,但野外视频的捕获问题尚未得到解决。特别是,我们专注于提取具有面部和手部表现力的身体(参见 SIGGRAPH 2021 上的 DECA 和 3DV 2021 上的 PIXIE)。我们还正在使用 BABEL 数据集来生成基于动作标签的更复杂的人体动作。我们正在开发新的隐式形状表示,它们更丰富、更真实、更容易学习。事实上,我们的“捕获-模型-合成”方法是一个良性循环,其中合成的人类可以用来训练更好的捕获方法(参见 AGORA)。
原文链接:数字人捕捉、建模与合成 - BimAnt