第五章 深度学习
九、图像分割
1. 基本介绍
1.1 什么是图像分割
图像分割(Segmentation)是图像处理和机器视觉一个重要分支,其目标是精确理解图像场景与内容。图像分割是在像素级别上的分类,属于同一类的像素都要被归为一类,因此图像分割是从像素级别来理解图像的。如下图所示的照片,属于人的像素部分划分成一类,属于摩托车的像素划分成一类,背景像素划分为一类。

图像分割级别可以分为语义级分割、实例级分割和全景分割。
- 语义分割(Semantic Segmentation):对图像中的每个像素划分到不同的类别;
- 实例分割(Instance Segmentation):对图像中每个像素划分到不同的个体(可以理解为目标检测和语义分割的结合);
- 全景分割(Panoptic Segmentation):语义分割和实例分割的结合,即要对所有目标都检测出来,又要区分出同个类别中的不同实例。

1.2 应用
1)无人驾驶

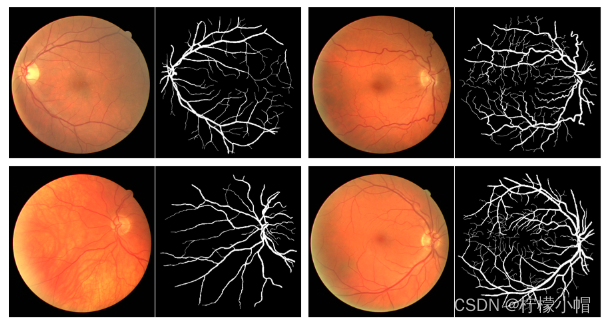
2)医学、生物图像分割(如病灶识别)
3)无人机着陆点判断
4)自动抠图

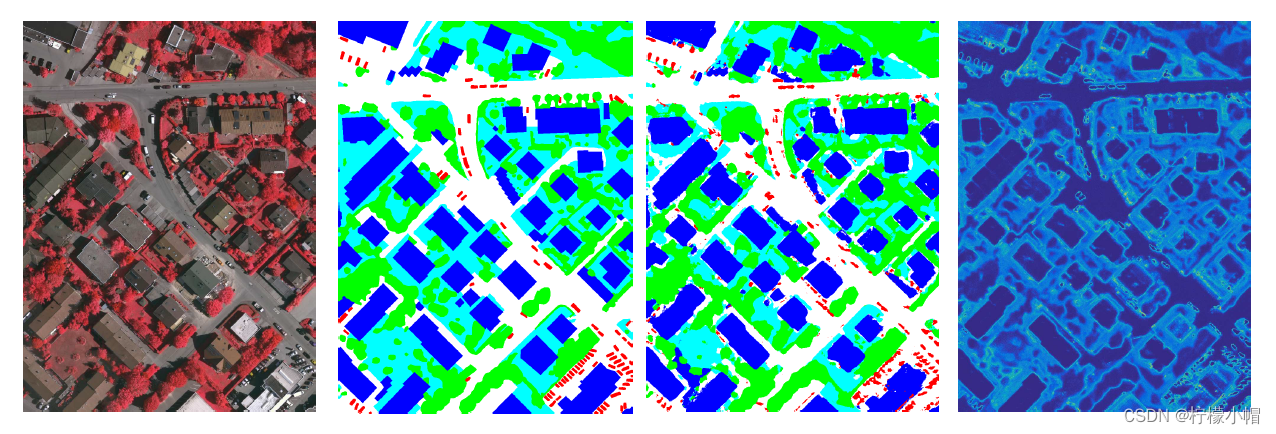
5)遥感图像分割
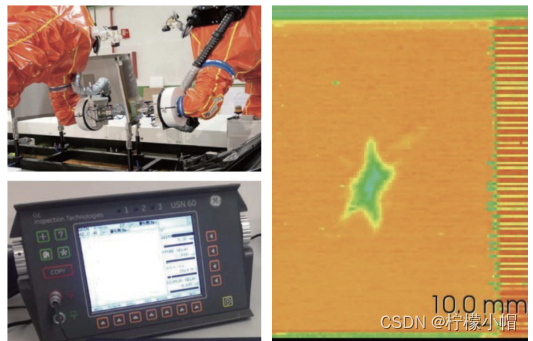
6)工业质检
1.3 图像分割的难点
1)数据问题:分割不像检测等任务,只需要标注边框就可以使用,分割需要精确到像素级标注,包括每一个目标的轮廓等信息;
2)计算资源问题:要想得到较高的精度就需要使用更深的网络、进行更精确的计算,对计算资源要求较高。目前业界有一些轻量级网络,但总体精度较低;
3)精细分割:目前很多算法对于道路、建筑物等类别分割精度很高,能达到98%,而对于细小的类别,由于其轮廓太小,而无法精确的定位轮廓;
4)上下文信息:分割中上下文信息很重要,否则会造成一个目标被分成多个部分,或者不同类别目标分类成相同类别;
2. 图像分割基本原理
2.1 整体实现思路
图像分割一般思路如下:
1)输入图像,利用深度卷积神经网络提取特征
2)对特征图进行上采样,输出每个像素的类别
3)利用损失函数,对模型进行优化,将每个像素的分类结果优化到最接近真实值
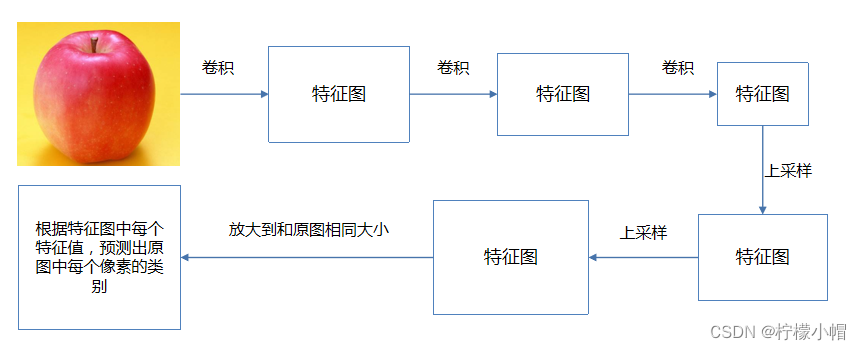
2.2 评价指标
1)像素精度(pixel accuracy ):每一类像素正确分类的个数/ 每一类像素的实际个数;
2)平均像素精度(mean pixel accuracy ):每一类像素的精度的平均值;
3)平均交并比(Mean Intersection over Union):求出每一类的IOU取平均值。
3. 常用模型
3.1 FCN(2014)
FCN(全称Fully Convolutional Networks)是图像分割的开山之作,2014年由加州大学伯克利分校Jonathan Long等人提出(论文名称《Fully Convolutional Networks for Semantic Segmentation》,该论文存在多个版本)。在该网络模型中,使用卷积层代替普通CNN中的全连接层,使用不同尺度信息融合,可以生成任意大小的图像分割图,从而实现对图像进行像素级的分类。
3.1.1 什么是FCN
一个典型的卷积神经网络在处理图像分类问题时,通常会使用若干个卷积层,之后接若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量,由输出层在softmax激活函数的作用下,产生N个分类概率,取其中概率最大的类别作为分类结果。如下图所示:
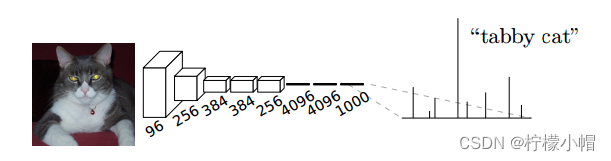
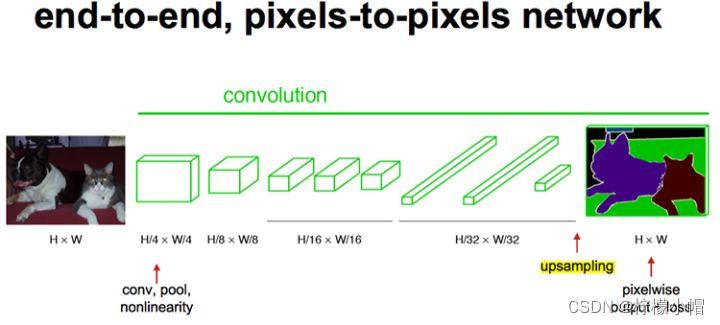
图像分割需要对图像进行像素级分类,所以在输出层使用全连接模型并不合适。FCN与CNN的区别在把于CNN最后的全连接层换成卷积层(所以称为“全卷积网络”)。该网络可以分为两部分,第一部分,通过卷积运算提取图像中的特征,形成特征图;第二部分,对特征图进行上采样,将特征图数据恢复为原来的大小,并对每个像素产生一个分类标签,完成像素级分类。结构如下图所示:
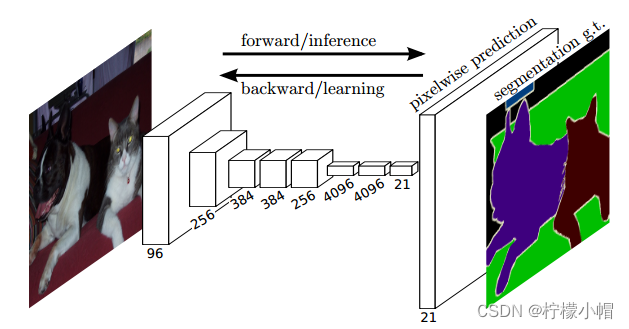
上采样示意图:
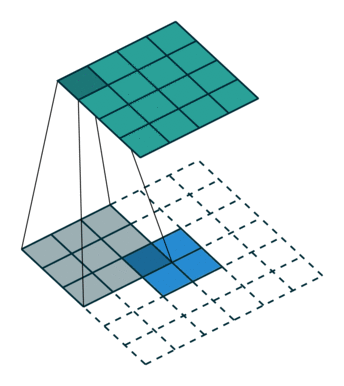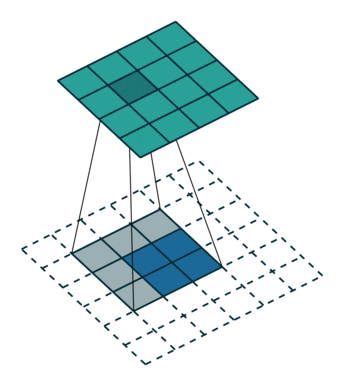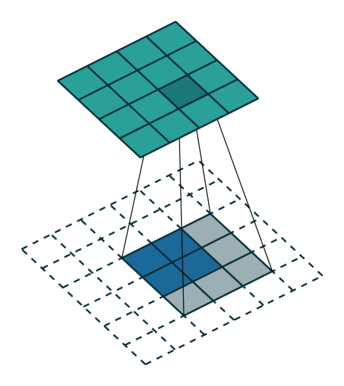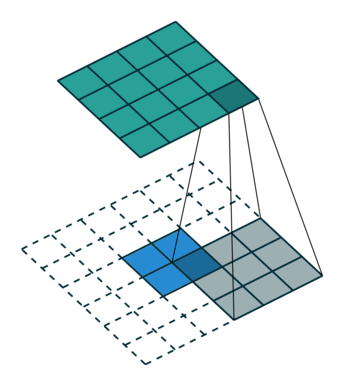
3.1.2 网络结构
下图是一个FCN的结构。
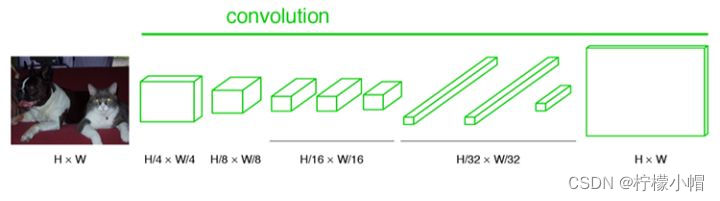
-
输入:H*W的图像。由于没有全连接层,网络可以接收任意维度的输入(而不是固定大小图像);
-
第1~5卷积层:执行卷积、池化操作。第一层pooling后变为原图大小的1/4,第二层变为原图大小的1/8,第五层变为原图大小的1/16,第八层变为原图大小的1/32(勘误:其实真正代码当中第一层是1/2,以此类推)。经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H 32 ∗ W 32 \frac{H}{32} * \frac{W}{32} 32H∗32W 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特征图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小;
-
输出:由于将全连接模型换成了卷积层,原本CNN中输出的1000*1*1维的特征变成了1000*W*H维,1000张热点图(heatmap)。在上述结构的基础上,将1000维变成21维(20种PASCAL类别+背景),再接一个反卷积层,以双线性上采样粗输出到像素密集输出,得到21张大小和原图一致的Mask,然后和真实标签逐像素比较分类结果,进行梯度下降优化。如下图右侧有狗狗和猫猫的图:
3.1.3 特征融合
FCN采用了特征融合,将粗的、高层信息与精细的、低层信息融合用来提高预测精度。融合实现方式是,对特征图进行上采样,然后将特征图对应元素相加。经过多次卷积、池化后,特征图越来越小,分辨率越来越低,为了得到和原图大小的特征图,所以需要进行上采样。作者不仅对pool5之后的特征图进行了上采样还原,也对pool4和pool3之后的特征图进行了还原,结果表明,从这些特征图能很好的获得关于图片的语义信息,而且随着特征图越来越大,效果越来越好。
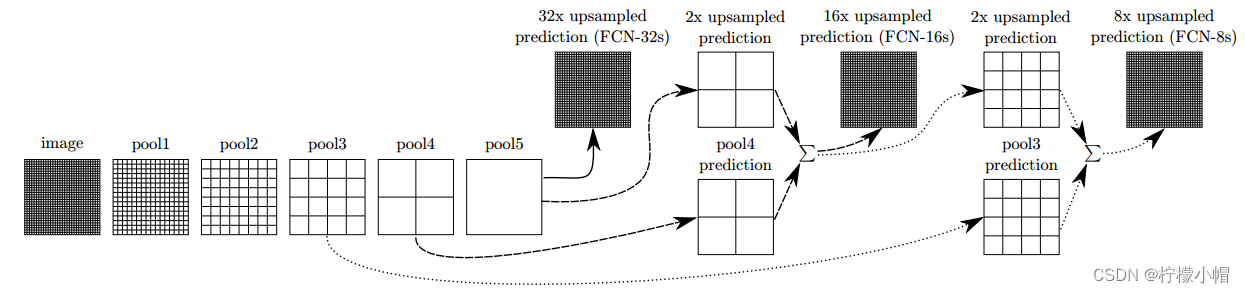
以下是不同大小特征图进行上采样,预测结果对比:

3.1.4 评价指标
作者在论文中提出了4种评价指标,即像素准确度、平均准确率、平均交并比、频率加权交并比。设 n i j n_{ij} nij为类别i预测为类别j的像素数量,有 n c l n_{cl} ncl个不同的类别,类别i总共有 t i = Σ j n i j t_i = \Sigma_j n_{ij} ti=Σjnij个像素,各指标具体表述如下:
- 像素准确率(Pixel Accuracy)
P A = Σ i n i i Σ i t i PA = \frac{\Sigma_i n_{ii}}{\Sigma_i t_i} PA=ΣitiΣinii
- 平均准确率(Mean Pixel Accuracy)
M P A = 1 n c l Σ i n i i t i MPA = \frac{1}{n_{cl}} \Sigma_i \frac{ n_{ii}}{t_i} MPA=ncl1Σitinii
- 平均交并比(Mean Intersection over Union)
M I U = 1 n c l Σ i n i i t i + Σ j n j i − n i i MIU = \frac{1}{n_{cl}} \Sigma_i \frac{n_{ii}}{t_i + \Sigma_j n_{ji} - n_{ii}} MIU=ncl1Σiti+Σjnji−niinii
- 频率加权交并比(Frequency Weighted IU )
F W I U = 1 Σ k t k Σ i t i n i i t i + Σ j n j i − n i i FWIU = \frac{1}{\Sigma_k t_k} \Sigma_i \frac{t_i n_{ii}}{t_i + \Sigma_j n_{ji} - n_{ii}} FWIU=Σktk1Σiti+Σjnji−niitinii
3.1.5 结论
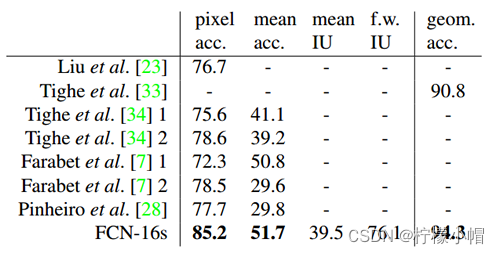
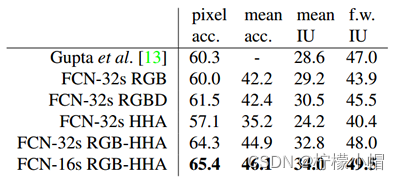
- NYUDv2数据集。该数据集包含1449个RGB-D图像。论文给出的实验结果如下(其中,FCN-32s表示未修改的粗糙模型,FCN-16s为16 stride的模型,RGB-HHA是采用了RGB和HHA融合的模型):
- SIFT Flow。该数据集包含2688幅图像,包含“桥”、“山”、“太阳”等33个语义类别以及“水平”、“垂直”和“天空”三个几何类别。论文给出的实验结果如下: