前言
我们的目标是基于Jaeger来实现分布式链路追踪的Java客户端工具包,实际就是一个Springboot的Starter,在1. 看完这篇文章我奶奶都懂Opentracing了一文中我们详细的学习了一下Opentracing的相关概念以及阅读了相关的源码,同时特别重要的是我们还知道了Opentracing为我们造了很多轮子,这些轮子大部分时候都是可以直接用的,我们只需要指定具体的实现框架例如Jaeger和提供相应的扩展点例如Span装饰器,我们就能够造出来我们自己的轮子。
那么毫无疑问的,我们的分布式链路追踪的Java客户端工具包,会按照Opentracing规范并使用Jaeger作为具体实现来进行开发,但是这里存在一个问题,就是Jaeger中的Span模型,和我们直观的觉得一个服务就是一个Span的想法是不太一样的,具体怎么不一样,如何调整,且听下文详述。
Opentracing和jaeger相关版本依赖如下。
opentracing-api版本:0.33.0
opentracing-spring-web版本:4.1.0
jaeger-client版本:1.8.1
正文
在1. 看完这篇文章我奶奶都懂Opentracing了一文中我们搭建了一个示例demo,这个示例大概表示了如下的一个请求路径。
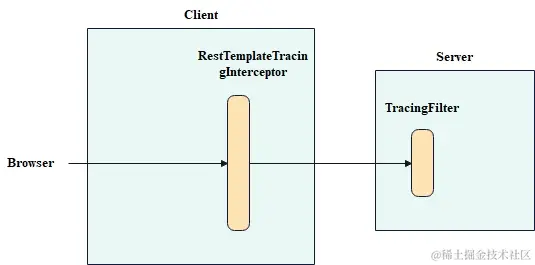
大致就是从浏览器发起请求,请求先到client,然后经过RestTemplateTracingInterceptor拦截后,由RestTemplate发送到server,进server前,先通过了TracingFilter,最终才来到server的Controller。上述这个demo不太好演示本文的Span模型,我们做一下修改,修改后的请求路径如下。

结合上面的请求路径,再结合示例demo中RestTemplateTracingInterceptor和TracingFilter的实现,上图可以进一步做如下的Span模型抽象。

我们知道一个Span通常包含traceId,spanId和parentSpanId,所以我们按照示例demo中RestTemplateTracingInterceptor和TracingFilter的实现的规则,再把这些信息添加上,此时Span模型抽象如下。

到这里可以发现,上述每个Span的id是不一样的,即在接收到请求以及发起请求时均会生成一个新的Span,那么这里就存在一个情况,即Span代表的是一次请求接收或请求发起,这无疑是符合Opentracing对Span的定义的,但是这样其实是不太好理解的,可如果说一个Span就代表一次请求经过的某一个服务实例,那么是不是一下子就好理解了,就像下面这样。

这样的Span才是符合我们直观的认知的,同时Span记录的时间范围,就可以表示从这个实例接收请求到这个实例响应所花的时间,那么一次请求慢在哪个实例,通过看Span的时间就清楚了,所以我们需要对之前Jaeger的Span模型做一下小小的改造,下面给出改造后的Span模型示意图。

上述模型,在每次作为客户端发起请求前,还是会创建一个新的Span,但是在作为服务端接收请求时,如果客户端跨进程传递了Span,则使用客户端传递过来的Span作为当前的Span,而不再新创建Span,这样一个过程,就好比是客户端(上游)替服务端(下游)创建好了Span然后给到了服务端(下游)一样。按照这样子改造,一个Span就可以表示一次请求经过的链路中的一个服务实例,而这,也正是契合Zipkin的Span模型。
现在既然已经明确了Span模型如何改造,那么具体到代码中,要怎么改造呢,Jaeger其实给我们留了口子,下面一起来看一下。
首先我们知道,无论是在服务端接收请求时创建Span还是在客户端发起请求时创建Span,均是通过JaegerTracer.SpanBuilder的start() 方法,简化版源码如下所示。
@Override
public JaegerSpan start() {JaegerSpanContext context;......if (references.isEmpty() || !references.get(0).getSpanContext().hasTrace()) {context = createNewContext();} else {context = createChildContext();}......JaegerSpan jaegerSpan = getObjectFactory().createSpan(JaegerTracer.this,operationName,context,startTimeMicroseconds,startTimeNanoTicks,computeDurationViaNanoTicks,tags,references);......return jaegerSpan;
}上述关键点在于会在JaegerTracer.SpanBuilder的createChildContext() 方法中创建父Span的子Span,这里的父Span有两种情况。
- 客户端跨进程传递过来的Span;
- 当前线程中已经激活的Span。
现在继续跟进JaegerTracer.SpanBuilder的createChildContext() 方法,如下所示。
private JaegerSpanContext createChildContext() {JaegerSpanContext preferredReference = preferredReference();if (isRpcServer()) {if (isSampled()) {metrics.tracesJoinedSampled.inc(1);} else {metrics.tracesJoinedNotSampled.inc(1);}if (zipkinSharedRpcSpan) {return preferredReference;}}return getObjectFactory().createSpanContext(preferredReference.getTraceIdHigh(),preferredReference.getTraceIdLow(),Utils.uniqueId(),preferredReference.getSpanId(),preferredReference.getFlags(),getBaggage(),null);
}看到这里,就应该明白Jaeger给留的口子是什么了,即如果当前是作为服务端接收到请求要创建Span时,如果zipkinSharedRpcSpan配置为true,则不创建新的Span,而是直接使用客户端跨进程传递过来的Span,这完全就符合了我们上面的Span模型的改造思路。
那么最后一个问题,zipkinSharedRpcSpan怎么配置为true,其实就是在创建JaegerTracer时,调用一下JaegerTracer.Builder的withZipkinSharedRpcSpan() 方法即可。
总结
在Jaeger的默认实现逻辑中,一个Span通常代表一次请求接收或请求发起,如果我们想要让一个Span代表一次请求经过的链路中的某一个服务实例,则需要显式的指定Jaeger的Span模型为Zipkin的Span模型,即在创建JaegerTracer时调用一下JaegerTracer.Builder的withZipkinSharedRpcSpan() 方法即可。
原文:https://juejin.cn/post/7330331064370774054