一、目录
1 定义
2. DP、DPP的区别
3 实现
4. 测试比较
二、实现
- 定义
accelerator 是由大名鼎鼎的huggingface发布的,专门适用于Pytorch的分布式训练框架,是torchrun 的封装。
GitHub: https://github.com/huggingface/accelerate
官网教程:https://huggingface.co/docs/accelerate/ - DP、DPP的区别
DataParallel:数据并行。
DistributedDataParallel:Distributed-data-parallel(简称DDP)顾名思义,分布式数据并行,是torch官方推荐的方式,相比于DP是单进程多线程模型,DDP使用了多进程的方式进行训练,能实现单机多卡、多机多卡训练。
注意的是,即使是单机多卡,DDP也比DP快很多,因为DDP从设计逻辑上杜绝了很多DP低效的缺点。在DDP中,再没有master GPU,每个GPU都在独立的进程中完成自身的任务。
3. 案例
- demo:https://zhuanlan.zhihu.com/p/544273093
import torchimport torch.nn.functional as Ffrom datasets import load_dataset
+ from accelerate import Accelerator+ accelerator = Accelerator()
- device = 'cpu'
+ device = accelerator.devicemodel = torch.nn.Transformer().to(device)optimizer = torch.optim.Adam(model.parameters())dataset = load_dataset('my_dataset')data = torch.utils.data.DataLoader(dataset, shuffle=True)+ model, optimizer, data = accelerator.prepare(model, optimizer, data)model.train()for epoch in range(10):for source, targets in data:#source = source.to(device)#targets = targets.to(device)optimizer.zero_grad()output = model(source)loss = F.cross_entropy(output, targets)- loss.backward()
+ accelerator.backward(loss)optimizer.step()
#运行: https://github.com/huggingface/accelerate/tree/main/examples 参考nlp_example.py
方式一:
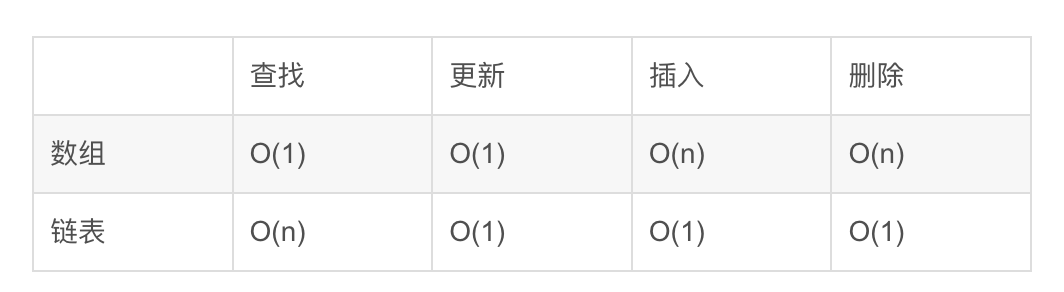
通过accelerate config 设置gpu 多卡方法
>>accelerate config
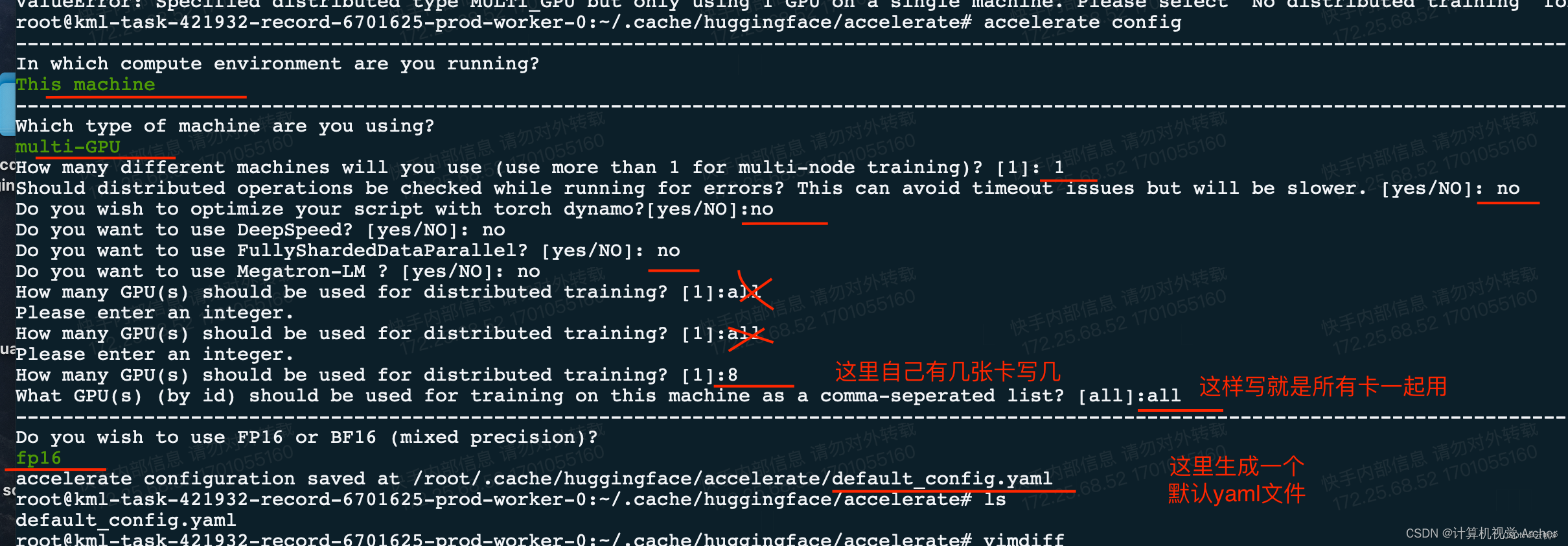 查看配置:
查看配置:
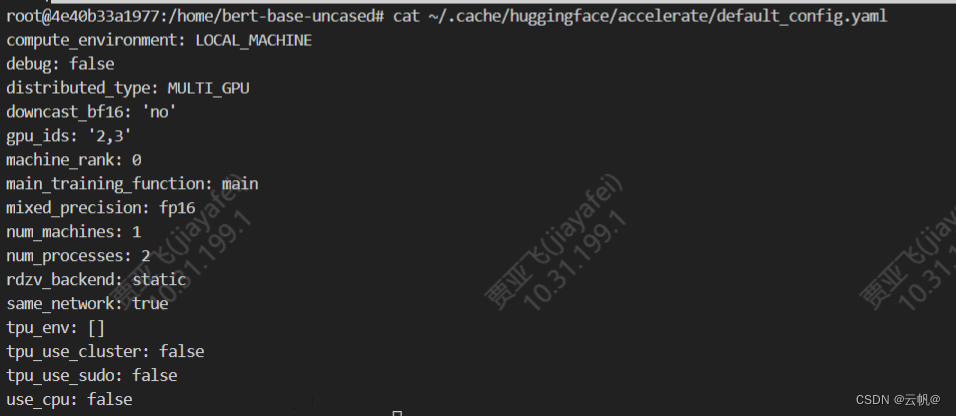
vim ~/.cache/huggingface/accelerate/default_config.yaml (后面配置时可以直接修改该文件)
>>accelerate config
>>accelerate launch xxxx.py
方式二:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 xxx.py
- 实例:
import timeimport torch
from accelerate import Accelerator
from datasets import load_dataset
from datasets import load_metric
from torch.optim import AdamW
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from transformers import AutoModelForTokenClassification
from transformers import AutoTokenizer
from transformers import DataCollatorForTokenClassification
from transformers import get_scheduler
accelerator = Accelerator()
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"
import datasets
#raw_datasets = load_dataset("conll2003")
#raw_datasets.save_to_disk("conll2003")
raw_datasets=datasets.load_from_disk("conll2003")print(raw_datasets)
device = "cuda:0" if torch.cuda.is_available() else "cpu"ner_feature = raw_datasets["train"].features["ner_tags"]
label_names = ner_feature.feature.names
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}def align_labels_with_tokens(labels, word_ids):new_labels = []current_word = Nonefor word_id in word_ids:if word_id != current_word:# Start of a new word!current_word = word_idlabel = -100 if word_id is None else labels[word_id]new_labels.append(label)elif word_id is None:# Special tokennew_labels.append(-100)else:# Same word as previous tokenlabel = labels[word_id]# If the label is B-XXX we change it to I-XXXif label % 2 == 1:label += 1new_labels.append(label)return new_labelsdef tokenize_and_align_labels(examples):tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)all_labels = examples["ner_tags"]new_labels = []for i, labels in enumerate(all_labels):word_ids = tokenized_inputs.word_ids(i)new_labels.append(align_labels_with_tokens(labels, word_ids))tokenized_inputs["labels"] = new_labelsreturn tokenized_inputsdef postprocess(predictions, labels):predictions = predictions.detach().cpu().clone().numpy()labels = labels.detach().cpu().clone().numpy()# Remove ignored index (special tokens) and convert to labelstrue_labels = [[label_names[l] for l in label if l != -100] for label in labels]true_predictions = [[label_names[p] for (p, l) in zip(prediction, label) if l != -100]for prediction, label in zip(predictions, labels)]return true_labels, true_predictions# tokenize
model_checkpoint = "/home/bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
tokenized_datasets = raw_datasets.map(tokenize_and_align_labels,batched=True,remove_columns=raw_datasets["train"].column_names,
)# model
model_checkpoint = "/home/bert-base-uncased"
model = AutoModelForTokenClassification.from_pretrained(model_checkpoint,id2label=id2label,label2id=label2id,
)
# model.to(device)# dataloader
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
train_dataloader = DataLoader(tokenized_datasets["train"],shuffle=True,collate_fn=data_collator,batch_size=32,num_workers=8
)
eval_dataloader = DataLoader(tokenized_datasets["validation"], collate_fn=data_collator, batch_size=128
)# metric
metric = load_metric("seqeval")# optimizer
optimizer = AdamW(model.parameters(), lr=2e-5)model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader,eval_dataloader)# lr_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,
)t1 = time.time()progress_bar = tqdm(range(num_training_steps))
print("Begin training")
for epoch in range(num_train_epochs):# Trainingmodel.train()for batch in train_dataloader:# batch = {key: batch[key].to(device) for key in batch}outputs = model(**batch)loss = outputs.loss# loss.backward()accelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)# Evaluationmodel.eval()for batch in eval_dataloader:# batch = {key: batch[key].to(device) for key in batch}with torch.no_grad():outputs = model(**batch)predictions = outputs.logits.argmax(dim=-1)labels = batch["labels"]# Necessary to pad predictions and labels for being gatheredpredictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)predictions_gathered = accelerator.gather(predictions)labels_gathered = accelerator.gather(labels)true_predictions, true_labels = postprocess(predictions, labels)metric.add_batch(predictions=true_predictions, references=true_labels)results = metric.compute()print(f"epoch {epoch}:",{key: results[f"overall_{key}"]for key in ["precision", "recall", "f1", "accuracy"]},)# Save and uploadaccelerator.wait_for_everyone()unwrapped_model = accelerator.unwrap_model(model)if accelerator.is_main_process:torch.save(unwrapped_model.state_dict, "./output/accelerate.pt")t2 = time.time()
print(f"训练时间为{t2 - t1}秒")
运行:CUDA_VISIBLE_DEVICES=0 torchrun --nproc_per_node=1 test.py用时:1hCUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node=2 test.py 用时:4h 为什么变慢了?原因:UserWarning: Can't initialize NVML warnings.warn("Can't initialize NVML")解决: nvidia-smi 报错, 重启docker ,保证nvidia-smi 可以用。
- 测试比较
原生单gpu 训练,训练集500条, 用时20s
accelorator 训练, 单gpu, 训练集500条, 用时17s
accelorator 训练 2个gpu 训练集500条, 用时11s