LAS 及其压缩版本 LAZ 是用于存储点云信息的流行文件格式,通常由 LiDAR 技术生成。 LiDAR(即光探测和测距)是一种遥感技术,用于测量距离并创建物体和景观的高精度 3D 地图。存储的点云信息主要包括X、Y、Z坐标、强度、颜色、特征分类、GPS时间以及扫描仪提供的其他自定义字段。 LAS 文件包含数百万个点,可以准确描述感知的环境或物体,这使得其分析成为一项具有挑战性的任务。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
处理和分析 3D 数据的基本步骤之一是计算法线。点云中的法线提供有关点云中每个点处的表面方向和方向的信息。这些信息对于可视化、对象识别和形状分析至关重要。
我们不会深入研究如何计算这些法线或使用哪个包的细节。相反,本文的重点是演示如何在对 LAS/LAZ 文件进行分块读取和分块写入时执行并行计算,以及 Python 如何应对并发和并行性的挑战。
要继续学习,你应该对 Python 有一定的了解,并熟悉 numpy 和 laspy。本文对 Python 中的并行性进行了高级概述。
[packages]
numpy = "==1.26.0"
laspy = {extras = ["lazrs"], version = "==2.5.1"}[requires]
python_version = "3.10"laspy 和 numpy 都是直接与 Python C_API 交互的包,使得它们速度极快。如果不采用直接 C 编程,速度方面没有太大的改进空间。因此,我们需要探索使用代码的新方法,以实现并行性或增强处理管道,以充分利用机器的潜力。
你可能知道也可能不知道,Python 的执行受到全局解释器锁 (GIL) 的限制。 GIL 是 CPython 解释器使用的一种机制,用于确保一次只有一个线程执行 Python 字节码。这简化了实现并使 CPython 的对象模型能够安全地防止并发访问。
虽然 GIL 为多线程程序和单核、单进程性能提供了简单性和优势,但它提出了一些问题:如果多个线程不能同时执行,为什么要使用多线程?是否可以与Python并行执行代码?
多线程是一种使 Python 非阻塞的方法,允许我们创建同时启动多个任务的代码,即使在任何给定时刻只能执行一个任务。当调用外部 API 或数据库(您大部分时间都在等待)时,这种类型的并发非常有用。然而,对于 CPU 密集型任务,这种方法有局限性。
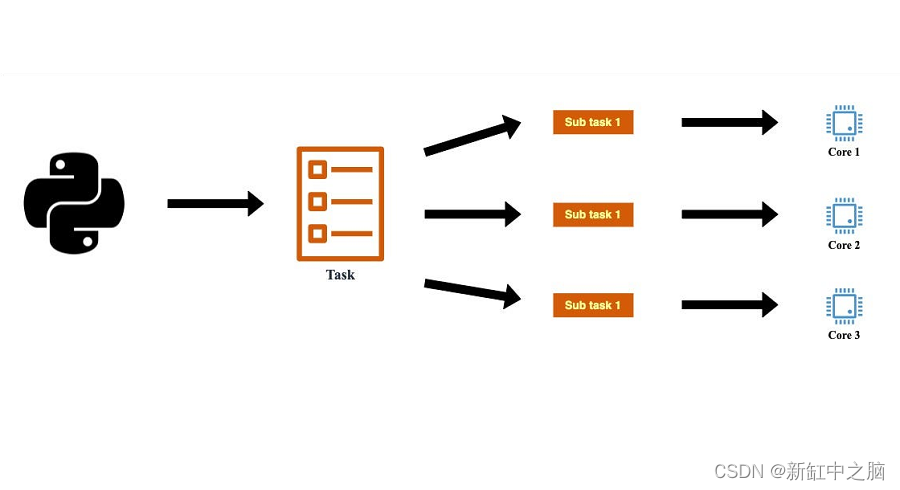
为了并行运行 Python 代码,多处理库使用操作系统 API 调用在不同内核上生成单独的进程。
spawn 是 MacOS 和 Windows 中的默认方法。它创建子进程,继承运行对象的 run() 方法所需的资源。尽管比其他方法(如 fork)慢,但它提供了一致的执行。
fork 是除 MacOS 之外的所有 POSIX 系统中的默认方法。它使用父进程的所有上下文和资源创建子进程。它比 spawn更快,但在多进程和多线程环境中可能会遇到问题。
这种方法允许我们为每个处理器提供一个新的 Python 解释器,从而消除了多个线程争夺解释器可用性的问题。
鉴于点云处理严重依赖 CPU 性能,我们采用多处理来并行执行正在读取的点云的每个块的进程。
为了读取大型 LAS/LAZ 文件, laspy 提供了 chunk_iterator,用于读取数据块中的点云,这些数据块可以发送到不同的进程进行处理。随后,处理后的数据被组装并按块写回到另一个文件中。为了实现这一目标,我们需要两个上下文管理器:一个用于读取输入文件,另一个用于写入输出文件。
你通常会这样做:
import laspy
import numpy as np# reading the file
with laspy.open(input_file_name, mode="r") as f:# creating a filewith laspy.open(output_file_name, mode="w", header=header) as o_f:# iteration over the chunk iteratorfor chunk in f.chunk_iterator(chunk_size):# Normals calculation over each chunkpoint_record = calculate_normals(chunk)# writting or appending the data into the point cloudo_f.append_points(point_record)为了并行化这个过程,我们创建了一个 ProcessPoolExecutor,它允许我们将函数的每次执行(计算法线的地方)发送到一个单独的进程。过程完成后,我们收集结果并将其写入新的 LAS/LAZ 文件。
由于我们在主进程中收集 future 的结果,然后将它们写入文件,因此我们避免了多个进程同时访问同一文件的问题。如果你的实现不允许这种方法,可能需要使用锁来确保数据完整性。
import laspy
import numpy as np
import concurrent.futures# reading the file
with laspy.open(input_file_name, mode="r") as f:# creating an output filewith laspy.open(output_file_name, mode="w", header=f.header) as o_f:# this is where we are going to collect our future objectsfutures = []with concurrent.futures.ProcessPoolExecutor() as executor:# iteration over the chunk iteratorfor chunk in f.chunk_iterator(chunk_size):# disecting the chunk into the points that conform itpoints: np.ndarray = np.array(((chunk.x + f.header.offsets[0])/f.header.scales[0],(chunk.y + f.header.offsets[1])/f.header.scales[1],(chunk.z + f.header.offsets[2])/f.header.scales[2],)).T# calculate the normals in a multi processing poolfuture = executor.submit(process_points, # function where we calculate the normalspoints=points,)futures.append(future)# awaiting all the future to complete in case we neededfor future in concurrent.futures.as_completed(futures):# unpacking the result from the futureresult = future.result()# creating a point record to store the resultspoint_record = laspy.PackedPointRecord.empty(point_format=f.header.point_format)# appending information to that point recordpoint_record.array = np.append(point_record.array,result)# appending the point record into the point cloudo_f.append_points(point_record)这段代码中有很多东西需要展开解释,比如为什么我们不使用块对象本身?为什么我们要创建一个空的 PackedPointRecord?
我们将从块对象开始。如果不触及原因,对象本身就无法发送到进程池中进行处理。因此,我们必须从中提取我们认为重要的信息。因为我们正在计算法线,所以我们需要的是块的 X、Y 和 Z 坐标,同时考虑到 LAS/LAZ 文件头中指定的偏移和比例。
鉴于计算返回一个值数组,该数组将表示 X、Y 和 Z 坐标、RGB 值、强度和分类,我们不能将其直接写入 LAS/LAZ 文件,我们需要创建一个 PackedPointRecord使用标头中指定的格式,我们将在其中存储返回的数组,然后将它们附加到 LAS/LAZ 文件中。
LAS/LAZ 文件有一个标头对象,我们在其中存储点云的比例、偏移和格式。这很重要,因为为了我们能够将信息发送到该文件,我们的值的格式必须与标头中指定的格式匹配。在我们的例子中,两个文件具有相同的标头格式。但是,如果你需要写入不同版本的文件,则数组格式必须与你要写入的版本匹配。
要确定能够将结果附加到 PackedPointRecord 中所需的格式,你可以运行以下命令:
>>> f.header.point_format.dtype()在此示例中,我们使用 Point Format版本 3,其结构如下:
np.dtype([('X', np.int32),('Y', np.int32),('Z', np.int32),('intensity', np.int16),('bit_fields', np.uint8),('raw_classification', np.uint8),('scan_angle_rank', np.uint8),('user_data', np.uint8),('point_source_id', np.int16),('gps_time', np.float64),('red', np.int16),('green', np.int16),('blue', np.int16),
])因为我们无法使用此命令来将解压后的 future 的 dtype 与 header 的 dtype 进行匹配。
>>> result = result.astype(header.point_format.dtype())我们必须按以下方式进行转换:
def process_points(points: np.ndarray,
) -> np.ndarray:# normals calculationnormals, curvature, density = calculate_normals(points=points)# RGBred, green, blue = 255 * (np.abs(normals)).Tdtype = np.dtype([('X', np.int32),('Y', np.int32),('Z', np.int32),('intensity', np.int16),('bit_fields', np.uint8),('raw_classification', np.uint8),('scan_angle_rank', np.uint8),('user_data', np.uint8),('point_source_id', np.int16),('gps_time', np.float64),('red', np.int16),('green', np.int16),('blue', np.int16),])array = np.zeros(len(points), dtype=dtype)array['X'] = points[:, 0]array['Y'] = points[:, 1]array['Z'] = points[:, 2]array['intensity'] = densityarray['bit_fields'] = np.zeros(len(points), dtype=np.uint8)array['raw_classification'] = curvaturearray['scan_angle_rank'] = np.zeros(len(points), dtype=np.uint8)array['user_data'] = np.zeros(len(points), dtype=np.uint8)array['point_source_id'] = np.zeros(len(points), dtype=np.int16)array['gps_time'] = np.zeros(len(points), dtype=np.float64)array['red'] = redarray['green'] = greenarray['blue'] = bluereturn np.ascontiguousarray(array)将所有这些放在一起,我们就能够使用计算机的所有资源并行处理大型点云。
尽管需要非常熟悉上述软件包才能理解和应用上面的代码,但我们的想法是解决我们在处理点云时遇到的常见问题之一,并分享我们找到的解决方案对于我们的问题。
原文链接:用Python并行化处理点云 - BimAnt