Acme学习笔记(一)
- Chapter 2 RL
- Online Reinforcement Learning
- Offline Reinforcement Learning
- Imitation Learning
- Learning from Demonstrations
- Chapter 3 Acme
- 3.1 Environments and environment loops
- 3.2 Actors
- 3.3 Experience replay and data storage
- 3.4 Learners
- 3.5 Defining agents using Builders
- 3.6 Running an agent
- 3.7 Distributed agents
- 3.8 Modifications for offline agents
- Chapter 4 Agent Algorithms
- 4.2 Online RL
Chapter 2 RL
强化学习的设置可以看作是一个智能体基于环境观察值生成动作、环境根据动作产生奖励和下一时刻观测值的迭代循环。从数学的角度而言,这样的迭代交互可以视为马尔可夫过程或者部分可观测马尔可夫过程。智能体通过策略与环境产生交互,在深度强化学习中,通常用一个深度神经网络来表示它,为了表征更加普遍的setting,智能体使用循环网络作为策略。
Online Reinforcement Learning
在线强化学习的setting常常与给定的环境描述有关,被视为”标准“的强化学习设置。在线强化学习算法分为on-policy和off-policy两种。其中off-policy算法采用experience replay充分利用数据进行策略的更新。
Offline Reinforcement Learning
离线强化学习也被称为batch-RL,agent无法与环境进行交互,只能从给定的数据集中学习策略。在setting下学习策略无法从环境中得到反馈,那么算法就可能出现选择了数据集中没有的actions导致高回报的错误。因此,离线setting中的方法经常包含正则化,以激励学习的策略避免未知或不确定的状态-动作区域。
Imitation Learning
对于一些任务,无法定义reward,使用模仿学习能够很好解决问题。在模仿学习的setting中,环境没有定义reward,而是使用一些demonstrations,目标是学习一个与所提供的demonstrations相匹配的策略或者推断这些demonstrations行为能够获得的奖励。
Learning from Demonstrations
环境可以定义reward,但是很难优化,使用一个专家agent引导学习。
Chapter 3 Acme
Acme是一个强化学习算法的实现框架,能够用于分布式的智能体并行执行。将agent分为三个组件:与环境交互生成数据的actor,存储数据的replay系统以及更新agent行为的learner。这些组件通过builder构成一个完整的agent用于训练和评估agent的性能。
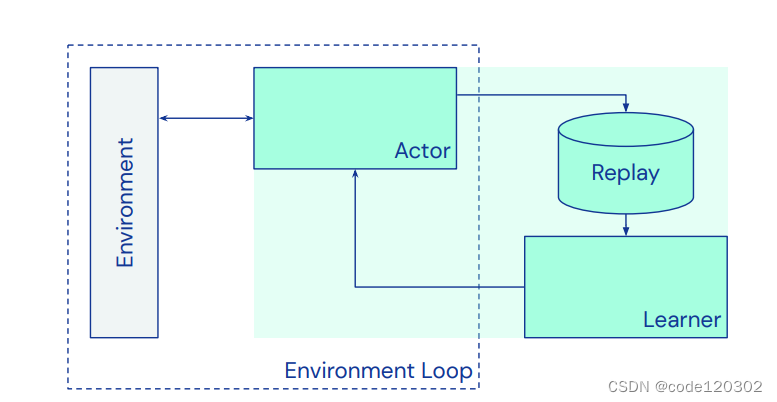
3.1 Environments and environment loops
使用dm_env这个包来定义环境:dm_env.Environment,里面的方法有:
重新开始一段序列
def reset(self) -> TimeStep
更新环境
def step(self, action) -> TimeStep
返回奖励
def reward_spec(self)
返回折扣因子
def discount_spec(self)
定义观察值
def observation_spec(self)
定义动作
def action_spec(self)
释放环境资源
def close(self)
......
上面六个方法为抽象方法,需要自定义。环境循环的伪代码如下:

3.2 Actors
Acme中实现了以下四个方法:
- select_action:根据观测值返回动作。
- observe:根据agent的动作生成元组(r, d, o, e)【奖励,折扣,下一时刻观测值,奖励】。
- observe_first:与observe功能相同,但只能在一个eposide的第一步调用。
- update:更新actor的内部参数,通常与learner的最新策略参数有关。
使用GenericActor来构造。当一个 Actor 被实例化时,它被赋予一个实现 VariableSource 接口的对象。此接口包括一个 get_variables 方法,可用于检索最新的策略参数集。

3.3 Experience replay and data storage
Acme通过使用Reverb来实现经验的存储。Reverb是一个高性能、可扩展且易于使用的回放缓冲库。它能支持大规模的数据流和学习算法。Reverb是server-client架构。
3.4 Learners
Learner的接口主要由一个step组成,该函数执行单个学习步骤来更新智能体的参数,对应于梯度下降的步长。Learner公开一个 get_variables 方法,该方法返回其参数的当前状态。通过定义此方法,Learner实现了描述Actor时引入的 VariableSource 接口,此方法主要用于在与环境交互时更新Actor。
3.5 Defining agents using Builders
定义builder的一些函数:
- make_policy:将策略构造为环境规范(environment spec)和神经网络的函数。
- make_replay_tables:返回replay tables。Reverb收集写入的数据,使用adder在多个表之间以不同的方式写入数据,然后可以在learner端进行采样。表的格式取决于环境的输入和输出的形状以及策略的输出。
- make_adder:构建adder用于记录数据到replay中。输入参数为环境规范和网络。
- make_actor:返回actor作为策略的函数。
- make_learner:返回处理agent参数更新的learner。
- make_dataset_iterator:构建replay client的数据迭代器。
3.6 Running an agent
在Acme中,一个experiment(agent)是一个builder,network和environment的结合。运行实验的组件可以使用ExperimentConfig数据类型进行特征定义,给定这样的配置,Acme 提供了一个简单的 run_experiment 函数,该函数将实例化所有必要的 actor、learner、environment loop组件。以下是experiement的伪代码:

第一行:载入环境
第二行:从环境中读取环境规范,即observation_spec, action_spec, reward_spec, discount_spec。
第三行:载入网络
第四行:定义builder,根据network和environment_spec生成策略。
第五、六行:创造replay table
第七行:形成数据迭代器,可直接读取使用
第八行:定义learner用于参数更新
第九行:定义adder用于添加数据到replay
第十行:定义actor用于与环境交互生成数据
第十一行:包装 actor 以定期对actor运行训练步骤
第十二行:创建EnvironmentLoop
第十三行:开始运行
下图为 Acme框架的组件
 Acme提供了一些工具,定义实验环境的配置和运行方式。从practitioner的角度,其更关注创建不同的环境和网络,定义agent的配置;从user角度,则是通过创建一个agent builder来得到新的算法。
Acme提供了一些工具,定义实验环境的配置和运行方式。从practitioner的角度,其更关注创建不同的环境和网络,定义agent的配置;从user角度,则是通过创建一个agent builder来得到新的算法。
实验还包含一个logger factory来打印debug过程当中的信息。
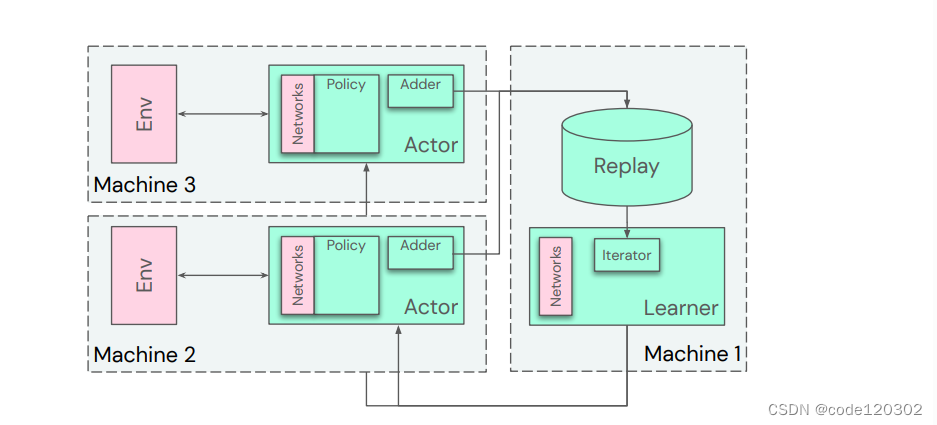
3.7 Distributed agents
下图为分布式智能体的示意图,通过增加actor的数量,actor并行执行加快数据产生的速度,learner将有充分的数据进行学习。
3.8 Modifications for offline agents
Acme适用run_offline_experiment函数进行无数据生成过程、拥有固定数据集的简单实验。使用OfflineBuilder定义agent,不包含adder组件。
Chapter 4 Agent Algorithms
4.2 Online RL
经典的DQN(2013, 2015)

Munchausen DQN (2020)

改进版本的DQN,普通版本DQN通过估计下一时刻的Q值,引导agent向Q值大的方向学习,通过自举更新Q值。而Munchausen DQN提出一个不同于Q值的引导信号,log-policy。对于一个确定性策略,每个最优动作的概率为1, 其他动作的概率为0,那么取log后,最优动作的log值为0,而其他动作的log值为负无穷,当把它加入到reward当中,可以引导agent学习最优动作,对policy进行自举(最优动作未知)。
性能提升的关键:在最大化奖励的同时会最小化新旧policy的KL散度。
目标Q为
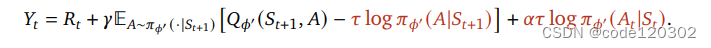
Recurrent Replay Distributed DQN(2018)

Recurrent Replay Distributed DQN 是一个分布式、有循环神经网络的DQN。用在部分可观测马尔可夫过程中,拥有较好的效果。
Distributed Distributional Deterministic Policy Gradients(2018)
D4PG是DDPG的分布式版本,一些改进:
- 分布式RL:在critic中使用Q distribution来替代Q function
- N-step return:使用n步的return替换掉一步的return
- Apex 和PER:从多个actor上采样,使用优先经验回放充分利用经验。
The Twin Delayed DDPG (2018)

TD3是DDPG的优化版本,一些改进:
- double DQN:使用两个网络进行Q值估算,选择较小的作为更新目标
- actor更新延迟:critic运行多次后再更新actor
- 目标策略平滑:价值函数的更新目标每次都在action上加一个小扰动,估计更准确,更健壮
未完待续
——————————————————————————————————————
参考文献&资料:
【1】Hoffman, M.W., Shahriari, B., Aslanides, J., Barth-Maron, G., Behbahani, F.M., Norman, T., Abdolmaleki, A., Cassirer, A., Yang, F., Baumli, K., Henderson, S., Novikov, A., Colmenarejo, S.G., Cabi, S., Gulcehre, C., Paine, T.L., Cowie, A., Wang, Z., Piot, B., & Freitas, N.D. (2020). Acme: A Research Framework for Distributed Reinforcement Learning. ArXiv, abs/2006.00979.
【2】https://zhuanlan.zhihu.com/p/286495498
【3】https://zhuanlan.zhihu.com/p/474734276
【4】https://zhuanlan.zhihu.com/p/111334500
【5】https://zhuanlan.zhihu.com/p/104433790