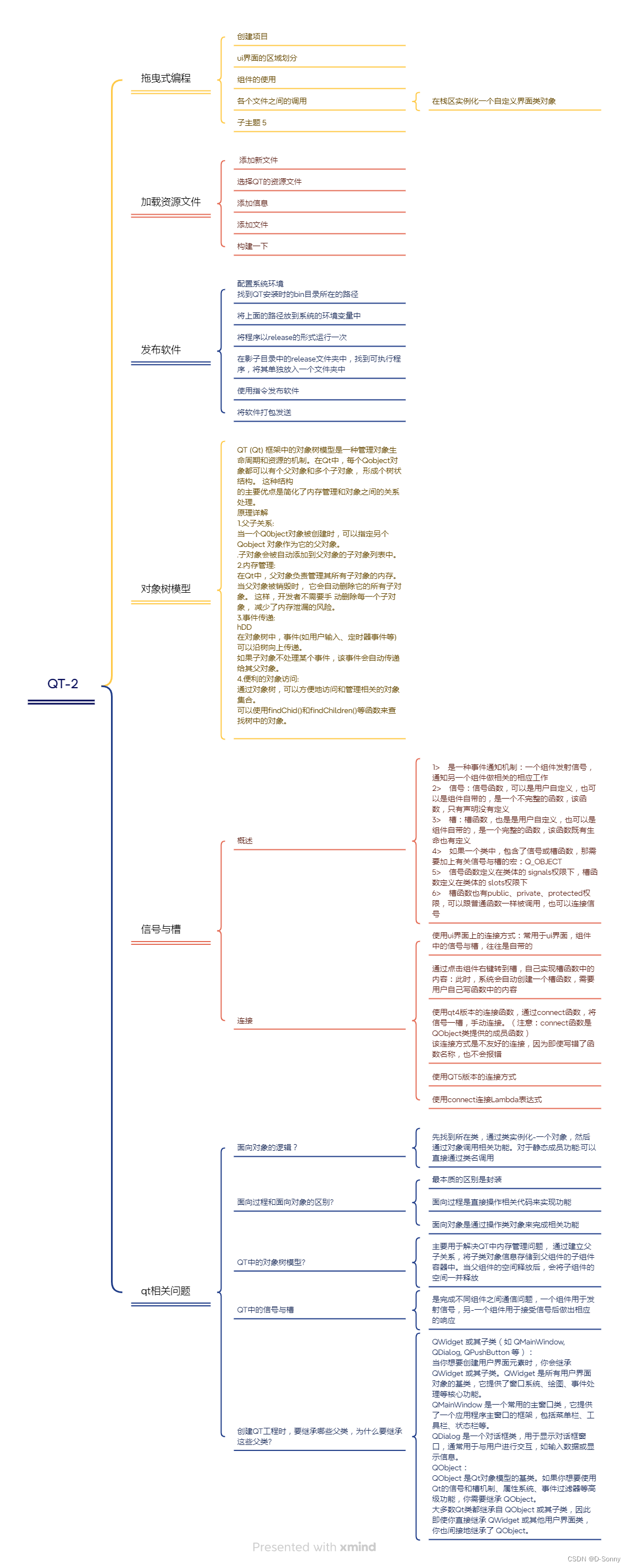
二. 概念分析
1. Span和SpanContext
结合上述示例,我们从Span开始入手来进行概念分析,但是说在最前面,Span在不同的分布式链路实现中,其定义是不全一样的,尽管Opentracing已经进行了概念的统一,但是具体到各家实现,有时候差异还是有的,故此,我们这里解释Span概念时,会更倾向于Jaeger。
一次请求,通常会由分布式系统中的多个工作单元组成,这些工作单元按照调用顺序串起来会形成一条链路,那么一条链路中的某个工作单元,就用Span来表示。但工作单元具体指什么呢,可以这么理解,服务B收到请求并开始处理,这就是一个工作单元,我们可以为这件事情创建一个Span来表示,又比如服务B调用了服务C,这又是一个工作单元,我们可以为调用服务C这件事情创建一个Span。所有Span串联起来就组成一条分布式链路,例如下图这样。

Span千万别想太复杂,简单点想Span就是链路中的被调用或调用行为。通常一个Span需要包含如下的主要信息。
- Operation Name。可以粗略理解为Span的名称,用于描述当前Span是做什么的;
- StartTimestamp和FinishTimestamp。分别表示Span的开始处理时间和结束处理时间;
- Tags。是一个Map,用于以键值对的形式存储Span在处理业务的过程中的一些数据;
- Logs。最本质还是一个Map,用于以键值对的形式存储一些数据,在Span处理结束并打印链路日志时会用到;
- SpanContext。表示Span的上下文,这个说法有点抽象,下面会单独把这个SpanContext拎出来讲一下。
一个Span,最主要的就是上述的这些内容,其中Tags和Logs有点抽象,SpanContext较为抽象,但是不慌,首先是Tags和Logs,这两兄弟本质就是存储Span在处理业务过程中的一些需要记录的信息,所有内容都可以记录,想记啥就记啥,想记在Tags还是记在Logs全凭自己心情,反正最终要用到这些数据的时候,我们都可以通过Span来拿到,但是Tags和Logs也不是完全没有区别,先看一下Jaeger中的Span对象的tags字段的签名,如下所示。
private final Map<String, Object> tags;
是一个简单的Map,然后logs字段要复杂一点,字段签名如下所示。
private List<LogData> logs;@Getter
public final class LogData {private final long time;private final String message;private final Map<String, ?> fields;LogData(long time, String message, Map<String, ?> fields) {this.time = time;this.message = message;this.fields = fields;}
}
乍一看是一个LogData的集合,但其实LogData本质就是对一个Map做了包装,所以一个LogData就是一组键值对,这就让logs相较于tags有一个天然的分组的优势,例如我当前Span某次调用下游的操作的相关数据可以存成一个LogData,我当前Span某次SQL执行的相关数据可以存成一个LogData。
现在再来揭开SpanContext的面纱。首先Span是一次请求链路中的某个工作单元的表示,那么对于某个Span来说,有两个东西很重要,其一是标识这次请求链路的traceId,毕竟Span得知道自己是在哪条链路上对吧,其二是标识当前工作单元的spanId,相当于Span在这条链路上的身份证。既然SpanContext作为Span上下文,理所应当的SpanContext就应该保存着对应的链路的traceId以及SpanContext所属Span的spanId,但是仅有traceId和spanId还不够,还得保存一个parentSpanId,当前Span可以通过parentSpanId表示对应链路中自己的上一个工作单元是哪个Span,最后,SpanContext还有一个字段叫做baggage,是一个Map,可以将数据从当前Span传递到下一个Span,即跨进程数据传递。
那么总结一下SpanContext里面的主要信息。
- traceId。Span所属链路的唯一标识;
- spanId。Span在对应链路上的唯一标识;
- parentSpanId。Span在对应链路上的父Span的唯一标识;
- baggage。以键值对的形式存储数据并进行跨进程传输。
其实无论是traceId,spanId还是baggage,都是需要从一个Span传递到下一个Span的,所以SpanContext主要就是负责跨进程数据传递。
那么到这里,Span是什么,想必在纸面上已经是说明白了七七八八了,下面再来看一下我愿称之为Span发射器的Tracer,先看一下io.opentracing包中提供的Tracer接口的注释,如下所示。
Tracer is a simple, thin interface for Span creation and propagation across arbitrary transports.
Tracer主要干两件事情,其一是创建Span,其二是传递Span,创建Span没什么好说的,传递Span又分同一进程和跨进程传递,至于怎么传递,后面可以结合Jaeger提供的相关实现来看一下。
到此为止,我们已经基本具备去阅读Jaeger对Opentracing相关实现的源码的基础了,所以现在就接合第一节中的客户端和服务端的示例代码,过一下相关源码实现,这样能更加理解Opentracing的相关概念。
首先再重温一下客户端这边的RestTemplate的拦截器的实现,如下所示。
public class RestTemplateTracingInterceptor implements ClientHttpRequestInterceptor {private final Tracer tracer;public RestTemplateTracingInterceptor(Tracer tracer) {this.tracer = tracer;}@NotNullpublic ClientHttpResponse intercept(@NotNull HttpRequest request, @NotNull byte[] body,ClientHttpRequestExecution execution) throws IOException {Span span = tracer.buildSpan(REST_TEMPLATE_SPAN_NAME).withTag(Tags.SPAN_KIND.getKey(), Tags.SPAN_KIND_CLIENT).start();span.setBaggageItem(REST_TEMPLATE_SPAN_TAG_URI, request.getURI().toString());tracer.inject(span.context(), Format.Builtin.HTTP_HEADERS, new HttpHeadersCarrier(request.getHeaders()));try (Scope scope = tracer.activateSpan(span)) {return execution.execute(request, body);} catch (IOException e) {Tags.ERROR.set(span, Boolean.TRUE);throw e;} finally {span.finish();}}}
首先我们通过Tracer创建了一个Span,因为使用的是Jaeger,这里的Tracer实际是JaegerTracer,创建出来的Span实际是JaegerSpan。在创建Span时,实际调用的是JaegerTracer.SpanBuilder#start方法,这个方法实现如下所示。
@Override
public JaegerSpan start() {JaegerSpanContext context;if (references.isEmpty() && !ignoreActiveSpan && null != scopeManager.activeSpan()) {asChildOf(scopeManager.activeSpan());}if (references.isEmpty() || !references.get(0).getSpanContext().hasTrace()) {context = createNewContext();} else {context = createChildContext();}long startTimeNanoTicks = 0;boolean computeDurationViaNanoTicks = false;if (startTimeMicroseconds == 0) {startTimeMicroseconds = clock.currentTimeMicros();if (!clock.isMicrosAccurate()) {startTimeNanoTicks = clock.currentNanoTicks();computeDurationViaNanoTicks = true;}} else {verifyStartTimeInMicroseconds();}JaegerSpan jaegerSpan = getObjectFactory().createSpan(JaegerTracer.this,operationName,context,startTimeMicroseconds,startTimeNanoTicks,computeDurationViaNanoTicks,tags,references);if (context.isSampled()) {metrics.spansStartedSampled.inc(1);} else {metrics.spansStartedNotSampled.inc(1);}return jaegerSpan;
}
上面的JaegerTracer.SpanBuilder#start方法在创建Span对象时,关键的地方其实是创建SpanContext,创建有两种情况,如下所示。
- 创建新SpanContext。在没有显式指定父Span,并且当前线程之前没有已经存在的Span时,就需要创建新SpanContext,也就意味着会生成新的traceId和spanId,对应的Span也会作为整个链路的首个节点,相应的parentSpanId会置为0,表示没有父Span;
- 创建子SpanContext。如果显式指定了父Span,或者当前线程之前有已经存在的Span且不能忽略这个已经存在的Span,就需要创建子SpanContext。
创建新SpanContext的情况没什么好说的,下面重点分析一下创建子SpanContext,对应方法为SpanBuilder#createChildContext,如下所示。
private JaegerSpanContext createChildContext() {JaegerSpanContext preferredReference = preferredReference();if (isRpcServer()) {if (isSampled()) {metrics.tracesJoinedSampled.inc(1);} else {metrics.tracesJoinedNotSampled.inc(1);}if (zipkinSharedRpcSpan) {return preferredReference;}}return getObjectFactory().createSpanContext(preferredReference.getTraceIdHigh(),preferredReference.getTraceIdLow(),Utils.uniqueId(),preferredReference.getSpanId(),preferredReference.getFlags(),getBaggage(),null);
}
在创建子SpanContext时,Jaeger在满足一定条件下会开启Zipkin的兼容模式,这个时候父SpanContext会直接作为子SpanContext返回,至于这么做有什么用,其实质就是改变了Span的理论模型,但我们这里不必深究,知道有这么回事即可。在更多的时候,创建子SpanContext时其实就是父SpanContext把traceId传递给子SpanContext,然后父SpanContext的spanId作为子SpanContext的parentSpanId,最后子SpanContext会新生成一个自己的spanId。
至此,我们已经了解了Tracer如何创建出Span,那么现在再来看一下io.opentracing中定义的Span接口长什么样,这决定了我们可以基于Span做一些什么操作。
public interface Span {SpanContext context();Span setTag(String key, String value);Span setTag(String key, boolean value);Span setTag(String key, Number value);<T> Span setTag(Tag<T> tag, T value);Span log(Map<String, ?> fields);Span log(long timestampMicroseconds, Map<String, ?> fields);Span log(String event);Span log(long timestampMicroseconds, String event);Span setBaggageItem(String key, String value);String getBaggageItem(String key);Span setOperationName(String operationName);void finish();void finish(long finishMicros);
}
基本就是Span持有什么,我们就能操作什么,比如在客户端的RestTemplate拦截器的示例代码中,我们就手动添加了Baggage键值对,而我们知道,Baggage是存在于SpanContext中并用于跨进程传输的,那么这里要如何做到跨进程传输呢,这里就要引出Opentracing中另外一套很重要的概念,即Inject和Extract。
2. Inject和Extract
要了解Inject和Extract,首先需要看一下Tracer接口中的如下两个方法。
<C> void inject(SpanContext spanContext, Format<C> format, C carrier);<C> SpanContext extract(Format<C> format, C carrier);
上述的inject() 方法和extract() 方法乍一看有点抽象,但是如果用第一节示例代码来解释应该就比较好理解,即客户端这边通过inject() 方法可以将SpanContext中的内容,注入到HTTP请求头中,怎么注入,就是format和carrier配合完成,然后服务端这边通过extract() 方法可以从HTTP请求头中提取出SpanContext,怎么提取,也是format和carrier配合完成。在大概知道inject() 方法和extract() 方法的作用后,我们再来看一下format和carrier,通过方法签名,我们可以知道carrier的类型是由format来决定的,所以format和carrier肯定是要配合使用的,这里以示例代码中的客户端的RestTemplate拦截器的实现举例,先看如下这一段示例代码。
tracer.inject(span.context(), Format.Builtin.HTTP_HEADERS, new HttpHeadersCarrier(request.getHeaders()));
先看一下Format.Builtin.HTTP_HEADERS是什么,如下所示。
public final static Format<TextMap> HTTP_HEADERS = new Builtin<TextMap>("HTTP_HEADERS");
上述能说明两个事情:第一就是Format.Builtin.HTTP_HEADERS的名称叫做HTTP_HEADERS,表明这个Format和注入信息到HTTP请求头有关,第二就是和Format.Builtin.HTTP_HEADERS配合使用的carrier的类型是TextMap。不过如果仔细看一下Format.Builtin.HTTP_HEADERS,发现其是一个Builtin对象,这个对象是一个很简单的对象,如下所示。
final class Builtin<C> implements Format<C> {private final String name;private Builtin(String name) {this.name = name;}public final static Format<TextMap> TEXT_MAP = new Builtin<TextMap>("TEXT_MAP");public final static Format<TextMapInject> TEXT_MAP_INJECT = new Builtin<TextMapInject>("TEXT_MAP_INJECT");public final static Format<TextMapExtract> TEXT_MAP_EXTRACT = new Builtin<TextMapExtract>("TEXT_MAP_EXTRACT");public final static Format<TextMap> HTTP_HEADERS = new Builtin<TextMap>("HTTP_HEADERS");public final static Format<Binary> BINARY = new Builtin<Binary>("BINARY");public final static Format<BinaryInject> BINARY_INJECT = new Builtin<BinaryInject>("BINARY_INJECT");public final static Format<BinaryExtract> BINARY_EXTRACT = new Builtin<BinaryExtract>("BINARY_EXTRACT");@Overridepublic String toString() {return Builtin.class.getSimpleName() + "." + name;}
}
那反正我是无论如何都无法想明白Builtin对象怎么和TextMap扯上关系,直到我发现其实每一个Format都有一个配套的Injector以及Extractor,例如默认情况下,Format.Builtin.HTTP_HEADERS配套的Injector和Extractor都是TextMapCodec,所以下面就分析一下TextMapCodec,先看一下类图,如下所示。

首先TextMapCodec分别实现了Injector和Extractor接口,对应的实现方法签名如下所示。
public void inject(JaegerSpanContext spanContext, TextMap carrier)public JaegerSpanContext extract(TextMap carrier)
那么现在就逐渐清晰明了了,我们之前困惑format对象怎么和carrier扯上关系,其实就是首先根据format对象拿到与之配对的Injector和Extractor,然后在Injector和Extractor中会调用到carrier对象来完成注入和提取的操作,那么具体到我们的示例里,format对象是Format.Builtin.HTTP_HEADERS,所以对应的carrier类型是TextMap,且其配对的Injector和Extractor均是TextMapCodec,然后TextMapCodec实现的inject() 和extract() 的入参carrier的类型也均是TextMap,所以Format.Builtin.HTTP_HEADERS就可以处理类型是TextMap的carrier。
那么示例代码中,客户端RestTemplate拦截器中,使用的format是Format.Builtin.HTTP_HEADERS,carrier是HttpHeadersCarrier,所以如何将SpanContext的内容写到HTTP请求头,需要分析一下TextMapCodec#inject方法,如下所示。
@Override
public void inject(JaegerSpanContext spanContext, TextMap carrier) {carrier.put(contextKey, contextAsString(spanContext));for (Map.Entry<String, String> entry : spanContext.baggageItems()) {carrier.put(keys.prefixedKey(entry.getKey(), baggagePrefix), encodedValue(entry.getValue()));}
}
我们知道上述方法中的carrier实际类型为HttpHeadersCarrier,所以看一下HttpHeadersCarrier#put方法干了什么,如下所示。
@Override
public void put(String key, String value) {httpHeaders.add(key, value);
}
真相大白了,就是HttpHeadersCarrier#put方法其实就是往HTTP请求头里塞键值对嘛,那么如法炮制,在示例代码服务端的TracingFilter中,使用的format是Format.Builtin.HTTP_HEADERS,carrier是HttpServletRequestExtractAdapter,所以其实最终会调用到HttpServletRequestExtractAdapter#iterator方法,如下所示。
@Override
public Iterator<Map.Entry<String, String>> iterator() {return new MultivaluedMapFlatIterator<>(headers.entrySet());
}
我感觉我又懂了,这肯定就是外层会for循环HttpServletRequestExtractAdapter,从而HttpServletRequestExtractAdapter的iterator() 方法就把HTTP请求头的迭代器返回出去了,然后外层就能拿到从客户端传递过来的数据了,包括SpanContext和Baggage中的内容都能拿到,从而完成了跨进程传递链路信息。
现在知道如何跨进程传递链路信息了,但是我们站在服务端的视角来审视一下,服务端收到一个携带链路信息的请求,然后这个请求在送到业务代码前,先经过了TracingFilter,我们在TracingFilter中通过format和carrier配合,将客户端传递过来的SpanContext获取了出来,然后基于SpanContext创建出来了当前这一个工作单元的Span,那么后续就应该进入到业务代码中了对吧,但是这个热乎乎的Span对象怎么传递下去呢,如果是通过方法参数的形式传递下去,那侵入性可太大了,例如Go语言,可能真的只能把Span放在context里面,然后把context当传家宝一样的逐层转递下去,但若是Java语言,我们应该想到一个很好使的东西,叫做ThreadLocal,没错,Span在线程中的传递,本质是依赖ThreadLocal,我们接着来分析是怎么一回事。
3. Scope和ScopeManager
现在来到示例的服务端TracingFilter的代码,注意到在获取到Span对象后,后续执行了如下这么一行代码。
Scope scope = tracer.activateSpan(span)
好的,目标出现了,上述代码通过Tracer的activateSpan() 方法传入Span并得到了一个Scope,Span我们已经很熟了,但是Scope又是什么妖魔鬼怪呢,我们先看一下Tracer接口中activateSpan() 方法的签名。
Scope activateSpan(Span span);
Tracer接口中的activateSpan() 方法用于在当前线程中激活一个Span,这里激活其实可以理解为绑定,即将一个Span绑定到当前线程上,然后得到一个Scope对象,那么再继续看一下Scope接口长啥样,如下所示。
public interface Scope extends Closeable {@Overridevoid close();}
只有一个close() 方法,这里其实就是反激活一个Span,即将一个Span从当前线程取消绑定,那么到这里,Scope基本可以理解为控制一个Span在线程中的活动时间段,当基于某个Span创建得到一个Scope起,这个Span在当前线程就开始活跃了,也就是当前线程任何一个地方都可以操作这个Span,当调用Scope的close() 方法时,对应Span就不活跃了,也就是当前线程不再能够任意操作这个Span了。
基本了解Scope的概念后,还是得结合具体的实现来加深理解,我们还是以Jaeger的实现进行举例,看一下JaegerTracer#activateSpan方法的实现,如下所示。
@Override
public Scope activateSpan(Span span) {return scopeManager().activate(span);
}
上述scopeManager() 方法默认情况下会返回一个ThreadLocalScopeManager,先简单将ScopeManager理解为管理Scope的管理器即可,下面先看一下ThreadLocalScopeManager的实现。
public class ThreadLocalScopeManager implements ScopeManager {final ThreadLocal<ThreadLocalScope> tlsScope = new ThreadLocal<ThreadLocalScope>();@Overridepublic Scope activate(Span span) {return new ThreadLocalScope(this, span);}@Overridepublic Span activeSpan() {ThreadLocalScope scope = tlsScope.get();return scope == null ? null : scope.span();}
}
我突然感觉自己就悟了,我们传进来的Span会被封装为一个ThreadLocalScope对象,同时ThreadLocalScopeManager中又有一个类型为ThreadLocal<ThreadLocalScope>的tlsScope字段,所以创建出来的ThreadLocalScope对象肯定就是放在了tlsScope中,这样就完成和当前线程绑定了嘛,但是上面的activate() 方法好像没有看到那里有将创建出来的ThreadLocalScope对象往tlsScope放,所以玄机肯定就在ThreadLocalScope的构造函数中,如下所示。
ThreadLocalScope(ThreadLocalScopeManager scopeManager, Span wrapped) {this.scopeManager = scopeManager;this.wrapped = wrapped;this.toRestore = scopeManager.tlsScope.get();scopeManager.tlsScope.set(this);
}
ThreadLocalScope在构造函数中做了两件事情,其一是将之前激活的Span获取出来以备后续恢复,也就是从ThreadLocal中把之前绑定的Span获取出来保存起,其二是将当前的Span放到ThreadLocal中,这会覆盖之前放的Span,这就表明同一线程同一时刻只能同时激活一个Span。
到这里就清晰明了了,我们要激活的Span其实是被包装成了一个ThreadLocalScope对象,然后所谓的激活,就是把ThreadLocalScope对象设置到ThreadLocalScopeManager持有的一个ThreadLocal中。
现在Span是激活了,那么我们要怎么获取到激活的Span呢,这就得看一下Tracer的activeSpan() 方法,Tracer接口中activeSpan() 方法的签名如下所示。
Span activeSpan();
直接看一下JaegerTracer对activeSpan() 方法的实现,如下所示。
@Override
public Span activeSpan() {return this.scopeManager.activeSpan();
}
继续跟进ThreadLocalScopeManager的activeSpan() 方法,如下所示。
@Override
public Span activeSpan() {ThreadLocalScope scope = tlsScope.get();return scope == null ? null : scope.span();
}
其实就是从ThreadLocal中把激活的Span获取出来。
最后再来分析一下ThreadLocalScope的close() 方法,如下所示。
@Override
public void close() {if (scopeManager.tlsScope.get() != this) {return;}scopeManager.tlsScope.set(toRestore);
}
因为每个Span在激活时,都会把之前已经激活的Span保存下来,而如果当前Span对应的ThreadLocalScope的close() 方法被调用,则表明当前Span已经结束活动,那么此时就应该将保存下来的之前Span再重新与当前线程绑定,所以ThreadLocalScope的close() 方法干的就是这么一个事情,而且ThreadLocalScope的close() 方法一定要记得调用,否则会引发内存泄漏。
4. Tracer
其实前文有提到Tracer是什么,之所以在这里又重新分析一次Tracer,是因为只有在知道Span和SpanContext,Inject和Extract,以及Scope和ScopeManager之后,才能明白Tracer是干什么的。在io.opentracing中定义的Tracer接口上,有如下这么一段注释。
Tracer is a simple, thin interface for Span creation and propagation across arbitrary transports.
也就是Tracer主要完成两件事情,其一是创建Span,其二是传递Span。
对于创建Span来说,Tracer主要是通过buildSpan() 方法得到一个SpanBuilder,然后基于SpanBuilder可以设置Span的父Span和Tags等信息,最后通过SpanBuilder的start() 方法创建出来Span。创建Span的相关源码,在本节第1小节介绍Span和SpanContext时已经进行了分析,这里就不重复分析了。
对于传递Span来说,又分两种情况,其一是跨进程传递,其二是线程中传递。对于跨进程传递,主要就是依赖Tracer的如下两个方法。
<C> void inject(SpanContext spanContext, Format<C> format, C carrier);<C> SpanContext extract(Format<C> format, C carrier);
跨进程传递Span,传递的主体是Span的SpanContext,inject() 方法可以把SpanContext注入到跨进程传递的介质中,例如HTTP请求头,具体一点就是利用format配套的Injector,把SpanContext注入给carrier中的传递介质例如HTTP请求头,然后extract() 方法可以从跨进程传递介质中把SpanContext提取出来,具体一点就是利用format配套的Extractor,从carrier中的传递介质例如HTTP请求头中提取出SpanContext。跨进程传递Span的相关源码,在本节第2小节介绍Inject和Extract时已经进行了分析,这里就不重复分析了。
对于线程中传递Span,主要是依赖Tracer的如下两个方法。
Scope activateSpan(Span span);Span activeSpan();
activateSpan() 方法意为激活Span,实际就是将Span和当前线程绑定,activeSpan() 方法意为拿到激活的Span,实际也就是拿到和当前线程绑定的Span,所以通过activateSpan() 方法和activeSpan() 方法,就能实现Span在线程中的传递,并且在Java语言中,绑定一个东西到一个线程,天然的适合使用ThreadLocal来使用,所以通常Span就是放在ThreadLocal中进行线程中传递的,具体的源码实现在本节第3小节介绍Scope和ScopeManager时已经进行了分析,这里就不重复分析了。
那么至此,Tracer是干啥的,其实是比较清楚的了,称之为Span发射器,不为过吧。
5. Jaeger中的Reporter
可以注意到,Span接口有定义一个finish() 方法,该方法签名如下所示。
void finish();
由上可知finish() 方法主要完成的事情就是设置Span的完成时间并记录Span,至于如何记录,取决于各家实现,本小节主要是分析一下Jaeger中的SpanReporter,首先看一下JaegerSpan#finish方法的实现,如下所示。
@Override
public void finish() {if (computeDurationViaNanoTicks) {long nanoDuration = tracer.clock().currentNanoTicks() - startTimeNanoTicks;finishWithDuration(nanoDuration / 1000);} else {finish(tracer.clock().currentTimeMicros());}
}
Span的持续时间就等于当前时间减去startTimeNanoTicks,startTimeNanoTicks是在Span被创建的时候完成赋值的,现在继续跟进一下JaegerSpan#finishWithDuration方法,如下所示。
private void finishWithDuration(long durationMicros) {if (durationMicrosUpdater.compareAndSet(this, null, durationMicros)) {if (context.isSampled()) {tracer.reportSpan(this);}} else {log.warn("Span has already been finished; will not be reported again.");}
}
上述方法实际就是基于CAS的方式来更新JaegerSpan的durationMicroseconds字段,更新成功则调用Tracer的reportSpan() 方法来记录Span,更新失败则表示Span已经被完成过,而Span是不能重复被完成的。现在继续看一下JaegerTracer#reportSpan方法的实现,如下所示。
void reportSpan(JaegerSpan span) {reporter.report(span);metrics.spansFinished.inc(1);
}
上述方法中会使用JaegerTracer持有的reporter字段(类型是Reporter)来记录Span,而JaegerTracer持有的reporter是在创建JaegerTracer时设置的,回顾一下示例代码中的TracerConfig,如下所示。
@Configuration
public class TracerConfig {@Autowiredprivate SpanReporter spanReporter;@Autowiredprivate Sampler sampler;@Beanpublic Tracer tracer() {return new JaegerTracer.Builder(TRACER_SERVICE_NAME).withTraceId128Bit().withSampler(sampler).withReporter(spanReporter).build();}}
我们在创建JaegerTracer时,设置了一个我们自己写的SpanReporter给JaegerTracer,我们自己写的SpanReporter实现了Reporter接口,如下所示。
public class SpanReporter implements Reporter {public void report(JaegerSpan span) {}public void close() {}}
所以在最终记录Span时,每一个Span都会送到我们写的SpanReporter中来,那这个时候所谓的记录Span,就很有可操作性了。
已知一条分布式链路中,实际就是由一个又一个的Span串起来的,每个Span都有一个相同的traceId,表明大家都是同一个分布式链路上的工作单元,同时每个Span都有spanId和parentSpanId,这样可以通过某个Span的spanId和parentSpanId明确这个Span在这条分布式链路中所处的位置,所以我们在记录Span时,其实就是需要读取出Span的traceId,spanId,parentSpanId和durationMicroseconds等参数,然后将这些参数组装成一定格式的数据,最后将Span的格式化后的数据送到分布式链路追踪系统的服务端,后续分布式链路追踪系统的服务端就可以结合指定的格式,解析出一个又一个Span的链路信息,最终给用户呈现出一条又一条的分布式链路。
我们在示例的SpanReporter中,没有对Span做任何操作,这主要是为了简化示例代码,但实际上,我们可以通过各种方式来发送Span数据给到我们的分布式链路追踪系统的服务端,例如发送Kafka,再例如打印日志再进行日志采集,总之可操作性是很强的。