目录
一、什么是数据库
二、ORDBMS 的一些术语
三、PostgreSQL 概述
四、PostgreSQL数据库优点和缺点
4.1PostgreSQL数据库的优点
4.2PostgreSQL数据库的缺点
4.3PostgreSQL 特征
五、Linux 上安装 PostgreSQL
5.1Yum 安装 PostgreSQL
5.1.1安装postgreSQL的官方yum仓库
5.1.2选择你要安装的版本
5.1.3初始化数据库
5.1.4启用并设置自动启动
5.2编译安装
5.2.1安装包介绍
六、数据库操作
6.1基本操作命令
6.1.1修改用户密码
6.2SQL语句分类
6.2.1SQL通用语法
6.2.2 SQL分类
6.3DDL语句
6.3.1CREATE创建
6.3.1.1创建数据库
6.3.1.2切换数据库
6.3.1.3创建表
6.3.2ALTER修改
6.3.2.1添加字段
6.3.2.2修改字段名称
6.3.3DROP删除
6.3.3.1删除表
6.4DML语句
6.4.1插入数据
6.4.2更新数据
6.4.3删除数据
6.5DQL语句
6.5.1基本查询
6.5.2条件查询
6.5.2.1 比较运算符
6.5.2.2逻辑运算符
6.5.3排序查询
6.5.3.1升序排序
6.5.3.2降序排序
6.5.3.3去重、压缩
6.5.4limit子句
6.5.5 as 别名
6.5.5.1设置字段别名
6.5.6子查询
6.5.6.1 EXISTS关键字
6.5.6.2IN关键字
6.6DCL语句
6.6.1创建用户
6.6.2用户授权
6.6.2.1用户库授权
6.6.2.2用户表授权
6.6.2.3查看权限
6.6.3撤销权限与删除用户
6.6.4角色
一、什么是数据库
- ORDBMS(对象关系数据库系统)是面向对象技术与传统的关系数据库相结合的产物,查询处理是 ORDBMS 的重要组成部分,它的性能优劣将直接影响到DBMS 的性能。
- ORDBMS在原来关系数据库的基础上,增加了一些新的特性。
- RDBMS 是关系数据库管理系统,是建立实体之间的联系,最后得到的是关系表。
- OODBMS 面向对象数据库管理系统,将所有实体都看成对象,并将这些对象类进行封装,对象之间的通信通过消息 OODBMS 对象关系数据库在实质上还是关系数据库
二、ORDBMS 的一些术语
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
三、PostgreSQL 概述
PostgreSQL 是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。
PostgreSQL 开发者把它念作 post-gress-Q-L
四、PostgreSQL数据库优点和缺点
4.1PostgreSQL数据库的优点
-
可靠性与稳定性:PostgreSQL以其出色的稳定性和可靠性著称,能够保证长时间无故障运行,尤其适合企业级应用和对数据完整性要求较高的场景。
-
全面的标准SQL支持:严格遵循ACID属性,并高度符合SQL标准,支持丰富的SQL特性,如窗口函数、递归查询、CTEs(公用表表达式)等。
-
强大的数据类型与存储:支持多种复杂数据类型,包括数组、JSON、XML、HSTORE、Range类型等。同时,PostgreSQL的表分区、索引、物化视图等功能提高了数据管理和查询性能。
-
安全性:提供了细粒度的访问控制,支持行级和列级的安全策略,可通过SSL加密通信,并有良好的审计功能。
-
扩展性:通过丰富的插件体系,可以很容易地添加新的数据类型和功能,例如全文搜索、地理位置索引(通过PostGIS扩展)、JSONB查询优化等。
-
高可用与容灾:支持逻辑复制、物理复制、热备和读写分离,能够构建高可用的集群环境。
-
社区与生态系统:PostgreSQL拥有活跃的开源社区和广泛的用户群,有许多周边工具和框架支持,为企业级应用提供丰富的解决方案。
-
完全开源免费:相对于oracle数据库,postgresql数据库完全开源免费,可以随意使用,且不会被其它公司控制,而oracle数据库属于商业数据库,不完全开放,而MySQL数据库先是被SUN公司收购,而后又被Oracle公司收购,在这之后,版本不再更新,InnoDB引擎也被Oracle控制
4.2PostgreSQL数据库的缺点
-
横向扩展能力:虽然PostgreSQL支持一定的水平扩展,如逻辑复制和流复制,但相比某些天生设计为分布式数据库系统的解决方案,其在大规模集群扩展方面的操作相对复杂,尤其是处理极高并发读写负载时。
-
内存占用较大:在处理大量并发连接或复杂查询时,PostgreSQL可能会消耗较多内存,尤其对于大型数据库实例,内存管理需要精细调整。
-
NoSQL功能有限:虽然PostgreSQL支持JSONB等非关系型数据存储,但在处理某些NoSQL数据库擅长的大规模非结构化数据存储和查询时,不如专门的NoSQL数据库那样高效。
-
入门门槛较高:相比于一些轻量级或专为Web开发优化的数据库系统,PostgreSQL的复杂特性和配置项可能让初学者感到有些难以掌握。
-
性能调优复杂:对于某些特定场景下的性能优化,可能需要深入了解PostgreSQL的工作原理和内部机制,对普通用户来说,优化过程可能会显得较为复杂。
4.3PostgreSQL 特征
-
函数:通过函数,可以在数据库服务器端执行指令程序。
-
索引:用户可以自定义索引方法,或使用内置的 B 树,哈希表与 GiST 索引。
-
触发器:触发器是由SQL语句查询所触发的事件。如:一个INSERT语句可能触发一个检查数据完整性的触发器。触发器通常由INSERT或UPDATE语句触发。
-
多版本并发控制:PostgreSQL使用多版本并发控制(MVCC,Multiversion concurrency control)系统进行并发控制,该系统向每个用户提供了一个数据库的"快照",用户在事务内所作的每个修改,对于其他的用户都不可见,直到该事务成功提交。
-
规则:规则(RULE)允许一个查询能被重写,通常用来实现对视图(VIEW)的操作,如插入(INSERT)、更新(UPDATE)、删除(DELETE)。
-
数据类型:包括文本、任意精度的数值数组、JSON 数据、枚举类型、XML 数据
等。 -
全文检索:通过 Tsearch2 或 OpenFTS,8.3版本中内嵌 Tsearch2。
-
NoSQL:JSON,JSONB,XML,HStore 原生支持,至 NoSQL 数据库的外部数据包装器。
-
数据仓库:能平滑迁移至同属 PostgreSQL 生态的 GreenPlum,DeepGreen,HAWK 等,使用 FDW 进行 ETL
五、Linux 上安装 PostgreSQL
PostgreSQL: The world's most advanced open source database
这里是官网,点击菜单栏上的 Download ,可以看到这里包含了很多平台的安装包,包括 Linux、Windows、Mac OS等 。
PostgreSQL官网https://www.postgresql.org/国产数据库排行https://www.modb.pro/dbRankPostgreSQL中文社区http://www.postgres.cn/v2/document全球数据库排行https://db-engines.com/en/
选择需要安装的软件版本及环境

5.1Yum 安装 PostgreSQL
systemctl stop firewalld
setenforce 0yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
#安装postgreSQL的官方yum仓库yum install -y postgresql14-server
#安装postgresql14-server,14为版本号,可以选择自己想要安装的版本/usr/pgsql-14/bin/postgresql-14-setup initdb
#初始化数据库,创建系统表空间、全局对象以及其他必须的内部数据库systemctl start postgresql-14
systemctl enable postgresql-14
#启用并设置自动启动5.1.1安装postgreSQL的官方yum仓库

5.1.2选择你要安装的版本
安装postgresql14-server,14为版本号,可以选择自己想要安装的版本

5.1.3初始化数据库
初始化数据库,创建系统表空间、全局对象以及其他必须的内部数据库
yum安装完毕之后直接启动会报错,需要先执行初始化命令,如果没有执行初始化,直接启动服务时,数据库集群不存在,就会报错

5.1.4启用并设置自动启动


5.2编译安装

5.2.1安装包介绍
这六个文件分别是 PostgreSQL 14.1版本的源代码压缩包及其相关的校验文件。以下是它们之间的区别:
- postgresql-14.1.tar.bz2:这是 PostgreSQL 14.1版本的源代码压缩包,使用 bzip2 压缩。可以使用该文件进行手动编译和安装 PostgreSQL。
- postgresql-14.1.tar.bz2.md5:这个文件包含了 postgresql-14.1.tar.bz2 文件的 MD5 校验值,用于验证下载文件的完整性。可以使用 md5sum 工具来验证文件的 MD5 值。
- postgresql-14.1.tar.bz2.sha256:这个文件包含了 postgresql-14.1.tar.bz2 文件的 SHA-256 校验值,用于验证下载文件的完整性。可以使用 sha256sum 工具来验证文件的 SHA-256 值。
- postgresql-14.1.tar.gz:这是 PostgreSQL 14.1 版本的源代码压缩包,使用 gzip 压缩。可以使用该文件进行手动编译和安装 PostgreSQL
- postgresql-14.1.tar.gz.md5:这个文件包含了 postgresql-14.1.tar.gz 文件的 MD5 校验值,用于验证下载文件的完整性。可以使用 md5sum 工具来验证文件的 MD5 值。
- postgresql-14.1.tar.gz.sha256:这个文件包含了 postgresql-14.1.tar.gz 文件的 SHA-256 校验值,用于验证下载文件的完整性。可以使用 sha256sum 工具来验证文件的 SHA-256 值。
- 通常情况下,可以选择下载其中一个 .tar.bz2 或 .tar.gz 的压缩包,然后使用相应的校验文件(.md5 或 .sha256)验证下载的文件是否完整
- .bz2 和 .gz 分别是两种不同的压缩格式,它们在本质上是不同的压缩算法
- 在选择使用哪一种格式的安装包时,主要的考虑因素包括压缩率、解压速度、以及个人的偏好
六、数据库操作
6.1基本操作命令
| 命令 | 作用
| ---------- | ----------------------------------------------
| \l | 查看系统中现存的数据库
| \q | 退出客户端程序psql
| \dt | 查看表
| \d | 查看表结构
| \di | 查看索引
| \c | 从一个数据库中转到另一个数据库中
| create | 创建数据库、表、用户等
| alter | 修改表结构
| insert | 添加数据
| update | 修改数据
| drop | 删除
| delete | 删除数据
| \help或\h | 显示所有SQL语句用法
| \h SQL语句 | 显示具体的SQL语句用法。例如 \h create database
| \? | 显示所有以\开头的命令 
6.1.1修改用户密码

6.2SQL语句分类
SQL(Structured Query Language,结构化查询语言)是一种用于管理关系型数据库的标准计算机语言,它涵盖了数据定义、数据查询、数据操作(增删改)以及数据控制四大功能
6.2.1SQL通用语法
- SQL语句可以单行或者多行书写,以分号结尾;
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
6.2.2 SQL分类
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库访问权限 |
6.3DDL语句
DDL(Data Definition Language,数据定义语言)是SQL中的一种语句集合,主要用于创建、修改和删除数据库中的结构对象,如数据库、表、视图、索引、触发器、存储过程等
常用语句有:CREATE(创建),DROP(删除),ALTER(修改)
6.3.1CREATE创建
CREATE语句主要用于创建库,表,以及用户等操作
su - postgrespsql6.3.1.1创建数据库

6.3.1.2切换数据库

6.3.1.3创建表
语法为:create table table_name (字段1...字段类型[约束],字段2...字段类型....[约束]);
create table kendeji (id int not null,name varchar(15),age varchar(3),address varchar(15),section char(3));
6.3.2ALTER修改
ALTER语句主要用于修改字段的信息或者插入新的字段
6.3.2.1添加字段
添加字段的基本语法为:alter table table_name add cloumn [字段][类型]
alter table kendeji add column cardid varchar(10);
6.3.2.2修改字段名称
修改字段名称的基本语法为:alter table table_name rename cloumn [old字段] to [new字段];
alter table kendeji rename column id to num;
6.3.3DROP删除
DROP主要用于对库、表、用户等进行删除操作
6.3.3.1删除表
删除表基本语法为:drop table table_name;
删除库的语法为:drop database database_name;
#切换到其它库,防止删除库的时候因为占用库导致删除失败
6.4DML语句
DML(Data Manipulation Language,数据操纵语言)是SQL中用于操作数据库表中数据的指令集。它主要涵盖以下几种类型的语句
插入数据(INSERT):在表中插入新的数据
更新数据(UPDATE):更新表中现有的数据
删除数据(DELETE):删除表中的数据
6.4.1插入数据
插入数据的语法为:
指定字段添加: insert into table_name (字段1,字段2...) values (值1,值2...);
全部字段添加: insert into table_name values (值1,值2...);
批量添加数据: insert into table_name values (值1,值2...),(值1,值2...)...;
[root@localhost ~]#su - postgres
上一次登录:六 4月 20 11:36:56 CST 2024pts/2 上
-bash-4.2$ psql
psql (14.11)
输入 "help" 来获取帮助信息.postgres=# create database work;
CREATE DATABASE
postgres=# \l数据库列表名称 | 拥有者 | 字元编码 | 校对规则 | Ctype | 存取权限
-----------+----------+----------+-------------+-------------+-----------------------nanjing | postgres | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | postgres | postgres | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | template0 | postgres | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | =c/postgres +| | | | | postgres=CTc/postgrestemplate1 | postgres | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 | =c/postgres +| | | | | postgres=CTc/postgreswork | postgres | UTF8 | zh_CN.UTF-8 | zh_CN.UTF-8 |
(5 行记录)postgres=# create table jichu (id int not null primary key,name varchar(15),age int,address varchar(10));
CREATE TABLE
postgres=# \d关联列表架构模式 | 名称 | 类型 | 拥有者
----------+-------+--------+----------public | jichu | 数据表 | postgres
(1 行记录)postgres=# \d jichu数据表 "public.jichu"栏位 | 类型 | 校对规则 | 可空的 | 预设
---------+-----------------------+----------+----------+------id | integer | | not null | name | character varying(15) | | | age | integer | | | address | character varying(10) | | |
索引:"jichu_pkey" PRIMARY KEY, btree (id)postgres=# insert into jichu values (1,'xiaowang',25,'beijing');
INSERT 0 1
postgres=# insert into jichu values (2,'xiaoli',20,'nanjing');
INSERT 0 1
postgres=# insert into jichu values (3,'xiaoliu',22,'wuhan');
INSERT 0 1
postgres=# select * from jichu;id | name | age | address
----+----------+-----+---------1 | xiaowang | 25 | beijing2 | xiaoli | 20 | nanjing3 | xiaoliu | 22 | wuhan
(3 行记录)postgres=# 
6.4.2更新数据
基本语法为:update 表名 set 字段1 = 值1,字段2 = 值2,...[where 条件];
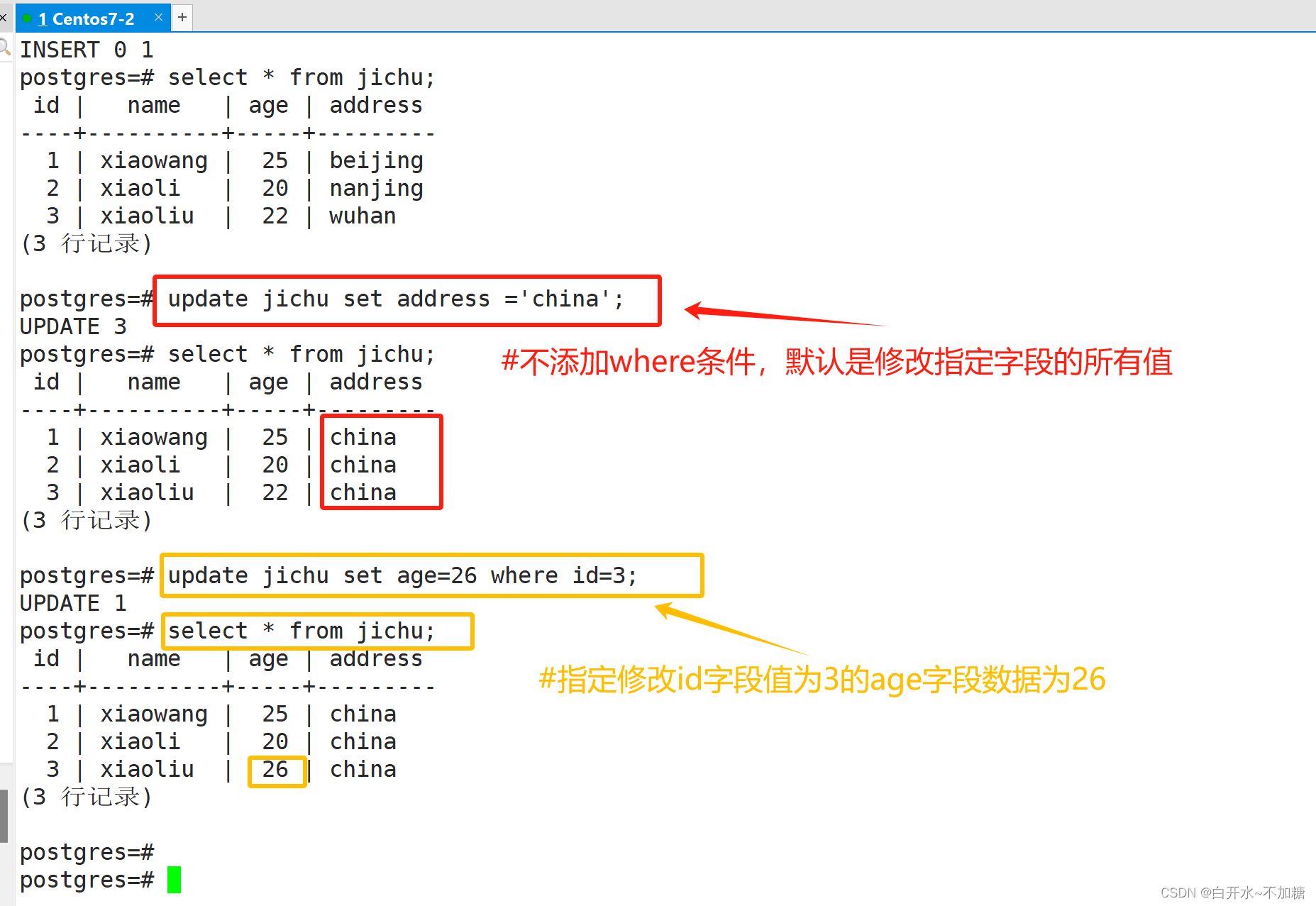
6.4.3删除数据
基本语法为:delete from table_name [where 条件];
注意:
DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据
DELETE 语句不能删除某一个字段的值。


6.5DQL语句
DQL (Data Query Language) 是SQL语言中专门用于查询数据的部分,它的主要目的是从数据库中检索满足特定条件的数据,而不改变数据库的状态 它的语句只有一个:select
在数据库操作中,查询的频率要远远高于增、删、改操作,在访问页面时,页面中所有的信息都需要通过select查询出来
6.5.1基本查询
基本语法为:select 字段1,字段2,... from table_name [where 条件];
postgres=# \c work
您现在已经连接到数据库 "work",用户 "postgres".
work=# create table mixue (id int not null primary key,name varchar(15),age int,address varchar(10)); #创建表
CREATE TABLE
work=# insert into mixue values (1,'xiaowang',30,'beijing'),(2,'xiaozhao',28,'shanghai'),(3,'xiaoli',25,'shanghai'),(4,'xiaoliu',26,'beijing'); #插入数据
INSERT 0 4
work=# select * from mixue; #查询所有字段id | name | age | address
----+----------+-----+----------1 | xiaowang | 30 | beijing2 | xiaozhao | 28 | shanghai3 | xiaoli | 25 | shanghai4 | xiaoliu | 26 | beijing
(4 行记录)work=# select name,age from mixue; #查询指定字段
6.5.2条件查询
6.5.2.1 比较运算符
| 比较运算符 | 功能 |
|---|---|
| > 或!= | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| BETWEEN ... AND ... | 在某个范围之内(含最小、最大值) |
| IN(..) | 在in之后的列表中的值 |
| LIKE 占位符 | 模糊匹配( _ :匹配单个字符,%:匹配任意个字符) |
| IS NULL | 是NULL |

6.5.2.2逻辑运算符
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非,不是 |

6.5.3排序查询
基本语法为:select 字段1, 字段2, ... from 表名 [where 条件]order by 排序字段1,排序字段2, ... [asc|desc]
| 关键字 | 排序方式 |
|---|---|
| asc | 升序排序,默认排序方式asc 可以省略 |
| desc | 降序排序 |
| distinct | 去重、压缩 |
work=# select * from mixue;id | name | age | address
----+----------+-----+----------1 | xiaowang | 30 | beijing2 | xiaozhao | 28 | shanghai3 | xiaoli | 25 | shanghai4 | xiaoliu | 26 | beijing
(4 行记录)work=# select * from mixue order by age; age升序排序,默认排序方式asc 可以省略id | name | age | address
----+----------+-----+----------3 | xiaoli | 25 | shanghai4 | xiaoliu | 26 | beijing2 | xiaozhao | 28 | shanghai1 | xiaowang | 30 | beijing
(4 行记录)work=# select * from mixue order by age desc; #age字段值降序排序id | name | age | address
----+----------+-----+----------1 | xiaowang | 30 | beijing2 | xiaozhao | 28 | shanghai4 | xiaoliu | 26 | beijing3 | xiaoli | 25 | shanghai
(4 行记录)work=# select distinct address from mixue; #数据压缩,将相同的数据压缩、去重address
----------shanghaibeijing
(2 行记录)work=#6.5.3.1升序排序

6.5.3.2降序排序

6.5.3.3去重、压缩

6.5.4limit子句
limit关键字用于限制查询结果返回的数据行数
limit子句的用法:limit count:返回查询结果的前count行。
例如,如果你想从mixue表中获取前10条记录:Sql
select * from mixue limit 10;
limit offset, count:返回从offset行开始的count行。
这里的offset是指从查询结果的第几行开始,count是指从offset开始往后取多少行。
例如,如果你想要从第11行开始取10条记录:Sql
select * from employees limit 10 offset 10;
这意味着查询结果会跳过前10行,然后返回接下来的10行记录在PostgreSQL中,limit通常与offset配合使用来进行分页查询。
需要注意的是,如果同时使用OFFSET和limit,较大的OFFSET值会导致性能下降,尤其是在大表上进行分页时,因为数据库需要扫描并丢弃很多不需要的行才能找到需要的行。在实现分页时,最好能利用索引来优化查询性能6.5.5 as 别名
在PostgreSQL中,为字段或表设置别名(alias)通常用于查询结果中,使列名更具可读性或简化后期处理
6.5.5.1设置字段别名
设置字段别名
基本语法为:select 字段1 [as] 字段1别名,字段2 [as] 字段2别名,.... from table_name;
#as可以省略

6.5.5.1设置表别名
设置表别名
基本语法为:select 表别名.字段1,表别名.字段2,.... from table_name [as] alias_table;

6.5.5.1as还可以作为连接语句
此外,as还可以作为连接语句,将select查询到的语句,重定向到新的表格当中
基本语法为:create table new_table [as] select 字段1,字段2.... from table_name;

#注释:只能复制表的字段与数据,不能复制表的约束,例如主键、唯一键等
6.5.6子查询
子查询(Subquery)是在SQL查询中嵌套的查询语句,它先执行内层查询,然后将结果作为外层查询的一部分进行处理。子查询通常放在比较运算符的右侧,或者用在IN、ANY、ALL、EXISTS等关键字后面
6.5.6.1 EXISTS关键字
EXISTS的参数是一个任意的SELECT语句, 或者说子查询。系统对子查询进行运算以判断它是否返回行。如果它至少返回一行,那么EXISTS的结果就为“真”; 如果子查询没有返回行,那么EXISTS的结果是“假”。
子查询可以引用来自周围的查询的变量,这些变量在该子查询的任何一次计算中都起常量的作用。
这个子查询通常只是运行到能判断它是否可以返回至少一行为止, 而不是等到全部结束。在这里写任何有副作用的子查询都是不明智的(例如调用序列函数);这些副作用是否发生是很难判断的。
因为结果只取决于是否会返回行,而不取决于这些行的内容, 所以这个子查询的输出列表通常是无关紧要的。
一个常用的编码习惯是用EXISTS(SELECT 1 WHERE ...)的形式写所有的EXISTS测试。不过这条规则有例外,例如那些使用INTERSECT的子查询
基本语法为:select 字段1,字段2,... from table_name where exists (子语句);

#这个简单的例子类似在所有字段上的一次内联接,但是它为每个mixue表的行生成最多一个输出,即使存在多个匹配haidilao的行也如此∶
6.5.6.2IN关键字
在查询表的数据时通过将子语句查询到的数据,当作主语的参数去匹配查询的表
基本语法为:select 字段1,字段2,... from table_name where 匹配字段 in (子语句);


6.6DCL语句
- DCL(Data Control Language)是SQL语言中的一个重要组成部分,它主要负责对数据库系统的访问权限和安全性进行管理。
- DCL语句主要用于授予或撤销用户对数据库对象(如表、视图、序列、存储过程等)的操作权限,以及管理事务和数据库的安全策略。
常用语句有:GRANT,REVOKE
| 权限 | 说明 |
|---|---|
| all,all privileges | 所有权限 |
| insert | 插入数据 |
| select | 查询数据 |
| update | 更新表的数据 |
| delete | 删除表中数据 |
| create | 创建库,表 |
| drop | 删除库,表 |
| index | 建立索引 |
| alter | 更改表属性 |
| create temp orary tableslock tables | 锁表 |
| create view | 创建视图 |
| show view | 显示视图 |
| create routine | 创建存储过程 |
| alter routine | 修改存储过程 |
| event | 事件 |
| trigger on | 创建触发器 |
6.6.1创建用户

6.6.2用户授权
6.6.2.1用户库授权
用户库授权:grant 权限 on database data_name to 用户;
grant all privileges on database work to zzz;
#授权用户可以操作work库
6.6.2.2用户表授权
用户表授权:grant 权限 on 表名 in schema public to 用户;
\c work;
grant all privileges on all tables in schema public to zzz;
#切换到work库下,授权库下的所有表
6.6.2.3查看权限
#退出之后 psql -U 指定用户 -d 指定库
[root@localhost ~]# psql -U zzz -d work;\du # 列出所有的用户,包括他们的角色、登录权限、超用户权限等信息\du username # 查看指定用户的权限6.6.3撤销权限与删除用户
revoke all privileges on database work from zzz;
#删除库权限
revoke all privileges on all tables in schema public from zzz;
#删除表权限
work=# drop user zzz;
#删除用户

6.6.4角色
在postgresql数据库当中,用户与角色没有严格意思上的区分,一个用户相当于一个角色