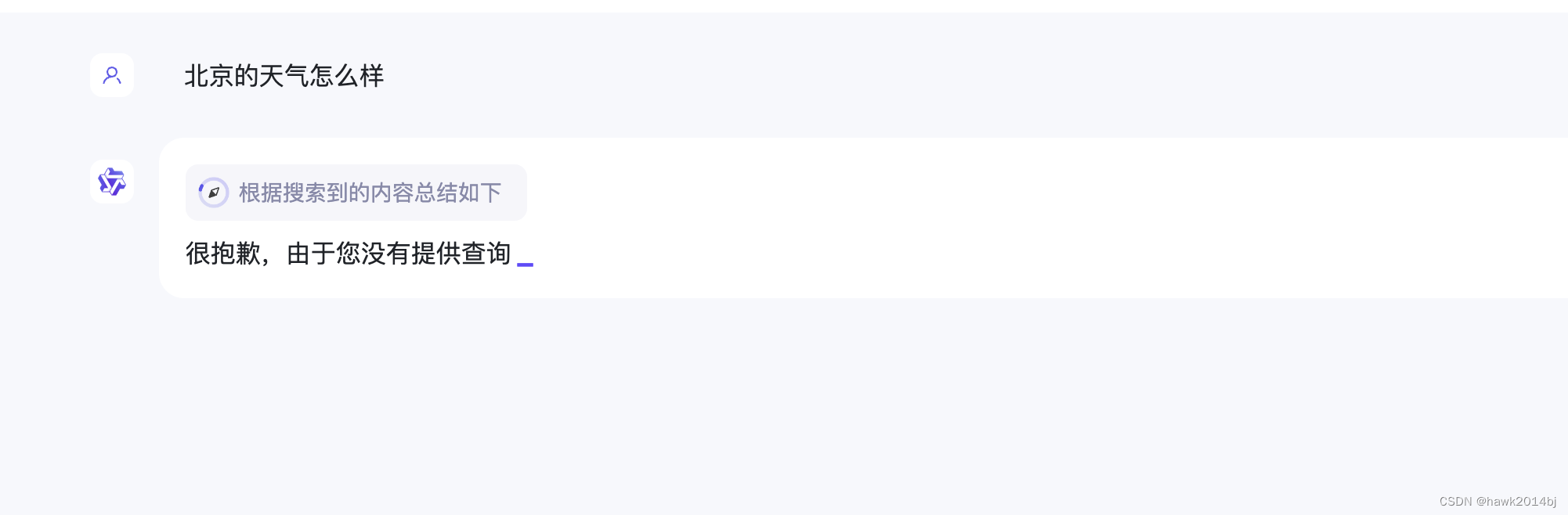
AI Agent 是 AIGC 落地实现的场景之一,与 RAG 不同,RAG 是对数据的扩充,是模型可以学习到新数据或者本地私有数据。AI Agent 是自己推理,自己做,例如你对 AI Agent 说我要知道今天上海的天气怎么样,由于 AI 是个模型,底层通过一套复杂的算法进行相似度的比较,最终选出相似最高的答案,所以模型本身是无法访问网络去获取数据的。如果AIGC 只能回答问题,复杂任务和与外界的沟通还需要人手工处理,就没有发挥出模型应有的能力。所以,AI Agent 做的就是根据具体问题的上下文信息,使用对应的工具得到需要的信息,并最终将信息返回。最典型的场景就是去 Google、百度搜索,模型对结果集进行理解并最终给出结果。我们看到当问 “千问” 天气问题的时候,他是去外部查找信息的。
通过 LlamaIndex + 本地 Ollama Llama3实现了一个 Agent。
首先安装依赖
pip install llama-index
pip install llama-index-llms-ollama
pip install python-dotenv
pip install llama-index-embeddings-huggingface
申请LlamaIndex API
https://cloud.llamaindex.ai/ 申请一个 API Key,使用 Llama Parser 解析 PDF。
Ollama
下载 Ollama3 和 Code Llama,一个模型用于 RAG,一个模型用于生成代码
解析 PDF 并生成 Python 代码
运行以下代码,输入 promote
"read content of test.py and write a python script to call post api to create a new item " 稍等文件就可以生成了。
from llama_index.llms.ollama import Ollama
from llama_parse import LlamaParse
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, PromptTemplate
from llama_index.core.embeddings import resolve_embed_model
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.agent import ReActAgent
from pydantic import BaseModel
from llama_index.core.output_parsers import PydanticOutputParser
from llama_index.core.query_pipeline import QueryPipeline
from prompts import context, code_parser_template
from code_reader import code_reader
from dotenv import load_dotenv
import os
import astload_dotenv()llm = Ollama(model="llama3", request_timeout=30.0)parser = LlamaParse(result_type="markdown")file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader("./data", file_extractor=file_extractor).load_data()embed_model = resolve_embed_model("local:BAAI/bge-m3")
vector_index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
query_engine = vector_index.as_query_engine(llm=llm)tools = [QueryEngineTool(query_engine=query_engine,metadata=ToolMetadata(name="api_documentation",description="this gives documentation about code for an API. Use this for reading docs for the API",),),code_reader,
]code_llm = Ollama(model="llama3")
agent = ReActAgent.from_tools(tools, llm=code_llm, verbose=True, context=context)class CodeOutput(BaseModel):code: strdescription: strfilename: strparser = PydanticOutputParser(CodeOutput)
json_prompt_str = parser.format(code_parser_template)
json_prompt_tmpl = PromptTemplate(json_prompt_str)
output_pipeline = QueryPipeline(chain=[json_prompt_tmpl, llm])while (prompt := input("Enter a prompt (q to quit): ")) != "q":retries = 0while retries < 3:try:result = agent.query(prompt)next_result = output_pipeline.run(response=result)cleaned_json = ast.literal_eval(str(next_result).replace("assistant:", ""))breakexcept Exception as e:retries += 1print(f"Error occured, retry #{retries}:", e)if retries >= 3:print("Unable to process request, try again...")continueprint("Code generated")print(cleaned_json["code"])print("\n\nDesciption:", cleaned_json["description"])filename = cleaned_json["filename"]try:with open(os.path.join("output", filename), "w") as f:f.write(cleaned_json["code"])print("Saved file", filename)except:print("Error saving file...")
相关文件上传到资源中了,或者访问git 进行下载 https://gitee.com/wan2000/aiagent。有了 Agent 这个框架感觉可以做很多类型 Agent,比如写数据库SQL、或者做复杂的查查询、接入第三方 API等,接下来我会做些 Agent 看看效果如何 。


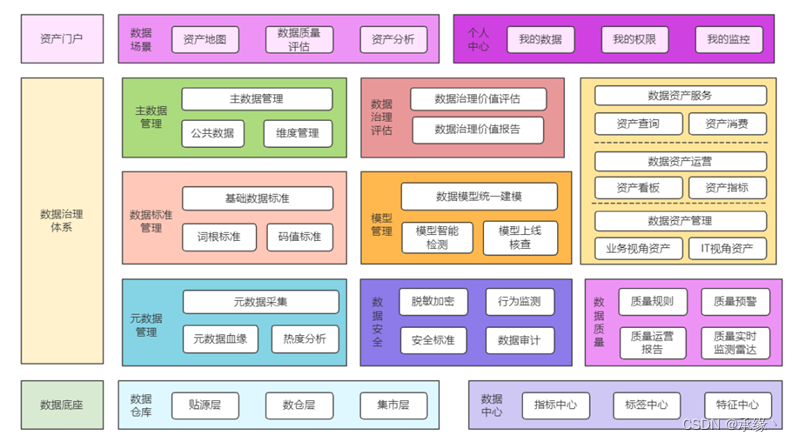
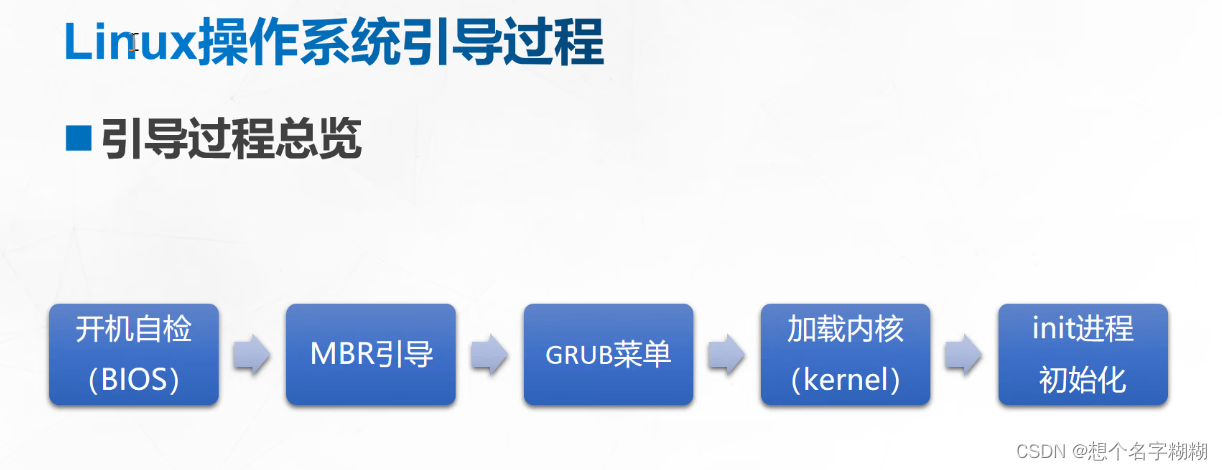

![[RTOS 学习记录] 复杂工程项目的管理](https://img-blog.csdnimg.cn/img_convert/299e42a82bcfd1b79b68a9e95fba5a32.png#pic_center)
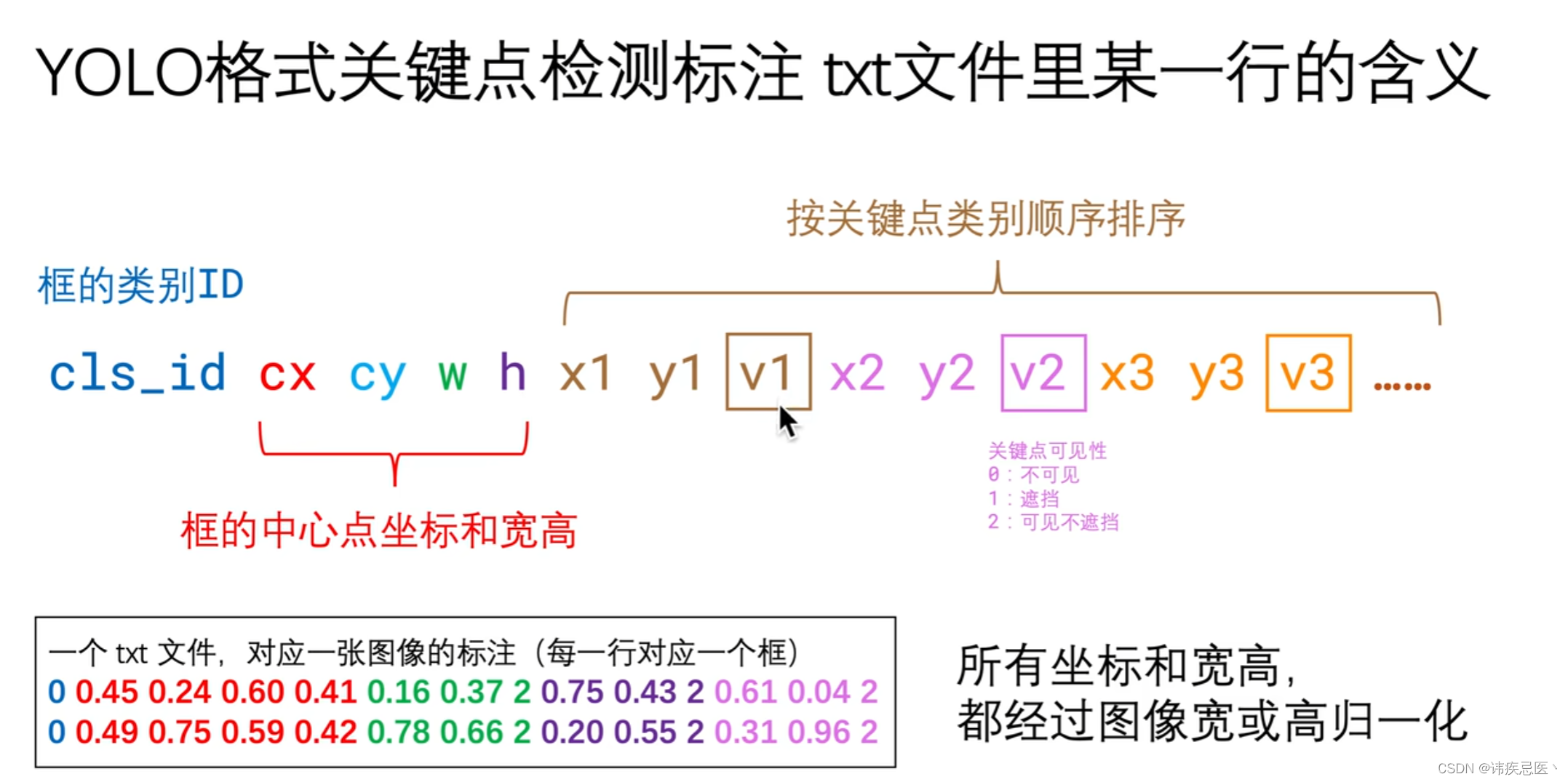





](https://img-blog.csdnimg.cn/direct/50f12046d42b4bb6b78540658bf380c8.png)