文章目录
- 1、YOLOv8安装及使用
- 1.2、命令行使用
- 1.3、使用python-API模型预测
- 1.4、pt转换ONNX
- 2、训练三角板关键点检测模型
- 2.1、训练命令
- 3、ONNX Runtime部署
1、YOLOv8安装及使用
参考链接: 同济子豪兄视频
github原文链接
# 安装yolov8
pip install ultralytics --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple# 验证安装成功
import ultralytics
ultralytics.checks()# 安装其它第三方工具包
pip install numpy opencv-python pillow pandas matplotlib seaborn tqdm wandb seedir emoji -i https://pypi.tuna.tsinghua.edu.cn/simple

1.2、命令行使用

1、命令行对图片进行推理预测
# 目标检测预测
yolo detect predict model=yolov8x.pt source=2.jpg device=0# 图像分割预测
yolo segment predict model=yolov8x-seg.pt source=2.jpg device=0# 图像分类预测
yolo classify predict model=yolov8x-cls.pt source=1.jpeg device=0# 人体姿态估计(关键点检测)预测
yolo pose predict model=yolov8x-pose-p6.pt source=1.jpeg device=0# 预测结果保存在runs目录
# YOLOV8命令行模板
yolo task=detect mode=train model=yolov8n.yaml args...classify predict yolov8n-cls.yaml args...segment val yolov8n-seg.yaml args...export yolov8n.pt format=onnx args...# YOLOV8预测命令行参数
https://docs.ultralytics.com/usage/cfg/#predict
https://docs.ultralytics.com/modes/predict
2、命令行对视频进行推理预测
# 目标检测预测
yolo detect predict model=yolov8x.pt source=videos/video_fruits.mp4 device=0# 图像分割预测
yolo segment predict model=yolov8x-seg.pt source=videos/video_fruits.mp4 device=0# 图像分类预测
yolo classify predict model=yolov8x-cls.pt source=videos/video_2.mp4 device=0# 人体姿态估计(关键点检测)预测
yolo pose predict model=yolov8x-pose-p6.pt source=videos/cxk.mp4 device=0
yolo pose predict model=yolov8x-pose-p6.pt source=videos/mother_wx.mp4 device=0
3、命令行对摄像头数据进行实时推理
yolo pose predict model=yolov8n-pose.pt source=0 show
文档
# YOLOV8官方文档
YOLOV8文档:https://docs.ultralytics.comYOLOV8的Github主页:https://github.com/ultralytics/ultralytics# YOLOV8预训练模型库
https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8# YOLOV8-Pose任务预训练模型
https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models#pose1.3、使用python-API模型预测
# 导入工具包
from ultralytics import YOLOimport cv2
import matplotlib.pyplot as plt
%matplotlib inlineimport torch
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device:', device)# 载入模型
model = YOLO('yolov8x-pose-p6.pt')# 计算设备
# 切换计算设备
model.to(device)
# 模型自带信息
model.device
# 模型名字
model.names# 预测
# 传入图像、视频、摄像头ID(对应命令行的 source 参数
img_path = '1.jpg'
results = model(img_path)# 解析预测结果
len(results)
result[0]
# 预测框的所有类别(MS COCO数据集八十类)
results[0].names# 预测类别 ID
results[0].boxes.cls# 有几个预测框
num_bbox = len(results[0].boxes.cls)
print('预测出 {} 个框'.format(num_bbox))# 每个框的置信度
results[0].boxes.conf# 每个框的:左上角XY坐标、右下角XY坐标
results[0].boxes.xyxy# 转成整数的 numpy array
bboxes_xyxy = results[0].boxes.xyxy.cpu().numpy().astype('uint32')# 每个框,每个关键点的 XY坐标 置信度
results[0].keypoints.shapebboxes_keypoints = results[0].keypoints.data.cpu().numpy().astype('uint32')
bboxes_keypoints# opencv可视化关键点
img_bgr = cv2.imread(img_path)
plt.imshow(img_bgr[:,:,::-1])
plt.show()# 框(rectangle)可视化配置
bbox_color = (150, 0, 0) # 框的 BGR 颜色
bbox_thickness = 6 # 框的线宽# 框类别文字
bbox_labelstr = {'font_size':6, # 字体大小'font_thickness':14, # 字体粗细'offset_x':0, # X 方向,文字偏移距离,向右为正'offset_y':-80, # Y 方向,文字偏移距离,向下为正
}# 关键点 BGR 配色
kpt_color_map = {0:{'name':'Nose', 'color':[0, 0, 255], 'radius':25}, # 鼻尖1:{'name':'Right Eye', 'color':[255, 0, 0], 'radius':25}, # 右边眼睛2:{'name':'Left Eye', 'color':[255, 0, 0], 'radius':25}, # 左边眼睛3:{'name':'Right Ear', 'color':[0, 255, 0], 'radius':25}, # 右边耳朵4:{'name':'Left Ear', 'color':[0, 255, 0], 'radius':25}, # 左边耳朵5:{'name':'Right Shoulder', 'color':[193, 182, 255], 'radius':25}, # 右边肩膀6:{'name':'Left Shoulder', 'color':[193, 182, 255], 'radius':25}, # 左边肩膀7:{'name':'Right Elbow', 'color':[16, 144, 247], 'radius':25}, # 右侧胳膊肘8:{'name':'Left Elbow', 'color':[16, 144, 247], 'radius':25}, # 左侧胳膊肘9:{'name':'Right Wrist', 'color':[1, 240, 255], 'radius':25}, # 右侧手腕10:{'name':'Left Wrist', 'color':[1, 240, 255], 'radius':25}, # 左侧手腕11:{'name':'Right Hip', 'color':[140, 47, 240], 'radius':25}, # 右侧胯12:{'name':'Left Hip', 'color':[140, 47, 240], 'radius':25}, # 左侧胯13:{'name':'Right Knee', 'color':[223, 155, 60], 'radius':25}, # 右侧膝盖14:{'name':'Left Knee', 'color':[223, 155, 60], 'radius':25}, # 左侧膝盖15:{'name':'Right Ankle', 'color':[139, 0, 0], 'radius':25}, # 右侧脚踝16:{'name':'Left Ankle', 'color':[139, 0, 0], 'radius':25}, # 左侧脚踝
}# 点类别文字
kpt_labelstr = {'font_size':4, # 字体大小'font_thickness':10, # 字体粗细'offset_x':0, # X 方向,文字偏移距离,向右为正'offset_y':150, # Y 方向,文字偏移距离,向下为正
}# 骨架连接 BGR 配色
skeleton_map = [{'srt_kpt_id':15, 'dst_kpt_id':13, 'color':[0, 100, 255], 'thickness':5}, # 右侧脚踝-右侧膝盖{'srt_kpt_id':13, 'dst_kpt_id':11, 'color':[0, 255, 0], 'thickness':5}, # 右侧膝盖-右侧胯{'srt_kpt_id':16, 'dst_kpt_id':14, 'color':[255, 0, 0], 'thickness':5}, # 左侧脚踝-左侧膝盖{'srt_kpt_id':14, 'dst_kpt_id':12, 'color':[0, 0, 255], 'thickness':5}, # 左侧膝盖-左侧胯{'srt_kpt_id':11, 'dst_kpt_id':12, 'color':[122, 160, 255], 'thickness':5}, # 右侧胯-左侧胯{'srt_kpt_id':5, 'dst_kpt_id':11, 'color':[139, 0, 139], 'thickness':5}, # 右边肩膀-右侧胯{'srt_kpt_id':6, 'dst_kpt_id':12, 'color':[237, 149, 100], 'thickness':5}, # 左边肩膀-左侧胯{'srt_kpt_id':5, 'dst_kpt_id':6, 'color':[152, 251, 152], 'thickness':5}, # 右边肩膀-左边肩膀{'srt_kpt_id':5, 'dst_kpt_id':7, 'color':[148, 0, 69], 'thickness':5}, # 右边肩膀-右侧胳膊肘{'srt_kpt_id':6, 'dst_kpt_id':8, 'color':[0, 75, 255], 'thickness':5}, # 左边肩膀-左侧胳膊肘{'srt_kpt_id':7, 'dst_kpt_id':9, 'color':[56, 230, 25], 'thickness':5}, # 右侧胳膊肘-右侧手腕{'srt_kpt_id':8, 'dst_kpt_id':10, 'color':[0,240, 240], 'thickness':5}, # 左侧胳膊肘-左侧手腕{'srt_kpt_id':1, 'dst_kpt_id':2, 'color':[224,255, 255], 'thickness':5}, # 右边眼睛-左边眼睛{'srt_kpt_id':0, 'dst_kpt_id':1, 'color':[47,255, 173], 'thickness':5}, # 鼻尖-左边眼睛{'srt_kpt_id':0, 'dst_kpt_id':2, 'color':[203,192,255], 'thickness':5}, # 鼻尖-左边眼睛{'srt_kpt_id':1, 'dst_kpt_id':3, 'color':[196, 75, 255], 'thickness':5}, # 右边眼睛-右边耳朵{'srt_kpt_id':2, 'dst_kpt_id':4, 'color':[86, 0, 25], 'thickness':5}, # 左边眼睛-左边耳朵{'srt_kpt_id':3, 'dst_kpt_id':5, 'color':[255,255, 0], 'thickness':5}, # 右边耳朵-右边肩膀{'srt_kpt_id':4, 'dst_kpt_id':6, 'color':[255, 18, 200], 'thickness':5} # 左边耳朵-左边肩膀
]for idx in range(num_bbox): # 遍历每个框# 获取该框坐标bbox_xyxy = bboxes_xyxy[idx] # 获取框的预测类别(对于关键点检测,只有一个类别)bbox_label = results[0].names[0]# 画框img_bgr = cv2.rectangle(img_bgr, (bbox_xyxy[0], bbox_xyxy[1]), (bbox_xyxy[2], bbox_xyxy[3]), bbox_color, bbox_thickness)# 写框类别文字:图片,文字字符串,文字左上角坐标,字体,字体大小,颜色,字体粗细img_bgr = cv2.putText(img_bgr, bbox_label, (bbox_xyxy[0]+bbox_labelstr['offset_x'], bbox_xyxy[1]+bbox_labelstr['offset_y']), cv2.FONT_HERSHEY_SIMPLEX, bbox_labelstr['font_size'], bbox_color, bbox_labelstr['font_thickness'])bbox_keypoints = bboxes_keypoints[idx] # 该框所有关键点坐标和置信度# 画该框的骨架连接for skeleton in skeleton_map:# 获取起始点坐标srt_kpt_id = skeleton['srt_kpt_id']srt_kpt_x = bbox_keypoints[srt_kpt_id][0]srt_kpt_y = bbox_keypoints[srt_kpt_id][1]# 获取终止点坐标dst_kpt_id = skeleton['dst_kpt_id']dst_kpt_x = bbox_keypoints[dst_kpt_id][0]dst_kpt_y = bbox_keypoints[dst_kpt_id][1]# 获取骨架连接颜色skeleton_color = skeleton['color']# 获取骨架连接线宽skeleton_thickness = skeleton['thickness']# 画骨架连接img_bgr = cv2.line(img_bgr, (srt_kpt_x, srt_kpt_y),(dst_kpt_x, dst_kpt_y),color=skeleton_color,thickness=skeleton_thickness)# 画该框的关键点for kpt_id in kpt_color_map:# 获取该关键点的颜色、半径、XY坐标kpt_color = kpt_color_map[kpt_id]['color']kpt_radius = kpt_color_map[kpt_id]['radius']kpt_x = bbox_keypoints[kpt_id][0]kpt_y = bbox_keypoints[kpt_id][1]# 画圆:图片、XY坐标、半径、颜色、线宽(-1为填充)img_bgr = cv2.circle(img_bgr, (kpt_x, kpt_y), kpt_radius, kpt_color, -1)# 写关键点类别文字:图片,文字字符串,文字左上角坐标,字体,字体大小,颜色,字体粗细kpt_label = str(kpt_id) # 写关键点类别 ID(二选一)# kpt_label = str(kpt_color_map[kpt_id]['name']) # 写关键点类别名称(二选一)img_bgr = cv2.putText(img_bgr, kpt_label, (kpt_x+kpt_labelstr['offset_x'], kpt_y+kpt_labelstr['offset_y']), cv2.FONT_HERSHEY_SIMPLEX, kpt_labelstr['font_size'], kpt_color, kpt_labelstr['font_thickness'])plt.imshow(img_bgr[:,:,::-1])
plt.show()cv2.imwrite('C1_output.jpg', img_bgr)
逐帧处理函数
def process_frame(img_bgr):'''输入摄像头画面 bgr-array,输出图像 bgr-array'''results = model(img_bgr, verbose=False) # verbose设置为False,不单独打印每一帧预测结果# 预测框的个数num_bbox = len(results[0].boxes.cls)# 预测框的 xyxy 坐标bboxes_xyxy = results[0].boxes.xyxy.cpu().numpy().astype('uint32') # 关键点的 xy 坐标bboxes_keypoints = results[0].keypoints.cpu().numpy().astype('uint32')for idx in range(num_bbox): # 遍历每个框# 获取该框坐标bbox_xyxy = bboxes_xyxy[idx] # 获取框的预测类别(对于关键点检测,只有一个类别)bbox_label = results[0].names[0]# 画框img_bgr = cv2.rectangle(img_bgr, (bbox_xyxy[0], bbox_xyxy[1]), (bbox_xyxy[2], bbox_xyxy[3]), bbox_color, bbox_thickness)# 写框类别文字:图片,文字字符串,文字左上角坐标,字体,字体大小,颜色,字体粗细img_bgr = cv2.putText(img_bgr, bbox_label, (bbox_xyxy[0]+bbox_labelstr['offset_x'], bbox_xyxy[1]+bbox_labelstr['offset_y']), cv2.FONT_HERSHEY_SIMPLEX, bbox_labelstr['font_size'], bbox_color, bbox_labelstr['font_thickness'])bbox_keypoints = bboxes_keypoints[idx] # 该框所有关键点坐标和置信度# 画该框的骨架连接for skeleton in skeleton_map:# 获取起始点坐标srt_kpt_id = skeleton['srt_kpt_id']srt_kpt_x = bbox_keypoints[srt_kpt_id][0]srt_kpt_y = bbox_keypoints[srt_kpt_id][1]# 获取终止点坐标dst_kpt_id = skeleton['dst_kpt_id']dst_kpt_x = bbox_keypoints[dst_kpt_id][0]dst_kpt_y = bbox_keypoints[dst_kpt_id][1]# 获取骨架连接颜色skeleton_color = skeleton['color']# 获取骨架连接线宽skeleton_thickness = skeleton['thickness']# 画骨架连接img_bgr = cv2.line(img_bgr, (srt_kpt_x, srt_kpt_y),(dst_kpt_x, dst_kpt_y),color=skeleton_color,thickness=skeleton_thickness) # 画该框的关键点for kpt_id in kpt_color_map:# 获取该关键点的颜色、半径、XY坐标kpt_color = kpt_color_map[kpt_id]['color']kpt_radius = kpt_color_map[kpt_id]['radius']kpt_x = bbox_keypoints[kpt_id][0]kpt_y = bbox_keypoints[kpt_id][1]# 画圆:图片、XY坐标、半径、颜色、线宽(-1为填充)img_bgr = cv2.circle(img_bgr, (kpt_x, kpt_y), kpt_radius, kpt_color, -1)# 写关键点类别文字:图片,文字字符串,文字左上角坐标,字体,字体大小,颜色,字体粗细kpt_label = str(kpt_id) # 写关键点类别 ID(二选一)# kpt_label = str(kpt_color_map[kpt_id]['name']) # 写关键点类别名称(二选一)img_bgr = cv2.putText(img_bgr, kpt_label, (kpt_x+kpt_labelstr['offset_x'], kpt_y+kpt_labelstr['offset_y']), cv2.FONT_HERSHEY_SIMPLEX, kpt_labelstr['font_size'], kpt_color, kpt_labelstr['font_thickness'])return img_bgr
视频逐帧处理(模板)
def generate_video(input_path='videos/robot.mp4'):filehead = input_path.split('/')[-1]output_path = "out-" + fileheadprint('视频开始处理',input_path)# 获取视频总帧数cap = cv2.VideoCapture(input_path)frame_count = 0while(cap.isOpened()):success, frame = cap.read()frame_count += 1if not success:breakcap.release()print('视频总帧数为',frame_count)# cv2.namedWindow('Crack Detection and Measurement Video Processing')cap = cv2.VideoCapture(input_path)frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# fourcc = int(cap.get(cv2.CAP_PROP_FOURCC))# fourcc = cv2.VideoWriter_fourcc(*'XVID')fourcc = cv2.VideoWriter_fourcc(*'mp4v')fps = cap.get(cv2.CAP_PROP_FPS)out = cv2.VideoWriter(output_path, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))# 进度条绑定视频总帧数with tqdm(total=frame_count-1) as pbar:try:while(cap.isOpened()):success, frame = cap.read()if not success:break# 处理帧# frame_path = './temp_frame.png'# cv2.imwrite(frame_path, frame)try:frame = process_frame(frame)except:print('error')passif success == True:# cv2.imshow('Video Processing', frame)out.write(frame)# 进度条更新一帧pbar.update(1)# if cv2.waitKey(1) & 0xFF == ord('q'):# breakexcept:print('中途中断')passcv2.destroyAllWindows()out.release()cap.release()print('视频已保存', output_path)
1.4、pt转换ONNX
python-api
from ultralytics import YOLO
model = YOLO('yolov8n-pose.pt')
success = model.export(format='onnx')
验证onnx是否转换成功
import onnx# 读取 ONNX 模型
onnx_model = onnx.load('checkpoint/Triangle_215_yolov8l_pretrain.onnx')# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)print('无报错,onnx模型载入成功')
命令行转换
# 导出onnx文件
yolo export model=weights/yolov8s-seg.pt format=onnx simplify=True opset=12
2、训练三角板关键点检测模型
训练使用到的数据集下载

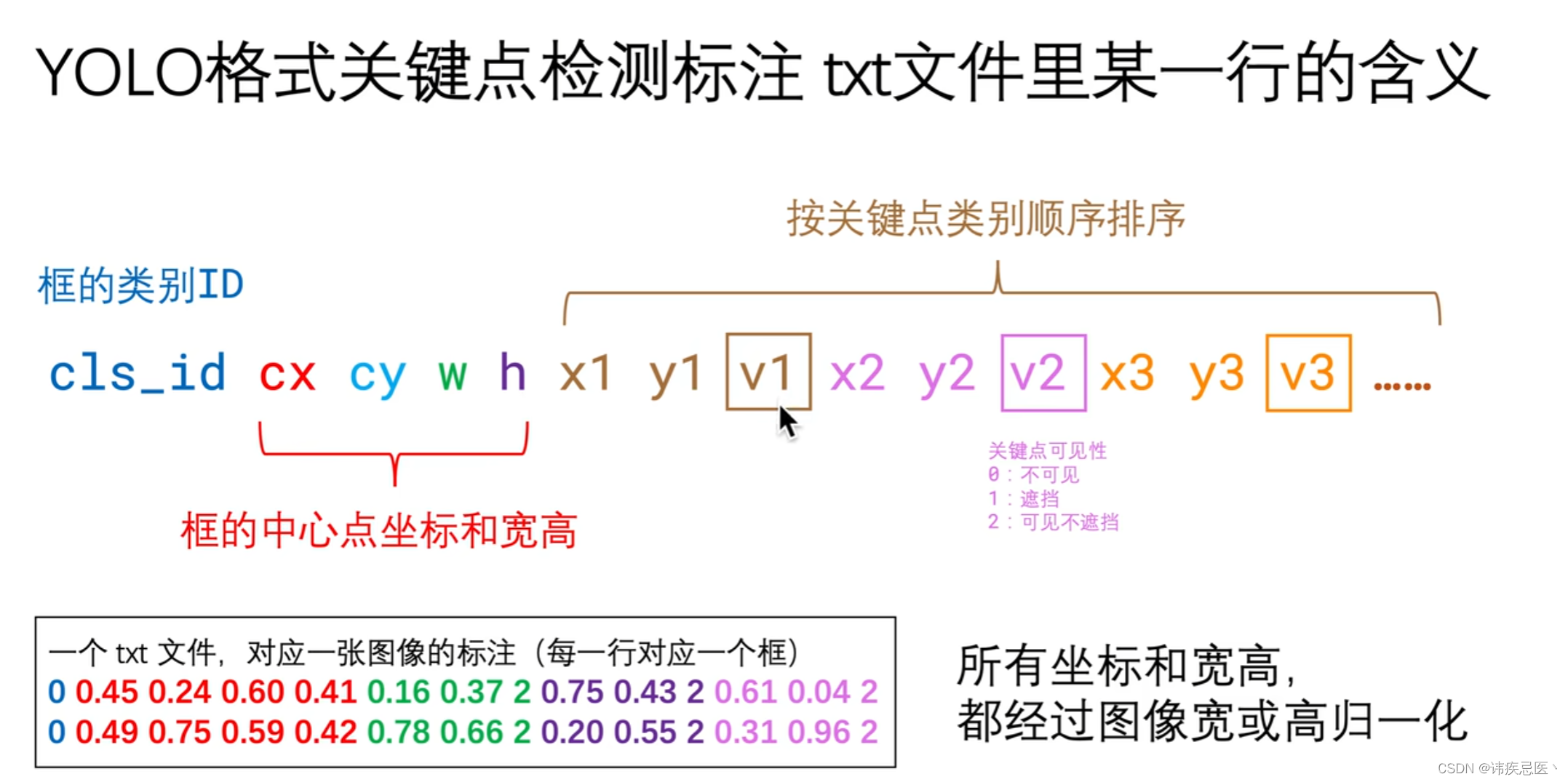
下载yaml文件
wget https://zihao-download.obs.cn-east-3.myhuaweicloud.com/yolov8/datasets/Triangle_215_Dataset/Triangle_215.yaml
几个比较重要的训练参数
model YOLOV8模型
data 配置文件(.yaml格式)
pretrained 是否在预训练模型权重基础上迁移学习泛化微调
epochs 训练轮次,默认100
batch batch-size,默认16
imgsz 输入图像宽高尺寸,默认640
device 计算设备(device=0 或 device=0,1,2,3 或 device=cpu)
project 项目名称,建议同一个数据集取同一个项目名称
name 实验名称,建议每一次训练对应一个实验名称
optimizer 梯度下降优化器,默认’SGD’,备选:[‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’]
close_mosaic 是否关闭马赛克图像扩增,默认为0,也就是开启马赛克图像扩增
cls 目标检测分类损失函数cls_loss权重,默认0.5
box 目标检测框定位损失函数box_loss权重,默认7.5
dfl 类别不均衡时Dual Focal Loss损失函数dfl_loss权重,默认1.5。
pose 关键点定位损失函数pose_loss权重,默认12.0(只在关键点检测训练时用到)
kobj 关键点置信度损失函数keypoint_loss权重,默认2.0(只在关键点检测训练时用到)
2.1、训练命令
如果遇到报错CUDA out of memory,内核-关闭所有内核,或调小batch参数
# yolov8n-pose模型,迁移学习微调
!yolo pose train data=Triangle_215.yaml model=yolov8n-pose.pt pretrained=True project=Triangle_215 name=n_pretrain epochs=50 batch=16 device=0# yolov8n-pose模型,随机初始权重,从头重新学习
!yolo pose train data=Triangle_215.yaml model=yolov8n-pose.pt project=Triangle_215 name=n_scratch epochs=50 batch=16 device=0# 训练yolov8s-pose关键点检测模型
# yolov8s-pose模型,迁移学习微调
!yolo pose train data=Triangle_215.yaml model=yolov8s-pose.pt pretrained=True project=Triangle_215 name=s_pretrain epochs=50 batch=16 device=0# yolov8s-pose模型,随机初始权重,从头重新学习
!yolo pose train data=Triangle_215.yaml model=yolov8s-pose.pt project=Triangle_215 name=s_scratch epochs=50 batch=16 device=0训练yolov8m-pose关键点检测模型
# yolov8m-pose模型,迁移学习微调
!yolo pose train data=Triangle_215.yaml model=yolov8m-pose.pt pretrained=True project=Triangle_215 name=m_pretrain epochs=50 batch=16 device=0# yolov8m-pose模型,随机初始权重,从头重新学习
!yolo pose train data=Triangle_215.yaml model=yolov8m-pose.pt project=Triangle_215 name=m_scratch epochs=50 batch=16 device=0# 训练yolov8l-pose关键点检测模型
# yolov8l-pose模型,迁移学习微调
!yolo pose train data=Triangle_215.yaml model=yolov8l-pose.pt pretrained=True project=Triangle_215 name=l_pretrain epochs=50 batch=4 device=0# yolov8l-pose模型,随机初始权重,从头重新学习
!yolo pose train data=Triangle_215.yaml model=yolov8l-pose.pt project=Triangle_215 name=l_scratch epochs=50 batch=4 device=0# 训练yolov8x-pose关键点检测模型
# yolov8x-pose模型,迁移学习微调
!yolo pose train data=Triangle_215.yaml model=yolov8x-pose.pt pretrained=True project=Triangle_215 name=x_pretrain epochs=50 batch=4 device=0# yolov8x-pose模型,随机初始权重,从头重新学习
!yolo pose train data=Triangle_215.yaml model=yolov8x-pose.pt project=Triangle_215 name=x_scratch epochs=50 batch=4 device=0# 训练yolov8x-pose-p6关键点检测模型
# yolov8x-pose-p6模型,迁移学习微调
!yolo pose train data=Triangle_215.yaml model=yolov8x-pose-p6.pt pretrained=True imgsz=1280 project=Triangle_215 name=x_p6_pretrain epochs=50 batch=2 device=0# yolov8x-pose-p6模型,随机初始权重,从头重新学习
!yolo pose train data=Triangle_215.yaml model=yolov8x-pose-p6.pt imgsz=1280 project=Triangle_215 name=x_p6_scratch epochs=50 batch=2 device=0
训练日志和评估指标可视化
训练得到的模型权重文件
最优模型:Project_Name/Name/weights/best.pt最终模型:Project_Name/Name/weights/last.pt数据集标注统计
目标检测框的中心点位置分布、宽高分布:labels.jpg目标检测框的中心点X、中心点Y、宽、高相关分布:labels_correlogram.jpg训练集:某一个batch的标注可视化
train_batch0.jpgtrain_batch1.jpgtrain_batch2.jpg测试集:某一个batch的标注、预测结果可视化
标注:val_batch0_labels.jpg预测结果:val_batch0_pred.jpg标注:val_batch1_labels.jpg预测结果:val_batch1_pred.jpg目标检测评估指标
不同置信度的Precision:BoxP_curve.png不同置信度的Recall:BoxR_curve.png不同置信度的PR曲线:BoxPR_curve.png不同置信度的F1:BoxF1_curve.png目标检测框混淆矩阵:confusion_matrix.png关键点检测评估指标
不同置信度的Precision:PoseP_curve.png不同置信度的Recall:PoseR_curve.png不同置信度的PR曲线:PosePR_curve.png不同置信度的F1:PoseF1_curve.png
3、ONNX Runtime部署
# 安装CPU版本的ONNX Runtime(二选一运行)# CPU
!pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple#安装GPU版本的ONNX Runtime(二选一运行)
# # GPU
# !pip install onnxruntime-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
# 验证安装配置成功
import onnxruntime
onnxruntime.get_device()
ONNX Runtime推理预测-单张图像
import cv2
import numpy as np
from PIL import Imageimport onnxruntime
import torch
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')import matplotlib.pyplot as pltkpts_shape = [3, 3] # 关键点 shapeort_session = onnxruntime.InferenceSession('checkpoint/Triangle_215_yolov8l_pretrain.onnx', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])import torch
x = torch.randn(1, 3, 640, 640).numpy()
x.shape
(1, 3, 640, 640)
ort_inputs = {'images': x}
ort_output = ort_session.run(['output0'], ort_inputs)[0]# 获得ONNX模型输入层和数据维度
model_input = ort_session.get_inputs()
input_name = [model_input[0].name]
input_name
['images']
input_shape = model_input[0].shape
input_shape
[1, 3, 640, 640]
input_height, input_width = input_shape[2:]# 获得ONNX模型输出层和数据维度
model_output = ort_session.get_outputs()
output_name = [model_output[0].name]
output_name
['output0']
output_shape = model_output[0].shape
output_shape# 载入图像
img_path = 'images/Triangle_4.jpg'
# 导入 BGR 格式的图像
img_bgr = cv2.imread(img_path)
# 获取原图尺寸
img_bgr.shape
(3712, 5568, 3)
## BGR 转 RGB
# img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
# plt.imshow(img_rgb)
# plt.show()
预处理-缩放图像尺寸
# 预处理-缩放图像尺寸
img_bgr_640 = cv2.resize(img_bgr, [input_height, input_width])
img_bgr_640.shape
(640, 640, 3)
img_rgb_640 = img_bgr_640[:,:,::-1]
plt.imshow(img_rgb_640)
plt.show()# X 方向 图像缩放比例
x_ratio = img_bgr.shape[1] / input_width
x_ratio
8.7
# Y 方向 图像缩放比例
y_ratio = img_bgr.shape[0] / input_height
y_ratio
5.8
预处理-构造输入张量
# 预处理-归一化
input_tensor = img_rgb_640 / 255# 预处理-构造输入 Tensor
input_tensor = np.expand_dims(input_tensor, axis=0) # 加 batch 维度
input_tensor = input_tensor.transpose((0, 3, 1, 2)) # N, C, H, W
input_tensor = np.ascontiguousarray(input_tensor) # 将内存不连续存储的数组,转换为内存连续存储的数组,使得内存访问速度更快
input_tensor = torch.from_numpy(input_tensor).to(device).float() # 转 Pytorch Tensor
# input_tensor = input_tensor.half() # 是否开启半精度,即 uint8 转 fp16,默认转 fp32
input_tensor.shape
torch.Size([1, 3, 640, 640])
执行推理预测
# ONNX Runtime 推理预测
ort_output = ort_session.run(output_name, {input_name[0]: input_tensor.numpy()})[0]# 转 Tensor
preds = torch.Tensor(ort_output)
preds.shape后处理-置信度过滤、NMS过滤
from ultralytics.yolo.utils import ops
preds = ops.non_max_suppression(preds, conf_thres=0.25, iou_thres=0.7, nc=1)
pred = preds[0]
pred.shape解析目标检测预测结果
pred_det = pred[:, :6].cpu().numpy()
# 目标检测预测结果:左上角X、左上角Y、右下角X、右下角Y、置信度、类别ID
pred_detnum_bbox = len(pred_det)
print('预测出 {} 个框'.format(num_bbox))# 类别
bboxes_cls = pred_det[:, 5]
bboxes_cls# 置信度
bboxes_conf = pred_det[:, 4]
bboxes_conf
pred_det
# 目标检测框 XYXY 坐标
# 还原为缩放之前原图上的坐标
pred_det[:, 0] = pred_det[:, 0] * x_ratio
pred_det[:, 1] = pred_det[:, 1] * y_ratio
pred_det[:, 2] = pred_det[:, 2] * x_ratio
pred_det[:, 3] = pred_det[:, 3] * y_ratio
bboxes_xyxy = pred_det[:, :4].astype('uint32')解析关键点检测预测结果
pred_kpts = pred[:, 6:].view(len(pred), kpts_shape[0], kpts_shape[1])
pred_kpts.shape
bboxes_keypoints = pred_kpts.cpu().numpy()
bboxes_keypoints# 还原为缩放之前原图上的坐标
bboxes_keypoints[:,:,0] = bboxes_keypoints[:,:,0] * x_ratio
bboxes_keypoints[:,:,1] = bboxes_keypoints[:,:,1] * y_ratio
bboxes_keypoints = bboxes_keypoints.astype('uint32')# OpenCV可视化关键点





](https://img-blog.csdnimg.cn/direct/50f12046d42b4bb6b78540658bf380c8.png)