论文:Query2doc: Query Expansion with Large Language Models
⭐⭐⭐⭐⭐
Microsoft Research, EMNLP 2023
文章目录
- 背景介绍
- Query2doc 论文速读
- 实现细节
- 实验结果和分析
- 总结分析
背景介绍
信息检索(Information Retrieval,IR)指的是,给定一个 user query,从一个 large corpus 中定位出相关的文档。
目前信息检索有两个主流的范式:
- Lexical-based sparse retrieval(基于词汇的稀疏检索):是一类经典的 IR 方法,它依赖于文本的词汇内容和它们的统计特性。这种方法的核心是将文档和查询表示为词汇的集合,然后通过计算这些集合之间的相似度来检索文档。其中最著名的稀疏检索模型是 BM25,它使用词频(term frequency, TF)和逆文档频率(inverse document frequency, IDF)来评估查询词与文档的匹配程度。这类方法简单高效且计算效率搞,但检索效果很大程度上依赖于 query 与 doc 中词汇的匹配程度。
- Embedding-based dense retrieval(基于 embedding 的稠密检索):是一种较为现代的信息检索方法。这种方法将文本转为 embedding 向量,这种 embedding 能够捕捉到词汇和短语的语义信息,并通过计算向量之间的距离(如余弦相似度)来检索相关文档。这类方法能够捕捉到词汇之间的语义关系,但更需要更多的计算资源。
尽管经典的 BM25 在很多场景下表现不如基于 embedding 的方法,但 BM25 在跨领域的场景下表现还是很不错的。
Query Expansion 是 IR 领域中的一项关键技术,旨在改善查询与文档之间的匹配度,从而提高检索系统的准确性和相关性。Query Expansion 的基本思想是,通过某些方法对用户原始查询进行扩展,添加额外的词汇或短语,以更好地捕捉用户的检索意图。Query Expansion 的挑战在于选择与用户意图高度相关的词汇,同时避免引入噪声或不相关的信息。有效的 Query Expansion 可以显著提高检索系统的性能,尤其是在处理短查询或模糊查询时。然而,不恰当的扩展可能会降低检索质量,因此 Query Expansion 策略的选择和优化是 IR 中的一个活跃研究方向。
Query2doc 论文速读
论文采用的思路很简单,但效果却很不错。
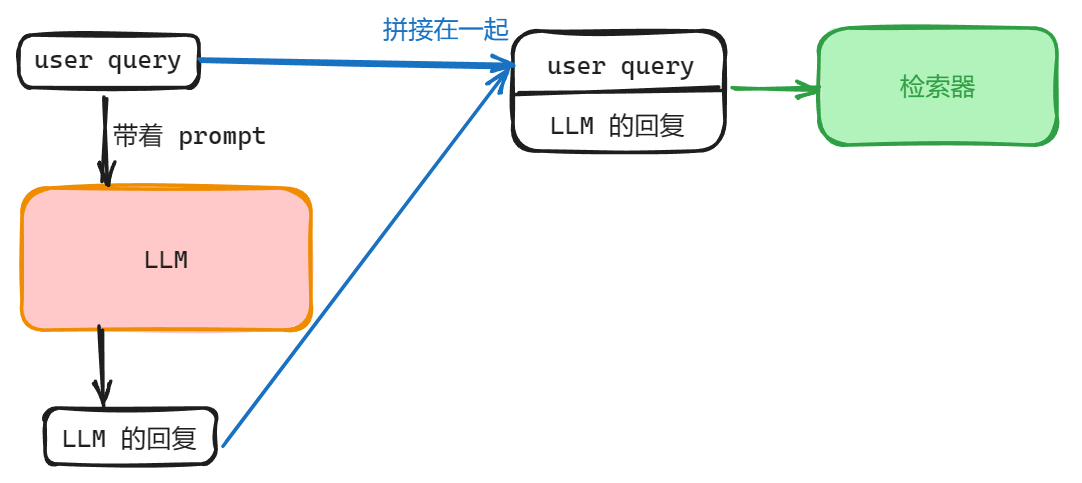
思路:先把 user query 带上 prompt 问一下 LLM,让 LLM 先生成一个关于这个问题的回复,这里称这个回复为伪文档,然后把伪文档和 user query 拼接在一起,实现了 Query Expansion,将扩展后的 query 再送给 Retriever 实现检索。
这里的 Retriever 可以是之前的任何检索器,可以是 sparse retrieval,也可以是 dense retrieval。
实现细节
下图是一个根据 user query 让 LLM 生成一个伪文档的示例:

其实就是先给一个指令 “Write a passage that answers the given query:”,然后再给他 k 个 few-shot 的 exemplars,从而让他根据 query 生成伪文档回复。
论文选用的 exemplars 的数量 k = 4
现在,我们有了原始 query q q q、LLM 生成的伪文档 d ′ d' d′,现在我们需要把它们拼接成扩展后的 query q + q^+ q+,这里的拼接有点小技巧,对于 sparse retrieval 和 dense retrieval 有着不同的拼接方法:
- 对于 sparse retrieval:由于 q q q 往往比伪文档更加简短,为了平衡两者的权重,这里故意将 q q q 重复几次之后再与 d ′ d' d′ 进行拼接:
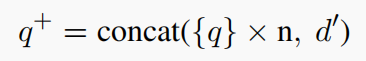
- 对于 dense retrieval:这时 query 和 document 都被表示为 embedding vector,这种情况下,不需要通过重复查询词汇来增加其权重,因为检索系统已经能够通过向量表示来捕捉查询和文档之间的语义关系。所以在这里,就直接将两者中间加一个
SEP直接拼接在一起就好了:
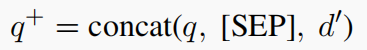
对于 dense retrieval 的场景,最大的困难并不在拼接,而在于训练,由于输入 query 和文档仍旧不是一个分布(两者语义并不相同甚至完全不相同,只是匹配),我们仍然需要针对特定的数据集或检索任务进行训练或微调模型。本论文工作对密集检索模型进行了训练,并展示了如何将新的查询扩展技术与这些模型结合,以提高信息检索系统的整体性能。具体的训练细节可以参考原论文。
实验结果和分析
实验结果数据如下,可以从中看到,使用了 query2doc 的 Query Expansion 技术后,效果都有了不错的提升。
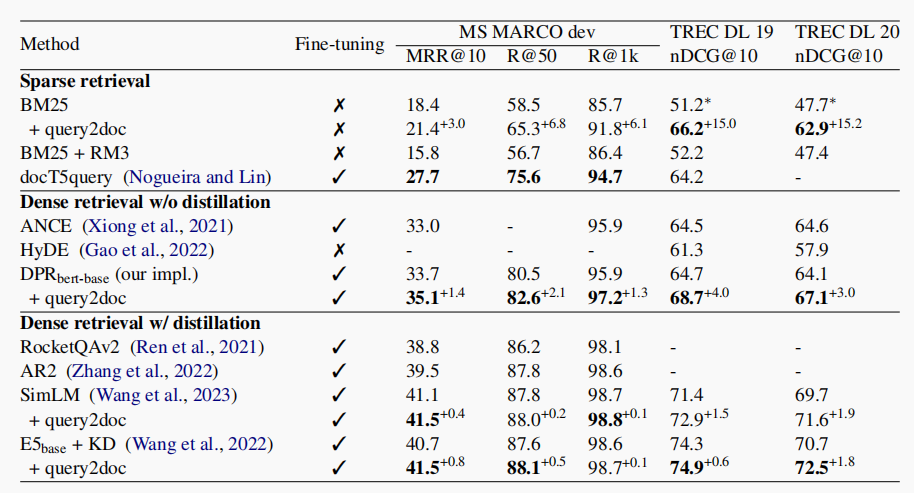
除此之外,作者还做出了以下分析:
- 模型大小的提升对最终的召回效果是有收益的,随着模型变大,生成的文本对预测效果有提升。
- 该方案本身对向量表征模型的训练,也是有明显收益的。
- 对字面检索而言,原始 query 和大模型生成的回复之间,是互补关系,两者组合才能真正达到提升。
作者还使用案例来分析了该方案生效的可能原因:大模型直接生成一个答案,很大程度拉近了检索词和文档之间在语义空间上的相似,因为本质上两者都是回复问题。
但是,由于 LLM 存在幻觉问题,其生成的答案可能并不准确,如果 LLM 生成的关键信息出现错误的话,那么这个错误很可能会导致最终检索结果的错误。
总之,该方案简单易行,有好处也有坏处,还是需要根据具体的场景来使用。
总结分析
这里参考 微软新文query2doc:用大模型做query检索拓展 的总结
Query2doc 的思路很简单,但其背后做的实验和分析很有价值,在现实应用中也很有意义,所以单独把这篇文章进行了分享。然而在现实中,仍旧有很多细节问题还需要进一步考虑,我还没完全想好,不过应该是逃不开的:
- 现实场景下的召回相似度应该如何计算,尤其是向量相似度,这里需要很多的数据支撑。
- 召回后的下一步,仍旧依赖相对完善的精排模块,也需要考虑类似的匹配机制,否则即使召回层有了召回,排序层面也会被排到后面去。
- 大模型本身的幻觉问题,会对召回带来很大的影响,该问题对召回还是有影响的,需要考虑如何尽可能剔除或者缓解。
- 性能问题,依赖大模型是能够有所提升,但是多一次的大模型的请求,无疑让整体耗时有了很大的影响。(这点在论文中也有提及)







![国标GB28181协议EasyGBS视频监控平台设备报错“callid[924517228] cseq”,是什么原因?](https://img-blog.csdnimg.cn/direct/e9fac59033a54cbab1dda1da1b9424fd.jpeg)