论文:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
链接:https://arxiv.org/abs/2010.11929
很多人博主都写烂了的论文,我到现在才真正翻开论文看,21年的工作,正好是刚毕业那年,恶补起来~
摘要
- 出发点:因为Transformer计算效率和可扩展性,逐渐在自然语言任务上成为主流,但在视觉领域的应用有限。基本都是与卷积结合使用或者替换卷积网络中的某些组件,并没有从整体上改变网络架构。
- 方案:Pre-train and transfer
- 实现很简单,按照原文精简表达出来就是:
we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. - why pre-train:在ImageNet等中等大小的数据集上,效果不如同等大小的ResNet。文中给出解释是 - Transformer缺少CNN固有的inductive biases(such as translation equivariance and locality),在数据不足时泛化性较差。所以模型在14M-300M图像数据集上做了预训练。
- why patchs:一个直观的使用自注意力机制在图像上的方法是,每个像素点之间做attention,但是这样计算复杂度是像素数的二次方,并不能用于真实的输入大小上。
- 实现很简单,按照原文精简表达出来就是:
- 结果:证明了在视觉领域CNN并不是必要的,直接将图像patch序列输入tranformer也可以取得良好的效果,并且在训练阶段可以减少计算资源的消耗。
方法
直接上图,问题点在于如何将图片patch转换为embedding。
- 模型输入
图像大小H*W*C,H和W分别代表宽和高,C代表通道数。将其flatten为2维N*(P*P*C),N为切割出的patch数量,每个patch的大小为P*P,patch的数量为N=HW / P^2(即tranformer输入长度)。对于二维patch处理,则是直接flatten并映射到输入向量维度-patch embeddings(原文flatten the patches and map to D dimensions with a trainable linear projection)。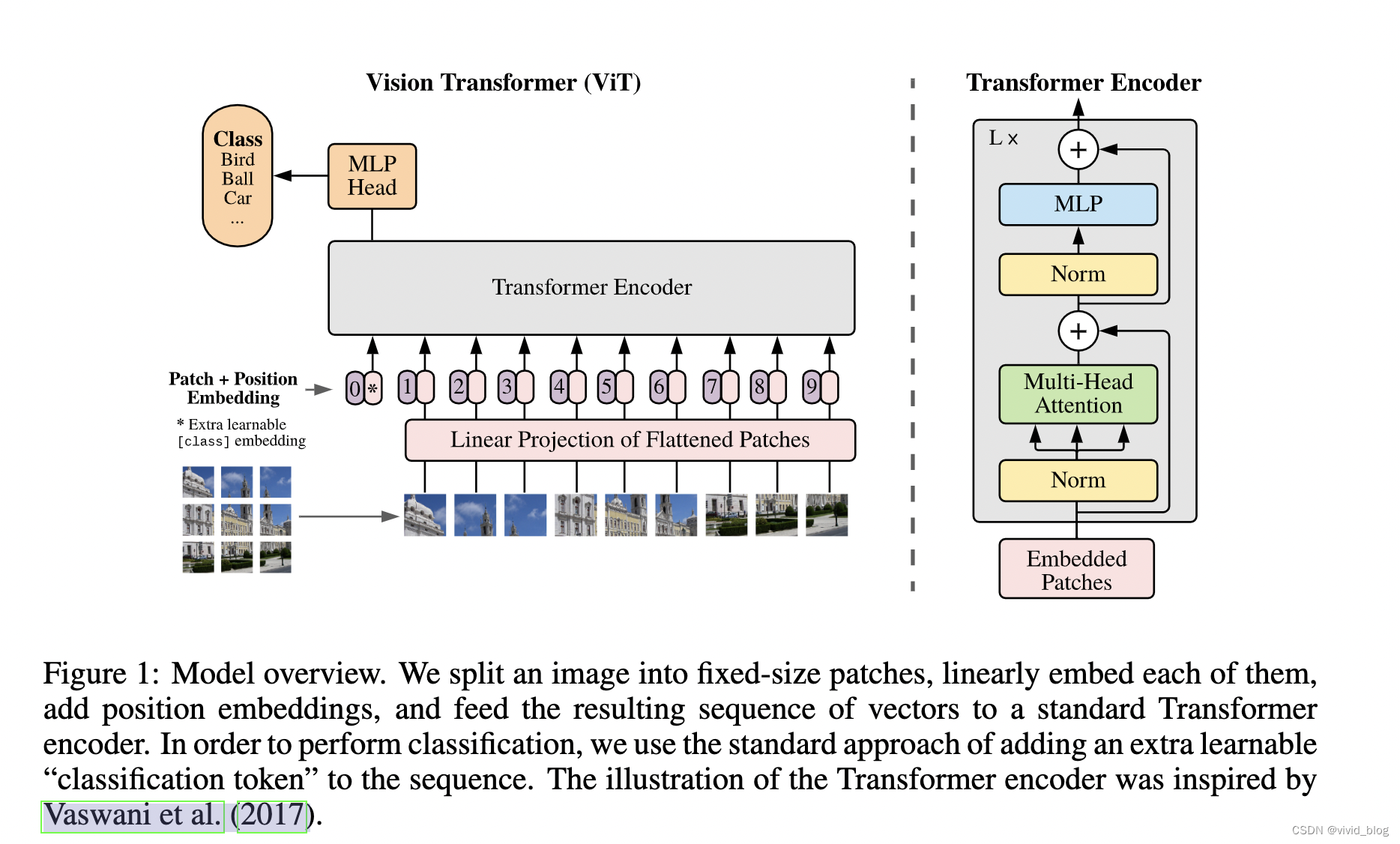
在输入端,还需要拼接一个[CLS](为了和BERT中的说法对齐,其实本质就是一个可学习的向量),在对应位置的输出端,过一个一层的MLP,得到整个图片表示。
除此之外,还有一个位置编码信息。文中介绍只用了standard learnable 1D position embeddings, 在2D-aware position embeddings未见到收益 - 模型结构
在结构上就是transformer的堆叠(MSA+MLP),文中给出的细节是,每个模块前都会使用Layernorm (LN),并且每个模块都会使用残差连接。公式感觉更清楚一些:
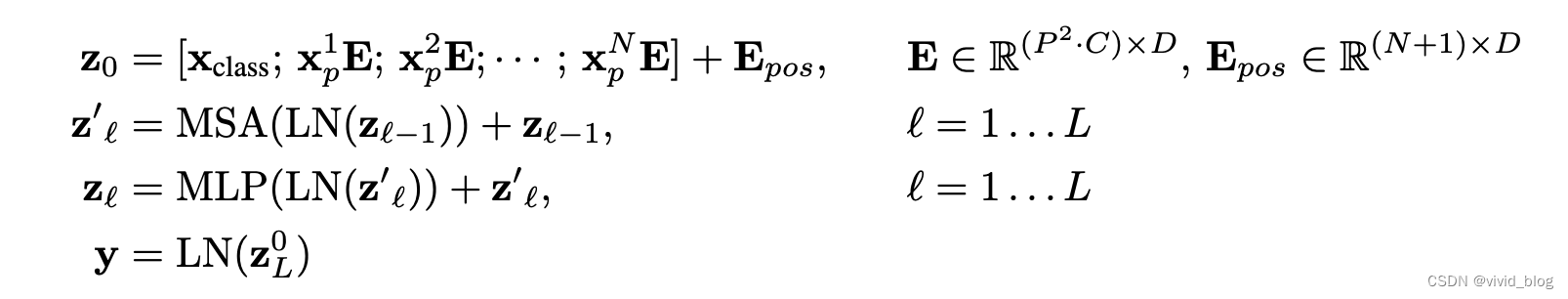
- 分析
Transformer与原始CNN相比缺少归纳偏置的特点(Inductive bias),这是一种先验知识,即提前做好的假设。CNN结构共包括两种归纳偏置,一种是局部性,一种是平移不变性;前者指的是图片上相邻的区域具有相似的特征;先卷积再平移和先平移再卷积结果一致。因此CNN具备很多先验信息,只需要相对少的数据就可以学习一个比较好的模型。
实验
先介绍一些我比较关心的实验结果
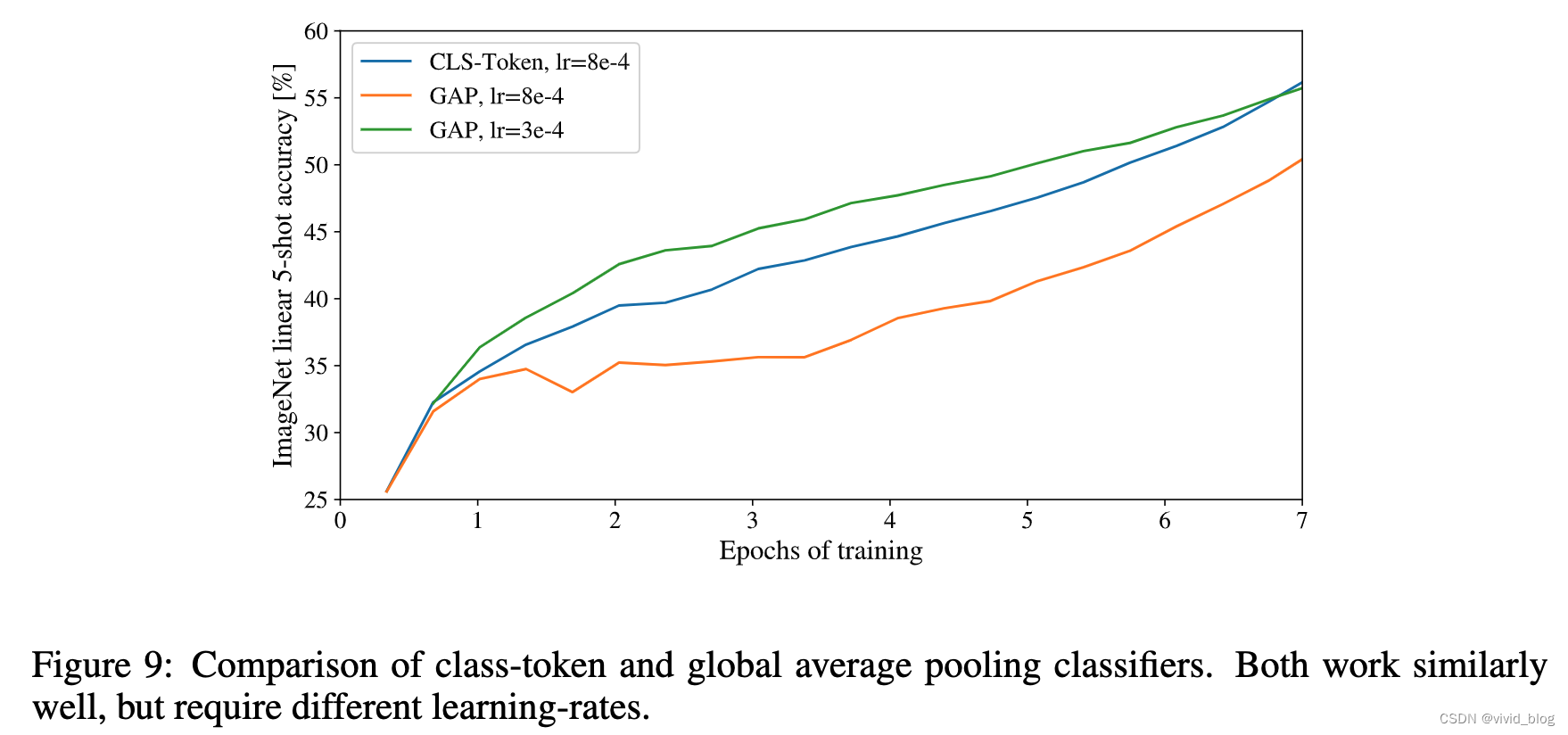
- 为什么增加CLS,而不直接使用average pooling,文中有对应实验结果,两者实际差别不大。
- Position embedding对比,位置编码将sum到输入embedding上,假设3x3共9个patch:
- 一维编码:patch编码为1到9
- 二维编码:patch编码为11,12,13,21,22,23,31,32,33,即同时考虑X轴与Y轴的信息,对X和Y Embedding进行concat
- 相对位置编码:为了编码patch之间的空间信息,考虑加入其相对位置距离,对于任意patch之间计算其1维上的相对位置,每个offset作为一个embedding,然后需要一个额外的attention,原有query作为query,相对位置的embedding作为key,然后将attention结果作为bias加入main attention中。
由实验结果可以看到,出了不加位置编码有比较大的性能损失外,其他位置编码方式差距不大,作者认为这是因为输入是基于patch而非像素,对于编码空间信息不是很重要,并且给予patch的方式使空间关系变得简单。

- 各种size的ViT模型
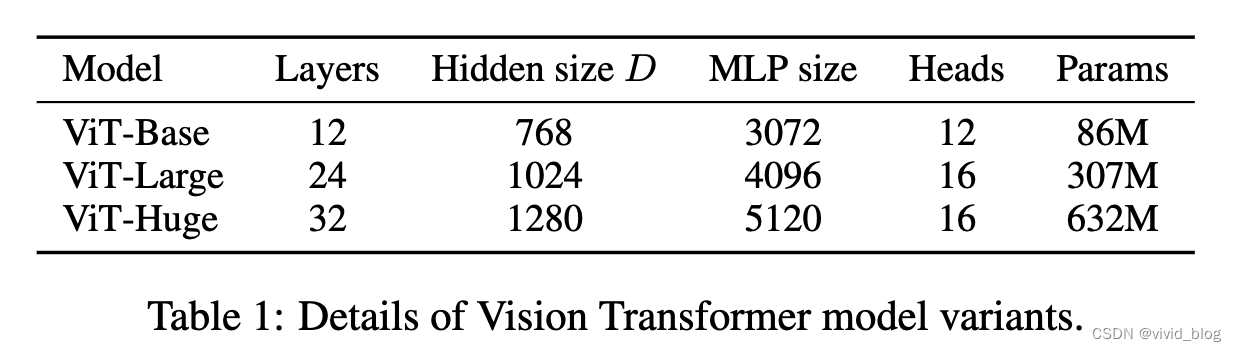
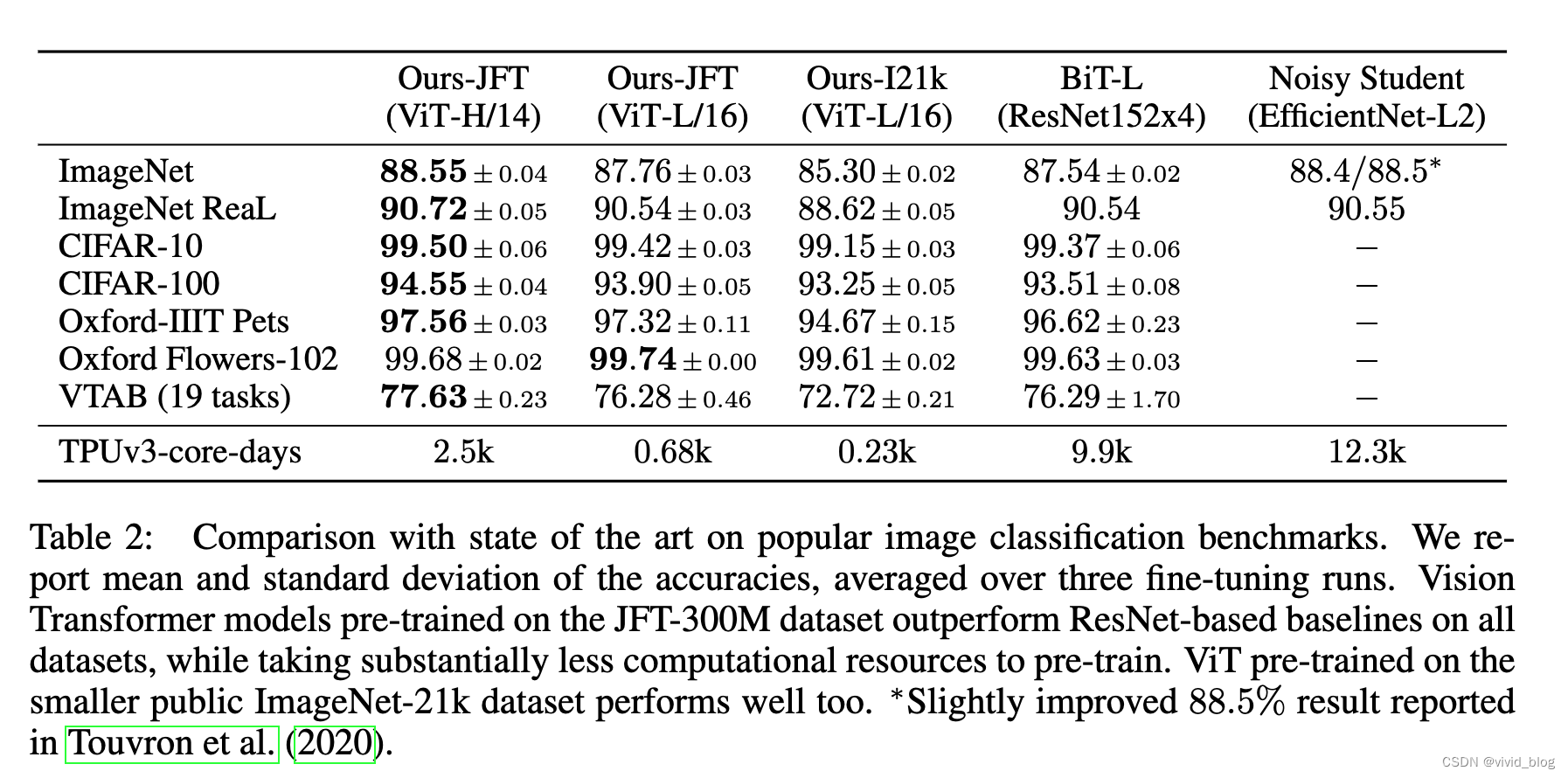
- 主要实验,可以看到在小数据集预训练结果不如resnet
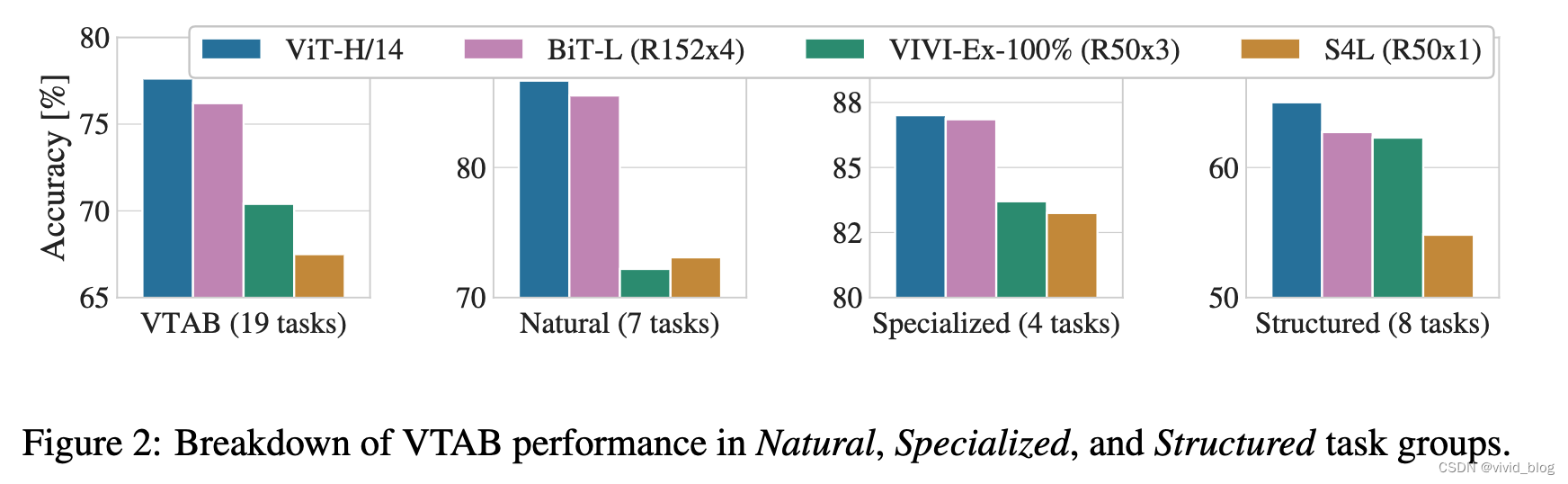
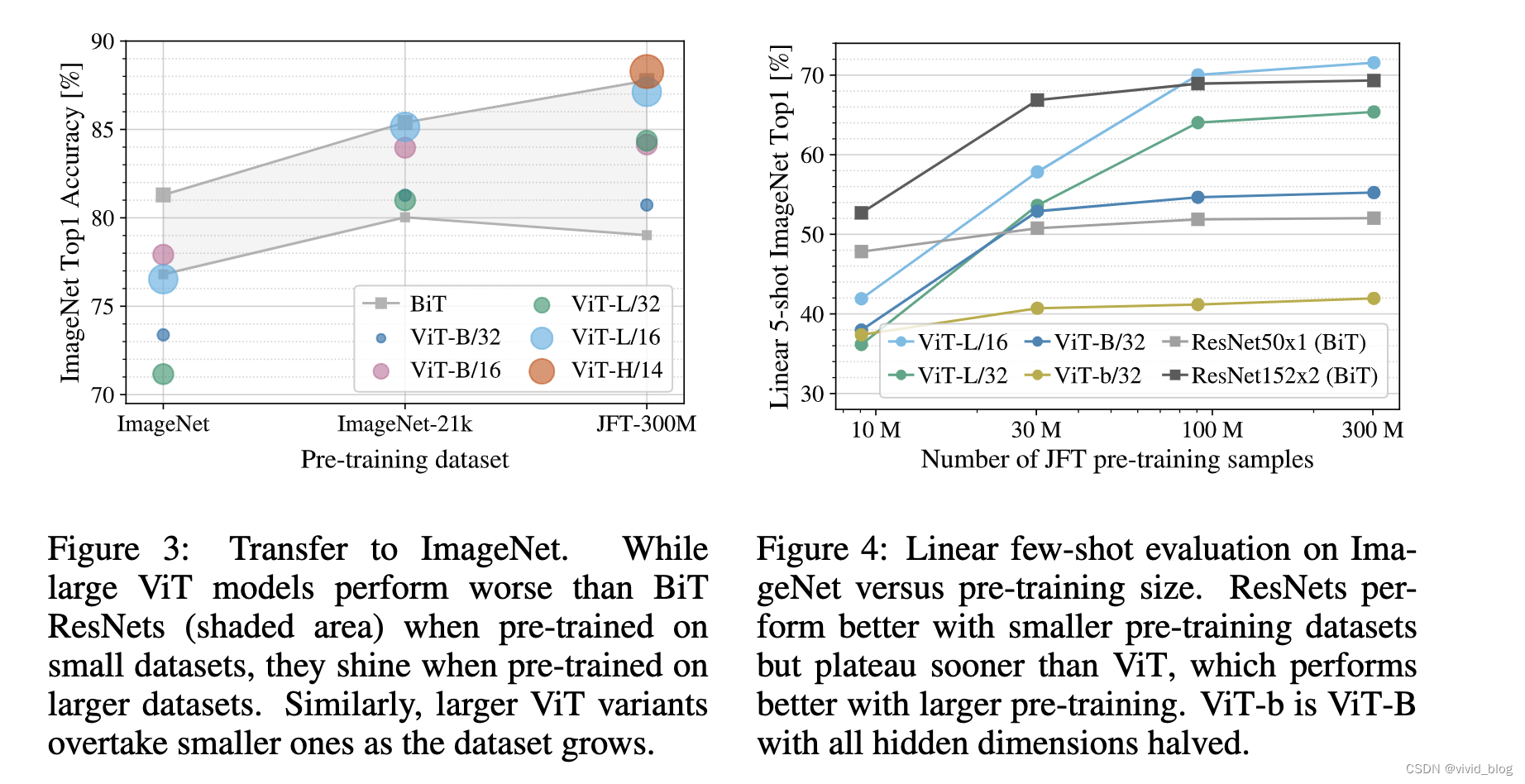
5. 不同大小的预训练数据集效果对比,卷积的归纳偏差对于较小的数据集很有用,但对于较大的数据集,直接从数据中学习相关模式就足够了。
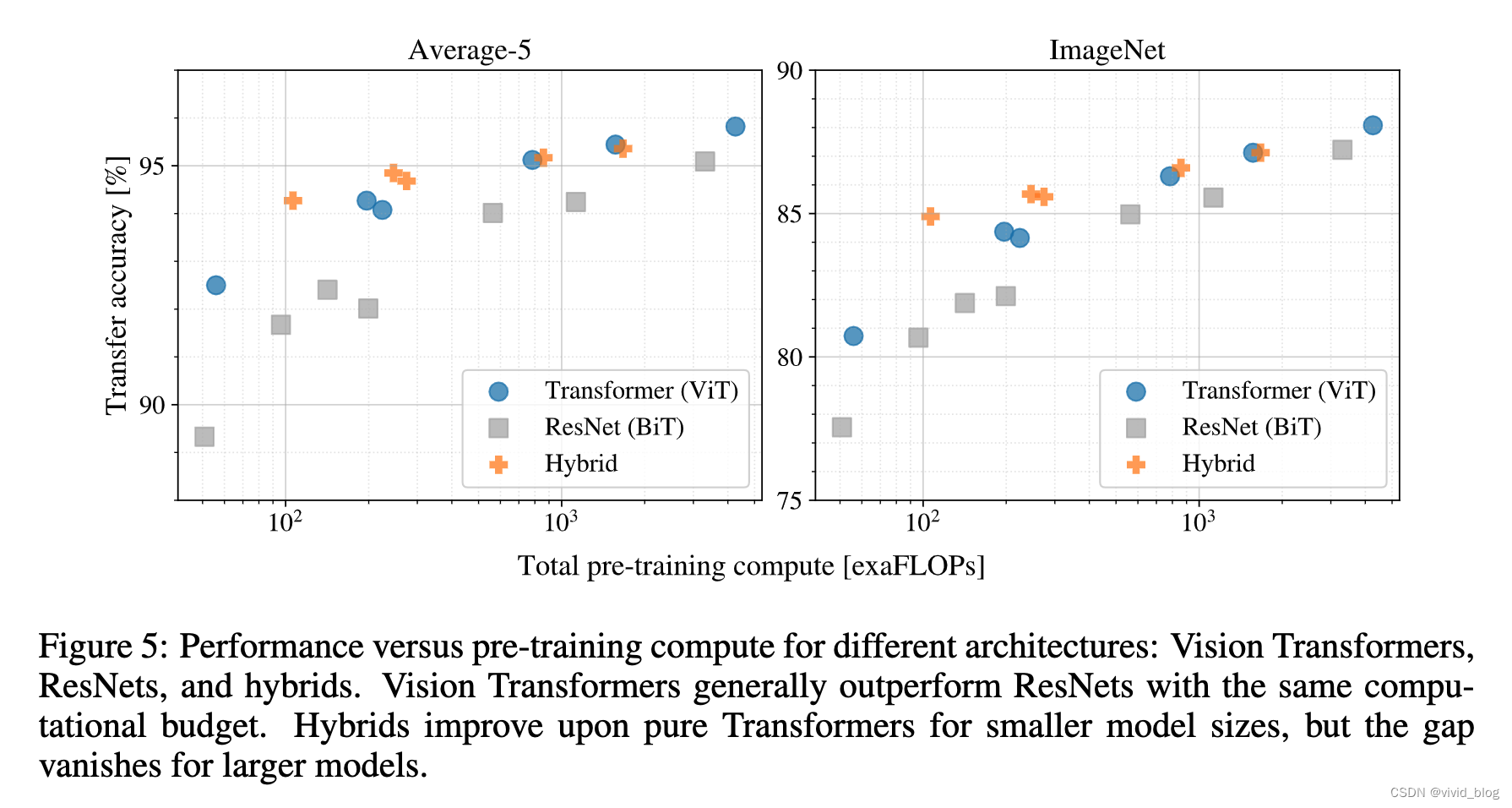
6. scaling study:ViT uses approximately 2 − 4× less compute to attain the same performance,CNN+Transformer即Hybrid的方法在模型较小时有效果,但是随着模型增大效果消失。
7. 一些可视化结果