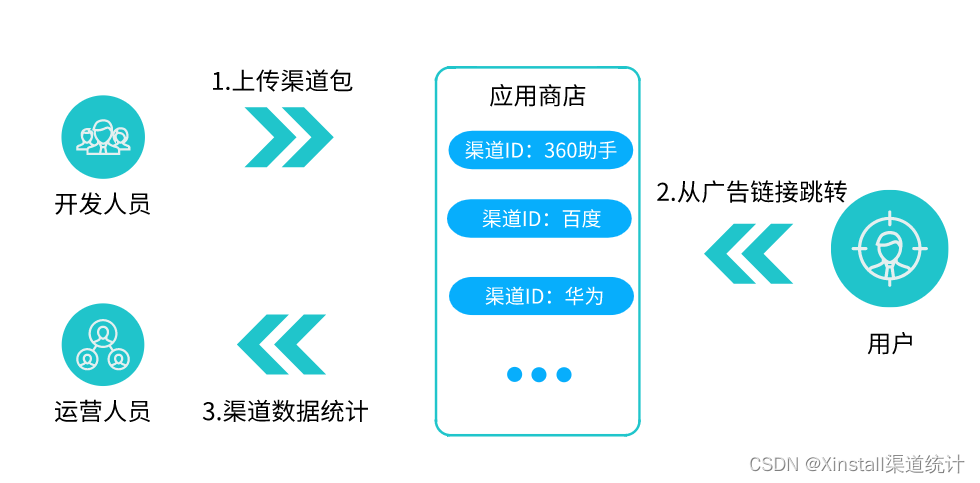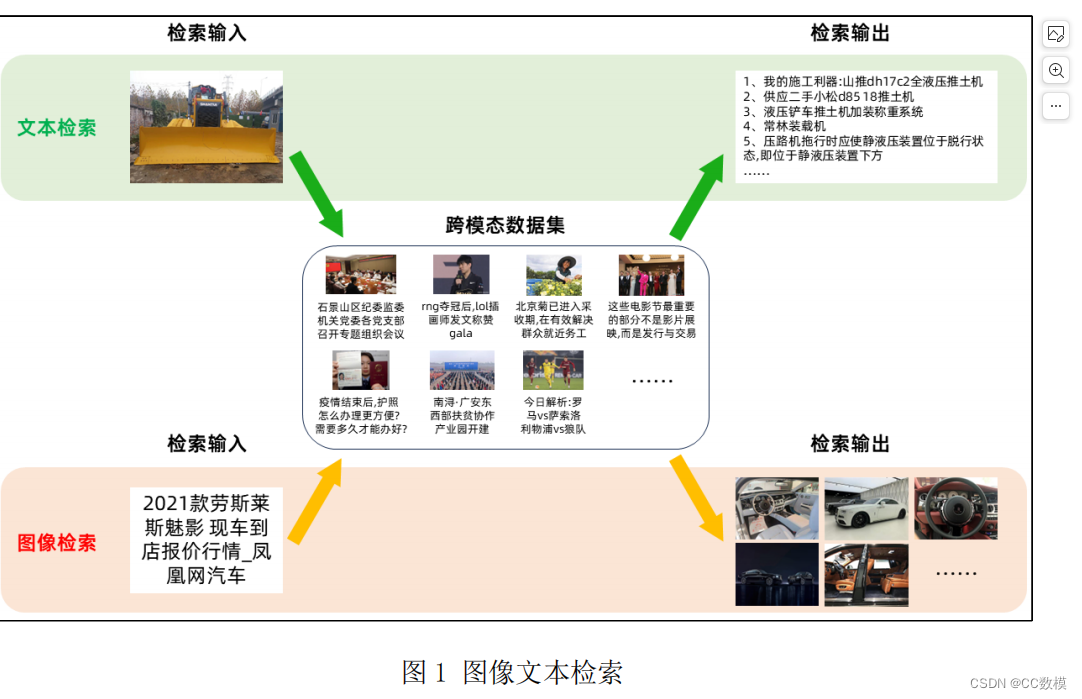
(1)基于图像检索的模型和算法,利用附件 2 中“word_test.csv”文件的文本信息, 对附件 2 的 ImageData 文件夹的图像进行图像检索,并罗列检索相似度较高的前五张图像,将结果存放在“result1.csv”文件中(模板文件详见附件4的result1.csv)。其中,ImageData文件夹中的图像 ID 详见附件 2 的“image_data.csv”文件。(完整附件见文末)
建立的“多模态特征融合的图像文本检索”模型。
1.数据加载与预处理:
通过读取CSV文件,加载图像数据集和对应的文本描述。
设置图像文件夹的路径,用于加载图像文件。
2.特征提取:
使用预训练的VGG16模型提取图像特征。VGG16是一个常用的深度学习模型,在ImageNet数据集上进行了训练,可提取图像的高级语义特征。
利用预训练的Word2Vec模型提取文本特征。Word2Vec是一个常用的词向量模型,可以将文本转换为密集向量表示,捕捉词语之间的语义关系。
3.特征融合:
将提取的图像特征和文本特征拼接在一起,形成多模态特征表示。
在这个示例中,使用了简单的拼接方式,将图像特征和文本特征直接连接在一起作为模型的输入。
4.模型训练与测试:
将数据集划分为训练集和测试集,使用划分后的数据训练多模态特征融合模型。
在这个示例中,使用了支持向量机(SVM)作为分类器,并在训练过程中加入了PCA降维处理以减少特征维度。



图像特征提取:
使用预训练的深度学习模型(如VGG、ResNet、Inception等)来提取图像的特征。这些模型在大规模图像数据集上进行了训练,并能够捕获图像的高级语义信息。
从每个图像中提取出的特征应该是一个固定长度的向量,表示图像的语义信息。
文本特征提取:
对文本数据进行处理,可以使用词嵌入模型(如Word2Vec、GloVe、BERT等)来将文本转换为向量表示。
对于每个文本,可以通过将词向量进行平均或加权平均来得到整个文本的向量表示。
特征融合:
将图像特征和文本特征进行融合,形成多模态特征表示。融合可以采用简单的拼接、加权平均等方式。
融合后的特征向量将包含图像和文本的语义信息,有助于更好地表示多模态数据。
相似度计算:
使用合适的相似度计算方法(如余弦相似度、欧氏距离等),计算图像与文本之间的相似度。相似度计算时应该基于融合后的特征向量。
相似度的计算可以使用最近邻算法(如k近邻)、基于距离的方法等。
(2)基于文本检索的模型和算法,利用附件 3 中“image_test.csv”文件提及的图像ID,对附件 3 的“word_data.csv”文件进行文本检索,并罗列检索相似度较高的前五条文本,将结果存放在“result2.csv”文件中(模板文件见附件 4 的 result2.csv)。其中,“image_test.csv”文件提及的图像 id,对应的图像数据可在附件 3 的 ImageData 文件夹中获取(完整附件见文末)
1.文本特征提取:
对附件3中的文本数据进行特征提取。可以使用预训练的词向量模型(如Word2Vec、GloVe等)将文本转换为向量表示,也可以使用文本嵌入技术(如BERT、ELMo等)获取文本的高级语义特征。
2.图像特征提取:
从附件3的ImageData文件夹中加载与图像ID对应的图像数据。然后,使用图像处理技术(如深度学习模型)提取图像的特征表示。
3.特征融合:
将文本特征和图像特征进行融合,形成多模态特征表示。可以简单地将两者连接在一起,也可以通过某些模型(如多层感知器、注意力机制等)进行融合。
4.相似度计算:
使用合适的相似度计算方法(如余弦相似度、欧氏距离等)来衡量图像与文本之间的相似度。较高的相似度表明图像与文本之间的语义关联性更强。
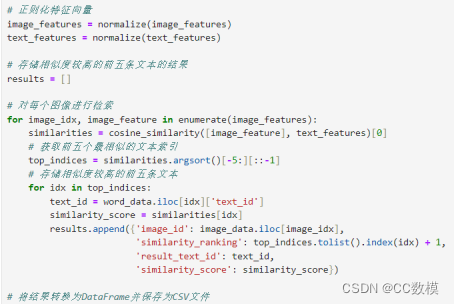
5.结果展示:
将相似度较高的前五条文本列出,并将结果存储在指定的CSV文件中,以便后续提交。每个图像ID都会有与之相关的文本ID列表。
附件: