1932. 合并多棵二叉搜索树
困难
相关标签
相关企业
提示
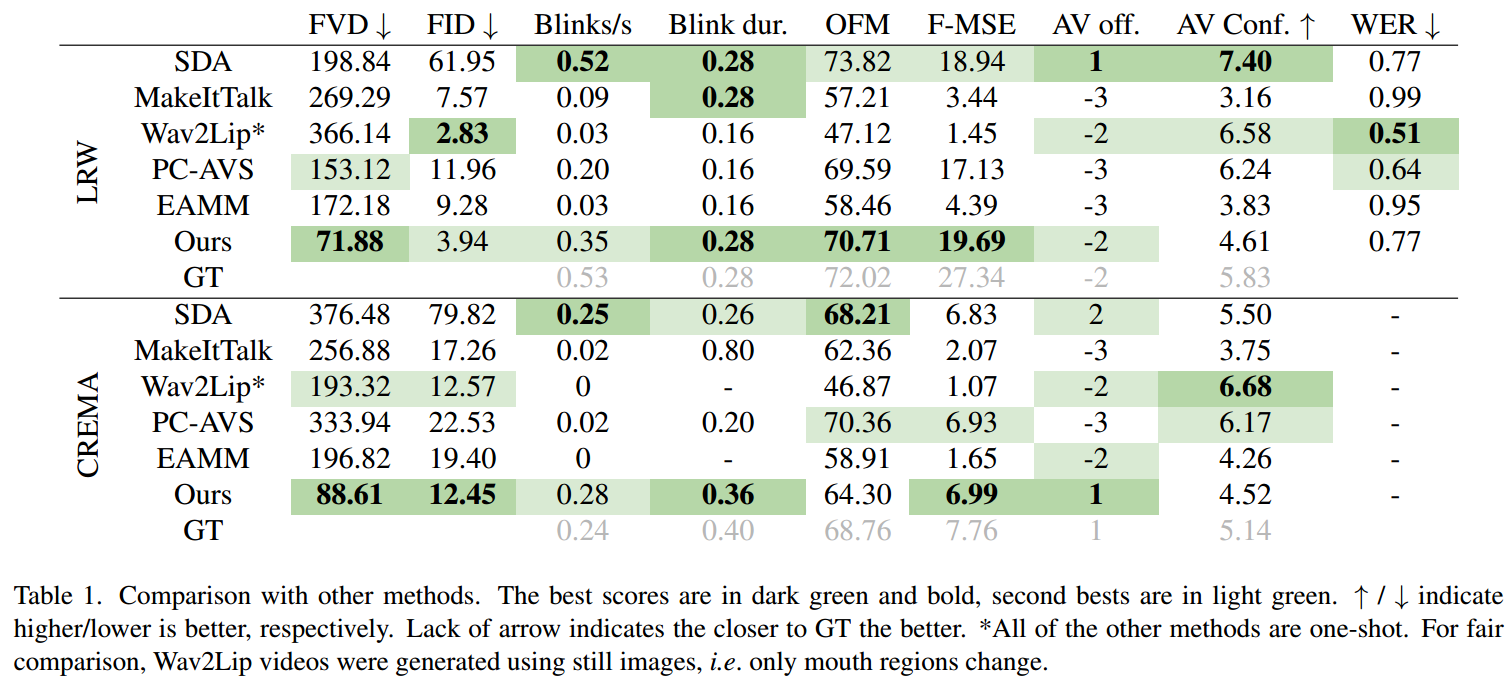
给你 n 个 二叉搜索树的根节点 ,存储在数组 trees 中(下标从 0 开始),对应 n 棵不同的二叉搜索树。trees 中的每棵二叉搜索树 最多有 3 个节点 ,且不存在值相同的两个根节点。在一步操作中,将会完成下述步骤:
- 选择两个 不同的 下标
i和j,要求满足在trees[i]中的某个 叶节点 的值等于trees[j]的 根节点的值 。 - 用
trees[j]替换trees[i]中的那个叶节点。 - 从
trees中移除trees[j]。
如果在执行 n - 1 次操作后,能形成一棵有效的二叉搜索树,则返回结果二叉树的 根节点 ;如果无法构造一棵有效的二叉搜索树,返回 null 。
二叉搜索树是一种二叉树,且树中每个节点均满足下述属性:
- 任意节点的左子树中的值都 严格小于 此节点的值。
- 任意节点的右子树中的值都 严格大于 此节点的值。
叶节点是不含子节点的节点。
示例 1:
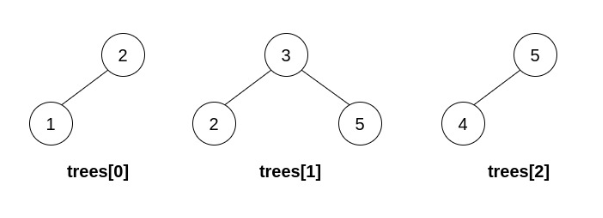
输入:trees = [[2,1],[3,2,5],[5,4]] 输出:[3,2,5,1,null,4] 解释: 第一步操作中,选出 i=1 和 j=0 ,并将 trees[0] 合并到 trees[1] 中。 删除 trees[0] ,trees = [[3,2,5,1],[5,4]] 。
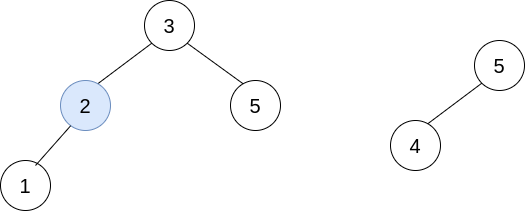
在第二步操作中,选出 i=0 和 j=1 ,将 trees[1] 合并到 trees[0] 中。 删除 trees[1] ,trees = [[3,2,5,1,null,4]] 。
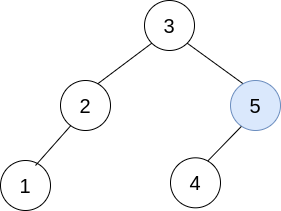
结果树如上图所示,为一棵有效的二叉搜索树,所以返回该树的根节点。
示例 2:
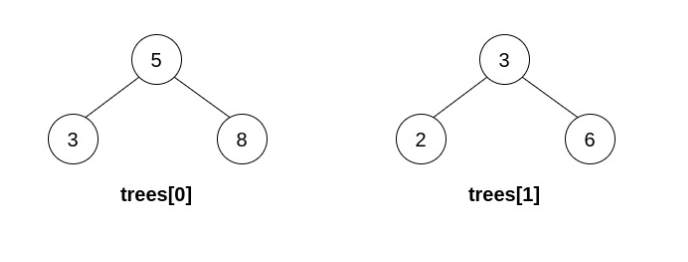
输入:trees = [[5,3,8],[3,2,6]] 输出:[] 解释: 选出 i=0 和 j=1 ,然后将 trees[1] 合并到 trees[0] 中。 删除 trees[1] ,trees = [[5,3,8,2,6]] 。
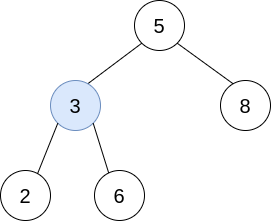
结果树如上图所示。仅能执行一次有效的操作,但结果树不是一棵有效的二叉搜索树,所以返回 null 。
示例 3:
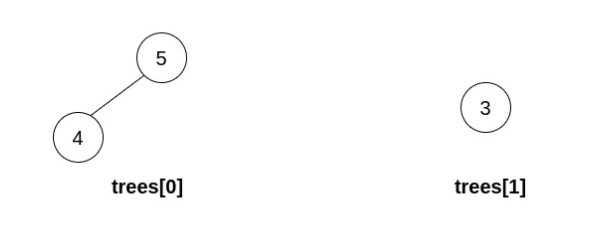
输入:trees = [[5,4],[3]] 输出:[] 解释:无法执行任何操作。
提示:
n == trees.length1 <= n <= 5 * 104- 每棵树中节点数目在范围
[1, 3]内。 - 输入数据的每个节点可能有子节点但不存在子节点的子节点
trees中不存在两棵树根节点值相同的情况。- 输入中的所有树都是 有效的二叉树搜索树 。
1 <= TreeNode.val <= 5 * 104.
首先,代码定义了一个unordered_set leaves,用于存储所有叶节点值的哈希集合。然后,代码定义了一个unordered_map<int, TreeNode*> candidates,用于存储(根节点值, 树)的键值对的哈希映射。
接着,代码遍历给定的一组二叉树,对于每棵树,先将其左右子节点的值加入leaves集合中,然后将(根节点值, 树)的键值对存入candidates哈希映射中。
然后,代码定义了一个名为dfs的lambda函数,用于进行中序遍历和合并操作。该函数首先判断当前节点是否为空,如果是空节点,则返回true。然后,如果遍历到叶节点,并且存在可以合并的树,就进行合并操作。合并前,还要检查合并前的树是否符合二叉搜索树的条件。合并完成后,将树从candidates哈希映射中移除。接下来,先递归遍历左子树,再遍历当前节点,最后递归遍历右子树。在遍历的过程中,还要检查是否满足严格单调递增的条件。如果满足条件,则返回true;否则,返回false。
接着,代码遍历给定的一组二叉树,对于每棵树,如果根节点的值不在leaves集合中,就从candidates哈希映射中移除该树,并从根节点开始进行遍历。如果中序遍历有严格单调递增的序列,并且所有树的根节点都被遍历到,说明可以构造二叉搜索树,返回合并后的二叉搜索树;否则,返回nullptr。
最后,代码定义了一个isBST函数,用于判断一棵树是否是二叉搜索树。该函数使用迭代的方式进行中序遍历,并检查是否满足严格单调递增的条件。
class Solution {
public:TreeNode* canMerge(vector<TreeNode*>& trees) {// 存储所有叶节点值的哈希集合unordered_set<int> leaves;// 存储 (根节点值, 树) 键值对的哈希映射unordered_map<int, TreeNode*> candidates;for (TreeNode* tree: trees) {if (tree->left) {leaves.insert(tree->left->val);}if (tree->right) {leaves.insert(tree->right->val);}candidates[tree->val] = tree;}// 存储中序遍历上一个遍历到的值,便于检查严格单调性int prev = 0;// 中序遍历,返回值表示是否有严格单调性function<bool(TreeNode*)> dfs = [&](TreeNode* tree) {if (!tree) {return true;}// 如果遍历到叶节点,并且存在可以合并的树,那么就进行合并if (!tree->left && !tree->right && candidates.count(tree->val)) {TreeNode* candidate = candidates[tree->val];// 检查合并前的树是否符合二叉搜索树的条件if (!isBST(candidate)) {return false;}tree->left = candidate->left;tree->right = candidate->right;// 合并完成后,将树从哈希映射中移除,以便于在遍历结束后判断是否所有树都被遍历过candidates.erase(tree->val);}// 先遍历左子树if (!dfs(tree->left)) {return false;}// 再遍历当前节点if (tree->val <= prev) {return false;};prev = tree->val;// 最后遍历右子树return dfs(tree->right);};for (TreeNode* tree: trees) {// 寻找合并完成后的树的根节点if (!leaves.count(tree->val)) {// 将其从哈希映射中移除candidates.erase(tree->val);// 从根节点开始进行遍历// 如果中序遍历有严格单调性,并且所有树的根节点都被遍历到,说明可以构造二叉搜索树return (dfs(tree) && candidates.empty()) ? tree : nullptr;}}return nullptr;}// 判断一棵树是否是二叉搜索树bool isBST(TreeNode* root) {stack<TreeNode*> stk;TreeNode* pre = nullptr;while (root || !stk.empty()) {while (root) {stk.push(root);root = root->left;}root = stk.top();stk.pop();if (pre && root->val <= pre->val) {return false;}pre = root;root = root->right;}return true;}
};
总结:这段代码的思路是通过中序遍历和合并操作来判断给定的一组二叉树是否可以合并成一棵二叉搜索树,并返回合并后的二叉搜索树。同时,还定义了一个辅助函数用于判断一棵树是否是二叉搜索树。