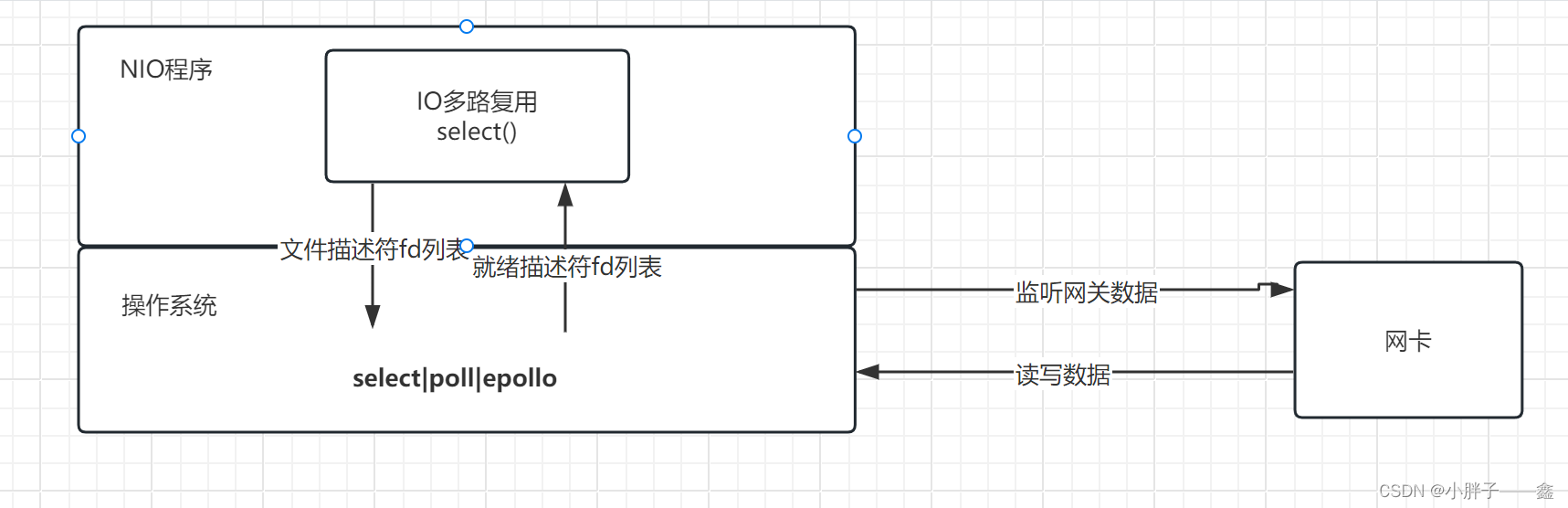
Diffused Heads: 扩散模型在说话人脸生成方面击败GANs
paper:[2301.03396] Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation (arxiv.org)
code:MStypulkowski/diffused-heads: Official repository for Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation (github.com)
来源:2023.7 WACV
总结:一种自回归扩散模型,输入:身份图像+音频序列。能够产生头部运动、眨眼等面部表情,并保留给定的背景。在两个不同的数据集上评估了该模型,在表现力和平滑性方面都取得了最先进的结果。
1. 介绍
现有方法在创建自然面部外观、保持真实表情和动作方面仍然存在困难,同时在生成过程中仍需要额外的监督。GANs 在语音驱动视频合成中的缺点:
- 首先,GAN 的训练困难,需要广泛的架构搜索和参数调整才能收敛。基于 GAN 的面部动画方法的训练稳定性可以通过使用额外的指导,如面具或引导帧来指导生成过程来改善。然而,这使它们局限于面部再现的应用,并降低了产生头部动作和面部表情的能力。
- 此外,GAN 的训练通常会导致模态崩溃,即生成器无法生成覆盖整个数据分布支持的样本,而是只学习生成几个唯一的样本 [1]。
- 最后,现有的一次性基于 GAN 的解决方案在生成视频时存在面部变形问题,特别是在生成具有大幅头部运动的视频时。这通常通过切换到少数帧方法(即使用几帧或短视频片段)或依赖预训练的面部验证模型来解决,这些模型作为保持身份一致性的参考。
针对这些问题提出了Diffused Heads——基于帧的扩散模型。生成的头部自然移动,同时保持主体身份和嘴唇同步。
- 使用去噪扩散概率模型[15, 23],采用变分方法,不需要稳定化判别器[27, 45, 50, 51]。
- 为了消除不自然序列的问题,引入了运动帧(见第 4.2 节),指导视频的创建。
- 为了保持语音和生成帧之间的一致性,使用从预训练时间模型提取的音频嵌入注入到模型中。
- 最后,引入了一种简单修改的损失函数,以保持嘴唇运动的一致性。
贡献总结如下:
- 是首个基于扩散模型的说话人脸生成的解决方案。
- 在扩散模型中增加了运动帧和音频嵌入,以保持生成图像的一致性。
- 泛化能力强,可保持身份帧和音频录音的来源不变。
2. 背景
正向扩散:
![]()
前向过程的一个性质是,只需一步就可获得中间状态:
![]()
这个性质帮助更有效地训练模型。
只有当模型知道前向扩散过程从哪里开始时,才能学习如何将xT去噪到基础数据点中。因此可以在x0上附加条件q(xt−1|xt),使其易于处理。利用贝叶斯定理得到:
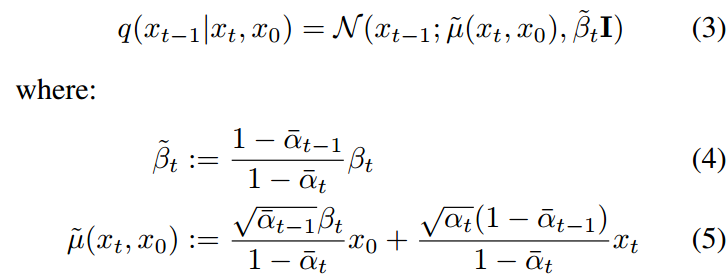
与VAE框架类似,定义近似q(xt−1|xt):
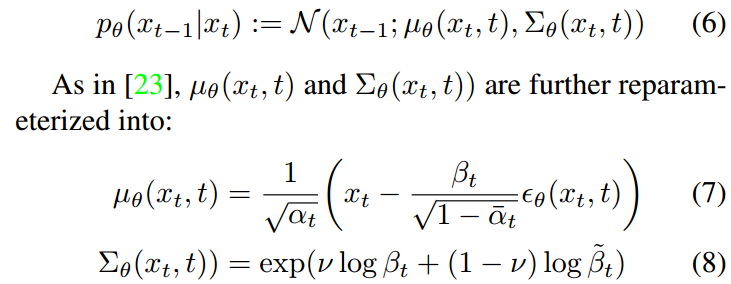
ϵθ(xt, t)是模型对高斯噪声的预测,应用于x0,以获得xt。而ν是模型的一个额外输出。
[23]中的Nichol和Dhariwal提出分别使用Lsimple和Lvlb训练μθ和Σθ:
![]()
![]()
其中L0是[15]中提出的离散高斯分布。LT被省略是因为q没有可训练的参数,而pθ(xT)是高斯先验。所有其他的项都是两个高斯分布之间的Kullback-Leibler散度,可以写成闭合形式。
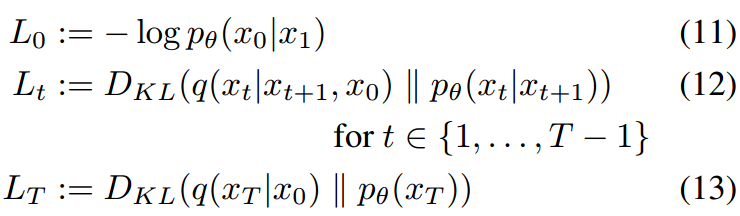
用一个具有跨层连接和注意力层的2D UNet[34],来预测噪声ϵθ(xt, t)和方差Σθ(xt, t)。时间步长t的信息通过相应的时间嵌入ψ(t)和组归一化(GN)来输入:
其中hs和hs+1是UNet的连续隐藏状态,(ts, tb) = MLP(ψ(t)),其中MLP是由线性层组成的浅层神经网络。
3. 方法
为了实现更平滑和更具表现力的结果,通过运动帧(第4.2节)和音频嵌入(第4.3节)在过去的运动和未来的表情中注入额外的信息。额外的唇同步损失(第4.4节),使模型更多地关注嘴部区域。

图2。训练步骤。一次去噪一帧,使用身份和运动帧,以及从预训练音频编码器中提取的音频嵌入。身份帧告诉模型感兴趣的人脸是什么,运动帧用来保留人脸的运动。
3.1 训练
训练一个扩散模型来学习从视频中提取的帧的分布。过程如图2所示。从训练集随机采样一个视频X = {X(1),…, x(n)},和视频中的任一帧x(k)。视频总帧数为n。除了标准的扩散模型的输入(时间步t、噪声x(k)t),为了保持源图像身份,将x(k)t和身份帧xId进行channel-wise:
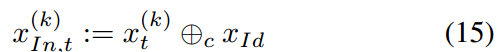
xId是从x中随机选择的。在训练过程中随机选择恒等帧而不是x(0),使模型熟悉更多种类的帧作为输入,从而提高鲁棒性。
为了添加时间信息,我们根据视频中的帧数将相应的音频序列拆分为长度相等的块。然后,使用来自[45]的音频编码器在LRW[4]数据集上进行预训练,音频块被编码成音频嵌入Y = {Y(1),…y (n)}。
3.2 运动帧
即使音频编码器向模型提供了时间信息,也不足以生成平滑的视频。为了克服这个问题并保持运动,对于目标帧x(k),引入运动帧![]() ,其中mx是运动帧的数量,
,其中mx是运动帧的数量,![]() c是对其所有参数在通道维度上的连接操作。消融研究发现mx的最佳值为2。
c是对其所有参数在通道维度上的连接操作。消融研究发现mx的最佳值为2。
为了使模型对样本初始化具有鲁棒性,使用xId作为缺失运动帧的替代品。将运动帧加入到式(15)中,得到模型直接输入的最终形式:

3.3 Speech conditioning
将音频嵌入y(k)中的信息注入,将式(14)修改为:
![]()
其中![]() 。利用时间编码和音频嵌入的信息来移动和缩放UNet的隐藏状态。
。利用时间编码和音频嵌入的信息来移动和缩放UNet的隐藏状态。
与运动帧相比,在采样期间,运动帧只能用于已经处理过的帧,我们可以事先获取整个语音。因此引入了运动音频嵌入,从过去和未来的音频片段中获取信息。定义为通过连接选定的音频嵌入而创建的向量:![]()
![]() ({y (k−my),…, y(k),…, y(k+my)}),其中my是来自一侧的额外音频嵌入的数量。
({y (k−my),…, y(k),…, y(k+my)}),其中my是来自一侧的额外音频嵌入的数量。
3.4 Lip sync loss
作者没有用显式损失函数来促进口型同步。扩散头适用于帧,而不是序列,因此基于序列的损失不能用。更重要的是,在扩散模型训练期间,目标是预测在帧上的噪声。从预测噪声返回到初始x0,这需要应用感知损失,在单个步骤中不够准确,并且在更多步骤中计算效率低下。
作者的解决方案:额外的口型损失Lls。在训练期间,利用面部landmark来裁剪嘴巴区域周围的每一帧,并最大限度地减少该区域的噪声预测:
![]()
其中和
θ分别表示裁剪版本的GT和预测噪声。该过程如图3所示。在唇形缺失的情况下,模型更加注重唇形与音频嵌入的同步,提高了采样视频的整体感知能力。用一个恒定的λls来加权ls,这个λls利用了模型对嘴巴区域和框架其余部分细节的关注。最终优化目标为:
![]()

图3。除了在Lsimple中最小化GT噪声λ与预测噪声ϵθ(xt, t)之间的L2距离外,还利用目标帧的landmark来最小化 裁剪的GT噪声λ与相应的预测面积λ θ(xt, t) 之间的口型同步损失Lls。
3.5 sampling
对于采样,只需要从讲话视频中提取身份帧和音频嵌入。
通过用身份帧的副本初始化 x(0) Motion 来启动视频生成。每一帧都是根据方程(6)中变分后验定义的扩散模型的去噪过程进行采样的。在每一步之后,用合成的帧替换最新的运动帧。y(k) Motion 遵循与训练过程中相同的步骤。
生成单帧需要相当长的时间,因为它需要模型对所有扩散时间步 {1, . . . , T} 进行预测。为了加快该过程,作者用r time step respacing的方法将采样时间缩短了5倍。
由于模型逐帧合成序列,错误都会在后续步骤中累积。
为了强制模型从身份帧中获取更多关于人外观的信息,将每个运动帧转换为灰度图像。这应该使模型更难提取身份特征(如颜色),同时推动它寻找运动信息。发现这种解决方案在具有大量参与者的更复杂数据集上效果良好。
4. 实验
评估数据集:CREMA,LRW。
训练细节:在128x128分辨率的视频上训练的。使用与[6]中提出的相同的UNet[34]架构。使用256-512-768通道作为输入块,每个通道有2个ResNet[12]层。实验的早期阶段,我们发现添加更多的注意力层会降低生成帧的质量。因此,我们在中间块中只使用具有4个头部和64个头部通道的注意层。
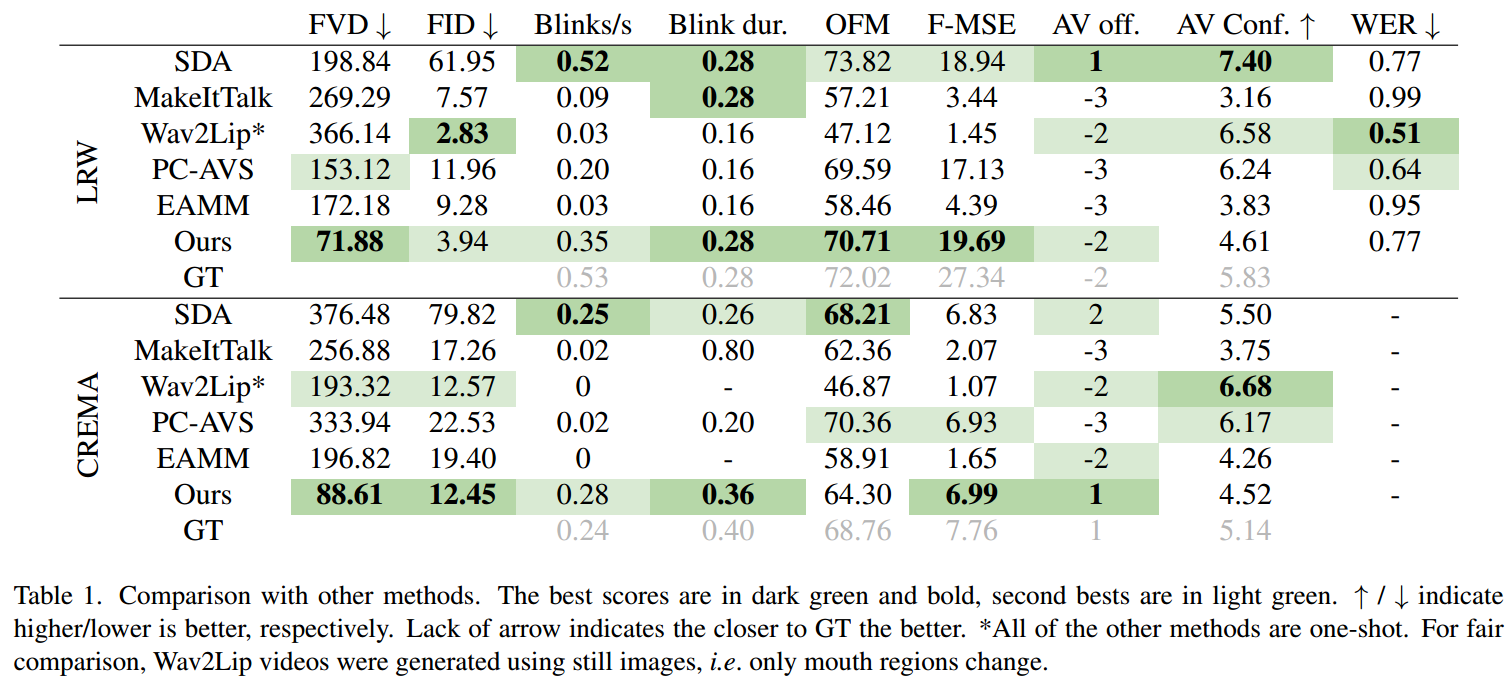
局限性:生成视频的长度有限。由于我们不提供任何额外的姿态输入或头部运动的视觉指导和模型自回归生成帧,它无法保持质量序列长于8-9秒。此外,与其他生成模型相比,扩散模型的生成时间较长,无法实时应用。