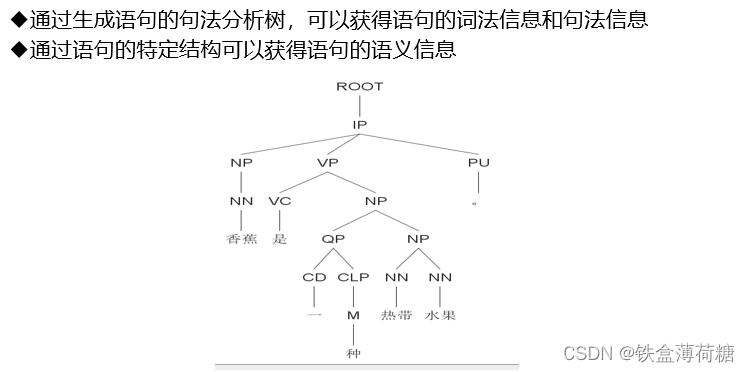
- 文献阅读:Transformers are Multi-State RNNs
- 1. 内容简介
- 2. 方法介绍
- 1. 基础回顾
- 1. RNN
- 2. Transformer
- 2. Transformer解构
- 1. MSRNN
- 2. Transformer
- 3. TOVA
- 1. 现有转换策略
- 2. TOVA
- 1. 基础回顾
- 3. 实验考察 & 结论
- 1. 实验设计
- 2. 实验结果
- 1. LM
- 2. 长文本理解
- 3. 文本生成
- 3. 细节考察
- 4. 总结 & 思考
- 文献链接:https://arxiv.org/abs/2401.06104
- GitHub链接:https://github.com/schwartz-lab-NLP/TOVA
1. 内容简介
这篇文章是今年1月Meta发表的一篇对Transformer的解构工作。
它对Transformer进行了更深入的解析和考察,发现Transformer的self attention机制等价于一个无限状态的MSRNN(multi-state RNN),并在此基础上对MSRNN进行了优化,提出了一个TOVA的MSRNN压缩策略,使之效果超过了其他的MSRNN,并能够与Transformer本身相提并论。而在内存方面,则显著优于经典的Transformer模型。

下面,我们就来具体看一下文中对于Transformer的具体考察以及文中提出的TOVA方法究竟是怎样的一个设计思路。
2. 方法介绍
1. 基础回顾
在解构Transformer以及引入TOVA之前,文中首先回顾了一下RNN和Transformer本身,这里,为了保持文章在结构上的完整性,我们也简略的回顾一下RNN和Transformer本身。
1. RNN
首先的话,RNN的话是一个迭代的解构,模型本身维护一个隐态 h t h_t ht,然后根据输入 x t x_t xt进行迭代:
x t l + 1 , h t l = f ( x t l , h t − 1 l ) x_t^{l+1}, h_{t}^{l} = f(x_t^l, h_{t-1}^l) xtl+1,htl=f(xtl,ht−1l)
2. Transformer
Transformer的话则是self-attention的解构,具体表达式如下:
X l + 1 = F F N ( A t t n ( X l ) ) = F F N ( S o f t m a x ( Q l ⋅ ( K l ) T ) ⋅ V l ) \begin{aligned} X^{l+1} &= \mathop{FFN}(\mathop{Attn}(X^l)) \\ &= \mathop{FFN}(\mathop{Softmax}(Q^l\cdot (K^l)^T) \cdot V^l) \end{aligned} Xl+1=FFN(Attn(Xl))=FFN(Softmax(Ql⋅(Kl)T)⋅Vl)
2. Transformer解构
有了上面的基础,我们来看一下文中是如何说明Transformer的本质就是一个无线state的MSRNN的。
我们将分两部分来说明这个问题:
- MSRNN是什么
- Transformer怎么对应到一个MSRNN
下面,我们来看一下文中对于这两个问题的回答。
1. MSRNN
首先,我们来看一下MSRNN是什么,本质上来说,MSRNN还是一个RNN,不过RNN当中的隐态是一个向量,而MSRNN则是用一个矩阵来替代向量,直观上理解就是有多个隐态,即multi-state。
用公式表达即为:
x t l + 1 , H t l = f ( x t l , H t − 1 l ) x_t^{l+1}, H_{t}^{l} = f(x_t^l, H_{t-1}^l) xtl+1,Htl=f(xtl,Ht−1l)
2. Transformer
然后,我们再来看一下Transformer,如前所述,Transformer的每一个module可以写为:
X l + 1 = F F N ( S o f t m a x ( Q l ⋅ ( K l ) T ) ⋅ V l ) X^{l+1} = \mathop{FFN}(\mathop{Softmax}(Q^l\cdot (K^l)^T) \cdot V^l) Xl+1=FFN(Softmax(Ql⋅(Kl)T)⋅Vl)
我们可以将其重写为:
x t l + 1 = F F N ( S o f t m a x ( q t l ⋅ ( K t l ) T ) ⋅ V t l ) x_{t}^{l+1} = \mathop{FFN}(\mathop{Softmax}(q_t^l\cdot (K_t^l)^T) \cdot V_t^l) xtl+1=FFN(Softmax(qtl⋅(Ktl)T)⋅Vtl)
亦即:
x t l + 1 , ( K t l , V t l ) = f l ( x t l , ( K t l , V t l ) ) x_{t}^{l+1}, (K_t^l, V_t^l) = f^l(x_t^l, (K_t^l, V_t^l)) xtl+1,(Ktl,Vtl)=fl(xtl,(Ktl,Vtl))
因此,从定义式上来看,Transformer确实可以理解为无限维度的MSRNN。
3. TOVA
综上,我们已经可以发现,在形式上而言,Transformer可以视为一个无限state的MSRNN,但是无限state显然在实现层面并不现实,因此,要想要真正将其对应到MSRNN,我们需要一个无限维转换为有限维的转换策略。
文中的话也是首先讨论了一下现有的几个转换的方法,然后在此基础上提出了他们自己的转换方法,即他们所谓的TOVA方法。
下面,我们来具体看一下这两部分的内容。
1. 现有转换策略
首先,我们来看一下当前已有的一些无限维转有限维的策略,文中主要给出了三种方法:
- Window
- 只保留最后k个token
- Window + i
- 保留最后k个token以及头部的i个token
- H 2 O H_2O H2O
- 保留最后k个token,然后动态通过attention score额外多保留i个token
2. TOVA
然后,我们来看一下文中提出的TOVA方法,其全称为Token Omission Via
Attention (TOVA),思路上其实也很直接,就是直接通过attention score选择attention score最高的k个token进行保留,文中给出示意图如下:

3. 实验考察 & 结论
下面,我们来考察一下文中的实验结果。
我们将分以下几个部分对文中的内容进行一下整理:
- 文中的实验设计
- 具体的实验结果
- TOVA的拆解实验
1. 实验设计
首先,我们来看一下文中的实验设计,主要包括两部分的内容:
- 具体采用的实验
- 实验中使用的模型
其中,关于文中具体采用的实验的话,主要是长文本上的实验,包括:
- LM的ppl考察
- 长文本的理解实验
- 文本生成任务
而关于文中使用的模型的话,文中主要使用了以下三类模型:
- LLama-2-7B
- Mistral-7B
- Yi-7B
2. 实验结果
下面,我们来看一下文中给出的具体实验结果。
1. LM
首先,关于Language Model的ppl,文中得到结果如下:

可以看到:
- 在各类策略下,TOVA能够获得最好的效果表达,且在各个模型下都有一致的结论。
2. 长文本理解
文中关于长文本当中理解任务的实验结果则如下所示:

可以看到:
- 无论是在长文本概括任务还是长文本QA任务当中,TOVA的效果都显著优于其他的转换策略。
- 同样的,在长文本理解任务当中,TOVA同样在不同的模型当中都有一致的有效性表达。
3. 文本生成
最后,文中还在生成任务当中对TOVA的效果进行了一下考察,具体来说的话,就是令TOVA和GPT4分别进行生成,然后交给人来标注对比结果的好坏,得到结果如下:

可以看到:
- 随着文本的增长,TOVA的效果逐步追上GPT4,说明TOVA在长文本下确实有效,且效果拔群。
3. 细节考察
然后,除了对于TOVA效果的基础考察,文中还对TOVA进行了细节的拆解,具体来说,主要就是考察了一下几个问题:
- TOVA保留的是哪些位置的token
- TOVA对于头部的token的留存度
- TOVA保留的具体是哪些token
文中得到的具体实验结果如下:


可以看到:
- 在图7当中,每一行代表对应的step当中参与到生成当中的token,可以看到,整体来说,邻近的token会更重要,当这也不是必然的,有时候长程的token也会参与其中,反而是短程的会被过滤掉。
- 从图8可以看到,前25个token都悲保留了很长的距离,且第一个token尤为关键;
- 从图9可以看到,一些标点符号类型的token会被更倾向于保留下来。
4. 总结 & 思考
综上,文中对Transformer进行了一下结构上的解构分析,发现其本质上就是一个无限维的MSRNN,且通过一定的压缩策略,可以用一个有限维的MSRNN对其进行逼近。
基于此,文中给出了一个名为TOVA的压缩策略,碾压了当前已有的其他压缩策略,并在长文本当中的效果逼近了GPT4,而在batch size方面可以扩大8倍,即效率上可以比当前的Transformer结构更好。
这个还是非常厉害的,Meta感觉确实还是做了不少基础方面的工作,不过具体TOVA策略下的MSRNN能不能干掉Transformer估计现在也说不好,毕竟文中也没有给什么直接的比较,估计效果上还是有差。
后面再看看吧,看看能不能有什么工作能够最终干掉transformer框架吧。