目录
- 1. java(jdk)
- 2. Hadoop
- 3. 配置文件
- 4. 启动Hadoop服务(搭建伪分布式环境)
1. java(jdk)
- yum list java* :列出所有名称中包含“java”字样的软件包
- yum install java-1.8.0-openjdk.x86_64:选择自己想要的版本。这里我选择java8
- java -version:查看java的版本号,以证明安装完毕
- 配置环境变量:
echo 'export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64/jre' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
(注意修改路径)
2. Hadoop
- 用wget 下载指定的URL(hadoop清华镜像)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
报错:错误: 无法验证 mirrors.tuna.tsinghua.edu.cn 的由 “/C=US/O=Let’s Encrypt/CN=R3” 颁发的证书:
颁发的证书已经过期。

解决:将https修改为http
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
- 解压Hadoop安装包至/opt/hadoop
tar -zxvf hadoop-3.2.4.tar.gz -C /opt/
mv /opt/hadoop-3.2.4 /opt/hadoop
- 配置Hadoop环境变量
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
(注意路径是否正确)
- 修改配置文件yarn-env.sh和hadoop-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64/jre" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64/jre" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
(注意路径是否正确)
- 测试Hadoop是否安装成功

3. 配置文件
作用:
hadoop.tmp.dir — 定义了Hadoop系统用于存储临时文件的本地文件系统目录。
fs.defaultFS — HDFS
- 配置文件core-site.xml
vim /opt/hadoop/etc/hadoop/core-site.xml
输入i进入编辑。在<configuration></configuration>节点内,插入如下内容。
<property><name>hadoop.tmp.dir</name><value>file:/opt/hadoop/tmp</value><description>location to store temporary files</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
按Esc并输入:wq保存退出
- 配置 mapred-site.xml 文件
作用:指定了处理MapReduce作业的框架是YARN。这意味着当您提交一个MapReduce作业时,它将由YARN来管理和调度
vim /opt/hadoop/etc/hadoop/mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
- 配置 yarn-site.xml 文件
vim /opt/hadoop/etc/hadoop/yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hahoop.mapred.ShuffleHandler</value></property>
- 配置 hdfs-site.xml 文件
- 创建文件夹
mkdir /opt/hadoop/data mkdir /opt/hadoop/data/datanode mkdir /opt/hadoop/data/namenode mkdir /opt/hadoop/data/tmp
-
编辑文件
vim /opt/hadoop/etc/hadoop/hdfs-site.xml<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/opt/hadoop/data/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:/opt/hadoop/data/datanode</value></property>
- 创建文件夹
4. 启动Hadoop服务(搭建伪分布式环境)
- namenode格式化
cd /opt/hadoop/bin
hdfs namenode -format
很好,没报错~
- 配置SSH免密登录
ssh-keygen -t rsa
创建公钥和私钥,直接三次回车
将公钥添加到authorized_keys文件中:
cd /root/.ssh # 有可能ssh文件夹不是这个路径
cat id_rsa.pub >> authorized_keys
- 开启hdfs:start-dfs.sh
cd /opt/hadoop/sbin
start-dfs.sh
- 开启yarn
start-yarn.sh
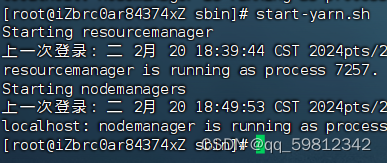
- 查看Hadoop运行的进程
jps
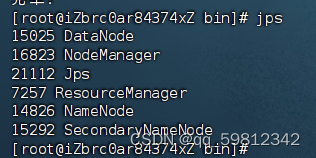
遇到错误:-bash: jps: 未找到命令,发现java安装包的bin文件夹中没有jps:
yum list | grep jdk-devel
yum install 选择对应自己Java版本和系统
-
在阿里云ECS实例安全组的
入方向中放行Hadoop所需的8088和50070端口
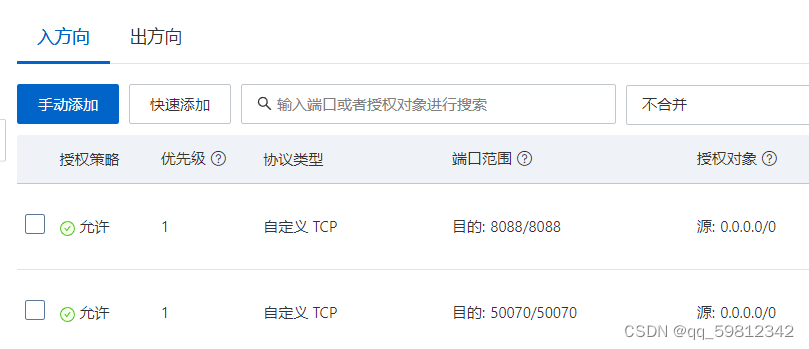
-
检查端口号是否存在
firewall-cmd --list-ports -
报错:没有开启防火墙
# 开启防火墙 systemctl start firewalld -
如果没有开启就使用命令
firewall-cmd --zone=public --add-port=端口号/tcp --permanent -
然后重启
systemctl restart firewalld.service firewall-cmd --list-ports
-
-
打开浏览器访问http://<ECS公网IP>:8088和http://<ECS公网IP>:50070