文章目录
- 基于Python网络爬虫的IT招聘就业岗位可视化分析推荐系统
- 项目概述
- 招聘岗位数据爬虫分析
- 系统展示
- 用户注册登录
- 系统首页
- IT招聘数据开发岗-java
- IT招聘数据开发岗-Python
- IT招聘数据开发岗-Android
- 算法方面
- 运维方面
- 测试方面
- 招聘岗位薪资多维度精准预测
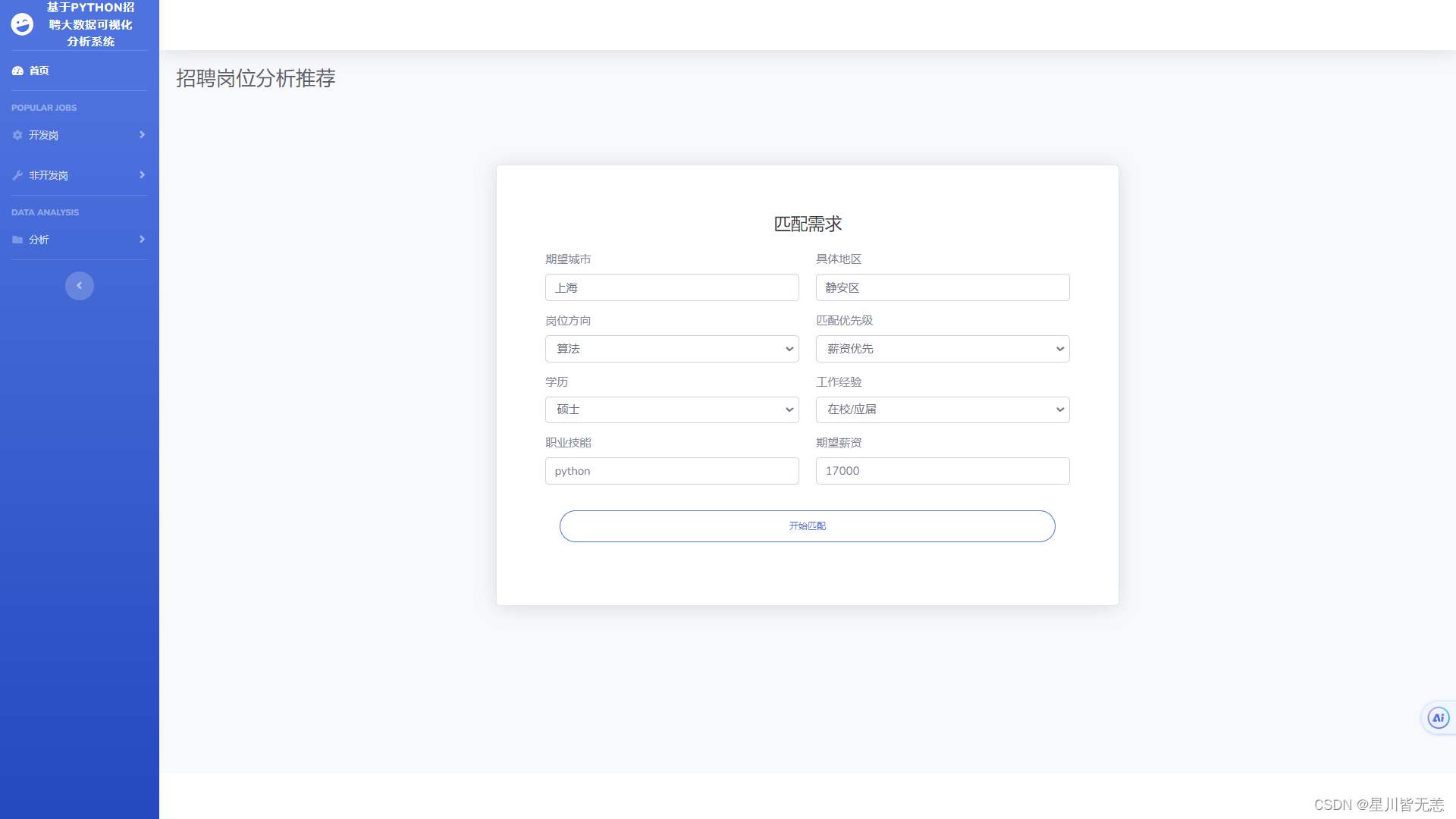
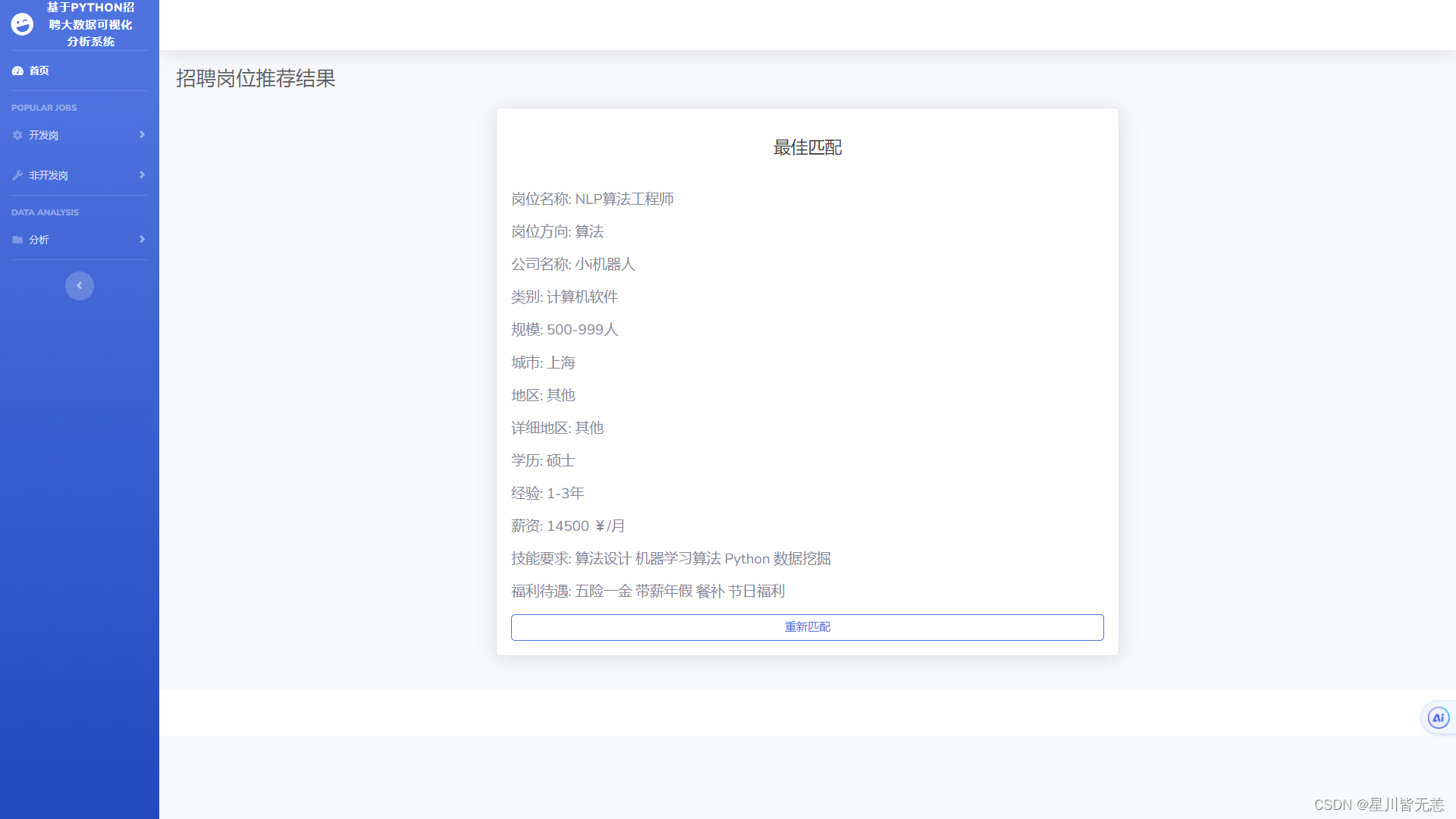
- 招聘岗位分析推荐
- 结语
基于Python网络爬虫的IT招聘就业岗位可视化分析推荐系统
项目概述
本项目旨在开发一个基于Python网络爬虫技术的IT招聘就业岗位可视化分析推荐系统。数据来源于Boss直聘招聘网站,采集到的各种岗位数据信息量合计在70万左右,数据精确真实可靠,本项目主要利用selenium、requests爬虫以及BeautifulSoup、numpy和Pandas等库进行数据的获取与分析处理。除此之外,项目还包括词云生成、数据分析、精准分析岗位算法推荐以及多维度薪资预测等功能,旨在为求职者提供全面的就业信息支持。
1.数据爬取与清洗:利用selenium和requests等库,结合BeautifulSoup解析HTML页面,从boss直聘等招聘网站上抓取相关数据。爬取的数据包括岗位名称、薪资、公司名称、公司规模、职位描述等。爬取后的数据需要进行清洗和预处理,确保数据的准确性和完整性。
2.词云生成:利用爬取的职位描述等文本数据,使用词云生成技术,将关键词可视化展示,帮助用户快速了解招聘岗位的主要特点和需求。
3.数据分析与可视化:利用Python的数据分析库(如Pandas、NumPy等)对爬取的数据进行分析,探索招聘市场的趋势、热门岗位、薪资水平等多维度、多层次招聘数据岗位关键信息。同时,利用可视化库(如Matplotlib、Echarts、Seaborn、Plotly等)生成直观、易于理解的图表和图形,提供给用户参考。
4.岗位算法推荐:根据用户输入的个人信息、技能和求职偏好,结合爬取的岗位数据,设计并实现精准分析岗位推荐给用户,为用户推荐匹配度较高的岗位,提高求职效率。
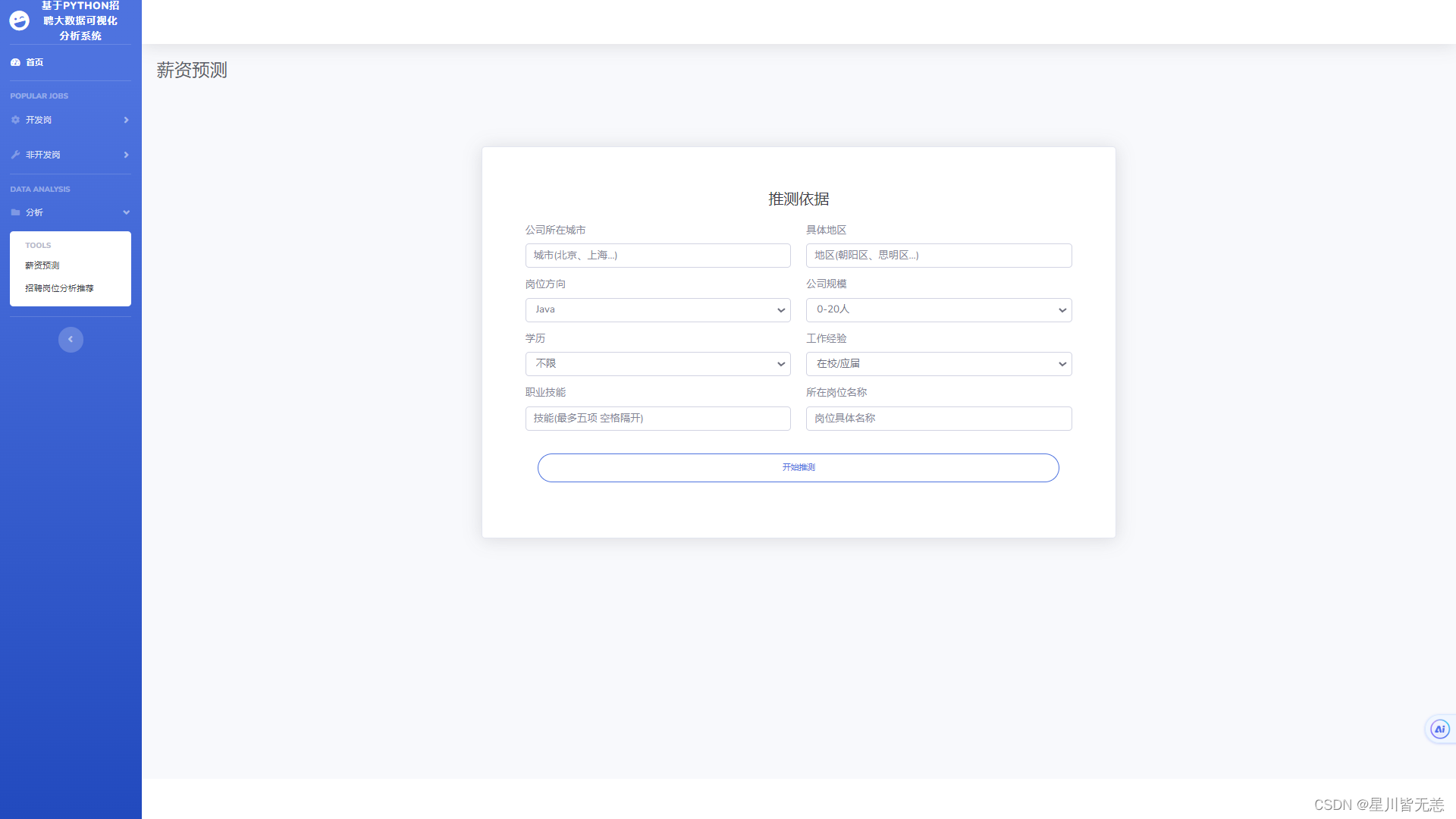
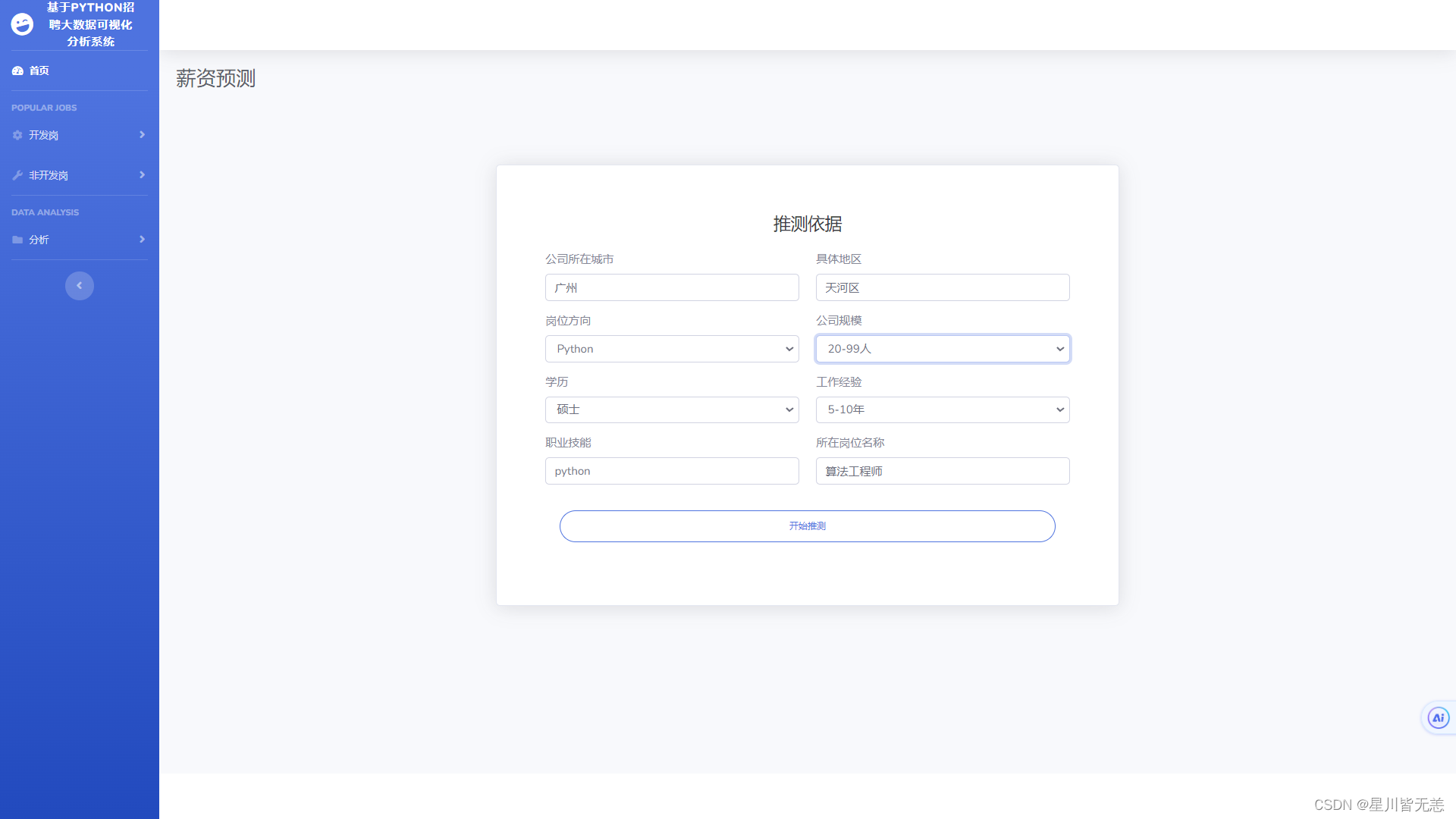
5.机器学习算法薪资预测:基于爬取的历史薪资数据以及其他相关因素,建立机器学习算法薪资预测模型,为用户提供对于不同岗位薪资水平的预测,帮助他们更好地评估职位的吸引力。
通过以上功能,本项目旨在为求职者提供一个综合性的就业信息平台,帮助他们更好地了解市场需求、制定求职策略,并通过推荐系统和薪资预测模型提供个性化的职位推荐和薪资参考,从而促进求职过程的顺利进行。
招聘岗位数据爬虫分析
通过selenium爬虫模块,能够快速准确的爬取所需要的详细招聘信息,可以精准爬取所需要的招聘岗位地区,城市,岗位名称,如’python’, ‘算法’, ‘测试’,'python’等不同IT岗位通过关键字都可以精确爬取。
然后将爬虫和数据处理接口全部封装到runtest脚本,完成所需要的招聘岗位数据爬虫及数据清洗。
#数据爬虫spider = bosszp_spider.Spider()spider.run()#数据清洗
# #
handle = datahandle.DataHandle()
handle.run()
selenium爬取招聘岗位详细信息并进行数据清洗,这里我的chromedriver.exe版本是v110,一定选择浏览器所兼容支持的版本号。
看下我之前爬取到的C语言招聘岗位详细数据信息
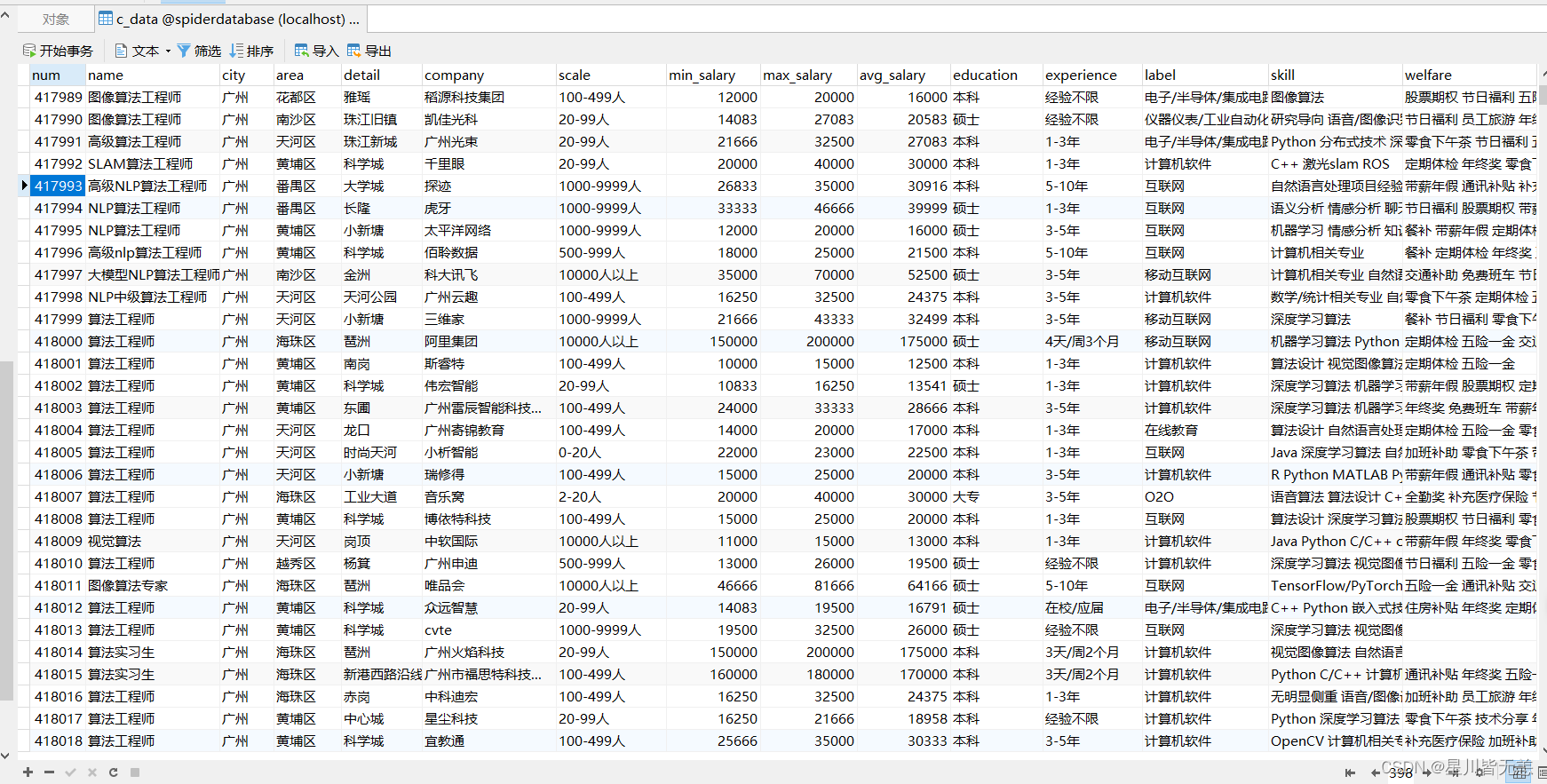
部分核心代码:
from selenium import webdriver
from bs4 import BeautifulSoup
import mysqlclass Spider(object):def __init__(self):# 创建数据库对象self.__sql = mysql.MySql()# 无头浏览器开启self.__driver = webdriver.Chrome('spider/chromedriver.exe')# 隐式等待self.__driver.implicitly_wait(20)# 设置需要爬取的 【关键词】self.__keyword = ['c', 'java', 'python', 'web前端', '.net', 'u3d', 'c#', 'c++', '算法', 'ios', 'Android']#self.__keyword = ['.net', 'u3d', 'c#', 'c++', '算法', 'ios', 'Android']#self.__keyword = ['测试', '运维','算法', 'ios', 'Android']# self.__keyword = ['python']# self.__keyword = ['python', '算法', '测试']# self.__keyword = ['Android']def __del__(self):# 关闭无头浏览器,减少内存损耗self.__driver.quit()# 设置爬取关键词def setKeyword(self, keyword):self.__keyword = []if isinstance(keyword, list):self.__keyword = keywordelse:var = str(keyword)var.strip()if " " in var:keyword_list = var.split(' ')self.__keyword = keyword_listelse:self.__keyword.append(var)# 获取所有关键词def getKeyword(self):return self.__keyword# 爬虫方法def run(self):print(">>>开始获取...")# 城市json# 在下方设置需要爬取的【城市】cities = [{"name": "北京", "code": 101010100, "url": "/beijing/"},{"name": "上海", "code": 101020100, "url": "/shanghai/"},{"name": "广州", "code": 101280100, "url": "/guangzhou/"},{"name": "深圳", "code": 101280600, "url": "/shenzhen/"},# {"name": "杭州", "code": 101210100, "url": "/hangzhou/"},# {"name": "天津", "code": 101030100, "url": "/tianjin/"},# {"name": "西安", "code": 101110100, "url": "/xian/"},# {"name": "苏州", "code": 101190400, "url": "/suzhou/"},# {"name": "武汉", "code": 101200100, "url": "/wuhan/"},# {"name": "厦门", "code": 101230200, "url": "/xiamen/"},# {"name": "长沙", "code": 101250100, "url": "/changsha/"},# {"name": "成都", "code": 101270100, "url": "/chengdu/"},# {"name": "郑州", "code": 101180100, "url": "/zhengzhou/"},# {"name": "重庆", "code": 101040100, "url": "/chongqing/"},# {"name": "佛山", "code": 101280800, "url": "/foshan/"},# {"name": "合肥", "code": 101220100, "url": "/hefei/"},# {"name": "济南", "code": 101120100, "url": "/jinan/"},# {"name": "青岛", "code": 101120200, "url": "/qingdao/"},# {"name": "南京", "code": 101190100, "url": "/nanjing/"},# {"name": "东莞", "code": 101281600, "url": "/dongguan/"},# {"name": "福州", "code": 101230100, "url": "/fuzhou/"}..............................................]# 总记录数all_count = 0# 关键词爬取for key in self.__keyword:print('>>>当前获取关键词: "{}"'.format(key))# 单个关键词爬取记录数key_count = 0# 每个城市爬取for city in cities:print('>>>当前获取城市: "{}"'.format(city['name']))# 记录每个城市爬取数据数目city_count = 0# 只获取前十页urls = ['https://www.zhipin.com/c{}/?query={}&page={}&ka=page-{}'.format(city['code'], key, i, i) for i in range(1, 11)]# 逐条解析for url in urls:self.__driver.get(url)# 获取源码,解析html = self.__driver.page_sourcebs = BeautifulSoup(html, 'html.parser')# 获取搜索框,用于判断是否被异常检测flag = bs.find_all('div', {'class': 'inner home-inner'})# 主要信息获取job_all = bs.find_all('div', {"class": "job-primary"})# 解析页面for job in job_all:# 工作名称job_name = job.find('span', {"class": "job-name"}).get_text()# 工作地点job_place = job.find('span', {'class': "job-area"}).get_text()# 工作公司job_company = job.find('div', {'class': 'company-text'}).find('h3', {'class': "name"}).get_text()# 公司规模job_scale = job.find('div', {'class': 'company-text'}).find('p').get_text()# 工作薪资job_salary = job.find('span', {'class': 'red'}).get_text()# 工作学历job_education = job.find('div', {'class': 'job-limit'}).find('p').get_text()[-2:]# 工作经验job_experience = job.find('div', {'class': 'job-limit'}).find('p').get_text()# 工作标签job_label = job.find('a', {'class': 'false-link'}).get_text()# 技能要求job_skill = job.find('div', {'class': 'tags'}).get_text().replace("\n", " ").strip()# 福利job_welfare = job.find('div', {'class': 'info-desc'}).get_text().replace(",", " ").strip()#职位类型 追加type=key# 数据存储self.__sql.saveData(job_name, job_place, job_company, job_scale, job_salary, job_education,job_experience,job_label,job_skill,job_welfare,type).......
最后爬取不同城市的详细真实IT招聘岗位数据大约70万条,爬的时间也挺久。
系统展示
启动项目 进入系统
http://127.0.0.1:8080/login.html
用户注册登录
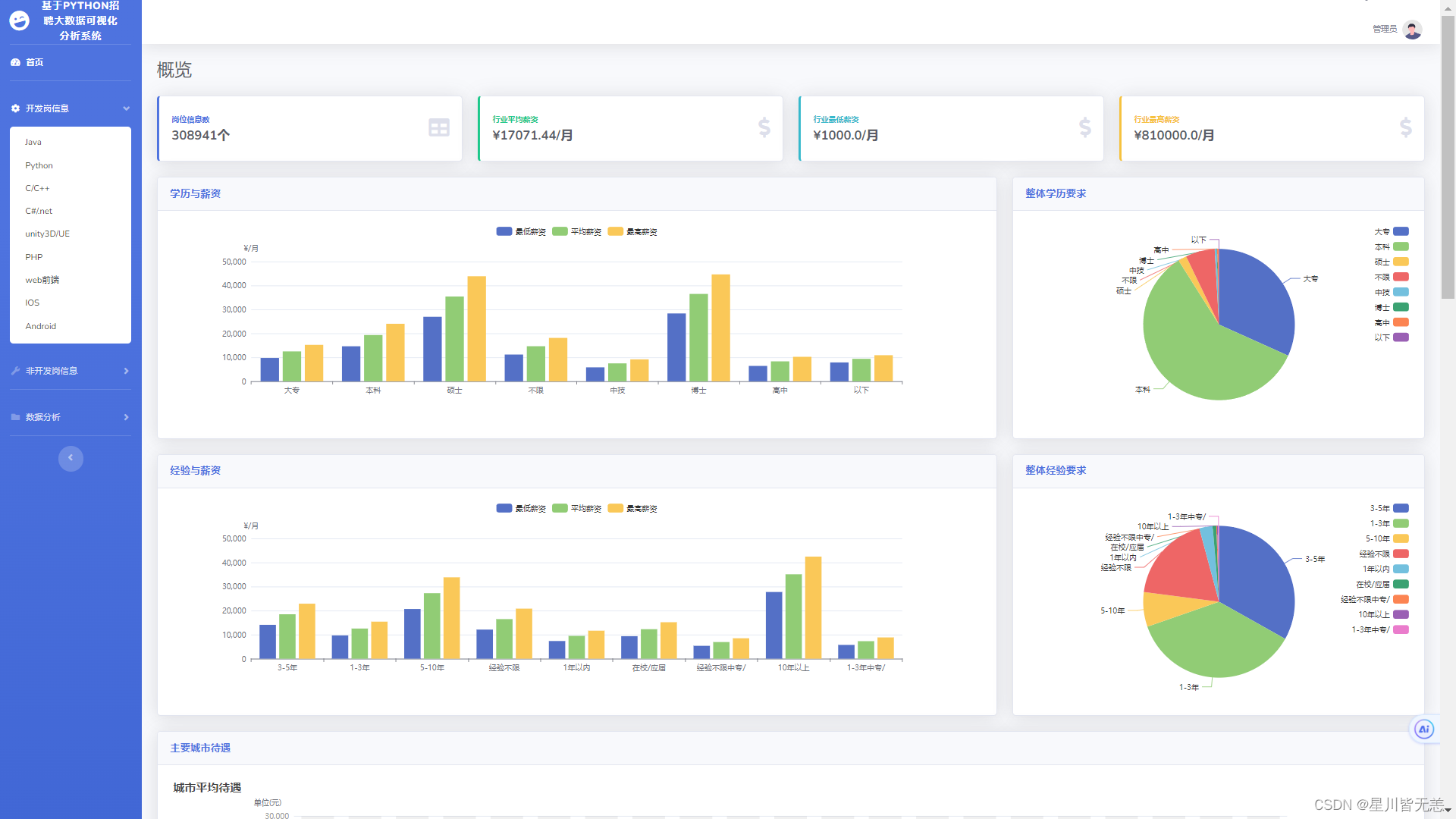
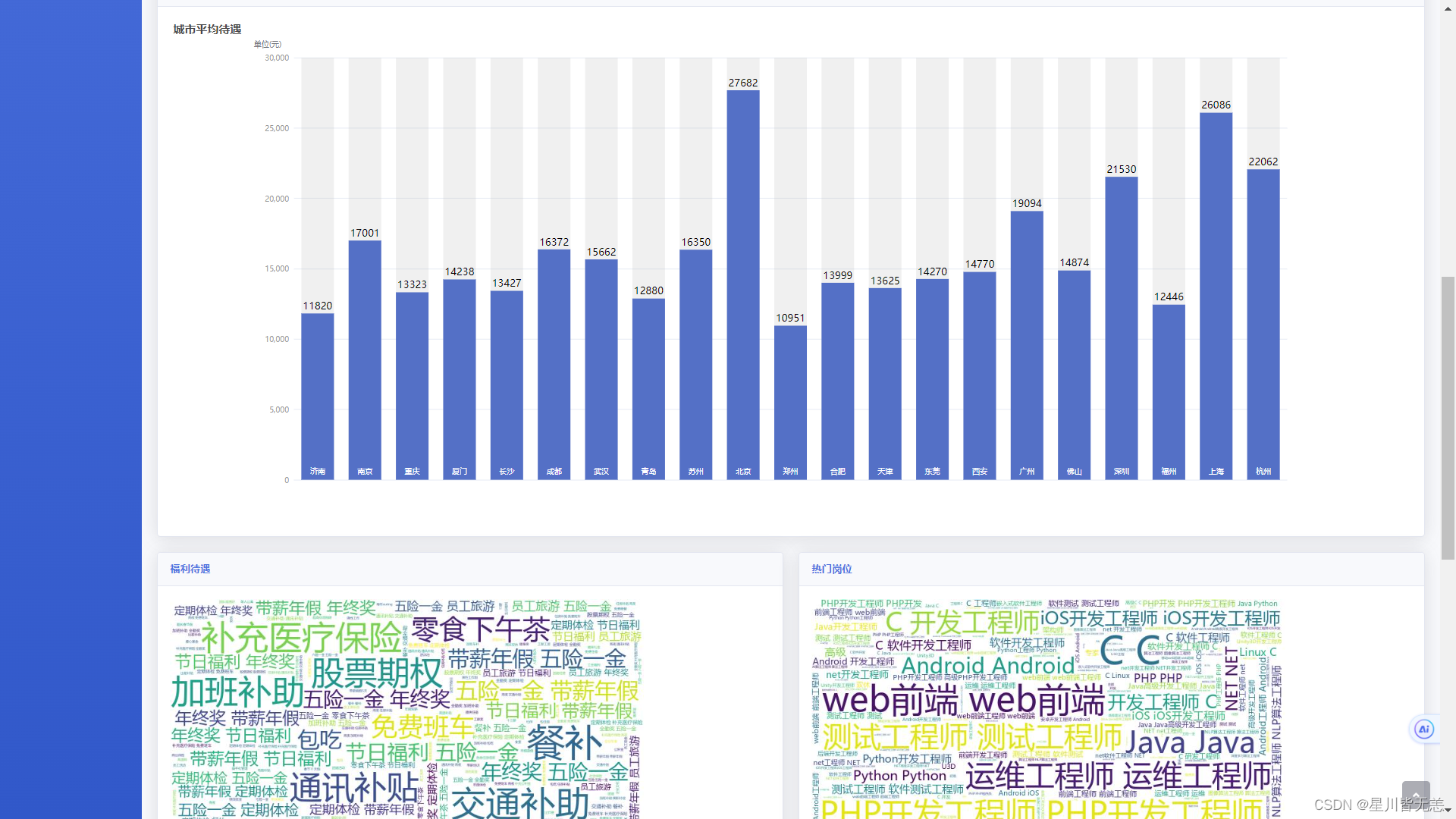
系统首页
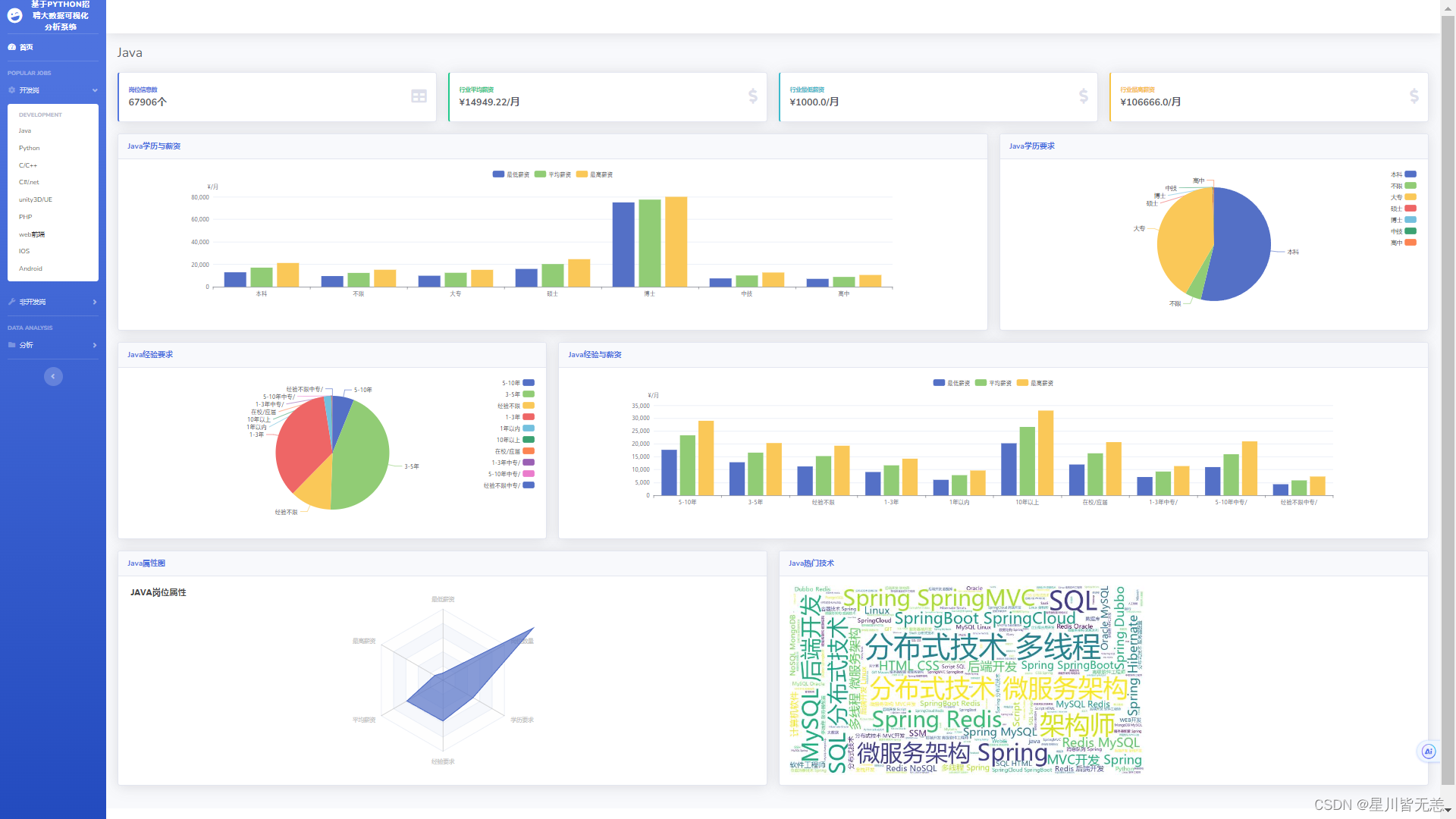
IT招聘数据开发岗-java
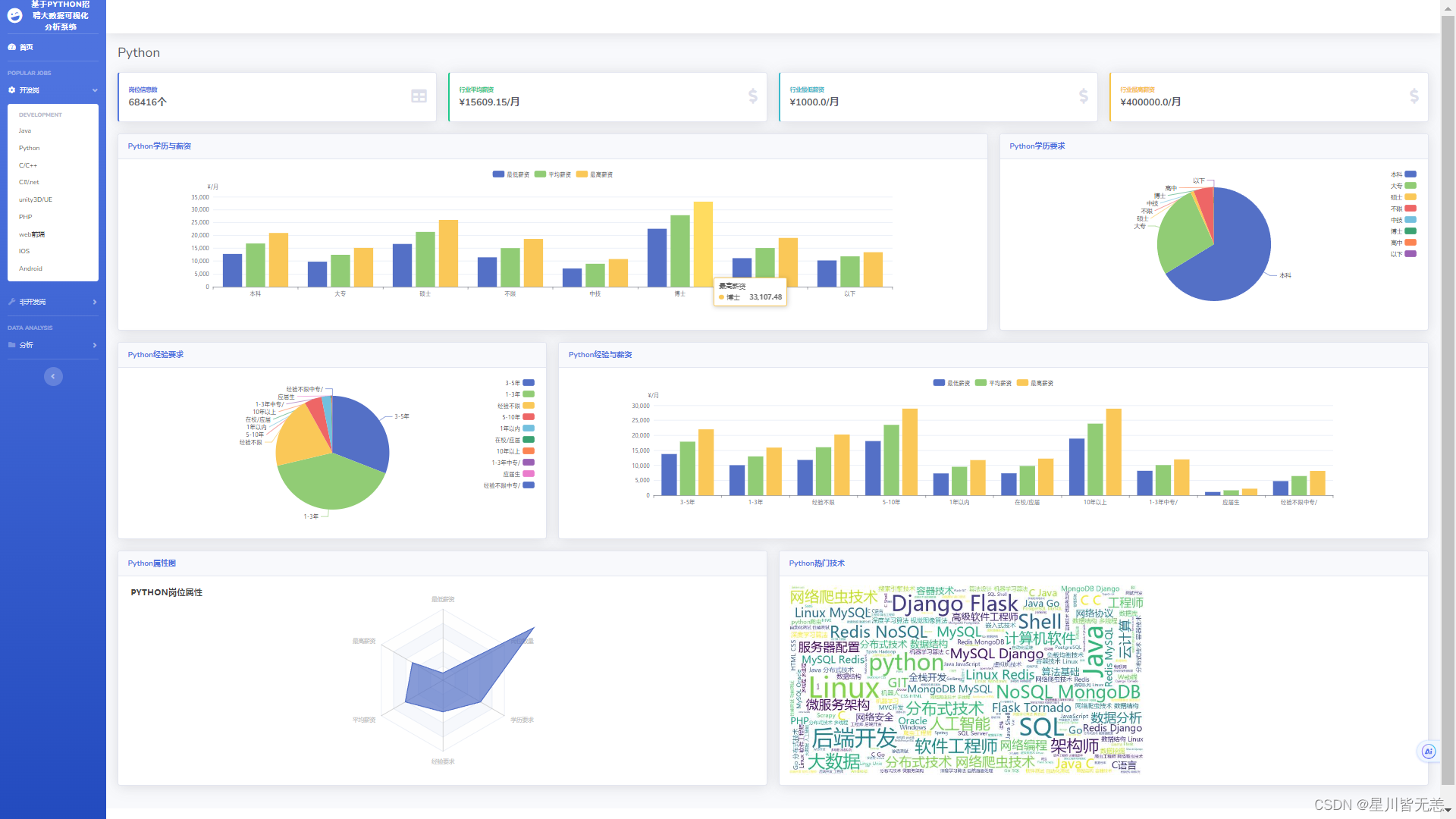
IT招聘数据开发岗-Python
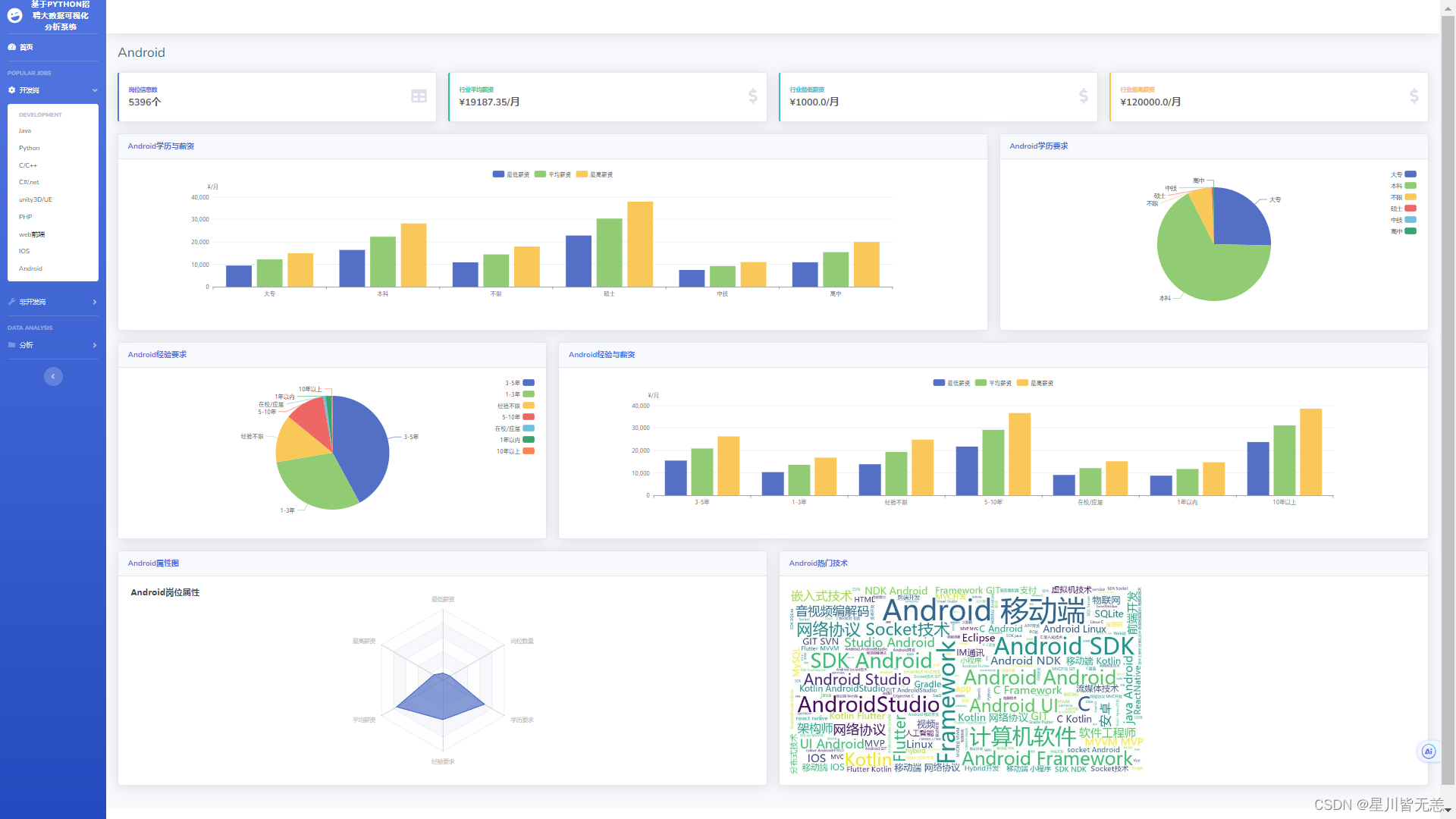
IT招聘数据开发岗-Android
非开发岗我这里爬取了3个,想爬取更多岗位,可以直接修改爬虫代码里面参数信息就行。
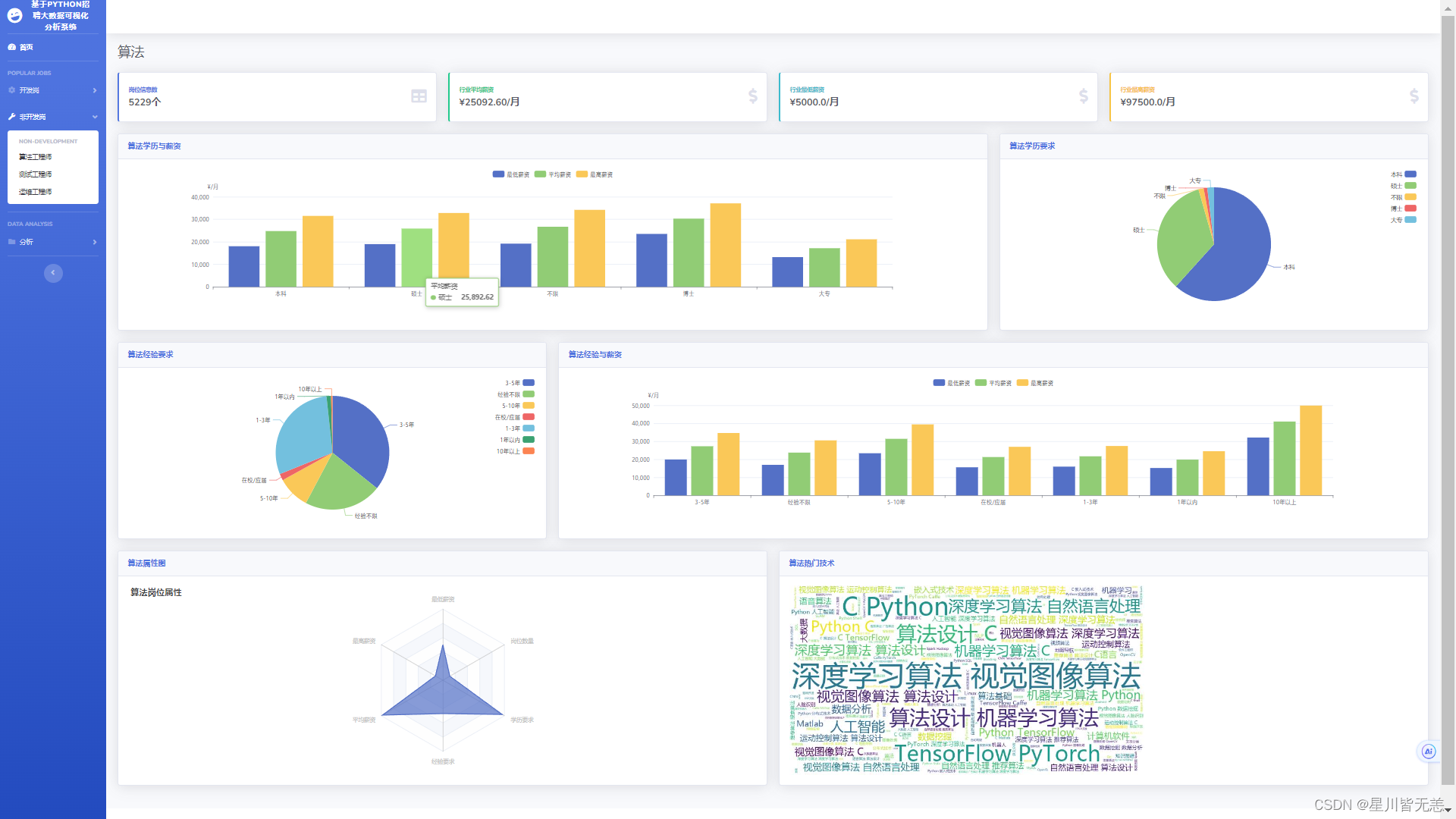
算法方面
运维方面

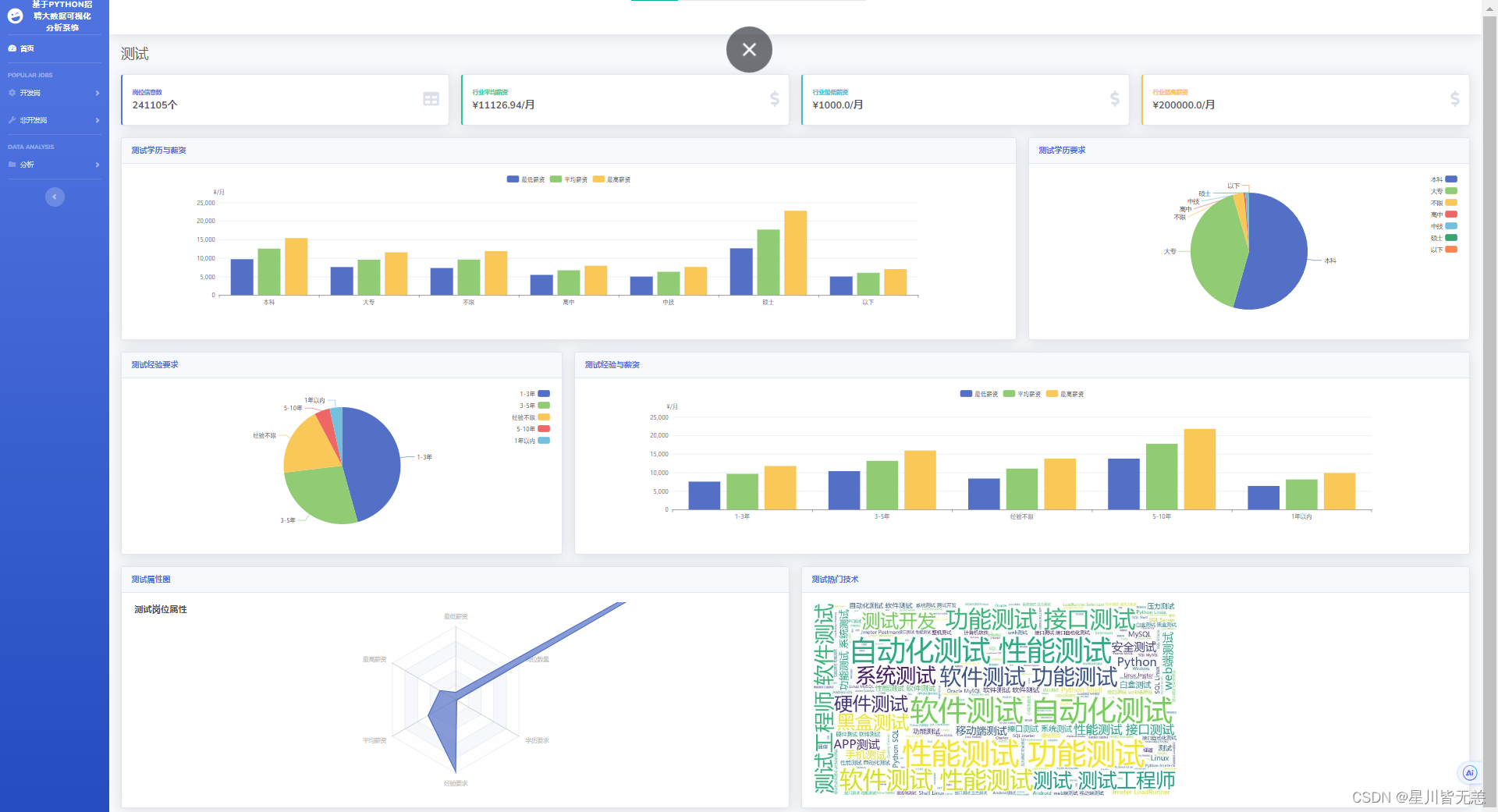
测试方面
招聘岗位薪资多维度精准预测

招聘岗位分析推荐
结语
后面有时间和精力也会分享更多关于大数据领域方面的优质项目内容,感谢各位的喜欢与支持!











![洛谷 P1038 [NOIP2003 提高组] 神经网络【拓扑序处理】](https://img-blog.csdnimg.cn/direct/0a150c24221d4acdb6504192d142b0cd.png)