接着上文写
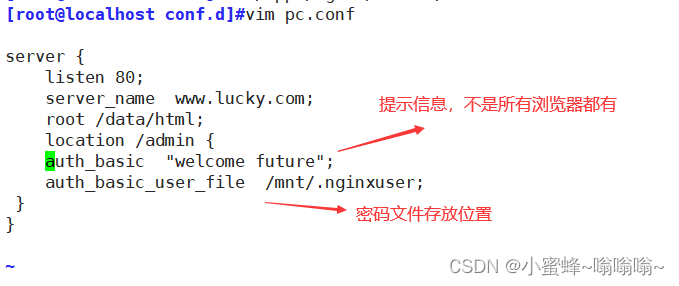
5.4.7 验证模块 需要输入用户名和密码
模块名称:ngx_http_auth_basic_module
访问控制基于模块 ngx_http_auth_basic_module 实现,可以通过匹配客户端资源进行限制
语法:
Syntax: auth_basic string | off;
Default:
auth_basic off;
Context: http, server, location, 1imit_exceptSyntax: auth_basic_user_file file;
Default: _
Context: http, server, location, 1imit_excepthtpasswd
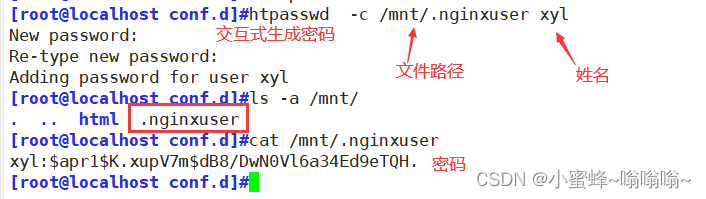
用此命令生成用户密码文件
此命令来自于 httpd-tools 包,如果没有安装 一下即可
第一次生成文件
htpasswd -c 文件路径 姓名 交互式生成密码
htpasswd -bc 文件路径 姓名 密码 直接将密码跟在后面 -c 代表新建用户名和密码对应的文件
-b 将密码跟在用户名后非第一次
htpasswd 文件路径 姓名 交互式生成密码
htpasswd -b 文件路径 姓名 密码 直接将密码跟在后面先安装 httpd


谷歌浏览器查看:
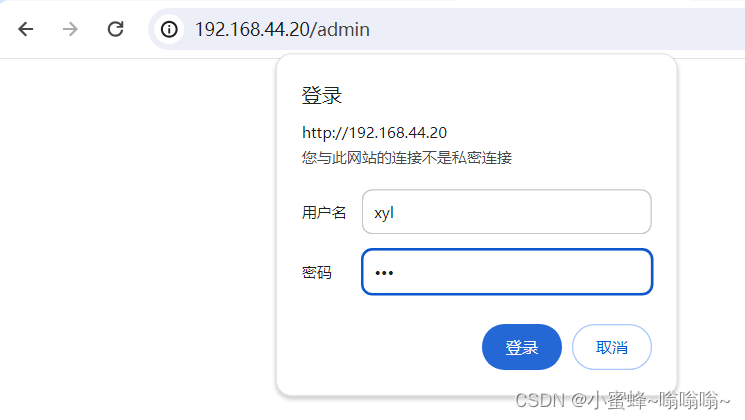

由于浏览器的差异,有的内容不支持,下面去火狐浏览查看
使用另一种方式

浏览器查看:
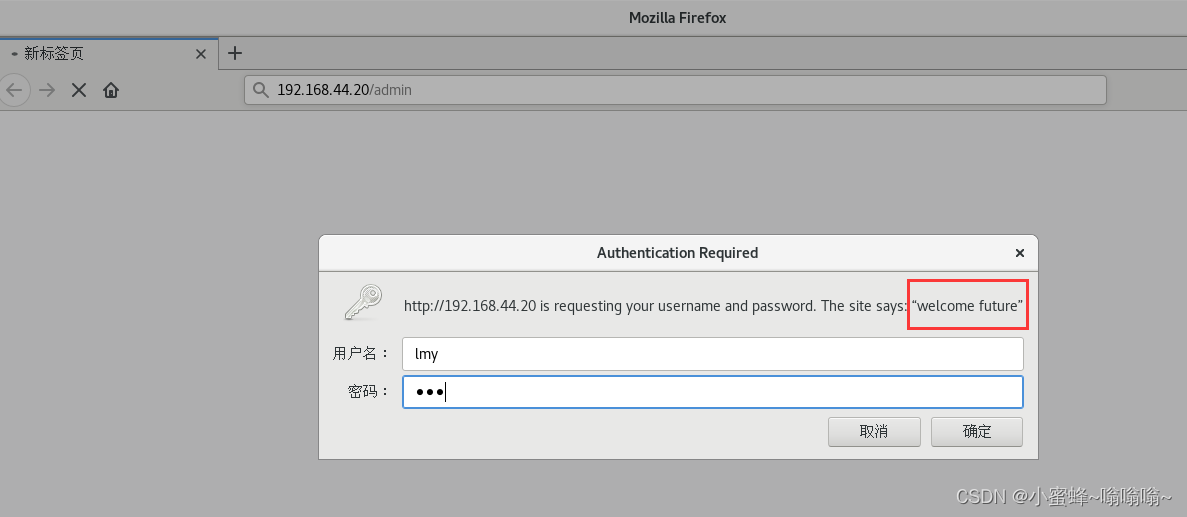
5.4.8 自定义错误的页面
我们可以改变默认的错误页面,同时也可以用指定的响应状态码进行响应, 可用位置:http, server, location, if in location
Syntax: error_page code ... [=[response]] uri;
Default: _
Context: http,server,location,if in locationerror_page 固定关键字
code 响应码(404 403 等)
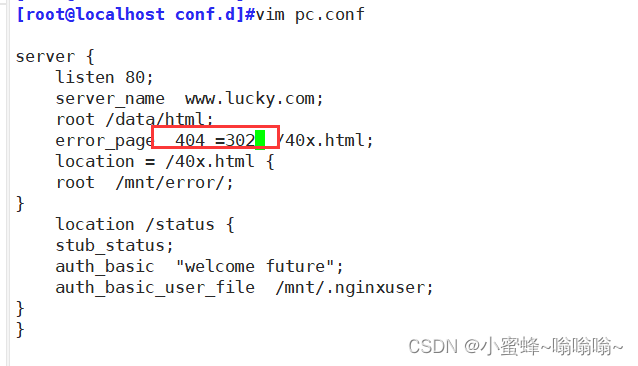
= 可以将响应码转换
uri 访问连接
默认错误页面 404 报错
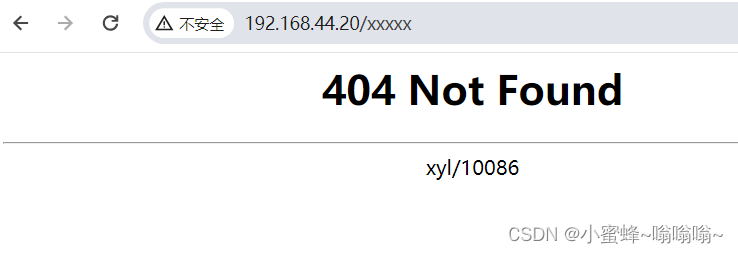
自定义页面:
① 错误了直接跳转到主页面
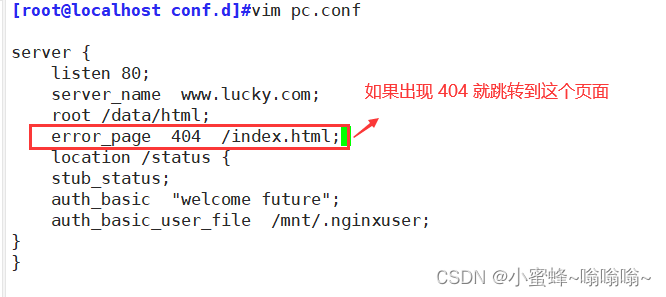
没有再显示404报错,而是跳转到了我们规定的页面

② 精确页面
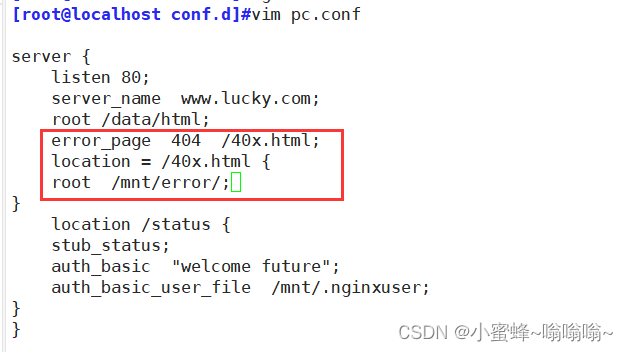
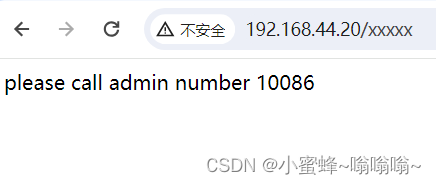
页面显示:
③ 我们可以指定状态码,防止劫持
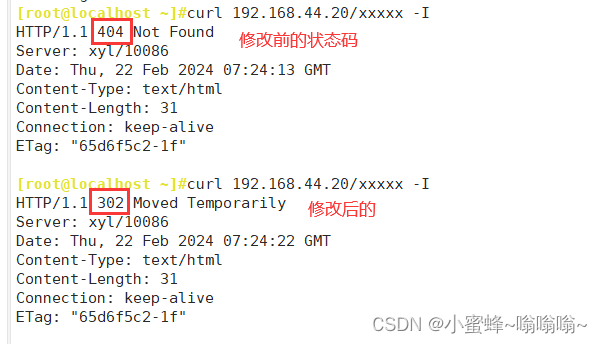
5.4.9 日志的存放位置
Syntax: error_log file [level];Default:
error_log logs/error.log error;
Context: main, http, mail, stream, server, location
level: debug, info, notice, warn, error, crit, alert, emergerror_log /apps/nginx/logs/xxx_error.log;
固定格式 文件路径 级别(info debug等 可以忽略不写)将两个网站的日志分离
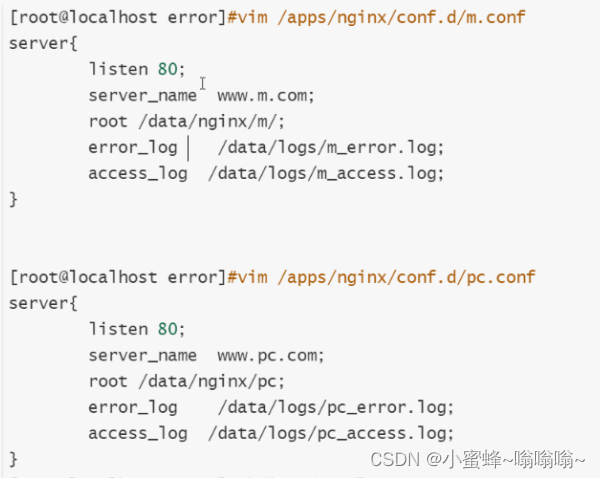
自定义错误日志的位置
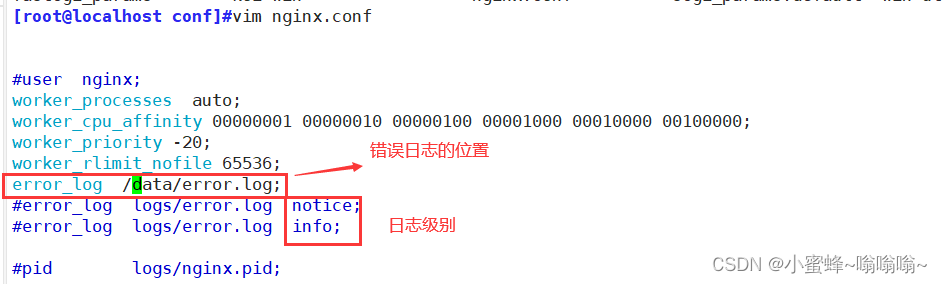


查看错误日志:
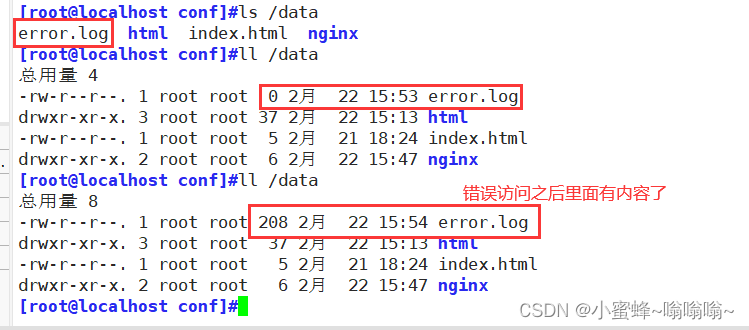
5.4.10 检测文件是否存在
try_files 会按顺序检查文件是否存在,返回第一个找到的文件或文件夹(结尾加斜线表示为文件夹),如果所有文件或文件夹都找不到,会进行一个内部重定向到最后一个参数。只有最后一个参数可以引起一个内部重定向,之前的参数只设置内部 URI 的指向。最后一个参数是回退URI且必须存在,否则会出现内部500错误。
语法格式:
Syntax: try_files file ... uri;
try_files file ... =code;
Default: —
Context: server, location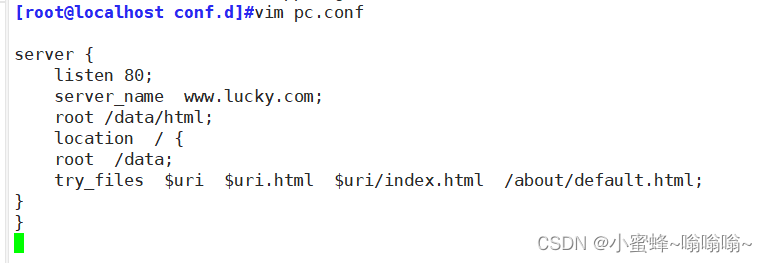
server {listen 80;server_name www.lucky.com;root /data/html;location / {root /data;try_files $uri $uri.html $uri/index.html /about/default.html;
}
}

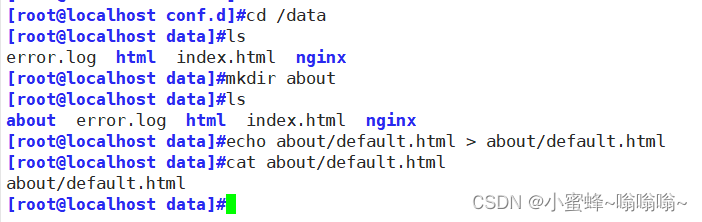
当不存在的时候,有托底页面

如果存在,就正常显示

5.4.11 长连接
keepalive_timeout timeout [header timeout];
#设定保持连接超时时长,0表示禁止长连接,默认为65s,通常配置在http字段作为站点全局配置keepalive_requests number;
#在一次长连接上所允许请求的资源的最大数量,默认为100次,建议适当调大,比如:500可以加在全局或者 server案例:
keepalive_requests 3;
#最大下载三个资源就会断开keepalive_timeout 60 65: #只能有一个空格
#开启长连接后,返回客户端的会话保持时间为60s,单次长连接累计请求达到指定次数请求或65秒就会被断开,后面的60为发送给客户端应答报文头部中显示的超时时间设置为60s:如不设置客户端将不显示超时时间。Keep-Alive:timeout=60 #浏览器收到的服务器返回的报文#如果设置为0表示关闭会话保持功能,将如下显示:
Connection:close #浏览器收到的服务器返回的报文默认开启

keepalive_disable none | browser ...;
#对哪种浏览器禁用长连接5.4.12 作为下载服务器配置
ngx_http_autoindex_module 模块处理以斜杠字符 "/" 结尾的请求,并生成目录列表,可以做为下载服务
小插曲:
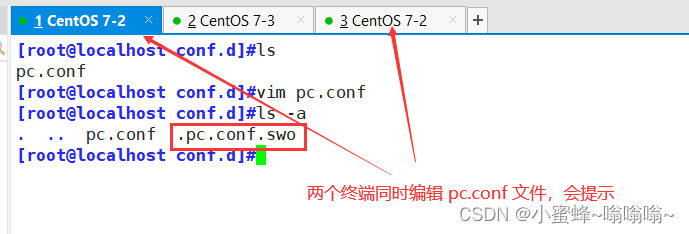
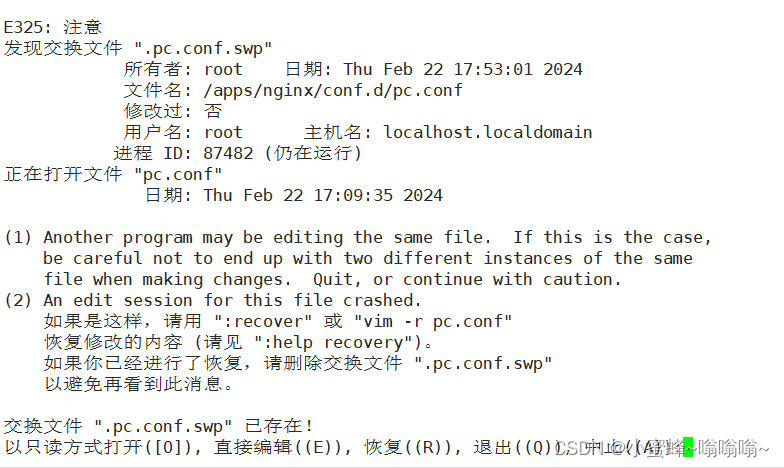
删掉此文件或者不管直接按 ENTER 进入,这是一个缓存文件
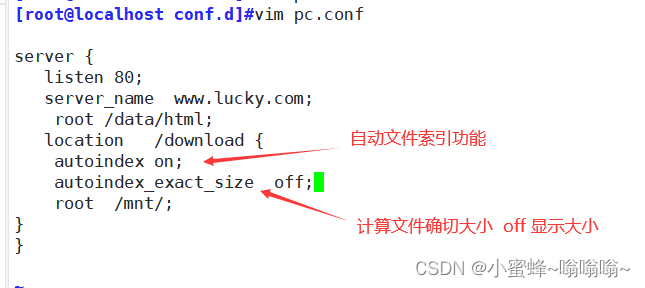
配置:

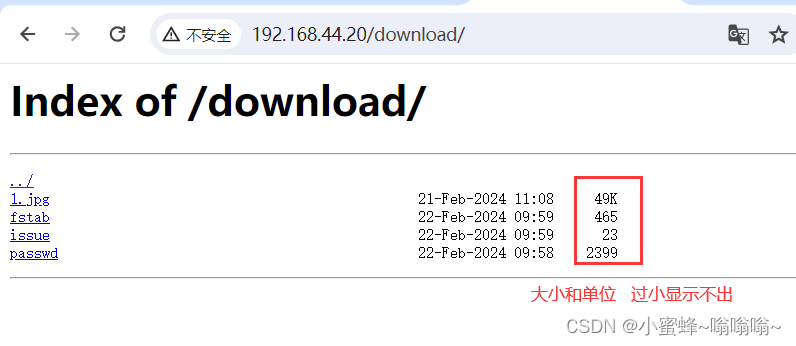
显示:
一些其它命令:
[root@localhost nginx-1.18.0]#./configure --help |grep auto
#自带--without-http_autoindex_module disable ngx_http_autoindex_moduleautoindex on | off;
#自动文件索引功能,默为offautoindex_exact_size on | off;
#计算文件确切大小(单位bytes),off 显示大概大小(单位K、M),默认onautoindex_localtime on | off ;
#显示本机时间而非GMT(格林威治)时间,默认offautoindex_format html | xml | json | jsonp;
#显示索引的页面文件风格,默认htmllimit_rate rate;
#限制响应客户端传输速率(除GET和HEAD以外的所有方法),单位B/s,即bytes/second,默认值0,表示无限制,此指令由ngx_http_core_module提供set $limit_rate
#变量提供 限制 变量优先级高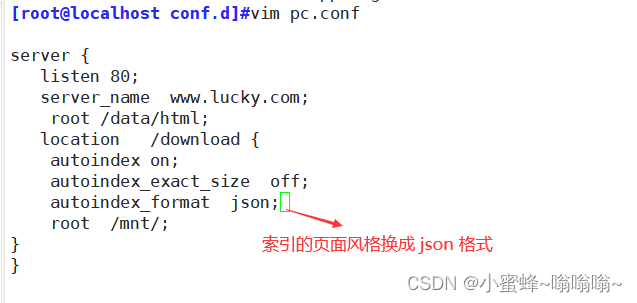
看到 json 格式的画面
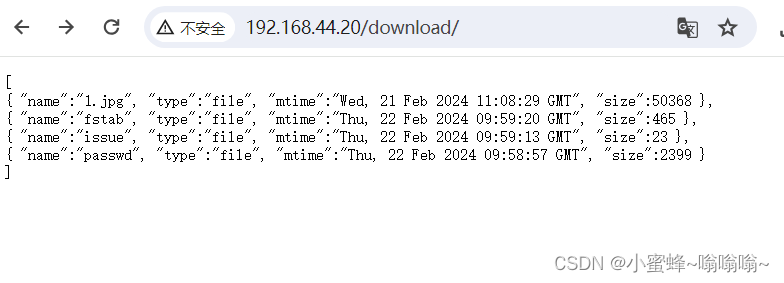
5.4.13 用户上传资料
上传需要借助开发小的程序, 并且程序 5M 和 nginx 10M 都会限制。 两者取最小
client_max_body_size 1m;
#设置允许客户端上传单个文件的最大值,默认值为1m,上传文件超过此值会出413错误client_body_buffer_size size;
#用于接收每个客户端请求报文的body部分的缓冲区大小;默认16k;超出此大小时,其将被暂存到磁盘上的由下面client_body_temp_path
#指令所定义的位置client_body_temp_path path [level1 [level2 [level3]]];
#设定存储客户端请求报文的body部分的临时存储路径及子目录结构和数量,目录名为16进制的数字,使用hash之后的值从后往前截取1位、2位、2位作为目录名5.4.14 其他设置
directio size | off;
#操作完全和aio相反,aio是读取文件而directio是写文件到磁盘,启用直接I/O,默认为关闭,当文件大于等于给定大小时,例如:directio 4m;同步(直接)写磁盘,而非写缓存。open_file_cache off; #是否缓存打开过的文件信息open_file_cache max=N [inactive=time];
#nginx可以缓存以下三种信息:
(1) 文件元数据:文件的描述符、文件大小和最近一次的修改时间
(2) 打开的目录结构
(3) 没有找到的或者没有权限访问的文件的相关信息
max=N:#可缓存的缓存项上限数量;达到上限后会使用LRU(Least recently used,最近最少使用)算法实现管理
inactive=time:#缓存项的非活动时长,在此处指定的时长内未被命中的或命中的次数少于open_file_cache_min_uses
#指令所指定的次数的缓存项即为非活动项,将被删除open_file_cache_valid time;
#缓存项有效性的检查验证频率,默认值为60s open_file_cache_errors on | off;
#是否缓存查找时发生错误的文件一类的信息,默认值为offopen_file_cache_min_uses number;
#open_file_cache指令的inactive参数指定的时长内,至少被命中此处指定的次数方可被归类为活动项,默认值为1示例:
open_file_cache max=10000 inactive=60s;
#最大缓存10000个文件,非活动数据超时时长60sopen_file_cache_valid 60s;
#每间隔60s检查一下缓存数据有效性open_file_cache_min_uses 5;
#60秒内至少被命中访问5次才被标记为活动数据open_file_cache_errors on;
#缓存错误信息limit_except method ... { ... },仅用于location
#限制客户端使用除了指定的请求方法之外的其它方法
method:GET, HEAD, POST, PUT, DELETE,MKCOL, COPY, MOVE, OPTIONS, PROPFIND,
PROPPATCH, LOCK, UNLOCK, PATCHlimit_except GET {allow 192.168.44.20;deny all;
}
#允许 192.168.44.20主机下载,其他都拒绝limit_except GET {
allow 192.168.44.20;
deny all;
}
#允许 192.168.44.20主机下载,其他都拒绝
六.高级配置
6.1 网页的状态页
基于nginx 模块 ngx_http_stub_status_module 实现,在编译安装nginx的时候需要添加编译参数 --with-http_stub_status_module,否则配置完成之后监测会是提示语法错误注意: 状态页显示的是整个服务器的状态,而非虚拟主机的状态。
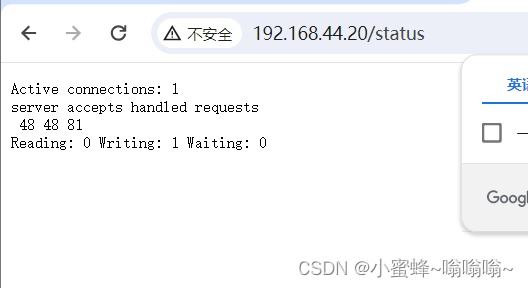
状态页用于输出 nginx 的基本状态信息
Active connections:
#当前处于活动状态的客户端连接数,包括连接等待空闲连接数=reading+writing+waiting
accepts:
#统计总值,Nginx自启动后已经接受的客户端请求的总数。
handled:
#统计总值,Nginx自启动后已经处理完成的客户端请求总数,通常等于accepts,除非有因worker_connections限制等被拒绝的连接
requests:
#统计总值,Nginx自启动后客户端发来的总的请求数。
Reading:
#当前状态,正在读取客户端请求报文首部的连接的连接数,数值越大,说明排队现象严重,性能不足
Writing:
#当前状态,正在向客户端发送响应报文过程中的连接数,数值越大,说明访问量很大
Waiting:
#当前状态,正在等待客户端发出请求的空闲连接数,开启 keep-alive的情况下,这个值等于active – (reading+writing)可以只提取里面的基本状态的数字
[root@localhost conf.d]#curl 192.168.44.20/status 2>/dev/null|awk '/Reading/{print $2,$4,$6}'
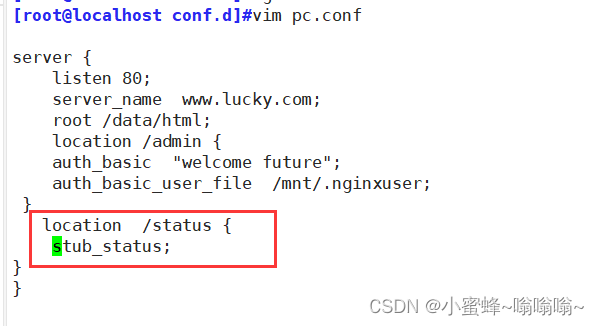
为了安全考虑,可以搭配验证模块一起使用
server {listen 80;server_name www.lucky.com;root /data/html;location /status {stub_status;auth_basic "welcome future";auth_basic_user_file /mnt/.nginxuser;} }
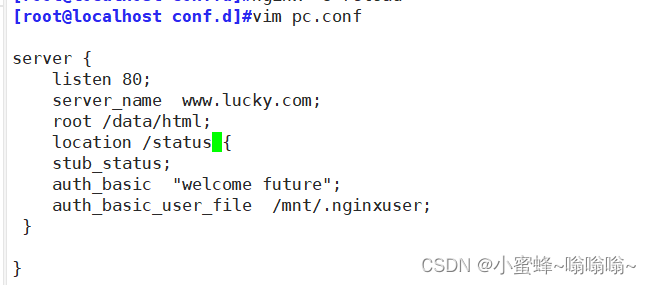


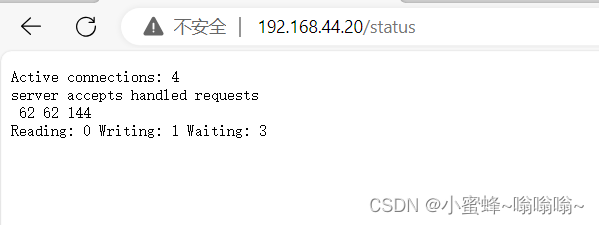
再想提取的时候
[root@localhost conf.d]#curl http://lmy:123@192.168.44.20/status 2>/dev/null |awk '/Reading/{print $2,$4,$6}'


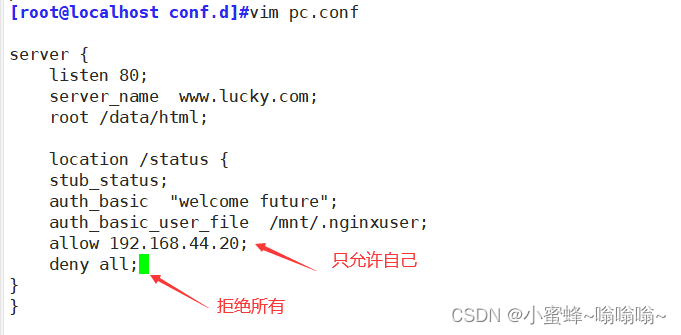
最终升级版
server {listen 80;server_name www.lucky.com;root /data/html;location /status {stub_status;auth_basic "welcome future";auth_basic_user_file /mnt/.nginxuser;allow 192.168.44.20;deny all;
}
}
6.2 nginx 第三方模块
6.2.1 echo模块
编译之前,先关闭 nginx,导入压缩包,并解压。
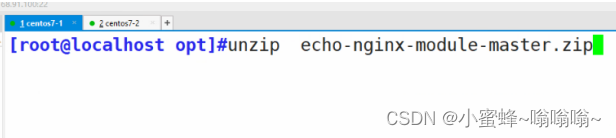
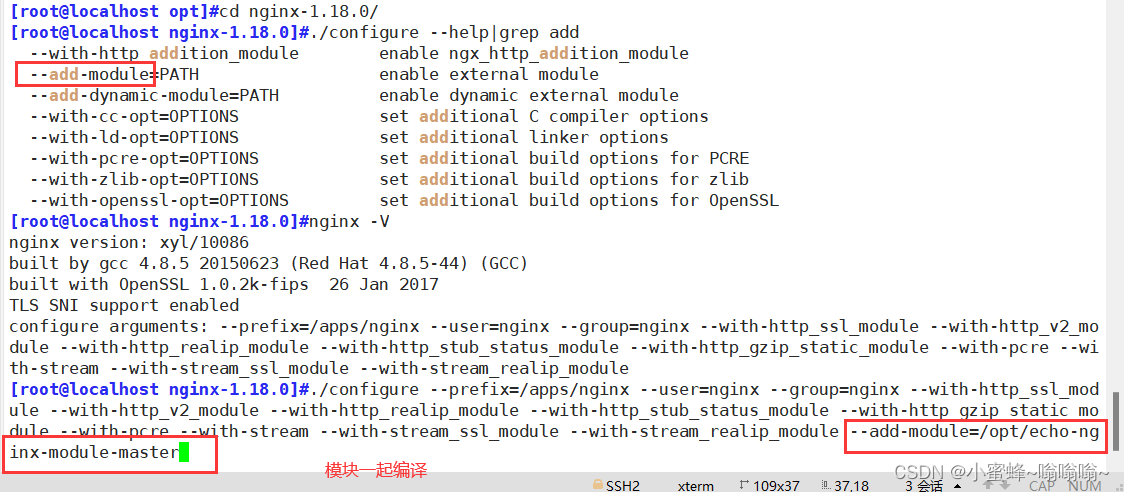
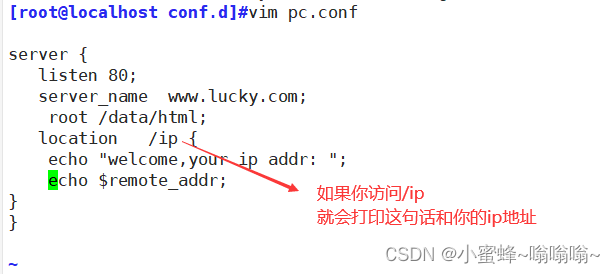


6.3 变量
官方文档 http://nginx.org/en/docs/varindex.html
6.3.1 内置变量
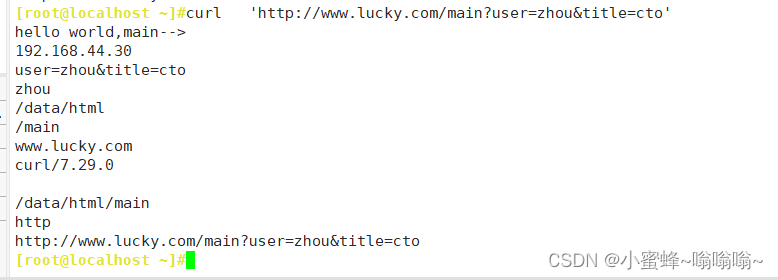
| $remote_addr; | 存放了客户端的地址,注意是客户端的公网IP |
| $args; | 变量中存放了URL中的参数 |
| $document_root; | 保存了针对当前资源的请求的系统根目录 |
| $document_uri; | 保存了当前请求中不包含参数的URI,注意是不包含请求的指令 |
| $host; | 存放了请求的host名称 服务端的地址 |
| $request_filename; | 当前请求的资源文件的磁盘路径,由root或alias指令与URI请求生成的文件绝对路径 |
| $scheme; | 请求的协议,例如:http,https,ftp等 |
| $http_user_agent; | 客户端浏览器的详细信息 |
| $http_cookie; | 客户端的cookie信息 |
$remote_addr;
#存放了客户端的地址,注意是客户端的公网IP$proxy_add_x_forwarded_for
#此变量表示将客户端IP追加请求报文中X-Forwarded-For首部字段,多个IP之间用逗号分隔,如果请求中没有X-Forwarded-For,就使用$remote_addrthe “X-Forwarded-For” client request header field with the $remote_addr variable appended to it, separated by a comma. If the “X-Forwarded-For” field is not present in the client request header, the $proxy_add_x_forwarded_for variable is equal to the $remote_addr variable.
客户机 代理1 代理2 nginx服务器
$proxy_add_x_forwarded_for: 在代理1 上存的是 客户机的ip
$proxy_add_x_forwarded_for: 在代理2 上存的是 客户机的ip,代理1的ip 用逗号隔开
$proxy_add_x_forwarded_for: nginx 上存的是 客户机的ip,代理1的ip,代理2的ip$args;
#变量中存放了URL中的参数,例如:http://www.kgc.org/main/index.do?id=20190221&partner=search
#返回结果为: id=20190221&partner=search 存放的就是这个select * from table where id=20190221$document_root;
#保存了针对当前资源的请求的系统根目录,例如:/apps/nginx/html$document_uri;
#保存了当前请求中不包含参数的URI,注意是不包含请求的指令,比
如:http://www.kgc.org/main/index.do?id=20190221&partner=search会被定义为/main/index.do
#返回结果为:/main/index.do$host;
#存放了请求的host名称
服务端的地址limit_rate 10240;
echo $limit_rate;
#如果nginx服务器使用limit_rate配置了显示网络速率,则会显示,如果没有设置, 则显示0$remote_port;
#客户端请求Nginx服务器时随机打开的端口,这是每个客户端自己的端口$remote_user;
#已经经过Auth Basic Module验证的用户名$request_body_file;
#做反向代理时发给后端服务器的本地资源的名称$request_method;
#请求资源的方式,GET/PUT/DELETE等$request_filename;
#当前请求的资源文件的磁盘路径,由root或alias指令与URI请求生成的文件绝对路径,如:/apps/nginx/html/main/index.html$request_uri; https:// www.baidu.com/main/index.do?id=20190221&partner=search
#包含请求参数的原始URI,不包含主机名,相当于:$document_uri?$args,例如:/main/index.do?id=20190221&partner=search $scheme;
#请求的协议,例如:http,https,ftp等$server_protocol;
#保存了客户端请求资源使用的协议的版本,例如:HTTP/1.0,HTTP/1.1,HTTP/2.0等$server_addr;
#保存了服务器的IP地址$server_name;
#请求的服务器的主机名$server_port; 443 https
#请求的服务器的端口号$http_<name>
#name为任意请求报文首部字段,表示记录请求报文的首部字段
arbitrary request header field; the last part of a variable name is the field name converted to lower case with dashes replaced by underscores
#用下划线代替横线
#示例: echo $http_User_Agent; $http_user_agent;
#客户端浏览器的详细信息$http_cookie;
#客户端的cookie信息$cookie_<name>
#name为任意请求报文首部字部cookie的key名$http_<name>
#name为任意请求报文首部字段,表示记录请求报文的首部字段,ame的对应的首部字段名需要为小写,如果有
横线需要替换为下划线
arbitrary request header field; the last part of a variable name is the field
name converted to lower case with dashes replaced by underscores #用下划线代替横线
#示例:
echo $http_user_agent;
echo $http_host;$sent_http_<name>
#name为响应报文的首部字段,name的对应的首部字段名需要为小写,如果有横线需要替换为下划线,此变量有问题
echo $sent_http_server;$arg_<name>
#此变量存放了URL中的指定参数,name为请求url中指定的参数
#对比 变量 $arg 是全部, 如果 要id 如下
echo $arg_id;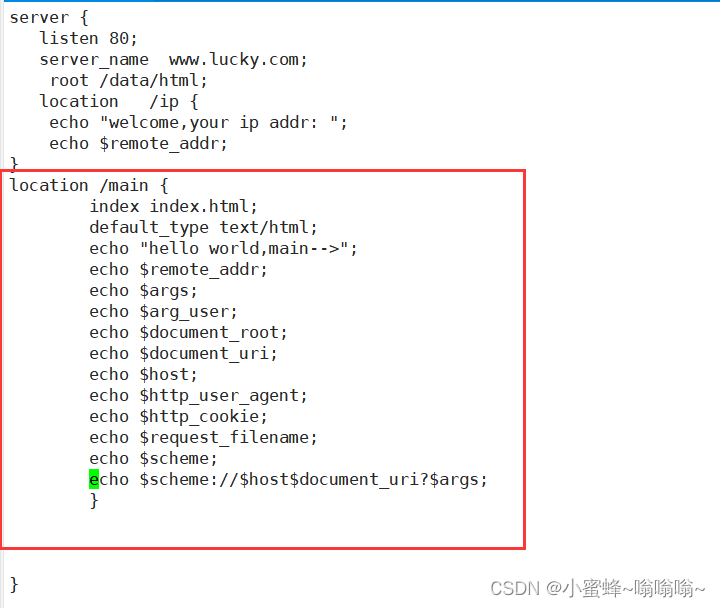
6.3.2 自定义变量
假如需要自定义变量名称和值,使用指令 set $variable value;
语法格式:
Syntax: set $variable value;
Default: —
Context: server, location, if location /test {set $name xyl;echo $name;set $my_port $server_port;echo $my_port;
}
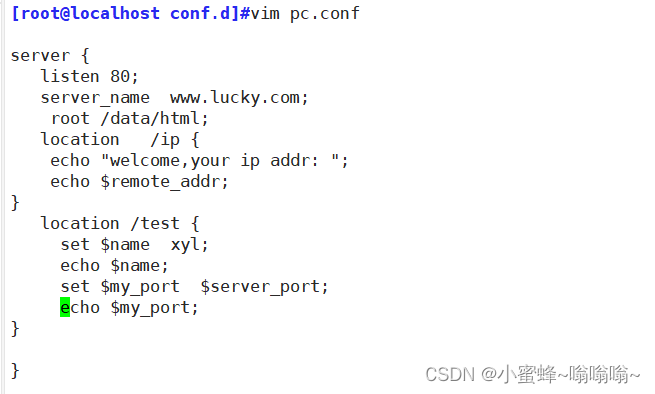

6.4 自定义图标
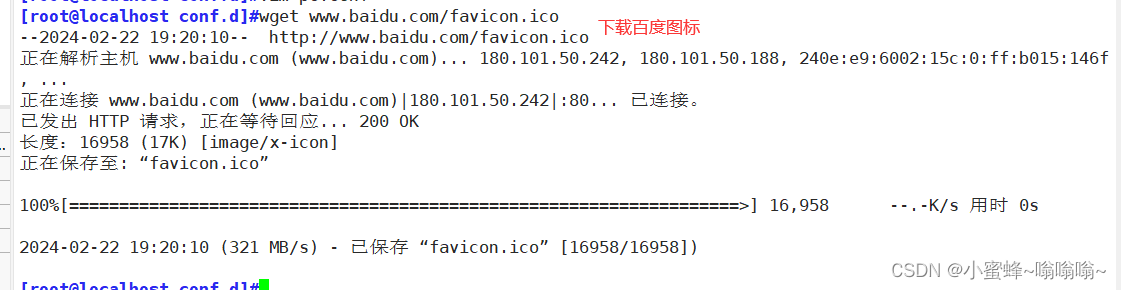
favicon.ico 文件是浏览器收藏网址时显示的图标,当客户端使用浏览器问页面时,浏览器会自己主动发起请求获取页面的favicon.ico文件,但是当浏览器请求的 favicon.ico 文件不存在时,服务器会记录404日志,而且浏览器也会显示404报错。

6.5 自定义访问日志
6.5.1 日志的格式可以指定
访问日志是记录客户端即用户的具体请求内容信息,而在全局配置模块中的 error log 是记录 nginx服务器运行时的日志保存路径和记录日志的 level,因此两者是不同的,而且Nginx的错误日志一般只有一个,但是访问日志可以在不同 server 中定义多个,定义一个日志需要使用 access_log 指定日志的保存路径,使用 log_format 指定日志的格式,格式中定义要保存的具体日志内容。
访问日志由 ngx_http_log_module 模块实现
Syntax: access_log path [format [buffer=size] [gzip[=level]] (flush=time] [if=condition]];access_log off;
Defau1t:
access_log 1ogs/access.1og combined;
Context: http,server, location,if in location,limit_exceptlog_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"''$server_name:$server_port';log_format test '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"''$server_name:$server_port';格式可以定义多个###注意如果开启 include 注意定义自配置文件与 日志格式的上下关系 , 日志格式一定要在 include 之前 否则会不生效。
去访问

看日志:

打印日志里面的状态码

6.5.2 自定义 json 格式日志
方便 ELK 收集日志

去访问

json 日志格式

提取状态码:

6.5.3 日志分割
----------------日志切割-------------------
vim /opt/fenge.sh
#!/bin/bash
# Filename: fenge.sh
day=$(date -d "-1 day" "+%Y%m%d") #显示前一天的时间
logs_path="/var/log/nginx"
pid_path="/usr/local/nginx/logs/nginx.pid"
[ -d $logs_path ] || mkdir -p $logs_path #创建日志文件目录
mv /usr/local/nginx/logs/access.log ${logs_path}/kgc.com-access.log-$day #移动并重命名日志文件
kill -USR1 $(cat $pid_path) #重建新日志文件
find $logs_path -mtime +30 -exec rm -rf {} \; #删除30天之前的日志文件
#find $logs_path -mtime +30 | xargs rm -rf chmod +x /opt/fenge.sh
/opt/fenge.sh
ls /var/log/nginx
ls /usr/local/nginx/logs/access.log #设置周期计划任务
crontab -e
0 1 * * * /opt/fenge.sh6.6 nginx 压缩功能
支持对指定类型的文件进行压缩然后再传输给客户端,而且压缩还可以设置压缩比例,压缩后的文件大小将比源文件显著变小,这样有助于降低出口带宽的利用率,降低企业的IT支出,不过会占用相应的CPU资源。Nginx对文件的压缩功能是依赖于模块 ngx_http_gzip_module
#启用或禁用gzip压缩,默认关闭
gzip on | off; #压缩比由低到高从1到9,默认为1
gzip_comp_level level;#禁用IE6 gzip功能
gzip_disable "MSIE [1-6]\."; #gzip压缩的最小文件,小于设置值的文件将不会压缩
gzip_min_length 1k; #启用压缩功能时,协议的最小版本,默认HTTP/1.1
gzip_http_version 1.0 | 1.1; #指定Nginx服务需要向服务器申请的缓存空间的个数和大小,平台不同,默认:32 4k或者16 8k;
gzip_buffers number size; #指明仅对哪些类型的资源执行压缩操作;默认为gzip_types text/html,不用显示指定,否则出错
gzip_types mime-type ...; #如果启用压缩,是否在响应报文首部插入“Vary: Accept-Encoding”,一般建议打开
gzip_vary on | off;#预压缩,先压缩好,不用临时压缩,消耗cpu
gzip_static on | off;
6.6.1 实际操作
太小的文件没必要压缩,压缩说不定变大了
制造一个大文件:

写配置:

压缩前:

压缩后:

要看状态码,如果不是200,需要强制刷新

6.6.2 预压缩
gzip_static on | off 预压缩,先压缩好,不用临时压缩,消耗cpu





该文件夹内,此文件和压缩包可以共存,修改修改的时候,可以直接修改文件,再进行压缩。
6.7 https 功能
Web 网站的登录页面都是使用 https 加密传输的,加密数据以保障数据的安全,HTTPS 能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议,HTTPS其实是有两部分组成:HTTP + SSL / TLS,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。

过程:
1.客户端发起HTTPS请求
用户在浏览器里输入一个 https 网址,然后连接到服务器的 443 端口
2.服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请,区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥
3.传送服务器的证书给客户端
证书里其实就是公钥,并且还包含了很多信息,如证书的颁发机构,过期时间等等
4.客户端解析验证服务器证书
这部分工作是由客户端的TLS来完成的,首先会验证公钥是否有效,比如:颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框提示证书存在问题。如果证书没有问题,那么就生成一个随机值,然后用证书中公钥对该随机值进行非对称加密
5.客户端将加密信息传送服务器
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加感解密了
6. 服务端解密信息
服务端将客户端发送过来的加密信息用服务器私钥解密后,得到了客户端传过来的随机值
7.服务器加密信息并发送信息
服务器将数据利用随机值进行对称加密,再发送给客户端
8.客户端接收并解密信息
客户端用之前生成的随机值解密服务段传过来的数据,于是获取了解密后的内容
nginx 的 https 功能基于模块 ngx_http_ssl_module 实现,因此如果是编译安装的nginx要使用参数 ngx_http_ssl_module 开启 ssl 功能,但是作为 nginx 的核心功能,yum安装的 nginx 默认就是开启的,编译安装的nginx需要指定编译参数 --with-http_ssl_module 开启
ssl on | off;
#为指定的虚拟主机配置是否启用ssl功能,此功能在1.15.0废弃,使用listen [ssl]替代
listen 443 ssl;ssl_certificate /path/to/file;
#指向包含当前虚拟主机和CA的两个证书信息的文件,一般是crt文件ssl_certificate_key /path/to/file;
#当前虚拟主机使用的私钥文件,一般是key文件ssl_protocols [SSLv2] [SSLv3] [TLSv1] [TLSv1.1] [TLSv1.2];
#支持ssl协议版本,早期为ssl现在是TLS,默认为后三个ssl_session_cache off | none | [builtin[:size]] [shared:name:size];
#配置ssl缓存off: #关闭缓存none: #通知客户端支持ssl session cache,但实际不支持builtin[:size]:#使用OpenSSL内建缓存,为每worker进程私有[shared:name:size]:#在各worker之间使用一个共享的缓存,需要定义一个缓存名称和缓存空间大小,一兆可以存储4000个会话信息,多个虚拟主机可以使用相同的缓存名称ssl_session_timeout time;
#客户端连接可以复用ssl session cache中缓存的有效时长,默认5m编译安装的nginx需要指定编译参数 --with-http_ssl_module 开启







![Unicode转换 [ASIS 2019]Unicorn shop1](https://img-blog.csdnimg.cn/direct/680cd82a7d1e459db8d6d97b93339d24.png)