目录
- 简介
- 1 模型
- 2 特征
- 3 索引
- 4 全链路优化
简介
个人的随笔,读者需要基本了解IR领域的基本知识和概念,本文主要记录了我觉得该工作一些重要的点。和大家共勉。
1 模型
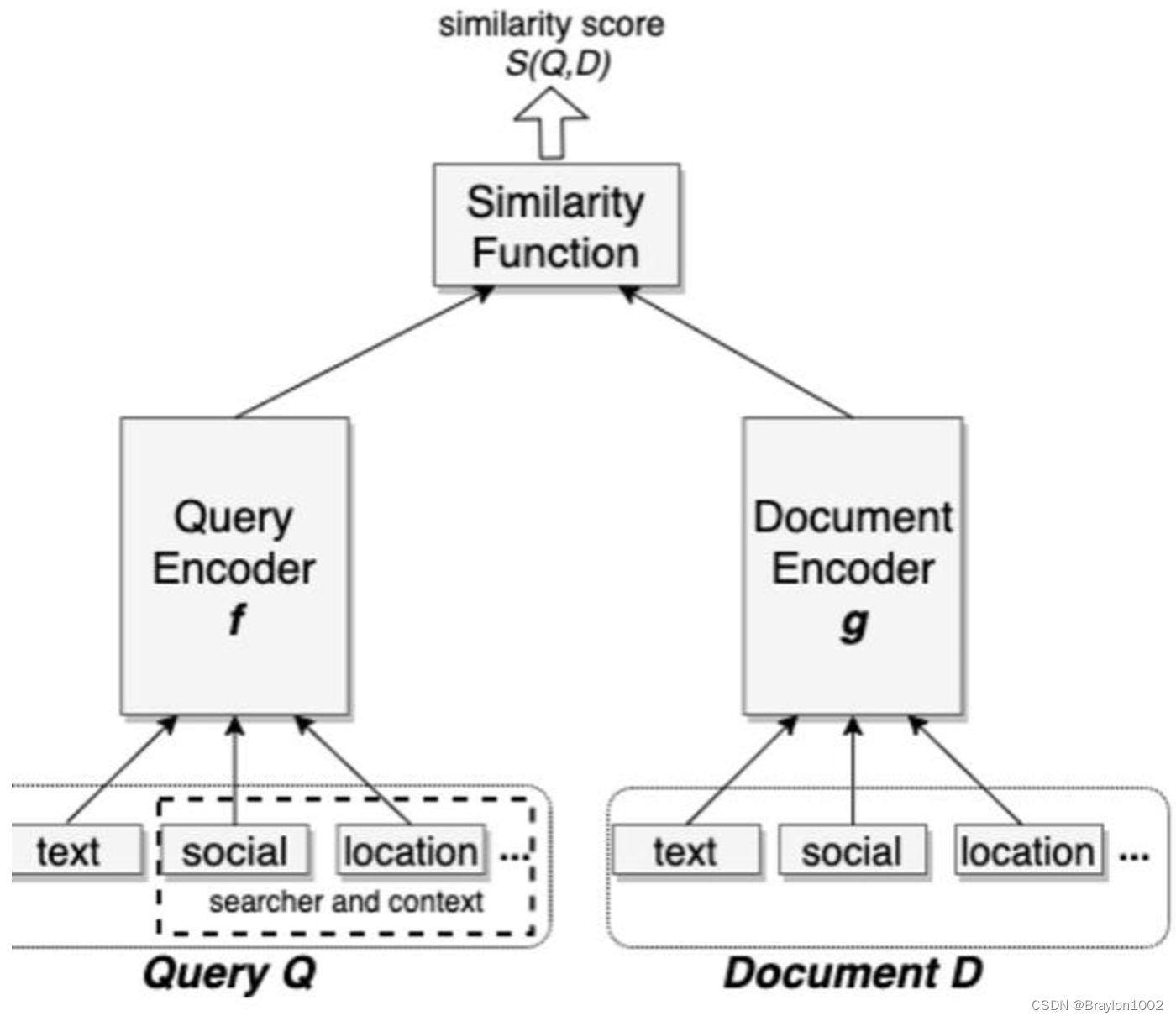
标准的双塔结构
1.1 损失函数
搜索相关性以pair-wise的形式进行建模,选择的是Triple loss形式:
loss = max(0, sim(u, x_pos) - sim(u, x_neg) + M)
1.2 正负样本选择
结论:
【正样本】点击样本>展现样本
这里衡量的是对模型影响力
【负样本】随机负采样>曝光未点击
召回阶段固然曝光未点击一定是负样本,但是召回的最重要任务是保证分布接近线上的样本分布,所以要让模型“见见世面”,故负采样更重要。
- hard negative mining
随机负采样会导致样本学习过于简单,虽然这样对模型是有正向影响的,不过需要套让模型感受到世界的参差。
作者提出两种
online:在线一般是batch内其他用户的正例当作负例池随机采,本文提到选相似度最高的作为hard样本,同时强调了最多不能超过两个hard样本。
offline:考虑到在线batch的容量太小,在离线阶段可以从全量池子里选择。做法是对每个query的Top-k结果利用hard selection strategy找到hard样本,并重复上述过程。作者提到要从101-500个中进行采集,太靠前也许根本不是负例。另外还有两个经验性的结论:(1)easy: hard = 100: 1 (2)先训练easy再训练hard 效果< 先训练hard再训练easy
- hard positive mining
作者认为用户点击没有点击但是也可以被认为是正样本,做法是从日志中发掘潜在的正样本,例如可能top1-10就是潜在正样本了
1.3 模型融合

2 特征
文本特征:
word n-gram和character n-gram,character级别更好,也是因为character词表更小,训练也更充分,也更容易泛化,本文提到在character基础上增加word表征能提升效果。
location features:位置编码已经被证明非常有效和必要,其中注意doc和query端都要增加这个特征。
social embedding features:
通过单独的嵌入模型学习社交表征emd作为特征,构建方法很多,比如deepwalk。
3 索引
本文主要提到了比如ivf、PQ等关键词,这里简单介绍一下,Int8/float/PQ是常见的量化方法,主要目的是降低内存带宽和存储空间;而IVF/BF/HNSW则是检索算法,目的是提高检索的速度和精度。我们当然是希望存储小精度高,但这往往是相反的,所以根据自己候选量+精度对推荐效果的影响权衡一下,本文也提到了一些trick,比如聚簇个数、product quantization算法选择等问题,这种serving效果在大厂里工程团队基本都定制优化了,大致了解一下即可。
本文提过但是容易被忽略的一个点在于,全量候选构建索引是非常耗存储和费时的,所以facebook在构建索引的时候,只选择了月活用户、近期/热门的item,即部分query不会触发EBR,推荐场景同理,根据自己的召回目标搞合适的候选往往对于部分分层有奇效。
4 全链路优化
召回的优化方向只有保证全链路的一致性才能发挥最大的作用。
这里有两个小的方案,当然还有很多更优秀的工作有待挖掘和学习:
- 将embedding作为排序模型的特征。如果不太了解思想的可以读一下《Deep Match to Rank Model for Personalized Click-Through Rate Prediction》,简单来讲就是给排序模型透穿召回信息,同理给召回透传排序的信息提升排出率也是常规操作。至于这里具体是怎么做的没有太详细的讲,常见的问题比如end2end还是拆开、多目标排序怎么搞、多路召回怎么透传都可以根据自己的系统架构设计。
- 训练数据反馈循环。 向量表征一般召回率不错但是精度一般, 为了提高精度,本文搞了一个人工评分反馈流程, 记录结果并后将这些结果发送给运营标记是否相关,在原本的基础上叠加这些人工评分数据来重新训练相关性模型。这个也很好理解,相当于补充了一些更准的训练数据,当然现实里有没有这么多人力去搞,推荐问题有没有搜索相关性这么好定义label就是另一回事了


![Unicode转换 [ASIS 2019]Unicorn shop1](https://img-blog.csdnimg.cn/direct/680cd82a7d1e459db8d6d97b93339d24.png)


![命令执行 [网鼎杯 2020 朱雀组]Nmap1](https://img-blog.csdnimg.cn/direct/b10ca899c2124f93aa76875b6bc7f331.png)