TCP丢失的消息会一直重传吗?说一下TCP的超时重传策略是啥?
造成消息丢失和超时重传的场景有以下两种:
- 发送消息时丢失
- ACK确认消息发送丢失
无论哪种情况,TCP不会一直重传丢失的消息,因为这样如果对方真正的下线,会造成系统资源浪费。所以TCP设计了两种重传策略:
- 动态重传时间:每次传递时间翻倍,例如第一次1s,第二次2s,第四次4s
- 最大重传次数:TCP如果超过一定的重试次数,那么就会强制断开连接,不会继续重传
什么是TCP粘包问题?如何解决?
TCP粘包和半包是数据传输中比较常见的问题。所谓的粘包问题就是指在数据传输的时候,在一条消息中读取到了另一条消息的部分数据,如下图: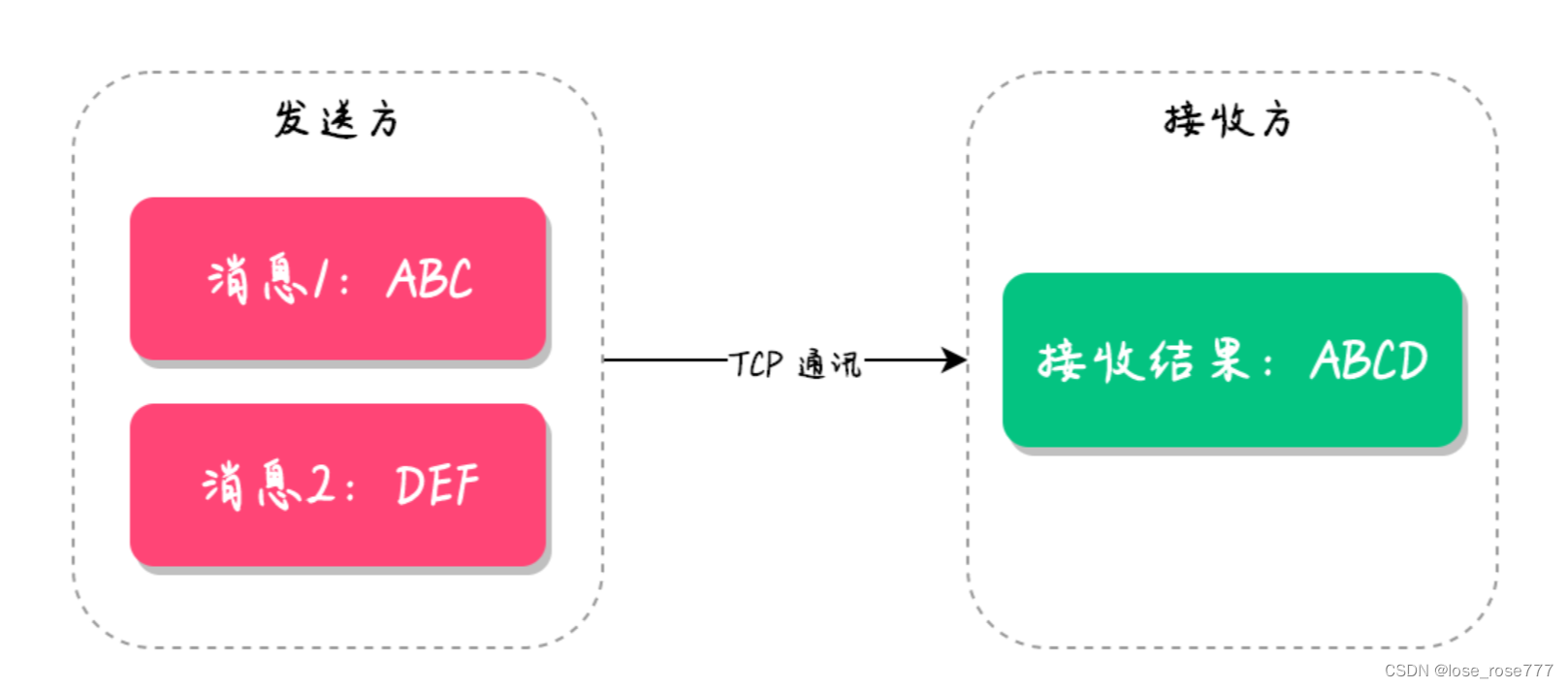
半包是指接收端只收到了部分的数据,而非完整的数据的情况,如下图:
大部分情况下我们都把粘包问题和半包问题看成同一个问题,所以下文就用粘包问题来替代粘包和半包问题
为什么会有粘包问题
粘包问题发生在TCP/IP协议中,因为TCP是面向连接的传输协议,它是以流的形式传输数据的,而流数据是没有明确开始和结尾的边界的,所以就会出现粘包问题
粘包问题演示
接下来我们用代码来演示一下粘包和半包问题,为了演示的直观性,我会设置两个角色:
- 服务器端用来接收消息
- 客户端用来发送一段固定的消息
服务端代码实现:
import java.io.*;
import java.net.*;public class Server {private static final int BYTE_LENGTH = 20;public static void main(String[] args) throws IOException {// 创建 Socket 服务器ServerSocket serverSocket = new ServerSocket(8888);// 获取客户端连接Socket clientSocket = serverSocket.accept();// 得到客户端发送的流对象try (InputStream inputStream = clientSocket.getInputStream()) {while (true) {// 循环获取客户端发送的信息byte[] bytes = new byte[BYTE_LENGTH];// 读取客户端发送的信息int count = inputStream.read(bytes, 0, BYTE_LENGTH);if (count > 0) {// 成功接收到有效消息并打印System.out.println("接收到客户端的信息是:" + new String(bytes, 0, count));}}}}
}
客户端代码实现:
import java.io.*;
import java.net.*;
import java.nio.charset.StandardCharsets;public class Client {public static void main(String[] args) throws IOException {String serverAddress = "127.0.0.1";int port = 8888;try (Socket socket = new Socket(serverAddress, port);PrintWriter out = new PrintWriter(socket.getOutputStream(), true)) {String message = "hello,world";OutputStream outputStream= socket.getOutputStream();for (int i = 0; i < 10; i++) {outputStream.write(message.getBytes());}}}
}程序执行结果:
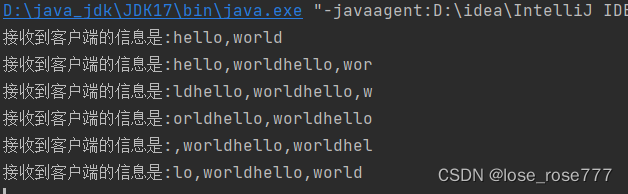
此时我们发现出现了粘包问题,正常应该是直接输出10次hello world 才对
解决方案
粘包问题的常见解决方案有以下三种:
- 固定数据大小:发送方和接收方固定发送消息的大小,当字符长度不够的时候用空字符弥补,有了固定大小就知道每条消息的边界了
- 自定义数据协议(定义数据边界):在TCP协议的基础上封装上一层自定义数据协议,在自定义的数据协议中,包含数据头(存储数据的大小)和数据的具体内容,这样服务端的得到的数据头就可以知道数据的具体长度,也就没有粘包问题
- 以特殊字符结尾:比如以“/n”字符结尾,这样就可以直到数据的具体边界,可以避免粘包问题(推荐使用)
解决方案一:固定数据大小
收、发固定大小的数据,服务端实现代码:
import java.io.*;
import java.net.*;public class Server {private static final int BYTE_LENGTH = 1024;public static void main(String[] args) throws IOException {// 创建 Socket 服务器ServerSocket serverSocket = new ServerSocket(8888);// 获取客户端连接Socket clientSocket = serverSocket.accept();// 得到客户端发送的流对象try (InputStream inputStream = clientSocket.getInputStream()) {while (true) {// 循环获取客户端发送的信息byte[] bytes = new byte[BYTE_LENGTH];// 读取客户端发送的信息int count = inputStream.read(bytes);if (count > 0) {// 成功接收到有效消息并打印System.out.println("接收到客户端的信息是:" + new String(bytes, 0, count));}}}}
}
客户端实现代码:
import java.io.*;
import java.net.*;
import java.nio.charset.StandardCharsets;public class Client {private static final int BYTE_LENGTH = 1024;public static void main(String[] args) throws IOException, InterruptedException {String serverAddress = "127.0.0.1";int port = 8888;String message = "hello,world";try (Socket socket = new Socket(serverAddress, port)) {OutputStream outputStream= socket.getOutputStream();byte[] bytes = new byte[BYTE_LENGTH];int idx= 0;for(byte b:message.getBytes()){bytes[idx]= b;idx++;}for (int i = 0; i < 10; i++) {outputStream.write(bytes,0,BYTE_LENGTH);}}}
}
运行结果:

后面是字符编码的问题
优缺点分析
从以上代码可以看出,虽然这种方式可以解决粘包问题,但这种固定数据大小的传输方式,当数据量比较小时会使用空字符来填充,所以会额外的增加网络传输的负担,因此不是理想的解决方案
解决方案二:自定义请求协议
这种解决方案的实现思路是将请求的数据封装成两部分:消息头(发送的数据大小)+消息体(发送的具体数据),如下图: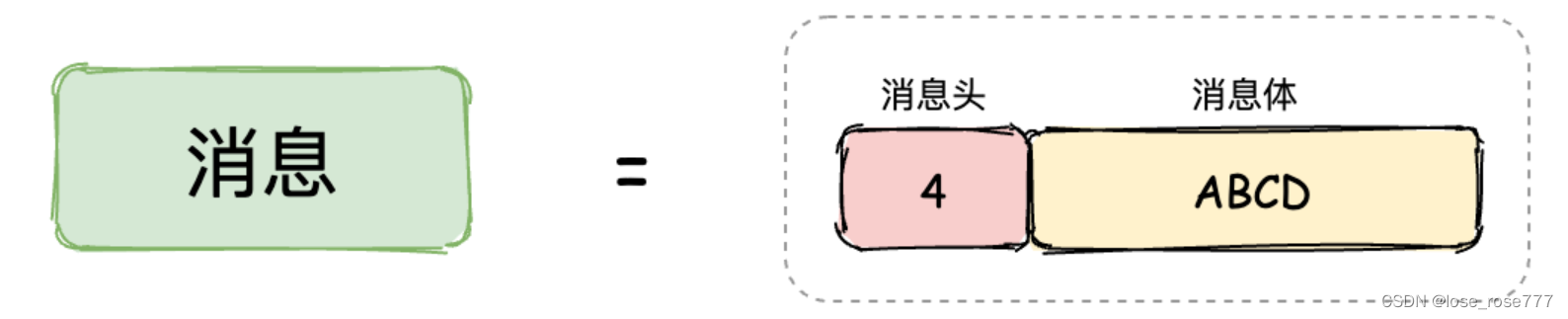
此解决方案的实现为以下三部分:
- 编写一个消息的封装类
- 编写客户端
- 编写服务器端
消息的封装类:
import java.nio.charset.StandardCharsets;public class CustomProtocol {private static final int HEAD_SIZE = 8; // 假设消息头固定为8个字节public static byte[] toBytes(String context) {// 协议体 byte 数组byte[] bodyByte = context.getBytes(StandardCharsets.UTF_8);int bodyByteLength = bodyByte.length;// 最终封装对象byte[] result = new byte[HEAD_SIZE + bodyByteLength];// 借助 NumberFormat 将int 转换为 byte[]NumberFormat numberFormat = NumberFormat.getNumberInstance();numberFormat.setMinimumIntegerDigits(HEAD_SIZE);numberFormat.setGroupingUsed(false);// 协议头 byte 数组byte[] headByte = numberFormat.format(bodyByteLength).getBytes();// 封装协议头System.arraycopy(headByte, 0, result, 0, HEAD_SIZE);// 封装协议体System.arraycopy(bodyByte, 0, result, HEAD_SIZE, bodyByteLength);return result;}public int getHeader(InputStream inputStream) throws IOException {int result = 0;byte[] bytes = new byte[HEAD_SIZE];inputStream.read(bytes, 0, HEAD_SIZE); // 得到消息体的字节长度result = Integer.valueOf(new String(bytes));return result;}
}
客户端代码:
import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
import java.util.Random;public class MySocketClient {public static void main(String[] args) throws IOException {// 启动 Socket 并尝试连接服务器Socket socket = new Socket("127.0.0.1", 9093);// 发送消息合集(随机发送一条消息)final String[] messages = {"hello world"};// 创建协议封装对象SocketPacket socketPacket = new SocketPacket();try (OutputStream outputStream = socket.getOutputStream()) {// 给服务器端发送 10 次消息for (int i = 0; i < 10; i++) {// 随机发送一条消息String msg = messages[new Random().nextInt(messages.length)];// 将内容封装为:协议头+协议体byte[] bytes = socketPacket.toBytes(msg);// 发送消息outputStream.write(bytes, 0, bytes.length);outputStream.flush();}}}
}
服务器端代码:
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;public class MySocketServer {public static void main(String[] args) throws IOException {// 创建 Socket 服务器端ServerSocket serverSocket = new ServerSocket(9093);// 使用线程池处理更多的客户端ThreadPoolExecutor threadPool = new ThreadPoolExecutor(100, 150, 100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000));while (true) {// 获取客户端连接Socket clientSocket = serverSocket.accept();// 客户端消息处理threadPool.submit(() -> {processMessage(clientSocket);});}}// 客户端消息处理private static void processMessage(Socket clientSocket) {// Socket 封装对象SocketPacket socketPacket = new SocketPacket();// 获取客户端发送的消息对象try (InputStream inputStream = clientSocket.getInputStream()) {while (true) {// 获取消息头(也就是消息体的长度)int bodyLength = socketPacket.getHeader(inputStream);// 消息体 byte 数组byte[] bodyByte = new byte[bodyLength];// 每次实际读取字节数int readCount = 0;// 消息体赋值下标int bodyIndex = 0;// 循环接收消息头中定义的长度while (bodyIndex <= (bodyLength - 1) && (readCount = inputStream.read(bodyByte, bodyIndex, bodyLength)) != -1) {bodyIndex += readCount;}bodyIndex = 0;// 成功接收到客户端的消息并打印System.out.println("接收到客户端的信息:" + new String(bodyByte));}} catch (IOException e) {e.printStackTrace();}}
}
运行结果:

优缺点分析:
此解决方案虽然可以解决粘包问题,但消息的设计和代码的实现复杂度比较高,所以也不是理想的解决方案
解决方案三:特殊字符结尾
以特殊字符结尾就可以知道流的边界了,它的具体实现是:使用Java 中自带的 BufferedReader 和Bufferedwriter ,也就是带缓冲区的输入字符流和输出字符流,通过写入的时候加上 \n 来结尾,读取的时候使用 readLine按行来读取数据,这样就知道流的边界了,从而解决了粘包的问题
服务器端代码:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ServerSocketV3 {public static void main(String[] args) throws IOException {// 创建 Socket 服务器端ServerSocket serverSocket = new ServerSocket(9092);// 使用线程池处理更多的客户端ThreadPoolExecutor threadPool = new ThreadPoolExecutor(100, 150, 100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000));while (true) {// 获取客户端连接Socket clientSocket = serverSocket.accept();// 消息处理threadPool.submit(() -> {processMessage(clientSocket);});}}// 消息处理private static void processMessage(Socket clientSocket) {// 获取客户端发送的消息流对象try (BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()))) {while (true) {// 按行读取客户端发送的消息String msg = bufferedReader.readLine();if (msg != null) {// 成功接收到客户端的消息并打印System.out.println("接收到客户端的信息:" + msg);}}} catch (IOException ioException) {ioException.printStackTrace();}}
}
客户端代码:
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.net.Socket;public class ClientSocketV3 {public static void main(String[] args) throws IOException {// 启动 Socket 并尝试连接服务器Socket socket = new Socket("127.0.0.1", 9092);final String message = "hello world";// 发送消息try (BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()))) {// 给服务器端发送 10 次消息for (int i = 0; i < 10; i++) {// 注意:结尾的\n 不能省略,它表示按行写入bufferedWriter.write(message + "\n");// 刷新缓冲区(此步骤不能省略)bufferedWriter.flush();}}}
}
运行结果:

优缺点分析:
以特殊符号作为粘包的解决方案的最大优点是实现简单,但存在一定的局限性,比如当一条消息中间如果出现了结束符就会造成半包的问题,所以如果是复杂的字符串要对内容进行编码和解码处理,这样才能保证结束符的正确性
TCP为什么要四次挥手?说一下四次挥手的流程?
四次挥手的具体流程如下:
- 用户发送FIN包:客户端发送一个FIN包,其中FIN标志位为1,表示客户端希望关闭连接
- 服务器发送ACK包:服务器收到客户端的FIN包,向客户端发送一个ACK包,其中ACK标志位为1,表示服务器已经收到了客户端的请求,并将确认号(ACK)设置为发送的序列号+1
- 服务器发送FIN包:服务器在发送完ACK包之后,也会发送一个FIN包,其中FIN标志位为1,表示服务器也希望关闭连接
- 客户端发送ACK包:客户端收到服务器的FIN包之后,向服务器发送一个ACK包,其中ACK标志位为1,表示客户端已经收到了服务器的请求,并将确认号设置为服务器发送的序列号+1
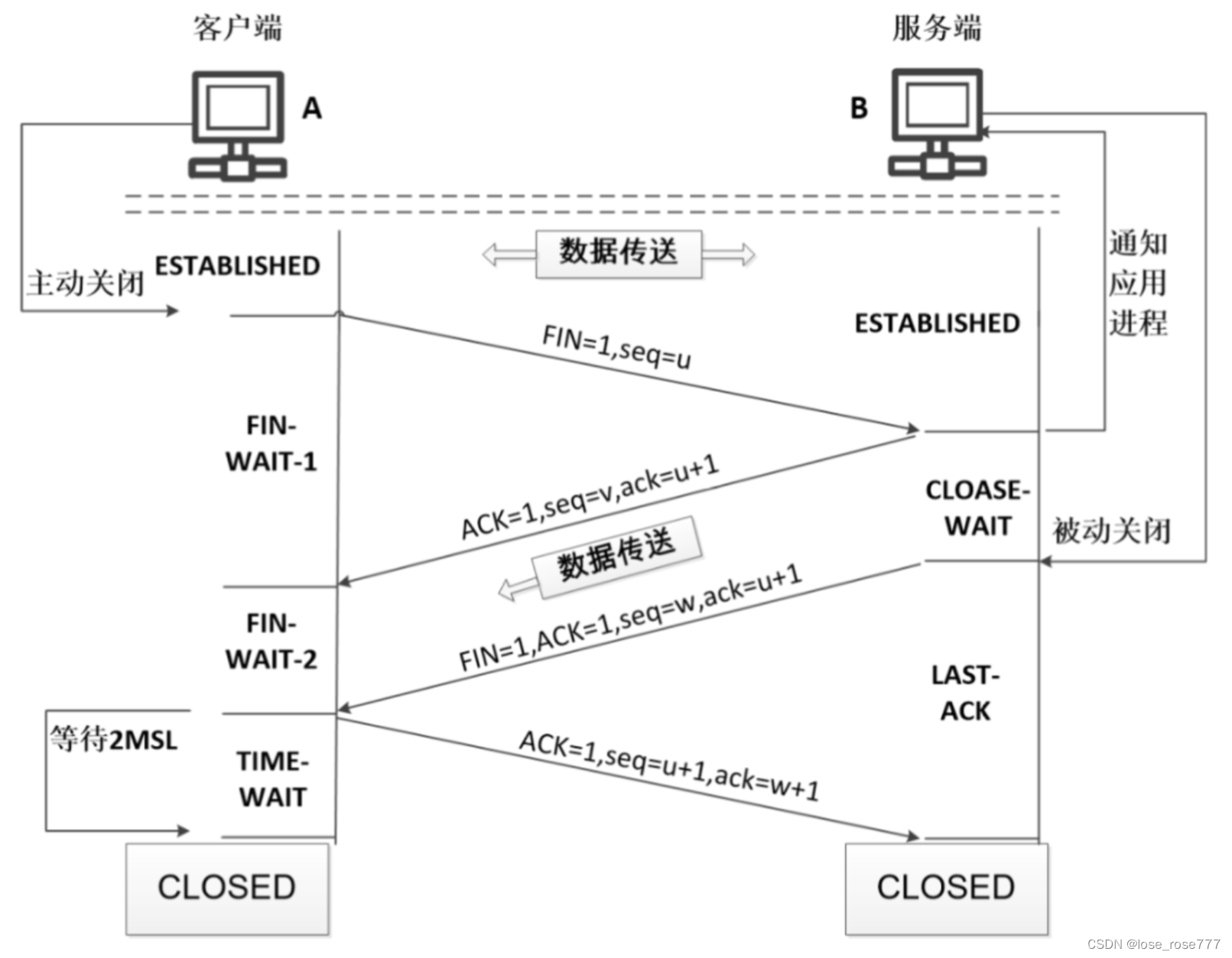
TCP进行四次挥手的作用主要是有两点:
- 确保所有数据都被传输完成:在关闭连接之前,双方都有可能还有数据需要传输,因此需要通过四次挥手来确保所有数据已经传输完成
- 确保双方都能正常关闭连接:四次挥手的过程中,客户端和服务器都需要发送 FIN 和 ACK 包,以确保双都能正确地关闭连接,避免连接一方关闭而另一方仍然处于连接状态
TCP四次挥手为什么要等两个MSL(最大生存时间)?
四次挥手时发送者最后一次等待时间是两个MSL(最大生存时间),目的就是确保最后一个ACK的可靠传输,在四次挥手的最后一步,接收方发送一个ACK给发送方,表示接受到了关闭连接的请求。发送方需要等待一段时间,确保这个ACK报文额能够可靠的传输到接受方。如果发送方在等待期间收到接收方的重传请求,可以重发ACK
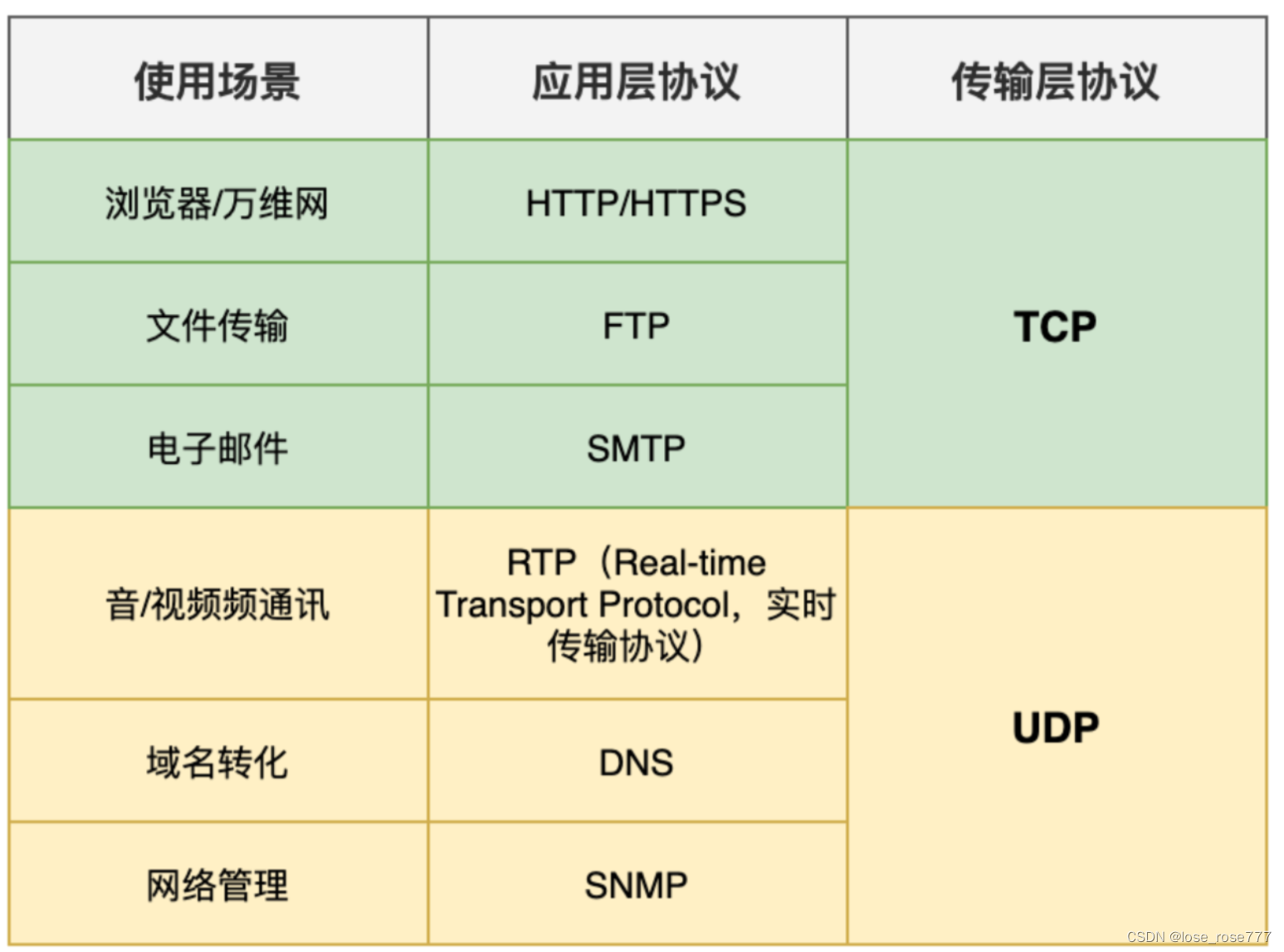
TCP和UDP有什么区别?
TCP和UDP都是传输层的重要协议,但是它们存在以下几点不同:
- 连接机制不同:TCP是面向连接的协议,需要在客户端和服务器之间建立一个稳定的连接,然后再进行数据传输;而UDP是无连接协议,数据包可以直接发送给目标主机,不需要事先建立连接
- 数据传输方式不同:TCP采用可靠的数据传输方式,即在传输的过程中使用序号、确认号和重传机制等控制手段来保证数据的可靠传输;而UDP采用不可靠的数据传输方式,数据包可能会丢失或重复,不提供数据的可靠性保障
- 数据传输效率不同:由于 TCP 需要进行连接、序号确认等额外的数据包传输,因此在数据传输效率方面相对于 UDP 要低一些
- 数据大小限制不同:UDP 对数据包的大小有限制,最大只能传输 64KB 的数据,而 TCP 的数据包大小没有限制
- 应用场景不同:TCP适用于要求数据传输可靠高的场景,如网页浏览、文件下载、电子邮件等;而UDP适用实时性要求高的场景,如视频会议、在线游戏等
Linux上如何查询某个端口是否被占用?
在Linux上,你可以使用以下几种方法来查询某个端口是否被占用:
-
使用netstat命令:
netstat -tuln | grep <端口号>这个命令会列出当前正在运行的所有TCP和UDP端口,并过滤出指定端口是否被占用。如果端口被占用,会显示对应的PID和程序名称。
-
使用ps命令结合grep命令:
ps -aux | grep <端口号>这个命令会列出所有正在运行的进程,并过滤出包含指定端口号的进程信息。通过查看对应的PID和程序名称,可以判断该端口是否被占用。
Linux常见目录有哪些?
Linux 系统中常见的目录有以下几个
- /bin:存放常用的命令二进制可执行文件,如 ls、grep 等
- /etc:系统配置文件目录,存放系统管理和配置文件
- /home:普通用户的主目录,在个人使用时通常将用户目录放在这里
- /root:超级管理员的主目录
- /usr:存放应用程序和文件。
- /usr/bin:应用程序目录,与/bin类似,但存放不常用的应用程序
- /usr/lib:共享库目录,存放系统和应用程序所需的共享库文件
- /usr/share:共享文件目录,不同系统和程序共享的数据文件存放这里
- /var:放系统运行过程中的各种变化文件,如日志
- /opt:可选应用软件包安装目录
- /tmp:临时文件目录
Linux中的常用命令有哪些?
Linux常用命令如下:
-
ls: 列出当前目录下的文件和子目录信息。
- 使用方式:ls [-options] [file/directory]
- 示例:ls /home/user 列出 /home/user 目录下的所有文件信息。
-
cd: 切换当前工作目录。
- 使用方式:cd [directory]
- 示例:cd Documents 切换到 Documents 目录,使用 cd … 返回上一级目录。
-
pwd: 显示当前工作目录的绝对路径。
- 使用方式:pwd
-
mkdir: 创建新的目录。
- 使用方式:mkdir [directory]
- 示例:mkdir javacn 创建 “javacn” 文件夹。
-
touch: 创建新文件或者更新已存在文件的时间戳。
- 使用方式:touch [file]
- 示例:touch newfile.txt
-
rm: 删除指定的文件或目录。
- 使用方式:rm [-options] file/directory
- 示例:rm file.txt(删除单个文件)、rm -r directory(递归删除目录及其内容)。
-
cp: 复制文件或目录。
- 使用方式:cp [-options] source destination
- 示例:cp file1.txt file2.txt(复制文件)、cp -r dir1 dir2(复制目录)
-
mv: 移动或重命名文件或目录。
- 使用方式:mv [-options] source destination
- 示例:mv file.txt newfile.txt(重命名文件)、mv file.txt /dir/(移动文件到指定目录)。
-
find: 在指定目录下查找满足条件的文件。
- 使用方式:find [path] [expression]
- 示例:find . -name “*.txt” 在当前目录及其子目录下查找扩展名为 .txt 的文件。
- grep: 搜索文件中匹配特定模式的行。
- 使用方式:grep [options] pattern file(s)
- 示例:grep “hello” file.txt 在 file.txt 中查找包含 “hello” 的行。
你可以使用命令的 --help 参数或查看相关命令的手册页(man 页)来获取更详细的信息,比如 man ls 可以查看 ls 命令的手册页
Linux中如何查看日志信息?
在 Linux 系统中查看日志一般需要以下两个步骤:
第一步:找到存放日志的位置。 日志文件通常存放在 /var/log 目录及其子目录中,不同的服务和应用程序可能会有自己独立的日志文件。常见的系统日志文件包括 /var/log/messages、/var/log/syslog、/var/log/dmesg 等,而特定服务或应用程序的日志文件则位于其对应的目录下,例如 Apache Web 服务器的日志文件通常位于 /var/log/apache2/ 目录下
第二步:使用以下命令查询具体的日志信息:
-
cat: 查看某个日志文件中的所有内容
- 使用示例:
cat file.txt显示file.txt文件的所有内容
- 使用示例:
-
head: 查看某个日志文件中开头的内容
- 使用示例:
head file.txt显示file.txt文件的前 10 行内容。也可以指定查看的行数,例如,head -n 5 file.txt显示file.txt文件的前 5 行内容
- 使用示例:
-
tail: 查看某个日志文件中末尾的内容,用法和
head类似- 使用示例:
tail file.txt显示file.txt文件的最后 10 行内容
- 使用示例:
-
more: 分页方式显示文件内容,常用来查看大型日志文件
- 使用示例:
more file.txt分页查看file.txt文件内容,一次只显示一屏内容,用户通过空格键或回车键翻看下一页,按 q 退出查看
- 使用示例:
Linux中如何查看负载情况?什么情况算负载比较高?
在Linux系统中,可以使用以下几种方式来查看系统的负载情况:
-
使用
uptime命令:uptime命令可以显示系统的运行时间以及平均负载。- 示例:
uptime
-
使用
top命令:top命令可以实时显示系统的各项指标,包括负载情况、CPU利用率、内存使用情况等。- 示例:
top
单核负载 0.7 以下是健康的情况,反之大于 0.7 表示负载比较高,对应四核健康的情况就是 0.7*4=2.8 是健康的情况,大于 2.8 就表示负载比较高



![[VulnHub靶机渗透] dpwwn: 1](https://img-blog.csdnimg.cn/direct/c28880cbfe2a4faf8b7f8aa1d51ece7d.png)