资源下载地址:https://download.csdn.net/download/sheziqiong/85705488
资源下载地址:https://download.csdn.net/download/sheziqiong/85705488
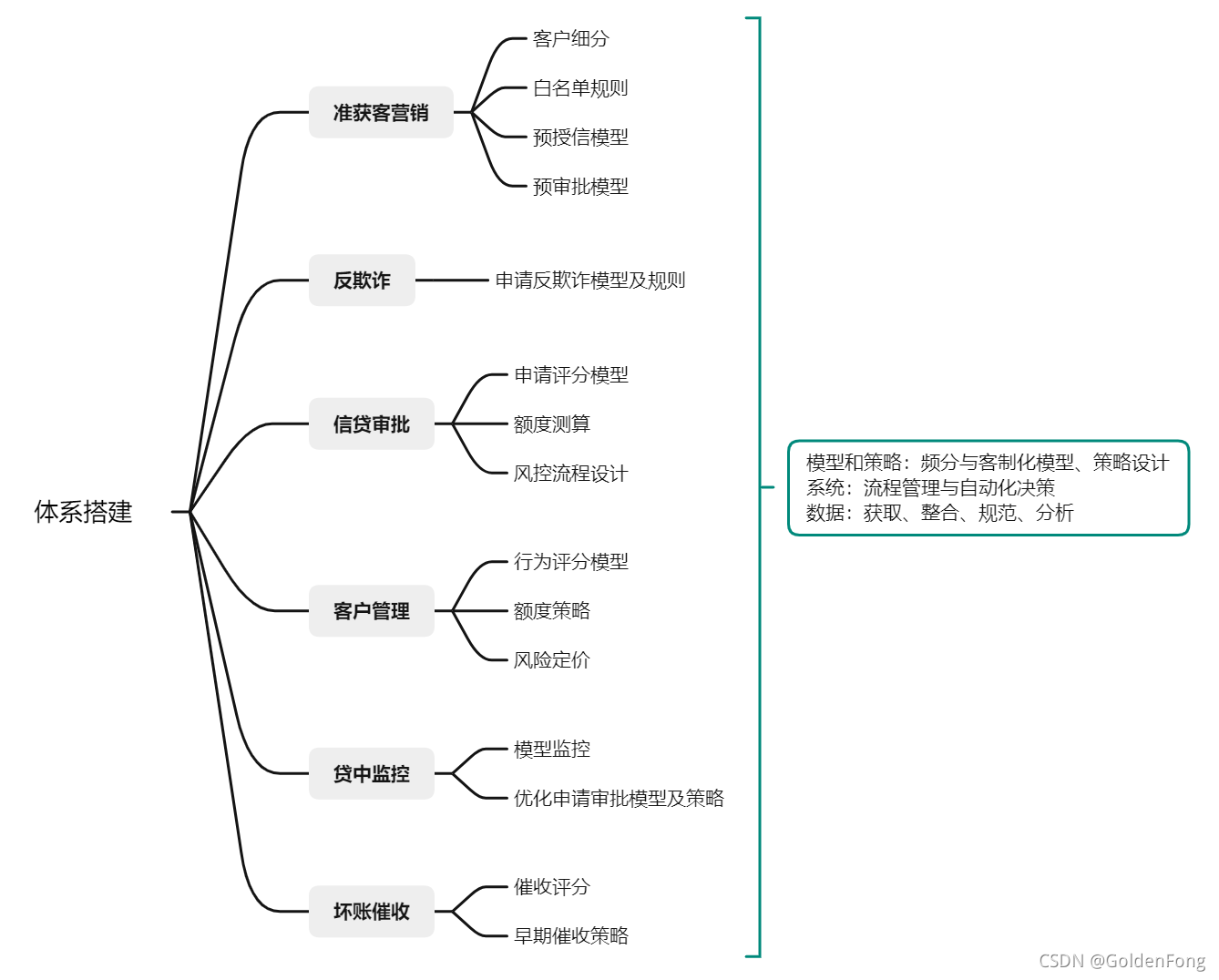
项目概述:
- 比赛数据:
"拍拍贷"提供的数据包括信用违约标签(因变量)、建模所需的基础与加工字段(自变量)、相关用户的网络行为原始数据,数据字段已经做脱敏处理。本次实战采用的是初赛数据,包括3万条训练集和2万条测试集。数据文档包括:
-
Master:每一行代表一个样本(一笔成功成交借款),每个样本包含200多个各类字段。
-
Log_Info:借款人的登陆信息,每个样本含多条数据。
-
Userupdate_Info:借款人修改信息,每个样本多条数据。
- 比赛规则:
基于训练集数据构建预测模型,使用模型计算测试集的评分(评分数值越高,表示越有可能出现贷款违约),评价标准为AUC。
建模思路:
-
数据清洗工作,主要做一下缺失值处理,常变量处理,空格符处理,字符大小写转换等
-
特征处理工作,分为特征转换和特征衍生。主要做了以下工作:
-
Master数据:地理位置信息的处理(省份,城市),运营商和微博特征的转换,以及对排序特征,periods特征的交叉组合等。
-
Log_Info数据:衍生出"累计登陆次数",“登录时间的平均间隔”,"最近一次的登录时间距离成交时间差"等特征。
-
Userupdate_Info数据:衍生出"最近的修改时间距离成交时间差",“修改信息的总次数”, "每种信息修改的次数"等特征。
-
特征筛选工作:利用lightgbm输出特征重要性进行筛选。
-
建模工作:
-
单模型,选用的机器学习模型是lightgbm。
-
bagging模型:基于bagging的思想,通过对模型参数进行随机扰动,构建多个子模型,选用的基模型是lightgbm。
重要工作:
-
数据离群值判定,清洗
-
利用XGboost,按特征重要性系统衍生新特征,剥离没用的特征
-
特征的离散化,二值化,数值型特征衍生排序
-
交叉验证,网格搜索完成lightGBM超参数设置
-
bagging lightGBM模型
项目流程
数据清洗(data_input, data_EDA_clean代码模块)
- 导入合并好的数据,看一下好坏用户比:
Mater数据包含约50000个样本,200多个字段。
# 样本的好坏比
data1.target.value_counts()

好坏比约11:1,属于不平衡数据集,因为最后模型用的是lightgbm,故本次实战先不采用过采样方法来进行数据抽样,直接用原始数据来建模。
- 缺失值处理:
缺失变量的数据可视化

有一些变量缺失率很高,如果将缺失填充为0,这类变量其实可看做一类稀疏特征,由于xgboost,lightgbm等GBDT类树模型对高维稀疏特征处理不太好,并考虑到这些变量的业务含义未知,携带的信息量太少,故对缺失率高的变量作删除处理。
除了要考虑变量的缺失情况,也要考虑样本缺失特征个数的情况,一个样本如果缺失的特征很多,说明用户的信息完善程度很低,通过对缺失样本的可视化,发现了这些离群点,可以考虑删除。
# 样本的趋势个数可视化
sc.plot_missing_user(df=data1,plt_size=(16,5))

# 删除变量缺失个数在100个以上的用户
data1 = sc.missing_delete_user(df=data1,threshold=100)
缺失变量个数在100以上的用户数有298个。
- 常变量处理
当一个变量中单个值所占比例过高(90%以上),说明该变量方差比较小,携带的信息较少,导致区分能力较差,对于这些变量也做删除处理。
- 字符格式转换
城市特征清洗:
# 计算4个城市特征的非重复项计数,观察是否有数据异常
for col in ['UserInfo_2','UserInfo_4','UserInfo_8','UserInfo_20']:
print('{}:{}'.format(col,data1[col].nunique()))
print('\t')

UserInfo_8相对其他特征nunique较大,发现有些城市有"市",有些没有,需要做一下格式转换,去掉字符串后缀"市".
print(data1.UserInfo_8.unique()[:50])

# UserInfo_8清洗处理,处理后非重复项计数减小到400
data1['UserInfo_8']=[s[:-1] if s.find('市')>0 else s[:] for s in data1.UserInfo_8]
UserupdateInfo1特征大小写转换:
'UserupdateInfo1’包含了大小写,如"qQ"和"QQ",属于同一种意思,所以需要对其英文字符统一转换大小写。
# 将UserupdateInfo1里的字符改为小写形式
df2['UserupdateInfo1'] = df2.UserupdateInfo1.map(lambda x:x.lower())
特征处理(feature_processing代码模块)
- Master数据:
对Master中的类别型特征(省份,城市,运营商,微博)做特征转换,对数值型变量做排序特征,periods特征的衍生。
类别型特征:
- 省份:
原数据有两个省份字段,推测一个为用户的户籍地址,另一个为用户居住地址所在省份,由此可衍生的字段为:
-
省份二值化,通过违约率将单个省份衍生为二值化特征,分为户籍省份和居住地省份
-
户籍省份和居住地省份是否一致,推测不一致的用户大部分为外来打工群体,相对违约率会高一点。
-
计算违约率时要考虑该省份的借款人数,如果人数太少,参考价值不大
省份二值化

两种省份特征选择出违约率排名前五的省份,并做二值化衍生。
户籍省份和居住地省份不一致衍生
- 城市变量:
原数据中有4个城市信息,推测为用户常登录的IP地址城市,衍生的逻辑为:
通过xgboost挑选比较重要的城市变量,进行二值化衍生
由4个城市特征的非重复项计数可衍生成 登录IP地址的变更次数
城市二值化衍生
# 根据xgboost变量重要性的输出对城市作二值化衍生

将特征重要性排名前三的城市做二值化衍生:
IP地址变更次数衍生
- 运营商:
因运营商的种类少,直接做亚编码处理即可。
- 微博:
先对微博特征做一下缺失值填充,再做亚编码处理。
数值型特征:
- 排序特征衍生:
对数值型特征按数值从小到大进行排序,衍生成排序特征,排序特征异常值有更强的鲁棒性,可以增强模型的稳定性,降低过拟合风险。
- periods特征衍生:
# 生成只包含periods的临时表
periods_col = [i for i in num_col2 if i.find('Period')>0]
periods_col2 = periods_col+['target']
periods_data = data1.loc[:,periods_col2]
观察包含period1所有字段的数据,发现字段之间量级差异比较大,可能代表不同的含义,不适合做衍生。
periods1_col = [col for col in periods_col if col.find('Period1')>0]
periods_data.loc[:,periods1_col].head()

观察后缀都为1的字段,发现字段数据的量级基本一致,可以对其做min,max,avg等统计值的衍生。
period_1_col=[]
for i in range(0,102,17):
col = periods_col[i]
period_1_col.append(col)
periods_data.loc[:,period_1_col].head()

对后缀都为1的periods字段做相应的四则运算(最小,最大,平均),衍生成新的特征。
- Log_Info表:
衍生的变量
-
累计登录次数
-
登录时间的平均间隔
-
最近一次的登录时间距离成交时间差
- Userupdate_Info表
衍生的变量
- 最近的修改时间距离成交时间差
- 修改信息的总次数
- 每种信息修改的次数
将衍生特征汇总成一张表:
update_info = pd.merge(time_span,cate_change_df,on='Idx',how='left')
update_info = pd.merge(update_info,update_cnt,on='Idx',how='left')
update_info.head()
建模
1.单模型lightgbm(single_lightgbm_model代码模块)
- 在不调参的情况下,两种版本的lightgbm的默认参数模型
sklearn接口版本
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PwC1RKaq-1655693041517)(https://www.writebug.com/myres/static/uploads/2022/6/18/b8b514598c8d1312831c6c39cc33ea46.writebug)]
原生版本的lightgbm

调参
- 学习速率先设定为0.1,便于缩短模型的训练时间,最后一步再减小学习速率,先确定最大的迭代次数。
# 确定最大迭代次数,学习率设为0.1
base_parmas={'boosting_type':'gbdt',
'learning_rate':0.1,
'num_leaves':40,
'max_depth':-1,
'bagging_fraction':0.8,
'feature_fraction':0.8,
'lambda_l1':0,
'lambda_l2':0,
'min_data_in_leaf':20,
'min_sum_hessian_inleaf':0.001,
'metric':'auc'}
cv_result = lgb.cv(train_set=lgb_train,
num_boost_round=200,
early_stopping_rounds=5,
nfold=5,
stratified=True,
shuffle=True,
params=base_parmas,
metrics='auc',
seed=0)
print('最大的迭代次数: {}'.format(len(cv_result['auc-mean'])))
print('交叉验证的AUC: {}'.format(max(cv_result['auc-mean'])))
确定subsample为0.5,colsample_bytree为0.6
- 正则化参数调参
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6K6spI9z-1655693041520)(https://www.writebug.com/myres/static/uploads/2022/6/18/981a2f24600efae4e882a964a55f7894.writebug)]
确定reg_lambda为0.03,reg_alpha为0.3
- 减小学习速率,再计算最佳参数下的迭代次数

确定最终的迭代次数为889次
- 最佳参数建模(sklearn接口版本)
lgb_single_model = lgb.LGBMClassifier(n_estimators=900,learning_rate=0.005,min_child_weight=0.001,min_child_samples = 20,subsample=0.5,colsample_bytree=0.6,num_leaves=30,max_depth=-1,reg_lambda=0.03,reg_alpha=0.3,random_state=0)
lgb_single_model.fit(x_train,y_train)
pre = lgb_single_model.predict_proba(x_test)[:,1]
print('lightgbm单模型的AUC:{}'.format(metrics.roc_auc_score(y_test,pre)))
sc.plot_roc(y_test,pre)

调参之后测试集的AUC提升了0.015。
- lightgbm bagging
主要借鉴了随机森林对于选取样本的随机性和对于特征的随机性的思想。
-
样本随机性的实现方法:random_seed,bagging_fraction,feature_fraction的参数扰动
-
特征随机性的实现方法:在使用所有原生特征基础上,随机抽取一定的排序特征和periods特征至模型中。
资源下载地址:https://download.csdn.net/download/sheziqiong/85705488
资源下载地址:https://download.csdn.net/download/sheziqiong/85705488