P2P是近年来很热的一个行业,由于这个行业在国内兴起才不久,国内的很多学者对这个行业都兴趣盎然,在大学研究互联网金融的学者更是有一大群。小编是学金融出身,深知数据在做学术研究的重要性,之前有不少学互联网金融的同学、师弟师妹们都请教过我如何获取研究数据,小编当年论文的研究数据其实也是花了不少大洋在网上买的。最近有幸接触到python这个强大的工具,python的一个强大的功能就是进行数据发掘(俗称“爬虫”),原来爬虫并没有想象中的那么难,只要花点功夫学习一下你也可以,下面就让我手把手教你们如何在人人贷网站上爬虫借款人信息。
首先我们需要下载并安装python软件,windows版本下载地址,下载python 3.5以上的版本, 建议下载可以直接安装的包:Windows x86 executable installer,下载下来之后直接双击安装,安装的时候记得勾选Add python to path选项
,后面的按默认的选项安装即可。

由于人人贷中借款人的信息需要登录之后才可见,因此需要先注册一个人人贷的账号用于爬虫。本爬虫脚本调用的是Firefox浏览器,需要电脑先下载并安装Firefox浏览器,用Firefox爬虫需要下载相应的驱动,可以到下面的地址下载下载geckodriver,并将该文件放在python的安装目录python3.exe所在的目录。
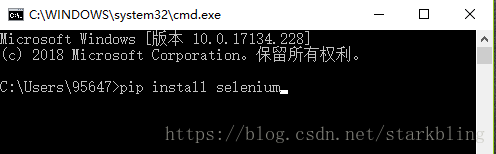
该爬虫脚本还需要用到几个模块,需要使用pip来安装,首先确保pip在电脑的环境变量中,关于如何设置电脑的环境变量网上有很多相关的文章,可以自行去了解。按住 win+R键,输入cmd调用系统的DOS命令栏,然后用pip安装对应的python包,使用的命名格式如下:pip install “模块名”,如安装selenium模块,命令如下pip install selenium。采用这种方式分别安装selenium、pandas、bs4、requests、numpy模块。
用于爬虫的脚本如下,在电脑上新建一个文件夹,命名为人人贷数据爬虫,然后用记事本在里面新建一个文件,并将后缀名改为.py,如renrendai_scrapy.py ,copy如下的脚本到这个renrendai_scarpy.py文件夹中,代码写的比较烂,源代码如下:
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 13 11:10:39 2018
@author: 95647
"""
from selenium import webdriver
import time
import json
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from selenium.webdriver.firefox.options import Options #use headless browser login
import requests
from pandas import DataFrame
time_start = time.clock()headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
#headers according to push F12 in browser
#enter the user information you have signed
username = u"username_" #在此填入你的用户名
password = "password_" #在此填入你的密码
#driver = webdriver.Firefox() #使用Firefox自带的无头浏览器登录
options = Options()
options.add_argument('-headless')
driver = webdriver.Firefox(firefox_options=options) #use headless firefox to login def LoginRRD(username, password):try:print(u'准备登录人人贷网站...')driver.get("https://www.we.com/pc/passport/index/login")elem_user = driver.find_element_by_name("j_username")elem_user.send_keys(username)time.sleep(2) #设置等待时间,不用修改elem_pwd = driver.find_element_by_name("j_password")elem_pwd.send_keys(password)time.sleep(5) #设置等待时间,以防止用户名下拉菜单挡住登录按钮driver.find_element_by_xpath(r"""//*[@id="form-login"]/div/div[2]""").click() #点击登录time.sleep(10) #设置等待几秒,以进入用户主界面,如不等待而直接进入爬虫会提示未登录print(u'登录成功!')except Exception as e:print("Error:", e)finally:print(u'End Login!\n')
loanid_e =[]
def parse_userinfo(loanid,idx): """用于提取借款人各项信息数据"""global loanid_e
# print(str(loanid))urll="https://www.renrendai.com/loan-%s.html"%str(loanid) driver.get(urll)html = BeautifulSoup(driver.page_source,'lxml')
# print(html.decode('utf-8'))
# f= open("html0.txt","w")
# f.write(html.decode("utf-8").replace('\xa9',"@"))
# f.closeinfo = html.findAll('div',class_="loan-user-info") #这个地方的命名经常修改userinfo = {}try:items = info[0].findAll('span',{"class":"pr20"})except IndexError as e:LoginRRD(username, password)loanid_e.append(loanid)else: for item in items:var = item.get_text()value = item.parent.text.replace(var,"")userinfo[var]=valuedata = pd.DataFrame(userinfo,index=[idx]) return datadef get_loanId():table=DataFrame(np.array(['allowAccess', 'amount', 'amountPerShare', 'beginBidTime', 'borrowerId','borrowerLevel', 'currentIsRepaid', 'displayLoanType', 'finishedRatio','forbidComment', 'interest', 'interestPerShare', 'leftMonths', 'loanId','loanType', 'months', 'nickName', 'oldLoan', 'openTime', 'overDued','picture', 'principal', 'productId', 'readyTime', 'repaidByGuarantor','startTime', 'status', 'surplusAmount', 'title', 'utmSource']).reshape(1,30),columns=['allowAccess','amount', 'amountPerShare', 'beginBidTime', 'borrowerId','borrowerLevel', 'currentIsRepaid', 'displayLoanType', 'finishedRatio','forbidComment', 'interest', 'interestPerShare', 'leftMonths', 'loanId','loanType', 'months', 'nickName', 'oldLoan', 'openTime', 'overDued','picture', 'principal', 'productId', 'readyTime', 'repaidByGuarantor','startTime', 'status', 'surplusAmount', 'title', 'utmSource'])#网页源码获取i=1for i in range(1,101): #当前101散标信息页面一共只有101页,所以填的是101,可根据具体情况修改url = "https://www.renrendai.com/loan/list/loanList?startNum=%s&limit=10"%str(i) #resourse of dataresp=requests.get(url,headers=headers) #获取页面源代码html=resp.text data_dic = json.loads(html)data=DataFrame(data_dic['data']['list'])table=pd.concat([table,data])i += 1#save filetable.to_csv('人人贷11.csv',header=False) #保存贷款人信息到人人贷.csv文件夹中loanId=table['loanId']return loanIdLoginRRD(username, password) #login renrendai website
loanId = get_loanId() #获取借款人ID
user_info = ['昵称', '信用评级','姓名','身份证号','年龄', '学历', '婚姻','申请借款', '信用额度', '逾期金额', '成功借款', '借款总额', '逾期次数','还清笔数', '待还本息', '严重逾期','收入', '房产', '房贷', '车产', '车贷','其他','公司行业','公司规模', '岗位职位', '工作城市', '工作时间']
table2 = pd.DataFrame(np.array(user_info).reshape(1, 27), columns=user_info)i = 1
idx = 0
for loanid in loanId[1:10]: """后面的数值用来设置需要爬取多少个借款人信息,如全部需要就输入len(loanId +1)替代1000,建议先输入5来进行爬虫测试,以避免爬虫时间太长,而实际没有抓取到数据"""table2 = pd.concat([table2, parse_userinfo(loanid,idx)])
# print(loanid)print(i)idx += 1i += 1 #check how many times of this program looptable2.to_csv('borrowerinfo1.csv',header=False)time_end = time.clock() #this scarpy use of total time
print("\nElapsed time: %s seconds"%(str(time_end -time_start)))
需要修改代码里面的部分内容,将username = u"username_" 里面的username_修改为自己的用户名,password = “password_”,将里面的 password_ 修改为自己的登录密码。还有其他可以修改的地方都用中文提示了,请按照自己的需要进行相应的设置。完成以上工作之后,见证奇迹的时刻来了。
同时按住win+R键,输入cmd按回车,调出dos命名栏,然后在里面输入python + renrendai_scrapy.py的文件路径,如:C:\Users\95647>python desktop\1\renrendai_scrapy.py ,“>”后面是我输入的命令,文件路径实际上是在C:\Users\95647\ desktop\1\renrendai_scrapy.py,由于我前面已经定位到了C:\Users\95647,所以节省了前面的输入,可对照下图。
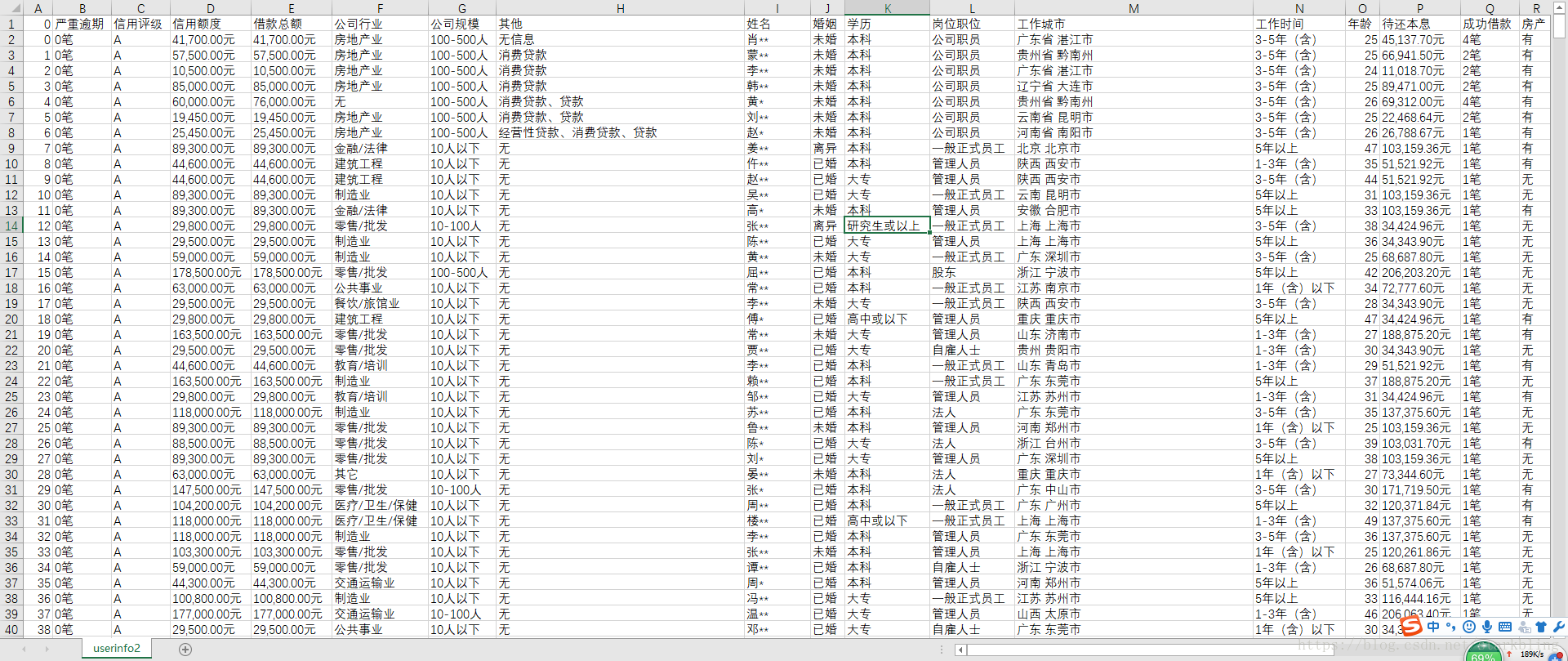
爬虫处理的结果保存的文件格式为csv格式,可以用excel直接打开,但是需要转换一下csv的编码格式,可以用notepad++等软件来转为ANSI的编码格式,这样用excel打开就能够正常显示了,我这边测试爬虫了前1000个用户的数据(总共用时30多分钟,这个和你的网速关系比较大),每个用户包含了27条信息,部分结果如下:
对爬虫感兴趣的朋友还可以阅读我的另外一条博文:用python爬取网贷之家p2p平台数据
由于人人贷网站后面进行了维护和更新,上面的代码在爬取数据的时候可能会出现问题,这里提供一个最新的代码下载链接:最新爬虫脚本下载