XPath
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航
使用方法:
使用前要把response.text通过etree.HTML()转换为对应的格式,再通过 变量名.xpath('xpath')截取内容
response=requests.get(url,headers=headers)
response.encoding='utf-8' #根据格式修改为utf-8或者gbk
html=response.text
xpath_style=etree.HTML(html)
text=xpath_style.xpath('xpath')
print(text)

现在的目标是百度首页的热搜,在左边的源码里可以看到热搜的所在位置,他的XPath就是:
/html/body/div/div/div[5]/div/div/div[3]/ul/li[1]/a/span[2]/text()
xpath的写法就和文件夹的路径一样,从大到小,可以在左边的源码中查看节点的结构,xpath中还有div[3],div[5]的写法,div[3]表示当前结构下的第三个div节点,下标默认从1开始
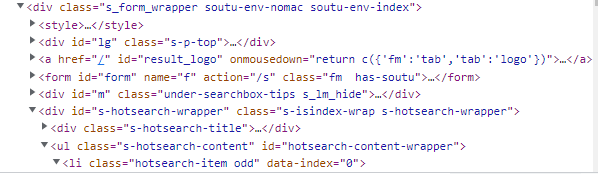
可以看到第一行的div下边有三个div,要表示第三个div就需要加上下标[3],其他节点也是如此。
获取关键字的值:以下案例地址:汽车产业资讯-汽车频道-和讯网

若要获取a标签里的href的值,xpath确定a标签之后在后边加 /@href
/html/body/div[5]/div[2]/div[1]/div[2]/div[1]/ul[1]/li[1]/a/@href
@+关键字名称 表示获取关键字的值
可以利用这种写法来浓缩xpath://*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]/text()
//*表示所有节点,[@id="hotsearch-content-wrapper"]表示id关键字的值=="hotsearch-content-wrapper",用这种写法确定一个或者多个节点,再确定后边的内容
以上两种写法的最后一个节点是text() 表示获取上一个节点的文本内容,若去掉text(),则输出:<Element span at 0x8847940>。或者输出是给变量加上 .text
for i in b: #b是通过xpath返回回来的变量print(i.text)
以上是XPath最基本最常用的写法,xpath还有很多方法和函数,具体请参考:XPath 教程
bs4
BS4全称是Beatiful Soup,它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
使用方法:
将response.text通过Beautifulsoup函数转换为对应的格式,‘html.parser’为bs4的解析器,种类有很多,它的功能就不在过多介绍了。
response=requests.get(url,headers=headers) response.encoding='utf-8' #根据格式修改为utf-8或者gbk html=response.text soup=BeautifulSoup(html,'html.parser')
主要介绍两个函数find_all()和select() (经过测试find_all比select快一些)
find_all():通过指定的标签名称和关键字的值来确定段落,匹配网页中的所有符合规则的结果。
PS:还有一个和find_all()相似的函数,find(),只匹配第一个符合规则的结果。
soup.find_all('div',class_='art_contextBox') 表示标签为div,class的值为art_contextBox的段落
注意:因为class为关键字,所以函数中的class需要加上下划线_!
这个函数的返回值是 <class 'bs4.element.ResultSet'>类型 可以用下标进行操作。
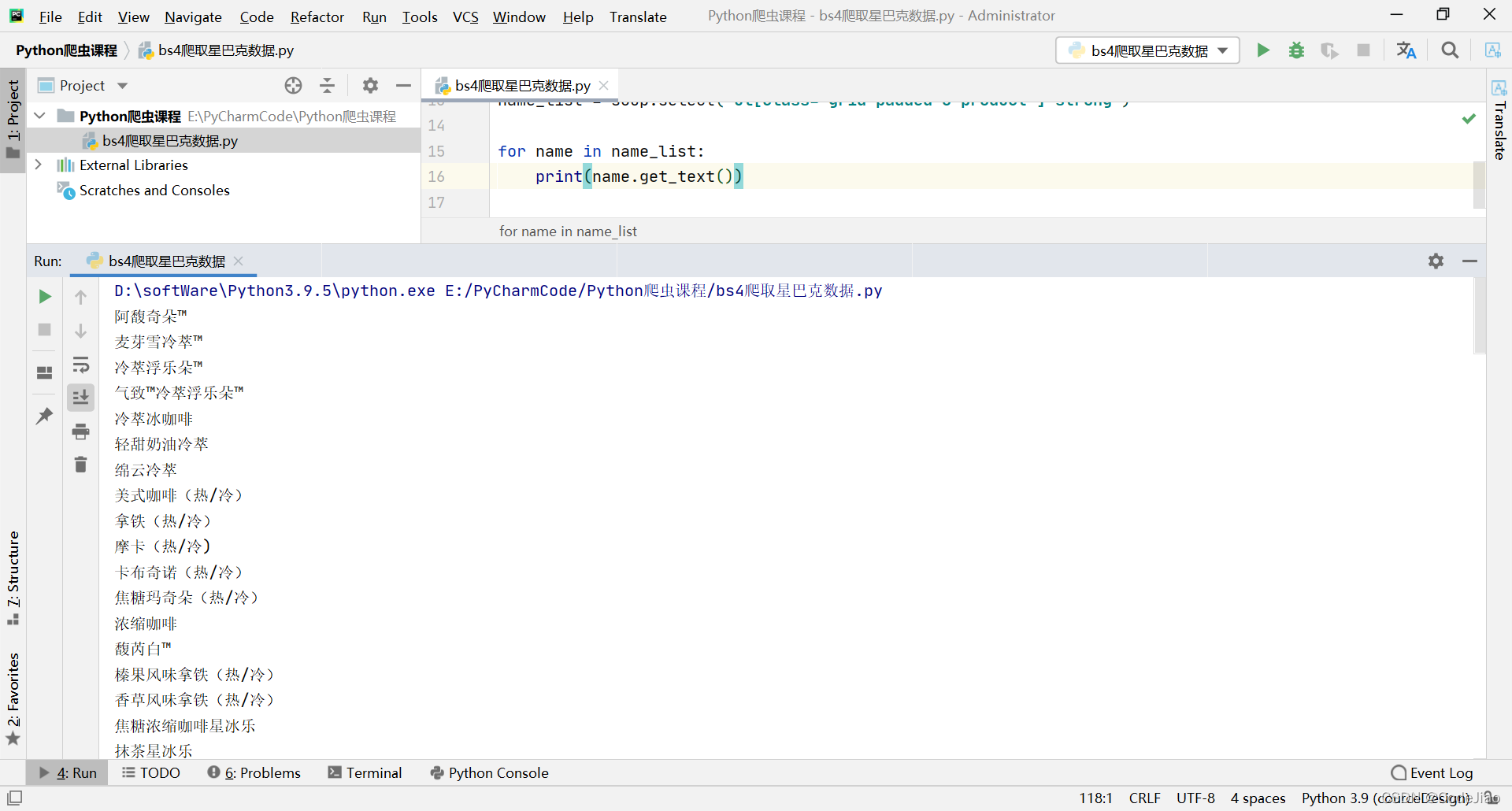
返回文本内容的话可以用get_text()函数,用法:
f_list=soup.find_all('div',class_='art_contextBox')
for i in f_list:print(i.get_text())
select():指定结构确定段落
soup.select('div span') 表示获取 div节点下 span节点的内容(一个网页中可能有多个这种关系,可以通过下标确定需要的内容)
soup.select("div[class='temp01'] ul li a") 表示节点名称div且class关键字的值是temp01的节点下的ul节点下的li节点下的a节点的内容。
返回的内容如下图所示

同样可以通过get_text()获取节点中的文本,用法:
f_list=soup.select("div[class='temp01'] ul li a")
for i in f_list:print(i.get_text())
还可以根据get()函数获取关键字的值:
f_list=soup.select("div[class='temp01'] ul li a")
for i in f_list:print(i.get('href'))
总结:
xpath和bs4各有各的特点,xpath相比来说简单一点,速度较快,根据自己的使用习惯和不同的应用场景来选择解析方式吧。