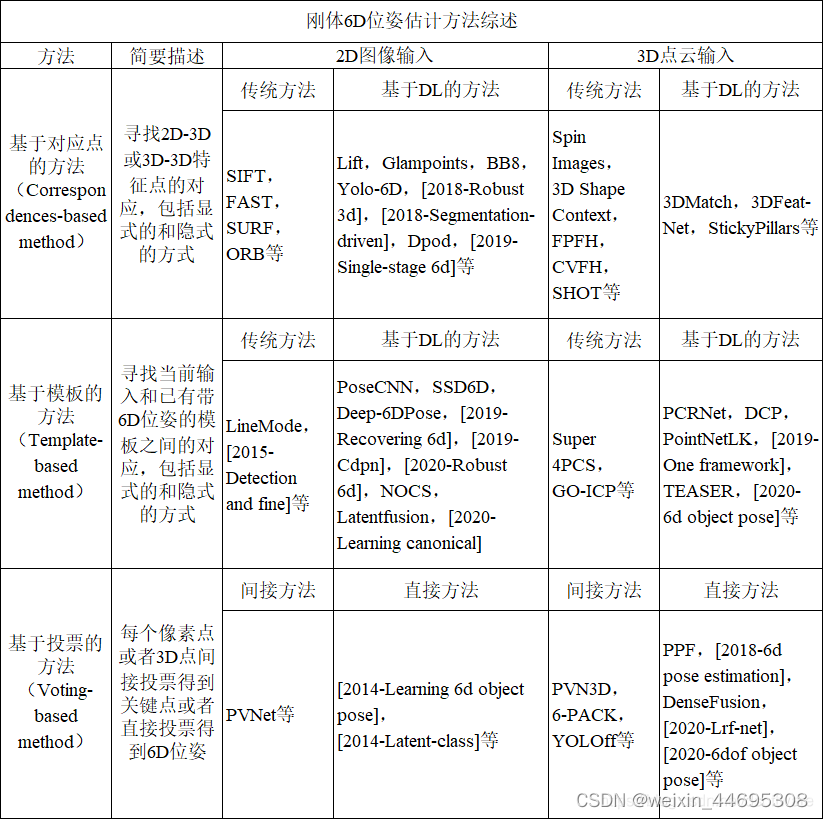
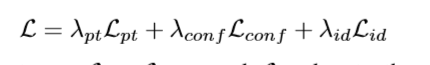转载请注明作者和出处: http://blog.csdn.net/john_bh/
paper 地址:GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
作者及团队: 王谷 & 季向阳 团队 & 清华大学 & 字节跳动 & 谷歌
会议及时间:CVPR 2021
code:https://git.io/GDR-Net
视频:
文章目录
- 1. 主要贡献
- 2. Method
- 2.1 Parameterization of 3D Rotation
- 2.2 Parameterization of 3D Translation
- 2.3 Disentangled 6D Pose Loss
- 2.4 Network Architecture
- 2.5 Dense Correspondences Maps ( M 2 D − 3 D M_{2D-3D} M2D−3D)
- 2.6 Surface Region Attention Maps (MSRA)
- 2.7 Geometry-guided 6D Object Pose Regression
- 2.8 Decoupling Detection and 6D Object Pose Estimation
- 3. 实验
- 3.1 实验结果
- 3.2 运行时间
- 4.结论
1. 主要贡献
在基于RGB 图像的 物体6DoF 姿态估计任务中,目前表现好的算法模型的是基于间接的方法,首先建立图像平面与物体坐标系的 2D-3D 坐标对应关系,然后使用 PnP/ RANSAC算法 。这种two-stage pipeline 方法不是 end-to-end 可训练的,因此很难用于许多需要可微分姿态的任务。另一方面,目前基于直接回归的方法不如基于几何的方法。
这种 correspondences 间接的方法虽然效果号,但是依然存在一些问题:
- 这种方法通常使用对应回归的代理目标进行训练(关键点),并不一定反映优化后的6DoF姿态误差的实际情况,例如具有相同误差,两组对应在描述完全不同的姿态时可能有相同的平均误差。
- 这种间接的方法对6DoF 姿态估计是不可微的,限制了学习。例如不能与从未标记的真实数据中进行的自我监督学习相结合,因为它们要求位姿的计算是完全可微的,以获得数据和位姿之间的信号。
- 当处理稠密对应时 RANSAC 迭代是比较耗时的(time-comsuming)
针对以上问题,作者提出一下解决方法:
- 提出了一种简单而有效的几何引导直接回归方法网络(GDR-Net);
- 提出从基于密集对应的中间几何表示中以端到端方式学习6D位姿网络 patch-PnP;
主要参考文章和技术:
- 主要的网络结构参考作者自己之前的工作 CNPN (ICCV 2019 oral), 包括 Dynamic Zoom-in, Scale-Invariant representation for Translation Estimation (SITE);
- M S R A M_{SRA} MSRA 来自论文 EPOS (CVPR 2020);
- 关键点的选取使用算法 farthest points sampling (FPS);
- Rotation 的表示方法 R 6 d R_{6d} R6d 参考论文 On the Continuity of Rotation Representations in Neural Networks (CVPR 2019)
- allocentic representation of the rotation R a 6 d R_{a6d} Ra6d 参考文章 3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compare (CVPR 2018)

2. Method

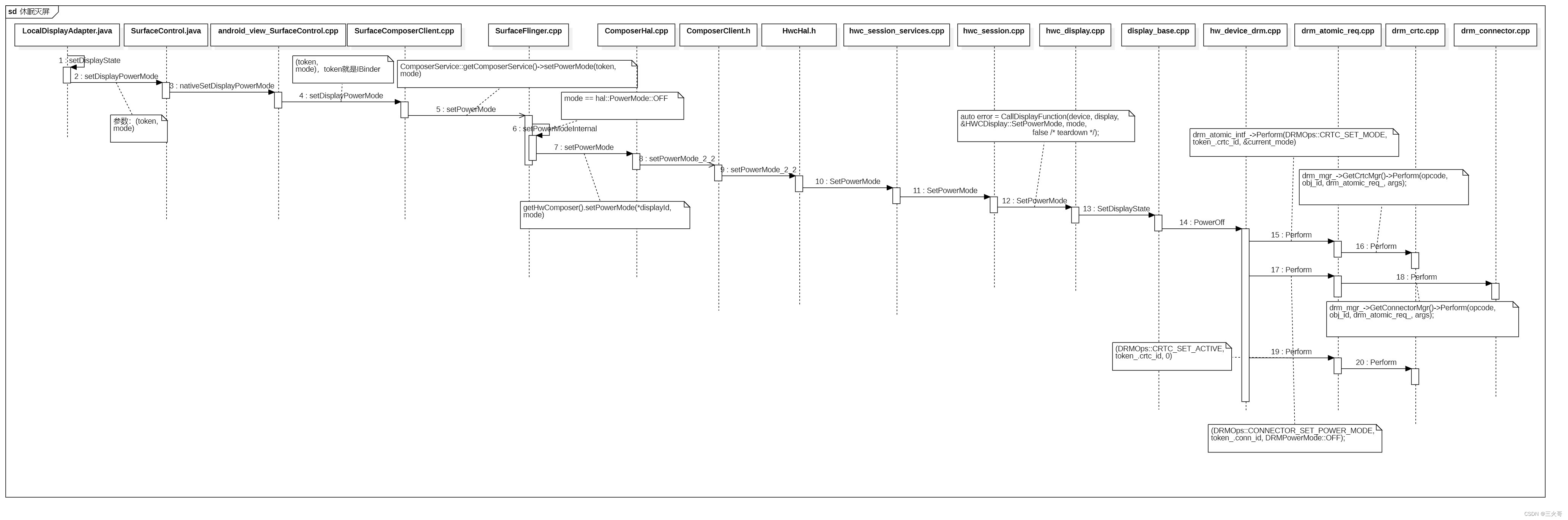
如图2所示,作者首先使用检测器检测图像中的物体,然后在训练中使用Dymic zoom in 对应的 RoI 进行数据增强,在测试的时候则不使用DZI; 然后 feed into 网络中提取几何特征( M 2 D − 3 D M_{2D-3D} M2D−3D 和 M S R A M_{SRA} MSRA),最后直接回归 6DoF 姿态估计。
2.1 Parameterization of 3D Rotation
存在不同的旋转向量 表示方法来表示 3D rotation。但是为许多表示表现出歧义,例如 R i ≠ R j R_i \neq R_j Ri=Rj, 但是却表示同样的旋转,所以一般选择 单位四元数(unit quaternion),对数四元数 ( log quaternion),基于李代数的向量 ( Lie algebra-based vectors )。然而,众所周知,对于三维旋转,所有具有四维或更小维的表示在欧几里得空间中都有不连续。当对旋转进行回归时,会引入一个接近不连续点的误差,这个误差往往会变得非常大。
为了克服这个限制,[65]在 S O ( 3 ) SO(3) SO(3)中提出了一种新的连续6维 R R R 表示,并且已经被证明它的有效性 (CosyPose ECCV2020)。具体来说,就是6维的表示 R 6 d R_{6d} R6d定义为R的前两列:

给定一个 6维向量 R 6 d = [ r 1 ∣ r 2 ] R_{6d}=[r_1|r_2] R6d=[r1∣r2],旋转矩阵 R = [ R . 1 ∣ R . 2 ∣ R . 3 ] R=[R_{.1|R_{.2}|R_{.3}}] R=[R.1∣R.2∣R.3] 可以通过计算得出:

ϕ ( ∙ ) \phi(\bullet) ϕ(∙)表示向量归一化操作。
鉴于这种表示的优点,作者使用 R 6 d R_{6d} R6d参数化 3 D 3D 3D旋转。进一步提出让网络预测旋转 R 6 d R_{6d} R6d的异中心表示,这种表示方式很受欢迎,因为它在物体的3D平移下是视点不变的,更适合处理 zoomed-in 的 RoI。注意,给定3D平移和摄像机固有K,自中心旋转可以很容易地从异中心旋转转换。
2.2 Parameterization of 3D Translation
直接回归三维空间的平移变量 t = [ t x , t y , t z ] t=[t_x,t_y,t_z] t=[tx,ty,tz] 的实际效果不好,之前的工作通常将 translation 解耦到 3D质心投影到 2D位置 ( o x , o y ) (o_x,o_y) (ox,oy)和物体朝向相机的距离 t z t_z tz 。给定相机内参 K K K,translation 可以通过反向投影计算的出:

之前有的方法将物体bounding box 的中心 c x , c y c_x,c_y cx,cy 近似等于物体中心 o x , o y o_x,o_y ox,oy, 使用参考相机距离估计 t z t_z tz 。尽管如此,这并不适合处理zoom -in RoI ,对于网络来说 估计位置和尺度不变参数是至关重要的。因此作者采用 之前工作 CDPN 中的方法 SITE(scale invariant representation for translation estimation)。具体地,给定输入图像大小bounding box s o = m a x ( w , h ) s_o=max(w,h) so=max(w,h) 和中心 c x , c y c_x,c_y cx,cy,放缩比例 r = s z o o m / s o r=s_{zoom}/s_o r=szoom/so,其中 s z o o n g s_{zoong} szoong 表示 zoom-in 的大小,网络回归 尺度不变的translation 参数 t S I T E = [ δ x , δ y , δ z ] T t_{SITE}=[\delta_{x},\delta_{y},\delta_{z}]^{T} tSITE=[δx,δy,δz]T,如下:

2.3 Disentangled 6D Pose Loss
除了旋转和平移的参数化,损失函数的选择也是6D位姿优化的关键。而不是直接利用基于旋转和平移的距离(例如,角距离, L 1 L_1 L1或 L 2 L_2 L2距离),大多数作品采用基于ADD(-S)度量的 Point-Matching loss 。作者采用解耦6D 姿态损失:

为了解释对称物体,给定 $R $,对称下所有可能的ground-truth旋转的集合,进一步将损失扩展到对称感知公式 L R , s y m = m i n R ∈ R L R ( R ^ , R ˉ ) \mathcal{L}_{R,sym}=min_{R\in \mathcal{R} }\mathcal{L}_R(\hat R,\bar R) LR,sym=minR∈RLR(R^,Rˉ)。
2.4 Network Architecture
GDR-net 网络参考CDPN 的结构设计,保留了regressing M X Y Z M_{XYZ} MXYZ和 M v i s M_{vis} Mvis的层,同时去掉了分离的 translation head。此外,将 M S R A M_{SRA} MSRA所需的通道添加到输出层。由于这些中间几何特征图都是的2D-3D对应图像,采用了一种简单而有效的2D卷积Patch-PnP模块直接从 M 2 D − 3 D M_{2D-3D} M2D−3D和 M S R A M_{SRA} MSRA回归6D目标位姿。
Patch-PnP模块由三个卷积层组成,内核大小为 3 × 3 3\times 3 3×3,stride为2,每个卷积层后面是Group Normalization 和ReLU激活。两个
全连接(FC)层应用于flattened feature,将维数从8192减少到256。最后,两个平行的FC层分别输出参数化为 $R_{6d} $(Eq. 1)的3D旋转 R R R和参数化为 t S I T E t_{SITE} tSITE(Eq. 4)的3D平移 t t t。
2.5 Dense Correspondences Maps ( M 2 D − 3 D M_{2D-3D} M2D−3D)
为了计算密集对应映射 M 2 D − 3 D M_{2D-3D} M2D−3D,首先估计密集坐标映射( M X Y Z M_{XYZ} MXYZ)。 M 2 D − 3 D M_{2D-3D} M2D−3D可以通过将 M X Y Z M_{XYZ} MXYZ stacking onto 相应的2 d像素坐标 得到。特别是,给定物体的CAD模型, M X Y Z M_{XYZ} MXYZ可以通过绘制模型的三维物体坐标得到相关的姿态。与[28,56]类似,让网络预测 M X Y Z M_{XYZ} MXYZ的规范化表示。具体来说, M X Y Z M_{XYZ} MXYZ的每个通道 通过 ( l x , l y , l z ) (l_x,l_y,l_z) (lx,ly,lz) 正则化到 [ 0 , 1 ] [0,1] [0,1]之间,它是对应三维 CAD模型的 bounding box 的大小。
注意,M2D-3D不仅编码了2D-3D的对应关系,而且还明确地反映了对象的几何形状信息。此外,如前所述,由于M2D-3D是图像可以通过一个简单的2D卷积神经网络(Patch-PnP)来学习6D对象的姿态。
2.6 Surface Region Attention Maps (MSRA)
受[15]的启发,作者让网络预测表面区域,作为额外的模糊感知监督。但是,没有将它们与RANSAC耦合,而是在Patch-PnP框架中使用它们。
ground-truth 区域 M S R A M_{SRA} MSRA可以从 M X Y Z M_{XYZ} MXYZ采用 farthest points sampling 得到。
对于每个像素,对相应的区域进行分类,从而隐式地得到预测 M S R A M_{SRA} MSRA中物体的对称性的概率。例如,如果一个像素由于对称面被分配给两个可能的碎片,对于每个片段,最小化这个赋值将返回0.5的概率。此外,利用$M_{SRA}$不仅减轻了歧义的影响,而且还充当了$M_{3d}$之上的辅助任务。换句话说,它简化了$M_{3d}$的学习,首先定位粗区域,然后回归更细的坐标。 利用 M S R A M_{SRA} MSRA作为对称感知的注意来指导Patch-PnP的学习。
2.7 Geometry-guided 6D Object Pose Regression
利用基于图像的几何特征patch M S R A M_{SRA} MSRA 和 M 2 D − 3 D M_{2D-3D} M2D−3D 指导Path-PnP直接回归物体6DoF 姿态:

对标准化的 M X Y Z M_{XYZ} MXYZ和可见mask M v i s M_{vis} Mvis 采用L1损失,对 M S R A M_{SRA} MSRA使用交叉熵损失(CE):

GDR-net 的损失函数可以总结为:
L G D R = L P o s e + L G e o m \mathcal {L}_{GDR}=\mathcal {L}_{Pose}+\mathcal {L}_{Geom} LGDR=LPose+LGeom
2.8 Decoupling Detection and 6D Object Pose Estimation
GDR-net 主要关注物体姿态估计工作,允许直接在运行时中使用其他目标检测器的二维目标检测结果,无需改变或重新训练姿态网络。因此,作者采用简化的dynamic zoom-in (DZI)来解耦GDR-Net和目标探测器的训练。在训练期间,首先以25%的比例均匀地移动ground-truth包围盒的中心和比例。然后zoom-in 输入基于 r = 1 : 5 r = 1:5 r=1:5原始高宽比 的RoI(这确保了包含对象的区域大约是RoI的一半)。DZI还可以避免处理不同对象大小的需要。
3. 实验
3.1 实验结果
实验就不在赘述了,可以去看原文的实验结果。这里放上几张实验结果:




3.2 运行时间
在 配置为 Intel 3.4 GHz CPU 和 NVIDIA2080Ti GPU 的 desktop 上,输入 640 × 480 640\times 480 640×480 图像,使用YOLOv3作为检测器,单个物体的推理时间大概22ms,8个物体大概35ms,其中包括15ms的目标检测。
4.结论
总的来讲,作者重新讨论了直接6D位姿回归的方法,并提出了一个新的GDR-Net来统一直接方法和基于几何的间接方法。其核心思想是利用中间几何特征 M 2 D − 3 D M_{2D-3D} M2D−3D 和 M S R A M_{SRA} MSRA 使用简单而有效的2D卷积Patch-PnP直接从几何制导回归6D位姿。这种end-to-end 的方法效果可达到two-stage 的效果,工作确实很优秀,另外作者团队一直都在做这样的的研究,从DeepIM ,CDPN, self-6D, GDR-Net,还有SO-Pose,论文质量都挺高的。