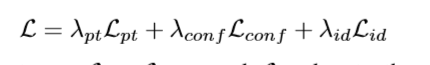提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、基本知识
- 6D位姿
- 相机内参
- 二、6D位姿估计方法
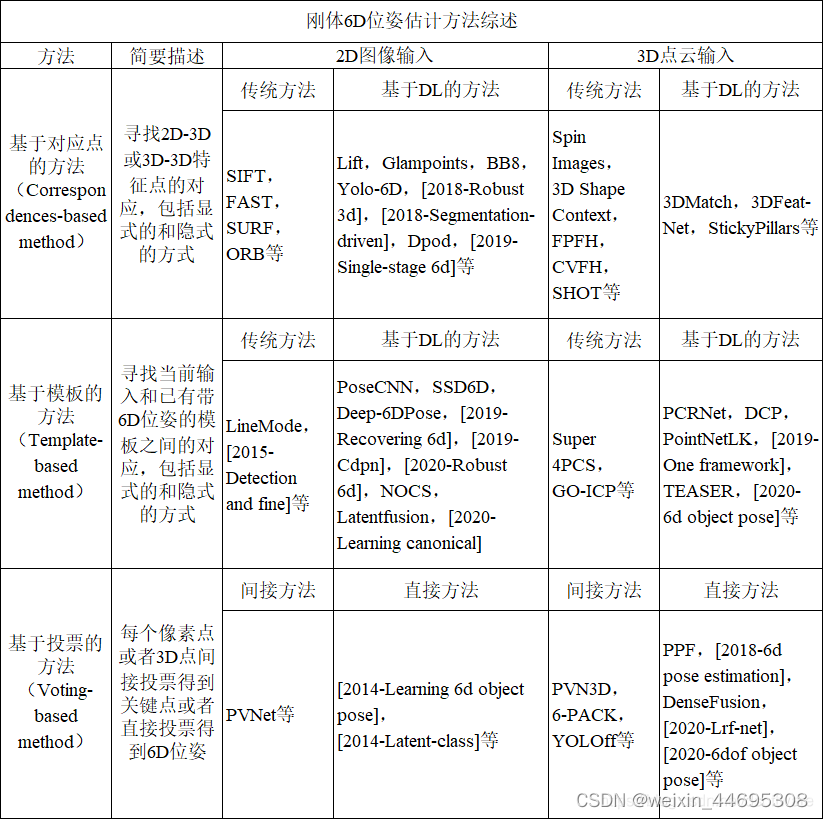
- 1.基于对应点的方法
- 2.基于模板
- 3.基于投票
- 评价标准
- 小结
一、基本知识
6D位姿
参见文章:物体6D位姿的含义
6D位姿,即3D位置和3D姿态(朝向),可以认为是相对概念,代表两个坐标系之间相对的位移和旋转;即拍摄时,相机坐标系相对于原始物体所在世界坐标系的平移和旋转变换[R,T];其中R的方向为旋转轴的方向,模长为旋转角大小,为逆时针。
我们所估计的6D位姿是物体6D位姿(等价于相机外参),即从物体所在的坐标系(以物体的重心为原点)到相机坐标系(以相机光心为原点)的旋转和平移,故即使在同一个场景下,不同物体的6D位姿也不同,但他们所在的相机坐标系是一致的。用公式表示为:Tc=R*Tm+t
其中为Tc物体在相机系的坐标,Tm为物体在世界系的坐标,R、t分别为旋转矩阵和平移向量。若将坐标扩充为4维T=[T 1]T,该公式也可以表示为:*Tc=[R t]Tm
- 在世界系到相机系的变换过程中,可以假设有一个中间坐标系,该坐标系的原点与世界系一致,基与相机系一致。即中间坐标系的坐标与世界系只需要旋转:Tz=R*Tm,与相机系只需要平移:Tc=Tz+t
- 旋转矩阵R的特点:旋转矩阵(Rotate Matrix)的性质分析
相机内参
参见文章:一文带你搞懂相机内参外参
如下图所示,真实世界坐标为[x,y,z],像素平面坐标为[u,v,1]两者通过相机内参矩阵K变换
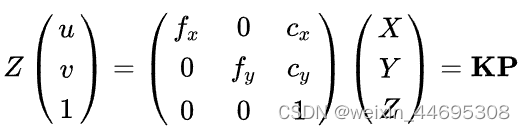
二、6D位姿估计方法
- PNPnet:找若干匹配的点对,知道这些点对在物体坐标系和相机2维坐标系中的位置,由此求出R、T矩阵
1.基于对应点的方法
主要使用特征点
- 对纹理丰富的2D图像:将3D模型投影到多个方向得到N张2D模板,并记录对应关系;对新图像,提取特征点与2D模板对应,由PnP算法求得6D位姿;
- 对弱纹理2D:借助深度学习
- 对3D点云:最小二乘法
2.基于模板
使用整体。对模型构造多个模板,模板含有位姿信息。目标物体与哪一个模板接近,就使用该模板的位姿;。
- 2D图像:模板是模型在各个方向的2D投影,转为图像检索问题
- 3D点云:模板是目标物体的完整点云,转为单视角点云和完整点云的全局配准问题。
3.基于投票
使用基元,每个像素或3D点都对整体有影响。分为间接投票、直接投票。
- 间接投票(多见于深度学习)
每个像素或3D点对特征点投票,再通过PnP或最小二乘法—例如6PACK - 直接投票
每个像素或3D点直接对6D位姿投票.通过生成大量位姿预测,再进行选择和优化,可以得到最终的位姿。
评价标准
-
非对称物体:ADD度量,即预测的RT和实际的RT分别作用在点云上后,所有点的平均偏差。
-
对称物体:ADD-S度量,考虑到对称性,寻找变换后,每一点到另一片点云的最近邻点,计算他们的平均距离偏差。
对于LineMod数据集,度量结果<模型直径的10%即估计正确;
对于YCB-Video数据集,常用ADD-S度量,而且阈值经常设置为2cm(面向抓取应用),而且ADD-S曲线下的面积(AUC)也被使用,其阈值设为10cm。
小结
对于纹理清晰的目标,常用基于对应的方法;无纹理或弱纹理,多用基于模板的方法;而对于有部分遮挡的目标,多采用基于投票的方法。
目前的问题:1.遮挡场景下的位姿估计效果并不好。2.即使是基于深度学习的方法,当前的数据集也不足够。
未来方向:1.如何得到可靠且大量的数据;2.如何降噪;3.仿真和现实的差距如何缩小;4.如何估计被遮挡不可见物体的6D位姿