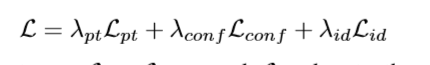本文同步于微信公众号:3D视觉前沿,欢迎大家关注。
1 引言
刚体的6D位姿估计,是指估计相机坐标系下物体的6D位姿,即3D位置和3D姿态,此时原始物体本身的坐标系可以看作是世界坐标系,也即得到原始物体所在世界系到相机系的RT变换。刚体是指物体不会弯曲变形(手),也不存在活动关节(胳膊)。刚体的6D位姿估计的意义在于能够获得物体的精确姿态,支撑对于物体的精细操作,主要应用于机器人抓取领域和增强现实领域。在机器人抓取领域,主流的方法是估计已知物体的6D位姿,进而获得抓取器的目标6D抓取位姿。在增强现实领域,可以在物体上叠加虚拟元素,随着物体的移动而保持和物体相对位姿不变。随着SLAM等技术的成熟,机器人已经能够在空间中进行很好的定位,但如果想要和环境中的物体进行交互,物体的6D位姿估计是必需的技术,也会持续成为研究热点。本文来自论文https://arxiv.org/abs/1905.06658,涉及的论文也都可以在论文中找到,也包含于 GitHub,转载请注明出处,有错误请指正,欢迎大家多交流 ^ _ ^
2 回顾
刚体的6D位姿估计按照使用的输入数据,可以分为基于2D图像的方法和基于3D点云的方法。早期基于2D图像的6D位姿估计方法处理的是纹理丰富的物体,通过提取显著性特征点,构建表征性强的描述符获得匹配点对,使用PnP方法恢复物体的6D位姿。对于弱纹理或者无纹理物体,可以使用基于模板的方法,检索得到最相似的模板图像对应的6D位姿,也可以通过基于机器学习的投票的方法,学习得到最优的位姿。
随着2011年以kinect为代表的的廉价深度传感器的出现,在获取RGB图像的同时可以获得2.5D的Depth图像,进而可以辅助基于2D图像的方法。为了不受纹理影响,也可以只在3D空间操作,此时问题变成获取的单视角点云到已有完整物体点云的part-to-whole配准问题。如果物体几何细节丰富,可以提取显著性3D特征点,构建表征性强的描述符获得3D匹配点,使用最小二乘获得初始位姿;也可以使用随机采样点一致算法(Ransac)获得大量候选6D位姿,选择误差最小的位姿。
自2012年始,深度学习在2D视觉领域一骑绝尘,很自然的会将深度学习引入到物体6D位姿估计,而且是全方位的,无论是基于纯RGB图像、RGB和Depth图像、还是只基于3D点云,无论是寻找对应、寻找模板匹配、亦或是进行投票,都展现了极好的性能。
随着在实例级物体上的6D位姿估计趋于成熟,开始涌现了类别级物体6D位姿估计的方法,只要处理的物体在纹理和几何结构上近似,就可以学习到针对这一类物体的6D位姿估计方法,这将极大提升这项技术在机器人抓取或者AR领域的实用性。
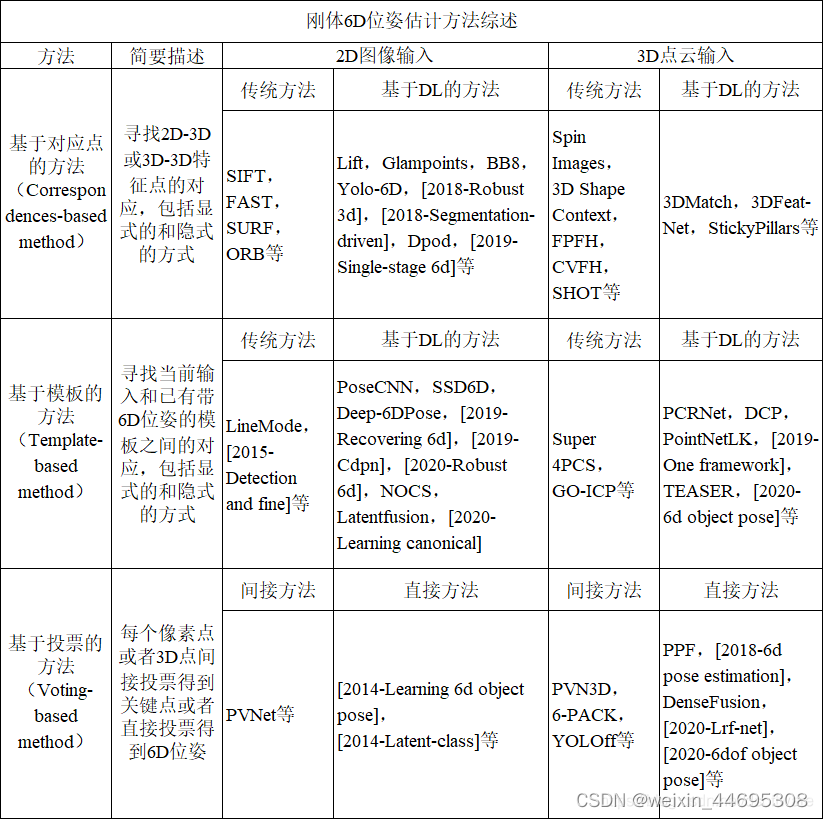
本文分别介绍基于2D图像和基于3D点云的,基于对应(Correspondence-based)、模板(Template-based)和投票(Voting-based method)的物体6D位姿估计方法,综合如下表。

表1 刚体6D位姿估计方法综述
3 基于对应的方法
这类方法的是指寻找输入数据和已有物体的完整3D点云之间的对应,如果输入的是2DRGB图像,可找到2D像素点和3D物体点之间的对应,进而使用PnP算法计算;如果输入的是3D点云,则可以使用3D特征描述符寻找输入点云中3D点和已有完整物体3D点之间的对应,使用最小二乘法获得6D位姿;两类输入都可以使用局部配准方法如ICP进行优化。

图1 输入2D图像的基于对应的方法
基于2D图像的方法主要针对纹理丰富的物体,3D模型首先投影到N个角度,得到N张模板RGB图像,记录3D点和2D像素之间的对应;采集单个视角下RGB图像后,提取特征点如SIFT,FAST,SURF,ORB等,寻找和模板图像之间的对应(2D-2D);这样我们得到了3D点和当前观测RGB图像2D像素点的对应,使用Perspective-n-Point(PnP)算法即可恢复当前视角图像的位姿(类似基于特征点vSLAM中的重定位过程)。除了传统的特征描述子,也出现了基于深度学习的特征描述子例如Lift,Glampoints等。
除了显式寻找特征点之间的对应,也出现了很多基于深度学习的方法,隐式地预测3D点在2D图像上的投影,进而使用PnP算法估计6D位姿。物体上特征点的选择不是那么直接,因此很多方法预测物体最小3D包围盒的8个顶点在2D图像上的投影,例如BB8[2017-Bb8]和Yolo-6D[2018-Real-time]。一些方法构建局部3D控制点,预测3D控制点在2D图像上的投影点,例如 [2018-Robust 3d]。包围盒的投影点有可能落在图像外,一些其他方法预测2D图像上的物体区域对应的所有3D点,通常借助物体坐标系(3D空间每一个点对应一个颜色值),例如[2018-Segmentation-driven],Dpod[2019-Dpod],[2019-Single-stage 6d]。

图2 输入3D点云的基于对应的方法
基于3D点云的方法主要基于3D特征描述符寻找两片点云之间的对应。常用的3D局部特征描述符,如Spin Images,3D Shape Context,FPFH,CVFH,SHOT等都可以使用,一些基于深度学习的3D描述符例如3DMatch,3DFeat-Net和StickyPillars等也可以使用。
4 基于模板的方法
这类方法是从标记好6D位姿的模板中,选择最相似的模板,将其6D位姿作为当前物体的6D位姿。这类方法针对的是弱纹理或者无纹理图像,也即Correspondence-based methods很难处理的情况;在2D情况下,模板通常为已知3D模型在不同角度下的投影图像,每个投影图像都对应一个物体的6D位姿,此时问题变成了一个图像检索的问题。在3D情况下,模板是指目标物体的完整点云,需要寻找到,能够使输入的单视角点云对齐到完整点云的最佳6D位姿,此时问题转变为一个部分配准问题。

图3 输入2D图像的基于模板的方法
基于2D图像方法的代表方法是LineMode方法[2012-Model based],通过比较观测RGB图像和模板RGB图像的梯度信息,寻找到最相似模板图像,以该模板对应的位姿作为观测图像对应的位姿,该方法还可以结合深度图的法向量来提高精度;[2015-Detection and fine]也利用了模板匹配策略。除了显式寻找最相似的模板图像外,也有方法隐式地寻找最近似的模板,代表性方法是AAE[2018-Implicit 3d]。该方法中,上万模板图像通过编码形成码书,输入图像变成一个编码和码书进行比较寻找到最近似的模板。
一些方法直接从图像中恢复目标物体的6D位姿,这个过程可以看作从已训练的带标签的图像中,寻找和当前输入图像最近似的图像,并且输出其对应的6D位姿标签。这类方法直接寻找输入图像到位姿参数空间的映射,而且较易和目标检测框架结合。这类方法较多,代表性的有PoseCNN[2017-Posecnn],SSD6D[2017-Ssd-6d],Deep-6DPose[2018-Deep-6dpose],[2019-Recovering 6d],[2019-Cdpn],[2020-Robust 6d]等。另外一类方法能够针对一类物体构建隐式表示,这类方法也可以看作是基于模板的方法,代表性的有NOCS[2019-Normalized],[2019-Latentfusion],[2020-Learning canonical]等。

图4 输入3D点云的基于模板的方法
基于3D点云的方法主要为多种全局配准方法,如Super 4PCS[2014-Super 4PCS]和GO-ICP[2015-Go-icp]等,能够得到相对准确的6D位姿,结果可以使用ICP进行优化。一些深度学习进行两片点云配准的方法也涌现出来,包括PCRNet [2019-Pcrnet], DCP [2019-Deep closest point], PointNetLK [2019-Pointnetlk],[2019-One framework], TEASER [2020-Teaser]等。在进行配准时,可以将多个视角拼合使输入数据更完整,也可以将完整物体投影多个角度得到多个单片点云,从而辅助配准。也有一些方法,不需要输入两片点云,给定单个视角点云,能够直接回归6D位姿,例如[2020-6d object pose regression via supervised learning on point cloud]。
5 基于投票的方法
这类方法是指每个像素或者每个3D点通过投票,贡献于最终的6D位姿估计。依据是图像中的每一个局部都能够对整体的输出产生投票,对遮挡情况较为有效。基于对应的方法主要使用特征点,基于模板的方法主要使用整体,基于投票的方法每个基元都进行贡献。存在两类投票策略,分别为间接投票和直接投票。间接投票是指每个像素或者3D点投票得到预定义的特征点,能够得到2D-3D或者3D-3D的对应。直接投票是指每个像素或3D点直接投票得到一个确定的6D物体坐标系或者6D位姿。

图5 基于间接投票的方法
间接投票方法中,2D输入的代表性方法为PVNet[2018-PVNet],投票得到一系列3D点在2D图像上的投影点像素坐标。3D输入情况下,代表性方法有PVN3D[2019-PVN3D],6-PACK[2019-6-pack],YOLOff[2020-Yoloff]等,直接基于3D深度神经网络,投票得到3D特征点,进而使用最小二乘法得到相对位姿。其中6-PACK能够处理类别级物体的6D位姿估计。

图6 基于直接投票的方法
直接投票方法中,通过生成大量位姿预测,再进行选择和优化,可以得到最终的位姿。2D输入的代表性方法有[2014-Learning 6d object pose]和[2014-Latent-class],3D输入的代表性方法有PPF[2012-3d object detection],[2018-6d pose estimation]。基于深度学习的有DenseFusion[2019-Densefusion],分别对RGB图像和Depth对应3D点云使用3DCNN网络得到融合的pixel-wise dense feature,每一个feature都能预测一个姿态,最后通过投票得到最后的6D姿态。此外还有[2020-Lrf-net],[2020-6dof object pose]等。
6 方法对比与总结
基于点云配准的方法可以参照一些综述,这里主要比较基于RGB-D的方法,也即在数据集LineMode[2012-Model based],Occlusion Linemod[2014-Learning 6d object pose]和YCB-Video[2015-The YCB]数据集上进行评测的方法。评测度量主要有针对非对称物体的ADD度量,和针对对称物体的ADD-S度量。ADD大意是指按照估计RT和真值RT分别作用于点云后,所有点的平均距离偏差。ADD-S考虑到对称物体,寻找变换后,每一点到另一片点云的最近邻点,计算他们的平均距离偏差。评测时对LineMod数据集中的非对称物体就用ADD度量,对称物体就用ADD-S度量,如果度量结果小于模型直径的10%,则认为位姿估计正确。对于YCB-Video数据集,经常用的度量是ADD-S度量,而且阈值经常设置为2cm(面向抓取应用),而且ADD-S曲线下的面积(AUC)也被使用,其阈值设为10cm。
在LineMode和Occlusion Linemod,YCB-Video上的对比结果如下面两个表所示,可以看到当前方法都得到了非常高的精度,已经能够满足实例级别物体6D位姿估计的需要,具体采用哪一种方法可以依据当前可获得的数据,需要的算力,要求的精度等等来选择。常用的构建自己数据集的方法有LabelFusion[2018-Label Fusion]。后续方向会逐步扩展到泛化能力,也即类别级物体的6D位姿估计。


参考文献
2012-Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes
2012-3d object detection and localization using multimodal point pair features
2014-Learning 6d object pose estimation using 3d object coordinate
2014-Latent-class hough forests for 3d object detection and pose estimation
2014-Super 4PCS: Fast Global Pointcloud Registration via Smart Indexing
2015-Detection and fine 3d pose estimation of texture-less objects in rgb-d images
2015-Go-icp: A globally optimal solution to 3d icp point-set registration
2015-The YCB object and model set: Towards common benchmarks for manipulation research
2017-Bb8: a scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth
2017-Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes
2017-Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again
2018-6d pose estimation using an improved method based on point pair features
2018-Deep-6dpose: recovering 6d object pose fromasinglergbimage
2018-Implicit 3d orientation learning for 6d object detection from rgb images
2018-Label Fusion: A Pipeline for Generating Ground Truth Labels for Real RGBD Data of Cluttered Scenes
2018-Learning to predict dense correspondences for 6d pose estimation
2018-PVNet Pixel-wise Voting Network for 6DoF Pose Estimation
2018-Real-time seamless single shot 6d object pose prediction
2018-Robust 3d object tracking from monocular images using stable parts
2018-Segmentation-driven 6d object pose estimation
2019-6-pack: Category-level 6d pose tracker with anchor-based keypoints
2019-Cdpn: Coordinates-based disentangled pose network for realtime rgb-based 6-dof object pose estimation
2019-Deep closest point: Learning representations for point cloud registration
2019-Densefusion: 6d object pose estimation by iterative dense fusion
2019-Dpod: 6d pose object detector and refiner
2019-Latentfusion: End-to-end differentiable reconstruction and rendering for unseen object pose estimation
2019-Normalized object coordinate space for category-level 6d object pose and size estimation
2019-One framework to register them all: Pointnet encoding for point cloud alignment
2019-Pcrnet: Point cloud registration network using pointnet encoding
2019-Pointnetlk: Robust & efficient point cloud registration using pointnet
2019-PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
2019-Recovering 6d object pose from rgb indoor image based on two-stage detection network with multi-task loss
2019-Single-stage 6d object pose estimation
2020-6d object pose regression via supervised learning on point clouds
2020-6dof object pose estimation via differentiable proxy voting loss
2020-Learning canonical shape space for category-level 6d object pose and size estimation
2020-Lrf-net: Learning local reference frames for 3d local shape description and matching
2020-Robust 6d object pose estimation by learning rgb-d features
2020-Teaser: Fast and certifiable point cloud registration
2020-Yoloff: You only learn offsets for robust 6dof object pose estimation