深度学习面试题
- 1.深度学习常用算法,及相应应用场景有哪些
- 2.什么数据集不合适做深度学习
- 3.如何确定CNN卷积核通道数和卷积输出层的通道数
- 4.什么是卷积
- 5.什么是CNN的池化层(pool)
- 6.CNN常用的几个模型
- 7.CNN的特点以及优势
- 8.卷积神经网络CNN中池化层作用
- 9.常见的激活函数,激活函数有什么作用
- 10.简述一下sigmoid函数
- 11.CNN关键层有哪些
- 12.什么是梯度爆炸
- 13.梯度爆炸会引发什么问题
- 14.如何确定是否出现梯度爆炸
- 15.如何修复梯度爆炸问题
- 重新设计网络模型
- 使用 ReLU 激活函数
- 使用长短期记忆网络
- 使用梯度截断(Gradient Clipping)
- 使用权重正则化(Weight Regularization)
- 16.什么是RNN
- 17.在神经网络中,有哪些办法防止过拟合
- 18.如何解决深度学习中模型训练效果不佳的情况
1.深度学习常用算法,及相应应用场景有哪些
- DNN是传统的全连接网络,可以用于广告点击率预估,推荐等。其使用embedding的方式将很多离散的特征编码到神经网络中,可以很大的提升结果
- CNN主要用于计算机视觉(Computer Vision)领域,CNN的出现主要解决了DNN在图像领域中参数过多的问题。同时,CNN特有的卷积、池化、batch normalization、Inception、ResNet、DeepNet等一系列的发展也使得在分类、物体检测、人脸识别、图像分割等众多领域有了长足的进步。同时,CNN不仅在图像上应用很多,在自然语言处理上也颇有进展,现在已经有基于CNN的语言模型能够达到比LSTM更好的效果。在最新的AlphaZero中,CNN中的ResNet也是两种基本算法之一
- GAN是一种应用在生成模型的训练方法,现在有很多在CV方面的应用,例如图像翻译,图像超清化、图像修复等等
- RNN主要用于自然语言处理(Natural Language Processing)领域,用于处理序列到序列的问题。普通RNN会遇到梯度爆炸和梯度消失的问题。所以现在在NLP领域,一般会使用LSTM模型。在最近的机器翻译领域,Attention作为一种新的手段,也被引入进来
2.什么数据集不合适做深度学习
1、数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
2、数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果
3.如何确定CNN卷积核通道数和卷积输出层的通道数
CNN的卷积核通道数 = 卷积输入层的通道数;CNN的卷积输出层通道数 = 卷积核的个数
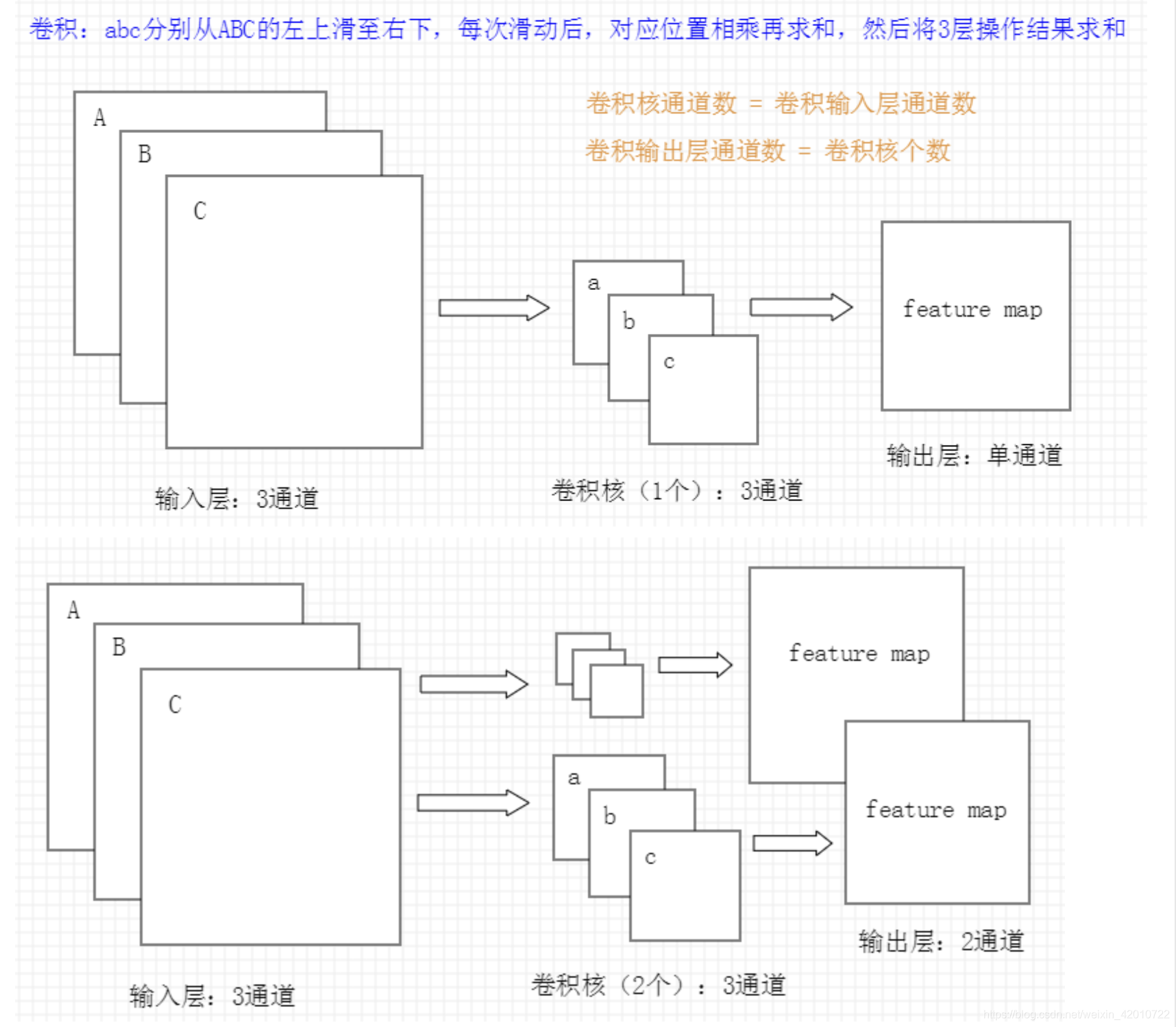
4.什么是卷积
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作
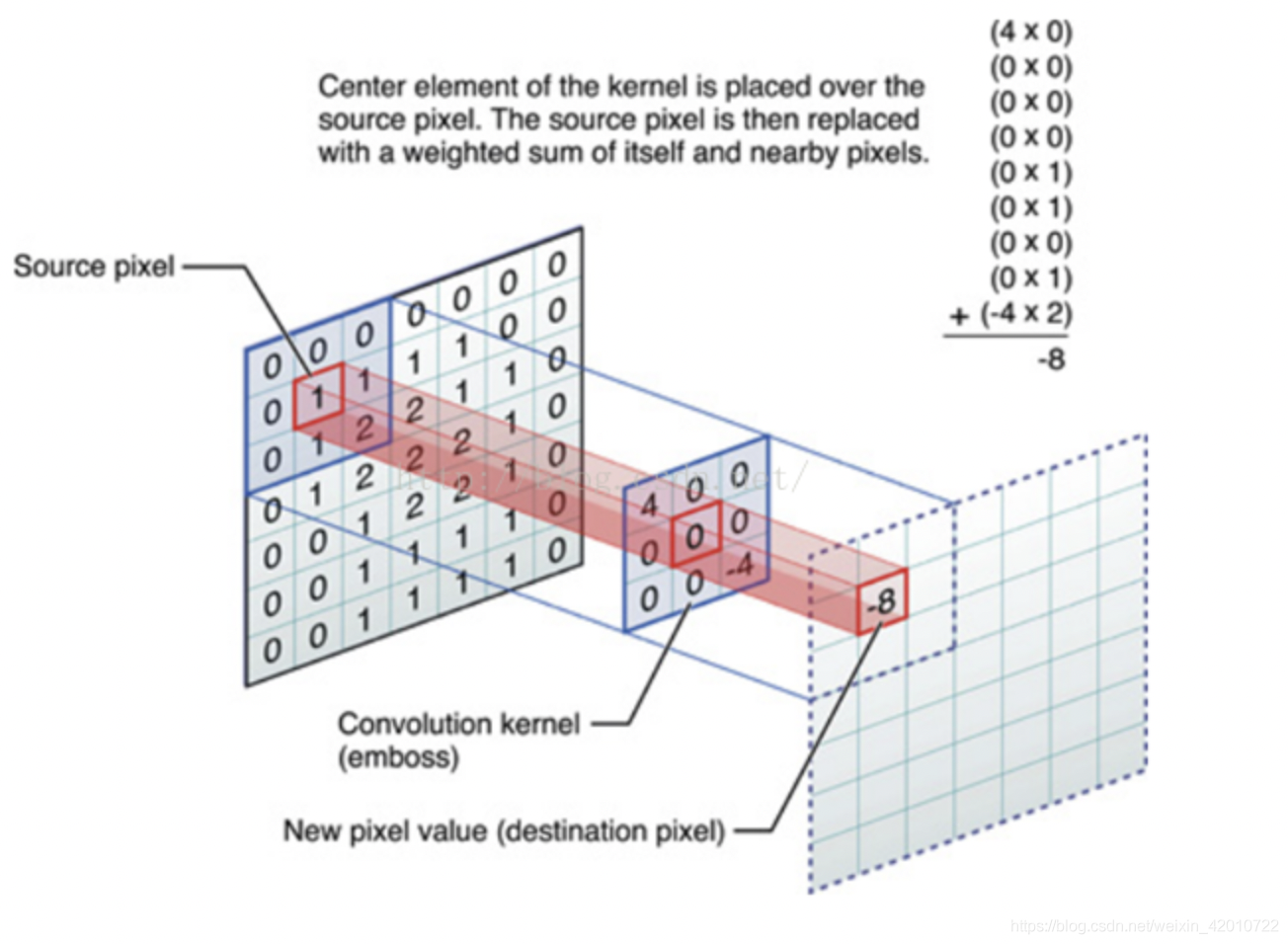
5.什么是CNN的池化层(pool)
池化,简言之,即取区域平均或最大

上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。
6.CNN常用的几个模型
- LeNet5传统的CNN模型
- AlexNet引入了Relu和dropout,引入数据增强、池化相互之间覆盖,三个卷积一个最大池化+三个全连接层
- VGGNet采用11和33的卷积核以及2*2的最大池化层使得层数变得更深,常用VGGNet16和VGGNet19
- Google Inception Net去除了最后CNN的全连接层,用一个全局的平均池化层来取代它,引入Inception Module,这是一个4个分支结合的结构,所有分支都用到了1*1的卷积
- ResNet引入高速公路结构
7.CNN的特点以及优势
CNN使用范围是具有局部空间相关性的数据,比如图像,自然语言,语音
局部连接:可以提取局部特征。
权值共享:减少参数数量,因此降低训练难度(空间、时间消耗都少了)。可以完全共享,也可以局部共享(比如对人脸,眼睛鼻子嘴由于位置和样式相对固定,可以用和脸部不一样的卷积核)
降维:通过池化或卷积stride实现。
多层次结构:将低层次的局部特征组合成为较高层次的特征。不同层级的特征可以对应不同任务。
8.卷积神经网络CNN中池化层作用
保留主要的特征同时减少参数和计算量,防止过拟合,提高模型泛化能力
9.常见的激活函数,激活函数有什么作用
Sigmoid
Sigmoid函数能够吧输入的连续的实值变换成为0和1之间的输出,特别地,如果是非常大的负数,那么输出就是0;如果是非常大的正数,则经过它的输出则是1
ReLU
R e l u = m a x ( 0 , x ) Relu=max(0,x) Relu=max(0,x)
目前ReLU是最常使用的一个激活函数,它实质上就是一个取最大值函数,但是它并不是全区间可导的,不过在一般情况下可以取sub-gradient。ReLU虽然简单,但却是近几年的重要成果,它在正区间内解决了梯度消失的问题,同时因为在使用它的过程中只需要判断输入是否大于零,所以它具有较快的计算速度,收敛速度远快于sigmoid和tanh函数
Tanh
t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x
Tanh函数是在其函数表达式的基础上经过放大或缩小处理后的结果,Tanh函数在一定程度上改善了sidmoid函数,但是梯度消失的问题仍然没有完全避免
Leaky ReLU
f ( x ) = m a x ( α x , x ) f(x)=max(\alpha x,x) f(x)=max(αx,x)
为了解决DeadReLU Problem, 提出了将ReLU在(-∞,0)区间内为αx,而非是0,通常α=0.001。Leaky ReLU继承了ReLU的优点,同时也进一步解决了Dead ReLU的问题,但是实际情况中,LeakyReLU并不一定总比ReLU的效果好
ELU
f ( x ) = { x x > 0 a ( e x − 1 ) o t h e r w i s e f(x)=\left\{ \begin{array}{lr} x & x > 0\\ a(e^x-1) & otherwise \end{array} \right. f(x)={xa(ex−1)x>0otherwise
ELU的提出是为了解决ReLU存在的Dead ReLU问题,它继承了ReLU的优点同时输出的均值接近于0
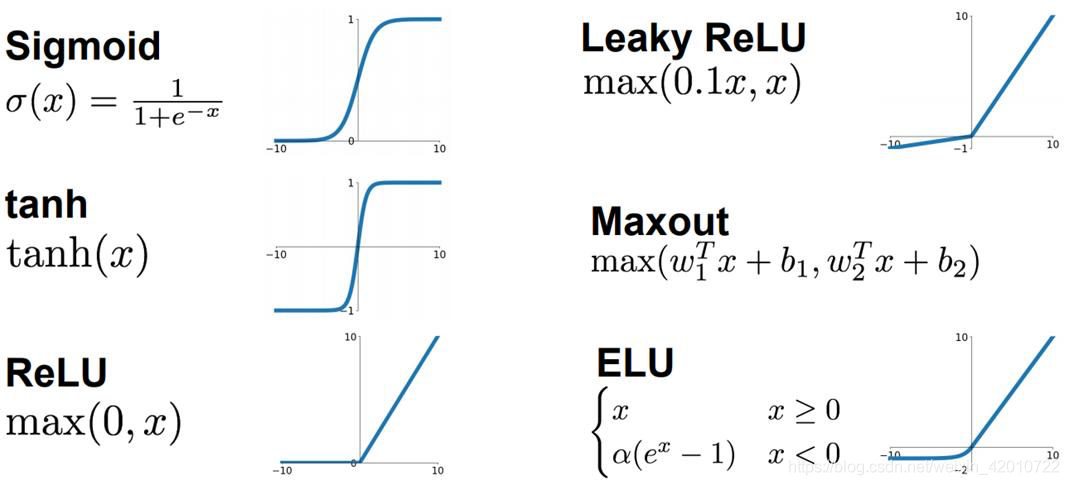
激活函数作用:非线性变换激活函数的主要作用是使网络具有非线性拟合能力,如果没有激活函数,那么神经网络只能拟合线性映射,即便是有再多的隐藏层,整个网络跟单层神经网络是等价的。因此,只有加入激活函数后,神经网络才具备了非线性的学习能力
10.简述一下sigmoid函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。
sigmoid的函数表达式如下
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
其中z是一个线性组合,比如z可以等于:b + w1x1 + w2x2。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。
因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):
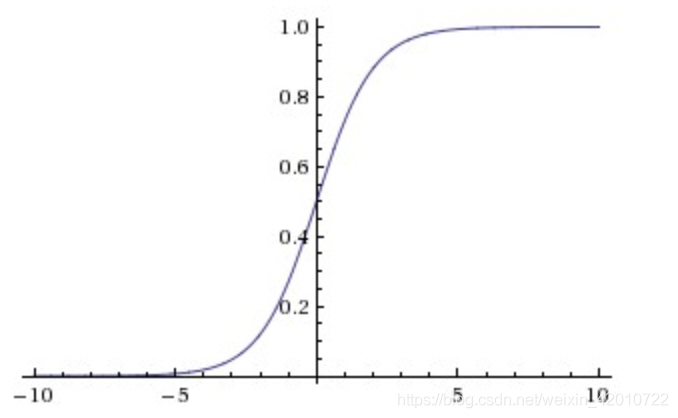
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。
11.CNN关键层有哪些
关键层有:
- 输入层,对数据去均值,做data augmentation等工作
- 卷积层,局部关联抽取feature
- 激励层,非线性变化(也就是常说的激活函数)
- 池化层,下采样
- 全连接层,增加模型非线性
- BN层,缓解梯度弥散
12.什么是梯度爆炸
误差梯度是神经网络训练过程中计算的方向和数量,用于以正确的方向和合适的量更新网络权重。
在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。
网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸
13.梯度爆炸会引发什么问题
在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
梯度爆炸导致学习过程不稳定,在循环神经网络中,梯度爆炸会导致网络不稳定,无法利用训练数据学习,最好的结果是网络无法学习长的输入序列数据
14.如何确定是否出现梯度爆炸
训练过程中出现梯度爆炸会伴随一些细微的信号,如:
- 模型无法从训练数据中获得更新(如低损失)。
- 模型不稳定,导致更新过程中的损失出现显著变化。
- 训练过程中,模型损失变成 NaN。
以下是一些稍微明显一点的信号,有助于确认是否出现梯度爆炸问题。
- 训练过程中模型梯度快速变大。
- 训练过程中模型权重变成 NaN 值。
- 训练过程中,每个节点和层的误差梯度值持续超过 1.0
15.如何修复梯度爆炸问题
重新设计网络模型
在深度神经网络中,梯度爆炸可以通过重新设计层数更少的网络来解决。
使用更小的批尺寸对网络训练也有好处,在循环神经网络中,训练过程中在更少的先前时间步上进行更新(沿时间的截断反向传播,truncated Backpropagation through time)可以缓解梯度爆炸问题。
使用 ReLU 激活函数
在深度多层感知机神经网络中,梯度爆炸的发生可能是因为激活函数,如之前很流行的 Sigmoid 和 Tanh 函数。
使用 ReLU 激活函数可以减少梯度爆炸。采用 ReLU 激活函数是最适合隐藏层的新实践。
使用长短期记忆网络
在循环神经网络中,梯度爆炸的发生可能是因为某种网络的训练本身就存在不稳定性,如随时间的反向传播本质上将循环网络转换成深度多层感知机神经网络,使用长短期记忆(LSTM)单元和相关的门类型神经元结构可以减少梯度爆炸问题。
采用 LSTM 单元是适合循环神经网络的序列预测的最新最好实践。
使用梯度截断(Gradient Clipping)
在非常深且批尺寸较大的多层感知机网络和输入序列较长的 LSTM 中,仍然有可能出现梯度爆炸。如果梯度爆炸仍然出现,你可以在训练过程中检查和限制梯度的大小。这就是梯度截断。
处理梯度爆炸有一个简单有效的解决方案:
如果梯度超过阈值,就截断它们,具体来说,检查误差梯度的值是否超过阈值,如果超过,则截断梯度,将梯度设置为阈值。梯度截断可以一定程度上缓解梯度爆炸问题(梯度截断,即在执行梯度下降步骤之前将梯度设置为阈值)。
在 Keras 深度学习库中,你可以在训练之前设置优化器上的 clipnorm 或 clipvalue 参数,来使用梯度截断。
默认值为 clipnorm=1.0 、clipvalue=0.5。
使用权重正则化(Weight Regularization)
如果梯度爆炸仍然存在,可以尝试另一种方法,即检查网络权重的大小,并惩罚产生较大权重值的损失函数。该过程被称为权重正则化,通常使用的是 L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)。
对循环权重使用 L1 或 L2 惩罚项有助于缓解梯度爆炸。
在 Keras 深度学习库中,你可以通过在层上设置 kernel_regularizer 参数和使用 L1 或 L2 正则化项进行权重正则化。
16.什么是RNN
RNN的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNN:
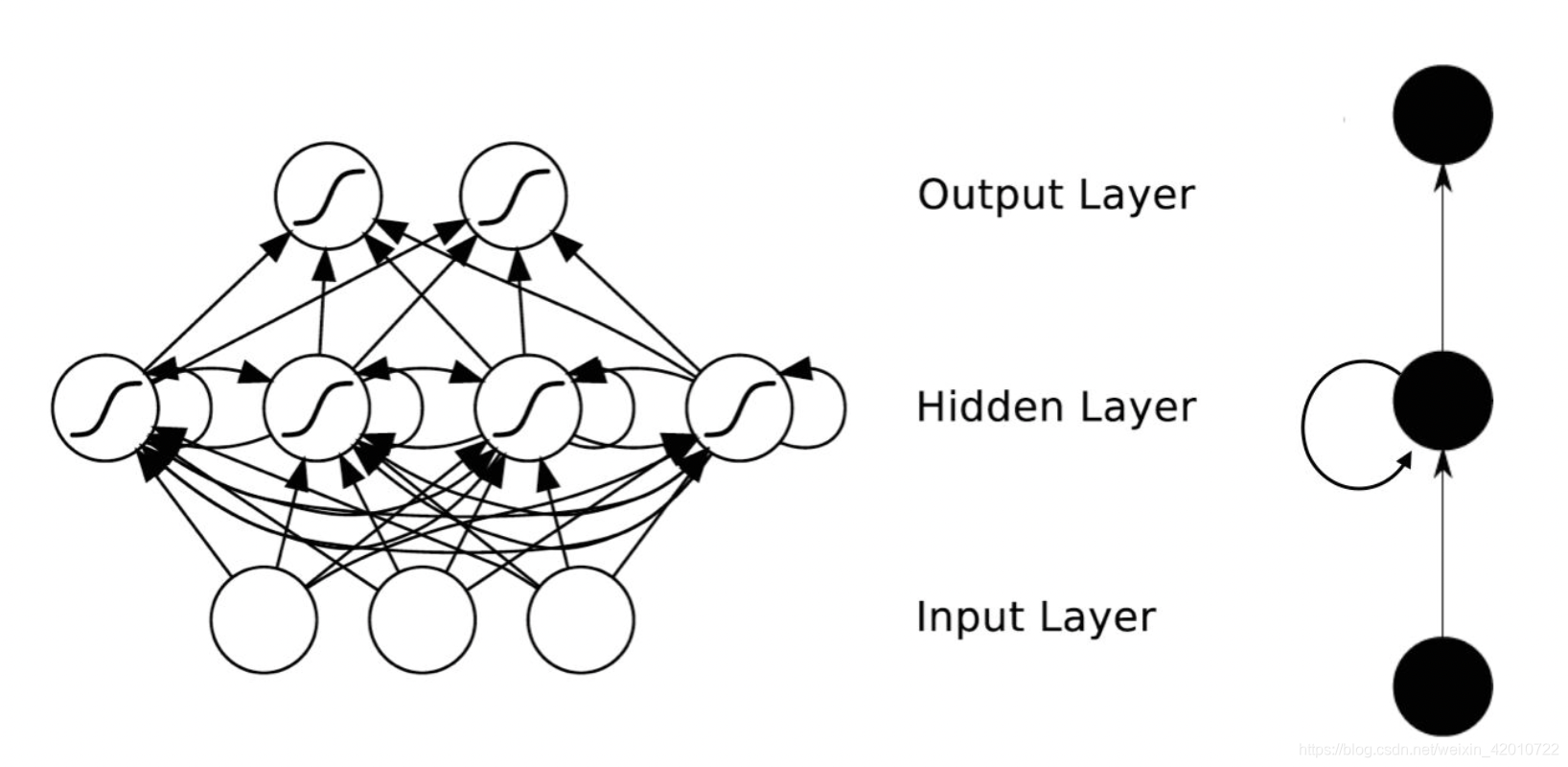
RNN包含输入单元(Input units),输入集标记为{x0,x1,…,xt,xt+1,…},而输出单元(Output units)的输出集则被标记为{y0,y1,…,yt,yt+1.,…}。RNN还包含隐藏单元(Hidden units),我们将其输出集标记为{s0,s1,…,st,st+1,…},这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNN会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
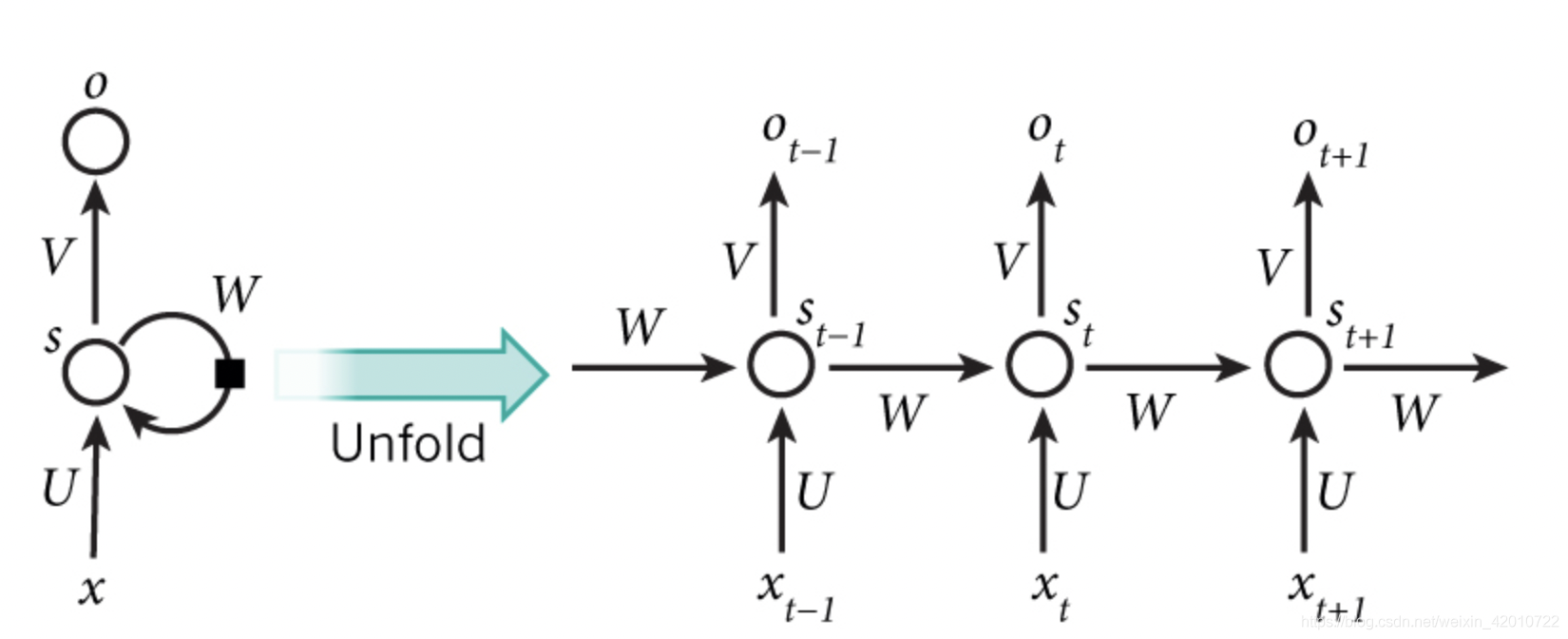
- xt表示第t,t=1,2,3…步(step)的输入。比如,x1为第二个词的one-hot向量(根据上图,x0为第一个词);
- st为隐藏层的第t步的状态,它是网络的记忆单元。st根据当前输入层的输出与上一步隐藏层的状态进行计算。st=f(Uxt+Wst−1),其中f一般是非线性的激活函数,如tanh或ReLU,在计算s0时,即第一个单词的隐藏层状态,需要用到s−1,但是其并不存在,在实现中一般置为0向量;
- ot是第t步的输出,如下个单词的向量表示,ot=softmax(Vst)。
17.在神经网络中,有哪些办法防止过拟合
- Dropout
- 加L1/L2正则化
- BatchNormalization
- 网络bagging
- 提取终止训练
- 数据增强
18.如何解决深度学习中模型训练效果不佳的情况
(1)选择合适的损失函数(choosing proper loss )
神经网络的损失函数是非凸的,有多个局部最低点,目标是找到一个可用的最低点。非凸函数是凹凸不平的,但是不同的损失函数凹凸起伏的程度不同,例如下述的平方损失和交叉熵损失,后者起伏更大,且后者更容易找到一个可用的最低点,从而达到优化的目的。
- Square Error(平方损失)
- Cross Entropy(交叉熵损失)
(2)选择合适的Mini-batch size
采用合适的Mini-batch进行学习,使用Mini-batch的方法进行学习,一方面可以减少计算量,一方面有助于跳出局部最优点。因此要使用Mini-batch。更进一步,batch的选择非常重要,batch取太大会陷入局部最小值,batch取太小会抖动厉害,因此要选择一个合适的batch size。
(3)选择合适的激活函数(New activation function)
使用激活函数把卷积层输出结果做非线性映射,但是要选择合适的激活函数。
- Sigmoid函数是一个平滑函数,且具有连续性和可微性,它的最大优点就是非线性。但该函数的两端很缓,会带来猪队友的问题,易发生学不动的情况,产生梯度弥散。
- ReLU函数是如今设计神经网络时使用最广泛的激活函数,该函数为非线性映射,且简单,可缓解梯度弥散。
(4)选择合适的自适应学习率(apdative learning rate)
- 学习率过大,会抖动厉害,导致没有优化提升
- 学习率太小,下降太慢,训练会很慢
(5)使用动量(Momentum)
在梯度的基础上使用动量,有助于冲出局部最低点。
如果以上五部分都选对了,效果还不好,那就是产生过拟合了,可使如下方法来防止过拟合,分别是
- 早停法(earyly stoping)。早停法将数据分成训练集和验证集,训练集用来计算梯度、更新权重和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
- 权重衰减(Weight Decay)。到训练的后期,通过衰减因子使权重的梯度下降地越来越缓。
- Dropout。Dropout是正则化的一种处理,以一定的概率关闭神经元的通路,阻止信息的传递。由于每次关闭的神经元不同,从而得到不同的网路模型,最终对这些模型进行融合。
- 调整网络结构(Network Structure)














![[Excel]Excel函数和用法(4)——查找字符串,SEARCH和FIND函数](https://img-blog.csdnimg.cn/20190228135345217.png)