文章目录
- 介绍
- 实现顺序表反转
- 实现链表反转
- 附链表的一些中间函数
介绍
顺序表和链表都是数据结构中常见的线性表。它们的主要区别在于内存管理方式不同。
顺序表(Array)是由一系列元素按照一定顺序依次排列而成,它使用连续的内存空间存储数据。顺序表使用一个数组来存储数据,数组中的每个元素都可以通过下标来访问。顺序表具有随机访问、空间利用率高等优点,但在插入和删除元素时需要移动其他元素,导致效率低下。在需要频繁修改元素的情况下,顺序表不适合使用。
链表(List)是一种通过指针来实现的动态数据结构,可以无序存储任意类型的数据。链表中的元素被称为节点,每个节点中都包含了数据和指向下一个节点的指针。相比之下,链表的内存分配是动态的,并且不需要提前规划数组大小,能够有效地避免内存浪费。链表可以快速地插入和删除节点,但是由于插入和删除必须先定位到指定位置,因此其访问时间比顺序表长。
总之,当需要频繁查询顺序、频繁访问内部元素和使用预定义的固定大小存储数据时,使用顺序表可能是比较合适的选择。但当需要大量插入、删除和更改元素和无法提前预测空间大小时,链表的动态分配方式更为有效。
实现顺序表反转
/***************************************
* 函数功能:逆置顺序表
* 函数参数:int*data-表示待逆置的顺序表 int size-表示顺序表的大小
* 函数返回值:无
****************************************/
void reverse(int*data, int size)
{for (int i = 0; i < size / 2; ++i){int temp = data[i];data[i] = data[size - i - 1];data[size - i - 1] = temp;}
}
在函数体中,发生了一次 for 循环,该循环的次数与数据规模 N 成线性关系。另外,for 循环中进行了常数次的赋值操作。因此,整个函数的时间复杂度是 O(N)。(其中N表示顺序表的长度)
该函数的空间复杂度为 O(1)(常数级别)。在函数执行期间,只使用了恒定数量的变量(i、temp),而且使用的空间不随问题规模 N 的增加而增加,因此该函数的空间复杂度为 O(1)。
因此,该函数的时间复杂度为 O(N),空间复杂度为 O(1)。
实现链表反转
核心代码
/***************************************
* 函数功能:逆置链表
* 函数参数:struct myHead* list待逆置链表
* 函数返回值:无
****************************************/
void reverseList(struct myHead* list)
{struct myNode*p = list->element->next,*q = NULL;// 遍历链表while (p){// 保存p的后继节点struct myNode*temp = p->next;// 改变指针指向的位置p->next = q;q = p;p = temp;}// 保存反转链表的结果list->element->next = q;
}
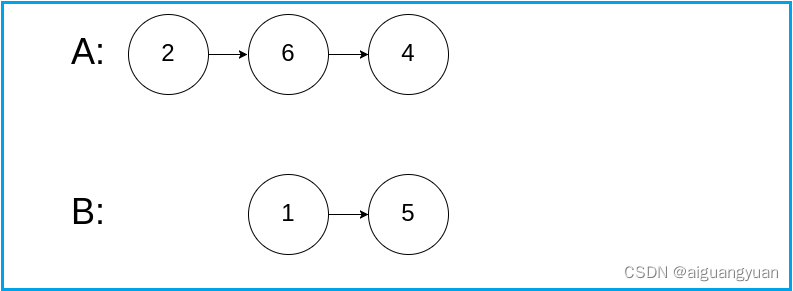
算法的核心设计思想:改变链表中节点指针指向的位置,也就是改变前驱与后继元素的位置。
若链表中的元素为1、2、3、4、5那么反转的过程图如下:

该函数主要有两个操作:遍历链表和反转链表。在遍历链表过程中,需要访问、操作每个节点以及节点中存储的数据。因此,函数的时间复杂度为 O(N)。(其中 N 表示链表长度)
函数的空间复杂度为 O(1)。函数只使用了常数级别的额外空间来存储一些临时变量,而且这些变量的空间占用与问题规模 N 无关,因此可以认为函数的空间复杂度为 O(1)。
附链表的一些中间函数
链表的结构
struct myNode
{int data;struct myNode*next;
};struct myHead
{int size;struct myNode*element;
};
链表的一些基本操作,包括初始化、添加节点与输出链表。
/***************************************
* 函数功能:链表初始化
* 函数参数:无
* 函数返回值:无
****************************************/
struct myHead*listInit(void)
{// 初始化头结点struct myHead*myList = (struct myHead*)malloc(sizeof(struct myHead));myList->size = 0;// 添加虚拟节点myList->element = (struct myNode*)malloc(sizeof(struct myNode));myList->element->data = -1;myList->element->next = NULL;return myList;
}/***************************************
* 函数功能:使用尾插法插入值至链表中
* 函数参数:struct myHead*list表示目标链表 int data表示待插入的值
* 函数返回值:无
****************************************/
void addNode(struct myHead*list, int data)
{struct myNode*p = list->element;// 遍历至待插入节点的前驱节点while (p->next)p = p->next;// 新建节点struct myNode*myNode = (struct myNode*)malloc(sizeof(struct myNode));myNode->data = data;myNode->next = NULL;// 插入节点并增加链表节点数量p->next = myNode;list->size++;
}/***************************************
* 函数功能:输出链表
* 函数参数:struct myHead* list待输出链表
* 函数返回值:无
****************************************/
void outPutList(struct myHead* list)
{struct myNode *p = list->element->next;while (p){printf("%d ",p->data);p = p->next;}
}