参考书籍:《Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition (Aurelien Geron [Géron, Aurélien])》
本次使用的数据集是tf.keras.datasets.fashion_mnist,里面包含6w张图,涵盖10个分类。
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import pickle'''
fashion_mnist = keras.datasets.fashion_mnist.load_data()
with open('fashion_mnist.pkl', 'wb') as f:pickle.dump(fashion_mnist, f)
'''
def load_data():with open('fashion_mnist.pkl', 'rb') as f:mnist = pickle.load(f)(X_train_full, y_train_full), (X_test, y_test) = mnistX_valid, X_train = X_train_full[:5000] / 255.0, X_train_full[5000:] / 255.0y_valid, y_train = y_train_full[:5000], y_train_full[5000:]X_test = X_test / 255.0return X_train, X_valid, X_test, y_train, y_valid, y_testclass_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat","Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
#print(class_names[y_train[0]]) # coat
# 查看
some_image = X_train[0]
plt.imshow(some_image, cmap="binary")
plt.axis("off")
plt.show()
随便拿一张来看:

构建网络:
'''
model = keras.models.Sequential()
# 28x28 -> 1x784 也可以用InputLayer(input_shape=[28, 28])
model.add(keras.layers.Flatten(input_shape=[28, 28]))
# 其他激活函数:https://keras.io/api/layers/activations/
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
# output layer. 10个输出
model.add(keras.layers.Dense(10, activation="softmax"))
'''
# 也可以这么写:
model = keras.models.Sequential([keras.layers.Flatten(input_shape=[28, 28]),keras.layers.Dense(300, activation="relu"),keras.layers.Dense(100, activation="relu"),keras.layers.Dense(10, activation="softmax")
])
# 下面235500 = 784 x 300 + 300, 前面表示每个input都要跑向300个节点,所以要给权重w。然后每个节点要加一个偏置b
# 30100 = 300 x 100 + 100
print(model.summary())
'''
Model: "sequential"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================flatten (Flatten) (None, 784) 0 dense (Dense) (None, 300) 235500 dense_1 (Dense) (None, 100) 30100 dense_2 (Dense) (None, 10) 1010 =================================================================
Total params: 266,610
Trainable params: 266,610
Non-trainable params: 0
_________________________________________________________________
'''import pydot
keras.utils.plot_model(model, 'model.png')
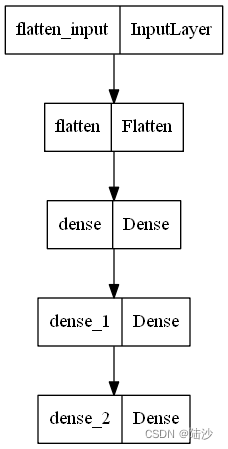
pydot安装与plot_model报错的解决:
参考:https://blog.csdn.net/shangxiaqiusuo1/article/details/85283432
先下载 https://graphviz.gitlab.io/_pages/Download/windows/graphviz-2.38.msi
然后双击,安装到D:\Program Files (x86)\Graphviz2.38\
- 建立变量名GRAPHVIZ_DOT,值为D:\Program Files (x86)\Graphviz2.38\bin\dot.exe
- 在用户环境变量添加一个新的变量:建立变量名 GRAPHVIZ_INSTALL_DIR, 值为D:\Program Files (x86)\Graphviz2.38
- 在系统环境变量的PATH中添加Graphviz的bin目录路径,如D:\Program Files (x86)\Graphviz2.38\bin
pip install graphviz
pip install pydot
pip install pydot-ng
在python文件中输入import pydot,然后按住Ctrl+鼠标左键点击pydot,会进入pydot的源文件,然后找到 self.prog = ‘dot’ ,改成 self.prog = ‘dot.exe’
这样改完如果还不行,在python文件里添加:
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/'
基本上这样就ok了。
# 用index或名字都可以access层
hidden1 = model.layers[1]
print(model.get_layer('dense') is hidden1)
weights, biases = hidden1.get_weights()
print(weights)
# bias最开始初始化为0
print(biases)
设置+训练模型:
# 使用这个loss是因为数据有10种离散的、互斥的标签
# optimizer=keras.optimizers.SGD(lr=xx)
# 这样可以设置学习率。default lr=0.01
model.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
X_train, X_valid, X_test, y_train, y_valid, y_test = load_data() # 获取数据的函数,略
history = model.fit(X_train, y_train, epochs=30, validation_data=(X_valid, y_valid))
'''
Epoch 1/30
1719/1719 [==============================] - 4s 2ms/step - loss: 0.6992 - accuracy: 0.7704 - val_loss: 0.4999 - val_accuracy: 0.8378
Epoch 2/30
1719/1719 [==============================] - 3s 2ms/step - loss: 0.4876 - accuracy: 0.8311 - val_loss: 0.4659 - val_accuracy: 0.8364
Epoch 3/30
1719/1719 [==============================] - 3s 2ms/step - loss: 0.4440 - accuracy: 0.8449 - val_loss: 0.4394 - val_accuracy: 0.8480
...
Epoch 29/30
1719/1719 [==============================] - 3s 2ms/step - loss: 0.2330 - accuracy: 0.9160 - val_loss: 0.3047 - val_accuracy: 0.8906
Epoch 30/30
1719/1719 [==============================] - 3s 2ms/step - loss: 0.2291 - accuracy: 0.9167 - val_loss: 0.2969 - val_accuracy: 0.8938
'''
这里设置了30次循环,其实未必达到最优,也基本不会过拟合。
如果训练集是有偏的,比如某些类overrepresented,某些类underrepresented,那么在fit()前应该设置class_weight,给underrepresented类以更大的权重,overrepresented类以更小的权重。如果有的case需要格外注意,比如某些cases是专家标注,另外一些是普通标注的,那么可以用per-instance weights,即设置sample_weight。如果class_weight和sample_weight都设置了,keras会把它们相乘。另外,也可以为验证集单独设置sample weights。
另外,history.history是个字典,里面包含loss,accuracy,val_loss, val_accuracy(每个都是epochs个数据),所以可以画图:
(就是把上面打印的信息以图的方式反映出来)
import pandas as pd
import matplotlib.pyplot as pltprint(history.history)
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
# 'gca'代表Get Current Axis
plt.gca().set_ylim(0, 1)
plt.show()
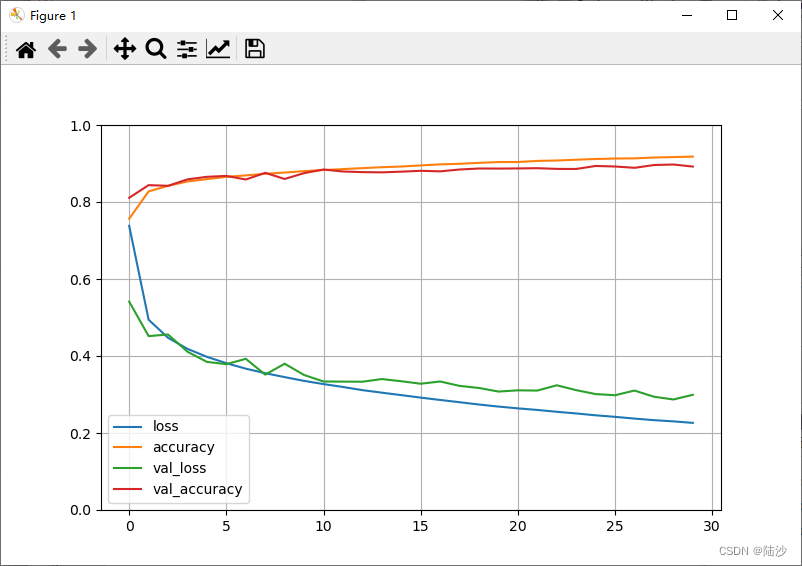
为什么在前几个epoch上,validation的结果看起来比train好?
因为validation error是在每个epoch结束时计算的,而training error是一个running mean,即在每个epoch运行时计算的,所以training的图像应该移半个epoch。此时前几个epoch的图像应该是比较近似的,甚至overlap。
等调完超参数(如learning rate, layer num, batch_size…),评估一下模型:
print(model.evaluate(X_test, y_test))
'''
loss, accuracy
[0.34293538331985474, 0.8896999955177307]
'''
注意:如果loss很大可能是X_test没有归一化。
保存模型:其他保存模型的方法:https://blog.csdn.net/qq_22841387/article/details/130194553
import joblib
joblib.dump(model, "my_model.joblib")# 导入使用load,导入后可以使用新数据继续训练 model.fit()
model = joblib.load("my_model.joblib")
预测
X_new = X_test[:3]
y_proba = model.predict(X_new)
print(y_proba.round(2))
'''
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ][0. 0. 0.99 0. 0.01 0. 0. 0. 0. 0. ][0. 1. 0. 0. 0. 0. 0. 0. 0. 0. ]]
'''import numpy as np
y_pred = model.predict(X_new)
# tf 2.6前可以用model.predict_classes(X_new), 2.6开始删除了该函数
labels = np.argmax(y_pred, axis=1)
print(labels) # [9 2 1]
# 显示分类名称
print(np.array(class_names)[labels]) # ['Ankle boot' 'Pullover' 'Trouser']







![四、初探[ElasticSearch]集群架构原理与搜索技术](https://img-blog.csdnimg.cn/ec9553a2f5ca4040a704e86c7bf26a22.png)








