选自 medium;作者:Gabriel Lerner、Nathan Toubiana
机器之心编译;参与:陈韵莹、张倩
好不容易码了个 python 项目,是不是很兴奋?那么怎么把这个项目发出去让大家看到呢?本文作者写了一份在 GitHub 上发布 python 包的简单分步指南。
作者以 SciTime 项目(一个对算法训练时间进行估计的包)的发布为例,详细解释了发布的每个步骤。
注意:本文假设你在 GitHub 上已经有一个想要打包和发布的项目。
第 0 步:获取项目许可证
在做其他事之前,由于你的项目要开源,因此应该有一个许可证。获取哪种许可证取决于项目包的使用方式。开源项目中一些常见许可证有 MIT 或 BSD。
要在项目中添加许可证,只需参照以下链接中的步骤,将 LICENSE 文件添加到项目库中的根目录即可:https://help.github.com/en/articles/adding-a-license-to-a-repository
第 1 步:让你的代码准备就绪
要将项目进行打包,你需要做一些预备工作:
让你的项目结构正确就位。通常情况下,项目库的根目录包含一个以项目名称命名的文件夹,项目的核心代码应该位于此文件夹中。在这个文件夹之外是运行和构建包(测试、文档等)所需的其他代码。
核心文件夹应包括一个(或多个)模块和一个 __init__.py 文件,该文件包含你希望让终端用户访问的类/函数。此文件还可以包含包的版本,以便于终端用户访问。
理想情况下,应使用 logging 包来设置合理的日志记录系统(而不是用 prints 输出)。
理想情况下,应将你的核心代码分配到一个或多个类中。
以__init__.py 为例,如果 Estimator 是终端用户将会访问的类(该类在 estimate.py 文件中定义)
import logging
class LogMixin(object):
@property
def logger(self):
name = '.'.join([self.__module__, self.__class__.__name__])
FORMAT = '%(name)s:%(levelname)s:%(message)s'
logging.basicConfig(format=FORMAT, level=logging.DEBUG)
logger = logging.getLogger(name)
return logger以日志系统为例:LogMixin 类可以在其他任何类中使用
第 2 步: 使用打包工具创建 setup.py
在你的项目有了一套结构之后,你应该在项目库的根目录下添加 setup.py 文件。这有助于所有发布和版本维护过程的自动化。以下是 setup.py 的例子(源代码:https://github.com/nathan-toubiana/scitime/blob/master/setup.py)。
from setuptools import setup
from os import path
DIR = path.dirname(path.abspath(__file__))
INSTALL_PACKAGES = open(path.join(DIR, 'requirements.txt')).read().splitlines()
with open(path.join(DIR, 'README.md')) as f:
README = f.read()
setup(
name='scitime',
packages=['scitime'],
description="Training time estimator for scikit-learn algorithms",
long_description=README,
long_description_content_type='text/markdown',
install_requires=INSTALL_PACKAGES,
version='0.0.2',
url='http://github.com/nathan-toubiana/scitime',
author='Gabriel Lerner & Nathan Toubiana',
author_email='toubiana.nathan@gmail.com',
keywords=['machine-learning', 'scikit-learn', 'training-time'],
tests_require=[
'pytest',
'pytest-cov',
'pytest-sugar'
],
package_data={
# include json and pkl files
'': ['*.json', 'models/*.pkl', 'models/*.json'],
},
include_package_data=True,
python_requires='>=3'
)setup.py 文件的示例
几点注意事项:
如果你的包有依赖项,处理这些依赖项的简单方法是在配置文件中通过 install_requires 参数来添加依赖项(如果列表很长,你可以像之前那样指向一个 requirement.txt 文件)。
如果你希望在任何人安装包时(从项目库中)下载元数据,则应通过 package_data 参数来添加这些元数据。
有关 setup() 函数的更多信息,请参见:https://setuptools.readthedocs.io/en/latest/setuptools.html
注意:第 3 步到第 6 步是可选的(但强烈推荐),但是如果你现在马上想发布你的包,可以直接跳到第 7 步。
第 3 步:设置本地测试和检查测试覆盖率
此时还没有完成,你的项目还应该有单元测试。尽管有许多框架能帮助你做到,但一种简单的方法是使用 pytest。所有测试都应该放在一个专用的文件夹中(例如名为 tests/或 testing 的文件夹)。在这个文件夹中放置你需要的所有测试文件,以便尽可能多地包含你的核心代码。下面是一个如何编写单元测试的示例。这里还有一个 SciTime 的测试文件。
一旦就位,你就可以通过在项目库的根目录运行 python -m pytest 在本地进行测试。
创建测试后,你还应该能估算覆盖率。这一点很重要,因为你希望尽可能多地测试项目中的代码量(以减少意外的 bug)。
很多框架也可以用于计算覆盖率,对于 SciTime,我们使用了 codecov。你可以通过创建.codecov.yml 文件来决定允许的最小覆盖率阈值,还可以通过创建.coveragerc 文件来决定要在覆盖率分析中包含哪些文件。
comment: false
coverage:
status:
project:
default:
target: auto
threshold: 10%
patch:
default:
target: auto
threshold: 10%.codecov.yml 文件示例
[run]
branch = True
source = scitime
include = */scitime/*
omit =
*/_data.py
*/setup.py.coveragerc 文件示例
第 4 步:标准化语法和代码风格
你还需要确保你的代码遵循 PEP8 准则(即具有标准样式并且语法正确)。同样,有很多工具可以帮助你解决。这里我们用了 flake8。
第 5 步:创建一个合理的文档
现在你的项目已经测试过了,结构也很好了,是时候添加一个合理的文档。首先是要有一个好的 readme 文件,它会在你的 Github 项目库的根目录上显示。完成后,加上以下几点会更好:
Pull 请求和 issue 模板:当创建新的 Pull 请求或 issue 时,这些文件可以根据你的需求给你的描述提供模板。
Pull 请求创建步骤:https://help.github.com/en/articles/creating-a-pull-request-template-for-your-repository
issue 创建步骤:https://help.github.com/en/articles/manually-creating-a-single-issue-template-for-your-repository
Pull 请求模板:https://github.com/nathan-toubiana/scitime/blob/master/.github/PULL_REQUEST_TEMPLATE.md
issue 模板:https://github.com/nathan-toubiana/scitime/tree/master/.github/ISSUE_TEMPLATE
贡献指南(contribution guide)。应该在贡献指南中简单地说明你希望外部用户如何协助你改进这个包。Scitime 的贡献指南参见:https://github.com/nathan-toubiana/scitime/blob/master/.github/CONTRIBUTING.md。
准则,Scitime 的准则参见:https://github.com/nathan-toubiana/scitime/blob/master/.github/CODE_OF_CONDUCT.md
标签和说明(见下面的截图)
readme 文件中的标签(推荐一篇如何使用标签的好文章:https://medium.freecodecamp.org/how-to-use-badges-to-stop-feeling-like-a-noob-d4e6600d37d2)。
由于 readme 文件应该相当综合,因此通常会有一个更详细的文档。你可以用 sphinx 来完成,然后在 readthedocs 上管理文档。与文档相关的文件通常放在 docs/文件夹中。sphinx 和 readthedocs 相关教程:https://docs.readthedocs.io/en/stable/intro/getting-started-with-sphinx.html。

包含标签和说明的项目库示例
第 6 步:创建持续集成
此时,你的项目离发布就绪不远了。但是,在每次提交之后,必须更新文档、运行测试以及检查样式和覆盖率似乎有点难以应付。幸运的是,持续集成(CI)可以帮助你完成。你可以在每次提交之后使用 GitHub 的 webhook 来自动执行所有的这些操作。以下是我们在 SciTime 中使用的一套 CI 工具:
对于运行测试,我们使用了 travis ci 和 appveyor(用于 Windows 平台上的测试)。对于 Travis CI,除了在项目库上设置 webhook 之外,你还必须创建一个.travis.yml 文件,在该文件中,你不仅可以运行测试,还可以上传更新的覆盖率输出以及检查样式和格式。通过创建 appveyor.yml 文件,appveyor 也可以这样做。
codecov 和 readthdocs 也有专用的 webhook
language: python
python:
- "3.6"
# command to install dependencies
install:
- pip install -r requirements.txt
- pip install flake8
- pip install pytest-cov
- pip install codecov
# command to run tests
script:
- python -m pytest --cov=scitime
- ./build_tools/flake_diff.sh
after_success:
- codecov.travis.yml 文件的示例:请注意,每次提交,测试都需要与检查测试覆盖率一起进行。但还有一个 flake8 检查(逻辑则在 flake_diff.sh 文件中定义:https://github.com/nathan-toubiana/scitime/blob/master/build_tools/flake_diff.sh)
environment:
matrix:
- PYTHON: "C:\\Python36-x64"
install:
# We need wheel installed to build wheels
- "%PYTHON%\\python.exe -m pip install -r requirements.txt"
- "%PYTHON%\\python.exe -m pip install pytest==3.2.1"
build: off
test_script:
- "%PYTHON%\\python.exe -m pytest"appveyor.yml 文件示例:这里我们只运行测试
这将使更新项目库的整个过程更加容易。
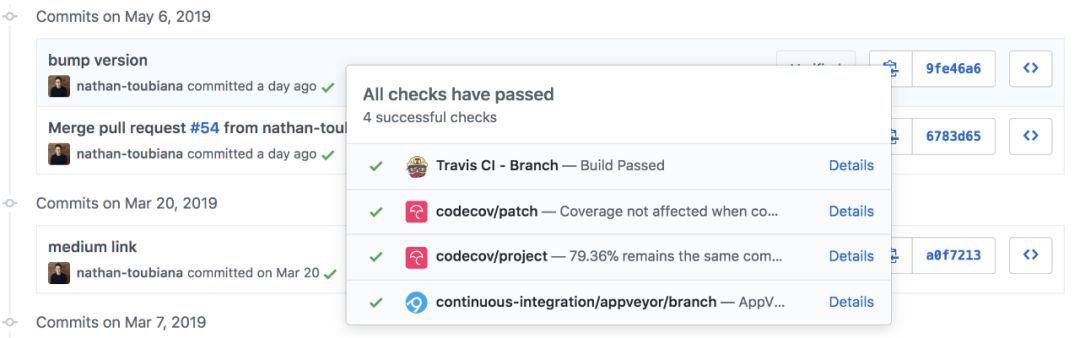
集成 webhook 的提交历史记录示例
第 7 步:创建你的第一个 release 和 publication
此时,你即将发布的包应与以下类似:
your_package/
__init__.py
your_module.py
docs/
tests/
setup.py
travis.yml
appveyor.yml
.coveragerc
.codecov.yml
README.md
LICENSE
.github/
CODE_OF_CONDUCT.md
CONTRIBUTING.md
PULL_REQUEST_TEMPLATE.md
ISSUE_TEMPLATE/现在可以发布了!首先要做的是在 GitHub 上创建你的第一个 release——这是为了在给定的时间点跟踪项目的状态,每次版本更改时都需要创建新的 release。创建步骤:https://help.github.com/en/articles/creating-releases。
完成后,唯一要做的就是发布包。发布 python 包最常见的平台是 PyPI 和 Conda。以下我们将描述如何用两者发布:
对于 PyPI,首先需要创建一个帐户,然后用 twine 执行一些步骤:https://realpython.com/pypi-publish-python-package/。这应该相当简单,而且 Pypi 还提供了一个可以在实际部署之前使用的测试环境。PyPI 总体上包括创建源代码(python setup.py sdist)并使用 twine(twine upload dist/*)来上传。完成后,应该有一个与你的包对应的 PyPI 页面,并且任何人都应该能够通过运行 pip 命令来安装你的包。
对于 Conda,我们推荐通过 conda forge 来发布你的包,conda forge 是一个社区,帮助你通过 conda 渠道发布和维护包。你可以按照以下步骤将包添加到社区:https://conda-forge.org/#add_recipe,然后你会被添加到 conda forge Github 组织中,并能够非常轻松地维护你的包,然后任何人都可以通过运行 conda 命令来安装你的包。
完成!
现在,你的包应该已经发出去,并且任何人都可以使用了!虽然大部分工作都完成了,但是你仍然需要维护你的项目,你需要进行一些更新:这大体上意味着每次进行重大更改时都要更改版本,创建新的 release,并再次执行第 7 步。
原文链接:https://medium.freecodecamp.org/from-a-python-project-to-an-open-source-package-an-a-to-z-guide-c34cb7139a22
有关 Scitime 的详细信息参见:
https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Fmedium.freecodecamp.org%2Ftwo-hours-later-and-still-running-how-to-keep-your-sklearn-fit-under-control-cc603dc1283b%3Fsource%3Dfriends_link%26sk%3D98e79add47516c38eeec59cf755df938)
END
转自:机器之心 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请联系QQ:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。