你知道吗
- 推荐系统:
- 解决问题:
- 系统环节:
- 召回路径:
- 推荐架构:
- 通用技术架构:
- 实现推荐:
- 基于内容的推荐系统【Content-Based Recommendations】
- 余弦相似度:
- 示例计算:
- 余弦相似度算法图:
- 分析:
- 实现协同过滤的推荐系统
- 基于用户的协同过滤:
推荐系统:
定义:根据用户的历史信息和行为,向用户推荐他感兴趣的内容
基于行为的协同过滤:①当两种事物出现的频率很高时,那么大概率会进行捆绑推荐 --【啤酒和尿布】
②当两个人是相似的时候,那么大概率会把B看过的事物推给A --【微信--他正在看】基于内容相似的推荐:①事物分类,大概率推荐相似度更高的事物
解决问题:
1、信息过载 【用户无法寻找物品】【系统无法精准推荐达到商业目标】
2、挖掘长尾【大量冷门物品无法暴露,但是价值加和超过热门物品,需要推荐曝光不同冷门兴趣的物品给冷门兴趣群众或者潜在兴趣群众】
3、用户体验【发现自己潜在喜欢的事物】
系统环节:
目的:需要在50ms–100ms以内选择推出用户喜欢的条目?

召回:
- 协同过滤召回
- 内容相似召回
- 图算法召回
- 热门召回
排序:【如果排序算法很高效,可以直接省略召回阶段】
-
机器学习
-
二分类算法(用户喜欢 0 用户不喜欢1 按照概率排列)
LR
GBDT
DNN
调整:
- 去重【不看重复】
- 已读过滤
- 在线过滤【过滤无效事物】
- 热门补足【补全推荐】
- 分页提取【推荐内容分页显示】
- 合并内容信息【根据推荐的ID获取其他信息如标题、内容、介绍等】
召回路径:
- I2i:物品–>物品(内容相似、协同过滤、关联规则挖掘) 【计算物品相似度召回】
- u2i:用户----直接行为---->视频【点击喜好】
- u2(i2i):用户----直接行为---->视频A【此时会推荐视频A的类似视频】
- (u2u)2i:用户A----->行为<----用户B 【此时推荐两个用户共同的关注事物】
- (u2Tag)2I:用户A(Tag:老人、男性、单身) —>推荐类似标签列表【该种推荐算法较为精准】
- 基于图算法【PersonalRank】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jquOZpvA-1639810945734)(/Users/keino/Library/Application Support/typora-user-images/image-20211218141853574.png)]](https://img-blog.csdnimg.cn/6853d8bdf4b34938be73d5ebe4a96f4d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LqM5Y2B5LiA55S7QA==,size_20,color_FFFFFF,t_70,g_se,x_16)
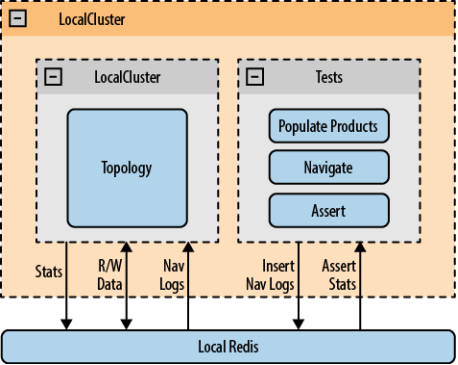
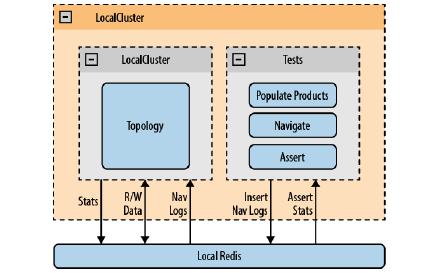
推荐架构:
目的:既要满足用户实时交互推荐,又要满足可处理海量数据进行算法分析
NetFlix:分为三层
-
在线层:
-
作用:快速响应,使用最新的数据输入
-
缺点:为了满足实时效率,无法处理大量数据,只能读取缓存中的少量数据或者处理少量数据推送
-
-
离线层:
- 作用:满足海量数据计算,优化算法,训练模型
- 优点:可以使用复杂算法计算,处理海量数据
- 缺点:无法对最新数据进行处理,只能天粒度或者小时粒度,做不到高效推荐
-
近线层:
- 作用:游离于离线和实时之间,将处理结果写入高速缓存
- 优点:可以使用接近于最新的数据,延迟时间远低于离线,略高于在线,同时也可以处理稍多的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Llbt8Ljc-1639810945735)(/Users/keino/Library/Application Support/typora-user-images/image-20211218144628901.png)]](https://img-blog.csdnimg.cn/fec542f859c74c409a448d7d849ee660.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LqM5Y2B5LiA55S7QA==,size_20,color_FFFFFF,t_70,g_se,x_16)
推荐组合:
1、天粒度:离线层做算法实现,得到用户向量和物品向量存储Mysql
2、10秒钟:根据用户行为,查询TopN相似的物品列表,存储缓存
3、200ms:在线查询第二步结果,更新推荐列表
通用技术架构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YNQC0PDh-1639810945741)(/Users/keino/Library/Application Support/typora-user-images/image-20211218150129704.png)]](https://img-blog.csdnimg.cn/b696f5094077477e8b7e552ed64ee554.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LqM5Y2B5LiA55S7QA==,size_20,color_FFFFFF,t_70,g_se,x_16)
实现推荐:
基于内容的推荐系统【Content-Based Recommendations】
注意:最早使用的推荐算法。影响深远⚠️
定义:给用户X推荐之前喜欢的物品相似的物品。即U2i2i、U2Tag2i
①物品打标签—>item矩阵
②给用户打标签【计算标签偏好】 ---->用户矩阵
③余弦相似度算法---->计算用户标签向量最相似的TopN物品列表

余弦相似度:
假设目前3个用户,一个A用户,一个B用户,一个C用户
用户向量矩阵:
| 动作片 | 科幻片 | 周星驰 | |
|---|---|---|---|
| UserA | 3 | 2 | 1 |
| UserB | 1 | 2 | 3 |
| UserC | 10 | 0 | 0 |
物品向量矩阵:
| 动作片 | 科幻片 | 周星驰 | |
|---|---|---|---|
| 无间道 | 0 | 0 | 0 |
| 大话西游之月光宝盒 | 0 | 0 | 1 |
| 复仇者联盟 | 1 | 1 | 0 |
示例计算:
这里就举例计算用户A可能对复仇者联盟的喜欢程度吧:
P = (3 x 1 + 2 x 1 + 1 x 0) /( (3x3 + 2x2 + 1x1)^0.5 x (1x1 + 1x1 + 0x0)^0.5)
= 5 / (14^0.5 x 2^0.5)
=5 /(3.74 x 1.41)
=5/5.28
=0.94
越接近1那么越需要推荐。
再计算一个用户C可能对大话西游的喜欢程度吧:
P = (10 x 0 + 0 x 0 + 1 x 0) /( (10x10 + 0x0 + 0x0)^0.5 x (0x0 + 0x0 + 1x1)^0.5)
= 0 / (14^0.5 x 2^0.5)
=0
这肯定是不推荐的。完全不喜欢。
余弦相似度算法图:

分析:
- 优点:
- 只需要该用户和当前视频标签即可
- 可以不分热门或者冷门实现推荐
- 容易满足用户口味
- 简单的解释逻辑,就是用户喜欢的就推送,不喜欢的或者喜欢概率低的就不推送
- 缺点:
- 对于打标签过程比较复杂,很难实现精准标签,有时需要人工打标签
- 无法对新用户做推荐,因为新用户没有历史行为
- 无法挖掘用户潜在兴趣,只能基于当前兴趣推荐
实现协同过滤的推荐系统
–使用行为数据,利用集体智慧推荐
- 基于数据统计【记录】的CF
- 基于模型【参数学习】的CF
协同过滤分为两种:
- 基于用户的协同过滤【U2U2I】先找相似的用户,然后观看相似用户推荐的视频
- 基于物品的协同过滤【U2I2I】先找相似的视频,然后观看相似视频的其他视频
基于用户的协同过滤:
- 搜索最相似的用户
- 计算u和新item的相似度
- 排序推荐
下面分开叙述:
前提:设有一用户和物品的向量矩阵:
| i1 | i2 | i3 | i4 | i5 | i6 | i7 | |
|---|---|---|---|---|---|---|---|
| A | 4 | 5 | 1 | ||||
| B | 5 | 5 | 4 | ||||
| C | 2 | 4 | 5 | ||||
| D | 3 | 3 |
-
搜索最相似的用户
- Jacarrd相似度
- 余弦相似度
- 皮尔逊相关系数
【Jacarrd相似度】
比较简单,是使用用户对物品之前的关注与否来判断两个用户是否相似。
分子:用户之间对于喜爱物品的交集个数
分母:用户之间对于喜爱物品的并集个数
缺点:没有考虑到用户物品的喜爱程度

【余弦相似度】
和上文类似,这里就不做叙述了
缺点:计算过程中,对于用户没有关注或者没有浏览点击的物品直接喜爱程度记为0,这是不合适的。因为不够客观。容易造成相似度计算差距不明显。

【皮尔逊相关系数】
为了弥补余弦相似度的不足,对于用户没打分的物品,使用当前用户的对其他物品打分的均值。
比如用户A对i2没有评分,这里就设置平均值,(4+5+1) = 5分,这里就默认用户A对i2也是5分
计算好之后,再运用余弦相似度计算

- 计算u和新item的相似度

需要使用第一步的结果。第一步可以得出每个用户和其他用户的相似度。
- 直接平均法
- 加权平均
【直接平均法】
已知用户A和用户B相似,用户A对i2没有喜爱程度【注意:上面皮尔逊系数是计算余弦相似度临时计算出的,只为为了防止不客观的用户喜爱得分,而不是真实意义上的用户对i2的喜爱程度】
但是用户B以及其他用户喜欢i2,那么推荐给用户A的权重就是:其他相似用户的得分的平均数:【假设其他相似用户是BC】

【加权平均】
那么推荐给用户A的权重就是:其他相似用户的相似度作为权重 x 其他用户得分累计作为分子,其他用户相似度之和作为分母。

-
排序推荐
求出用户A对每一个物品的喜爱程度,按照喜爱程度排序推荐接即可