什么是元数据锁?
英文名叫Metadata Lock,缩写为MDL,顾名思义,它是针对元数据的一种锁,锁的是元数据。
那什么是元数据?
一张表有100条记录,这里的记录我们可以称之为表数据,一张表的名字叫t1,有c1、c2两个字段,c1的类型是int,c2的类型是varchar,这里的表名、字段名、字段类型叫做表的元数据,当我们修改某行记录时,叫做修改表数据,当我们修改表名或字段类型时,叫做修改表的元数据。
什么情况要锁元数据呢?
很简单,用到元数据的时候就要锁,那什么时候用到元数据呢?注意,表名也是一个表的元数据,因此,只要是针对表的操作,都需要用到对应表的元数据,都需要给该表加元数据锁。
啊?任何对表的操作都要加元数据锁吗?就连最普通的select查询也要吗?
要,或者说MySQL就是这么做的,不过,大家还记得大明湖畔的读写锁吗,或者说InnoDB中的共享锁和排他锁。
元数据锁也分为共享锁和排他锁,额外说一句,元数据锁是属于MySQL级别的,而行锁、间隙锁这些是属于InnoDB级别的,因此元数据锁的级别更高,一条SQL执行时,都会先在MySQL层加元数据锁,加成功了之后才加InnoDB中的锁。
既然是元数据锁,读元数据是最基本的需求,在这个基础上,再来根据其他需求划分不同的类型。
如果只需要读元数据,不需要修改元数据,不需要读表数据,不需要修改表数据,那就加MDL_SHARED类型的元数据锁,比如CREATE TABLE t2 LIKE t1语句就属于这种情况,只需要读取t1表的元数据。
如果需要读元数据,不需要修改元数据,但需要读表数据,不需要修改表数据,那就加MDL_SHARED_READ类型的锁,比如大家关心的普通select查询就属于这种情况,既不需要修改元数据,也不需要修改表数据,只需要读数据。
如果需要读元数据,不需要修改元数据,但需要读表数据,并需要修改表数据,那就加MDL_SHARED_WRITE类型的锁,比如大家熟悉的insert、update、delete就属于这种情况,不需要修改元数据,但需要修改表数据。
如果既需要修改元数据,又需要修改表数据,那就加MDL_EXCLUSIVE类型的锁,比如某些执行DDL语句就属于这种情况,比如加字段、修改字段类型,这些操作不仅需要修改元数据,还可能需要修改表数据,比如给表新增字段时,如果指定了字段默认值,那么就需要修改所有记录,大家可以了解一下数据行格式,从而可以了解到更多DDL时需要修改记录的情况(关注我,我后面会分析,公众号:IT周瑜)。
因此,大多数执行SQL的时候,都需要加元数据锁,只不过可能类型不一样而已。
那一个连接(注意,我用的是连接,而不是事务,因为事务是InnoDB中的概念,元数据锁是属于MySQL层的概念,当然,为了方便理解,可以把连接和事务划上等号),那一个连接给某张表加了某种元数据锁,其他连接还能操作这张表吗?
这就得看各个连接分别加的什么类型的元数据锁了,实际上,不管是MySQL中的元数据锁,还是InnoDB中的行锁、意向锁都有一个概念,叫做锁兼容。(行锁和意向锁,我已经研究清楚了,关注我,我后面也会分析,公众号:IT周瑜)
什么是锁兼容?
如果连接1加了A锁,连接2现在想要加B锁,如果A锁和B锁是兼容的,那么连接2就能成功加到B锁,如果是不兼容的,那么连接2就需要等待连接1释放A锁。
那以上几种类型的元数据锁兼容性是怎样的呢?
|
| MDL_SHARED | MDL_SHARED_READ | MDL_SHARED_WRITE | MDL_EXCLUSIVE |
| — | — | — | — | — |
| MDL_SHARED | + | + | + | - |
| MDL_SHARED_READ | + | + | + | - |
| MDL_SHARED_WRITE | + | + | + | - |
| MDL_EXCLUSIVE | - | - | - | - |
+号表示兼容,-号表示不兼容
如何理解呢?
假如一个连接给t表加了MDL_SHARED锁,另一个连接也想加MDL_SHARED锁,当然没问题了,大家都只是想读元数据锁而已,并不冲突。
假如一个连接给t表加了MDL_SHARED锁,但是另一个连接想加MDL_EXCLUSIVE锁,那肯定不行了,我现在要读元数据,而你却想要修改元数据,会影响到我,会冲突,所以另一个连接只能等待,同时也表示MDL_SHARED锁和MDL_EXCLUSIVE锁是不兼容的,实际上MDL_EXCLUSIVE锁和谁都不兼容,因为它想修改元数据。
那如何理解MDL_SHARED和MDL_SHARED_READ、MDL_SHARED_WRITE都兼容呢,实际上MDL_SHARED_READ和MDL_SHARED_WRITE相当于是MDL_SHARED的子类,是MySQL做的更进一步区分,select读操作加的是MDL_SHARED_READ锁,update等写操作加的是MDL_SHARED_WRITE锁,但它们都只是需要读取元数据,不需要修改元数据,因此也是兼容的,也就是说当一个连接在执行select,另一个连接在执行update,还来一个连接也执行select,至少在元数据锁层面是不冲突的,是可以放行的,是可以加元数据锁成功的,至于在InnoDB层面会不会冲突,那就不是元数据锁该管的了,元数据锁只管元数据,不管表数据。
那MDL_SHARED_READ锁和MDL_SHARED_WRITE锁没啥用呗?
也不是,至少我们可以通过查看元数据锁的情况,知道当前各个连接分别加了什么类型的元数据锁,并且知道锁是不是阻塞了,从而知道锁冲突的情况,根据锁类型知道是什么样的SQL阻塞了。
如何查看元数据锁的阻塞情况?
元数据锁可以查看?可以,我给你看看。
首先执行:
UPDATE performance_schema.setup_instruments
SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME = 'wait/lock/metadata/sql/mdl';
然后开启事务一,并执行简单的查询,但是事务先不提交:
begin;
select * from user_info;
然后开启事务二,并执行一个DDL语句:
begin;
alter table user_info drop column phone;
你会发现,DDL语句执行时会转圈圈,也就是会阻塞住。
然后执行以下SQL查看元数据锁的情况:
SELECT * FROM performance_schema.metadata_locks;
结果为:

先看OWNER_THREAD_ID字段,该字段表示持有元数据锁的线程,发现只有两个线程61和67。
再看OBJECT_NAME字段,该字段表示元数据锁锁的对象,比如61和67两个线程都锁了user_info这张表。
再看LOCK_TYPE字段,该字段表示元数据锁的类型,仔细看看就能发现:
- 61线程针对user_info表加了SHARED_READ类型的锁
- 67线程针对user_info表加了EXCLUSIVE和SHARED_UPGRADABLE类型的锁(SHARED_UPGRADABLE不用管)
再看LOCK_STATUS字段,该字段表示锁当前的状态,仔细看看就能发现:
- 61线程,状态是GRANTED,表示成功加到了SHARED_READ类型的元数据锁
- 67线程,虽然SHARED_UPGRADABLE类型的锁加成功了,但是EXCLUSIVE类型的锁是PENDING状态,表示EXCLUSIVE类型的元数锁没有加成功,在等待,等待什么呢?自然就是等待61线程释放掉SHARED_READ类型的元数据锁,因为EXCLUSIVE和SHARED_READ是不兼容的,所以67线程需要等待
那61线程什么时候释放SHARED_READ元数据锁呢?很简单,当事务提交或回滚就会释放了。
能否先总结一下元数据锁的作用?
可以,一般的select查询和DML操作只需要读取元数据,而DDL操作则需要修改元数据,所以元数据锁更多是用来保证DML和DDL、DDL和DDL之间的并发安全性,DML和DML之间的并发安全由InnoDB中的锁来解决。
那传说中的Online DDL是不是跟这个元数据锁有关系?
必须有关系,而且有很大的关系,要理解Online DDL就得理解DDL的底层执行过程,在MySQL5.7中有两种DDL算法,一种是COPY,一种是INPLACE,MySQL8.0中新增了一种INSTANT算法(本文不介绍),在执行DDL语句时,MySQL会自动判断应该用哪种算法,当然你可以手动指定(后面会看到如何指定),但并不是你指定了INPLACE算法,MySQL就一定会用,如果当前DDL操作不支持INPLACE算法,MySQL会给出提示,让你用COPY算法。
COPY算法DDL的底层执行流程
比如,给t1表新增一个字段,如果选择的是COPY算法,那么大概流程是这样的:
- 在磁盘生成一张临时表,临时表的表名是MySQL自动生成的,临时表的字段是t1表+新字段
- 然后将t1表的数据复制到临时表中,我通过源码debug发现,这个过程是从通过调用InnoDB的查询接口每次查询一行,然后再调用InnoDB的插入数据接口,将数据插入到临时表中,从而完成数据的复制,就是这么一行一行进行复制的,所以效率很低
- 数据复制完之后,删除t1表,并将临时表重命名为t1
可以发现,COPY算法的核心是第二步,最耗时的也是第二步,COPY算法完全是属于MySQL层的,它只是调用了InnoDB提供的查询和插入数据的接口。
COPY算法执行过程中会出现如下情况:
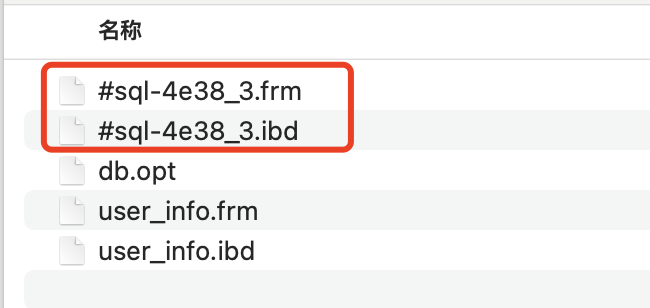
其中两个奇怪名字的文件就是临时表相关的文件,frm表示表定义文件,ibd表示表数据文件,奇怪的名字就是临时表名。
INPLACE算法DDL的底层执行流程
而INPLACE算法,表示“就地”修改,“就地”的意思是直接在InnoDB内部进行修改,你可以认为,如果能采用INPLACE算法进行DDL(注意,我说的是能,并不是所有的DDL都能采用INPLACE算法),那么MySQL层需要做的事情就比较少了,核心步骤都交给InnoDB了,而InnoDB中也分为了三个步骤,源码函数分别为:
- ha_innobase::prepare_inplace_alter_table()
- ha_innobase::inplace_alter_table()
- ha_innobase::commit_inplace_alter_table()
那采用INPLACE算法,还要不要复制表的数据呢,仍然需要,只不过是InnoDB来实现了,比如执行过程中会出现如下情况:
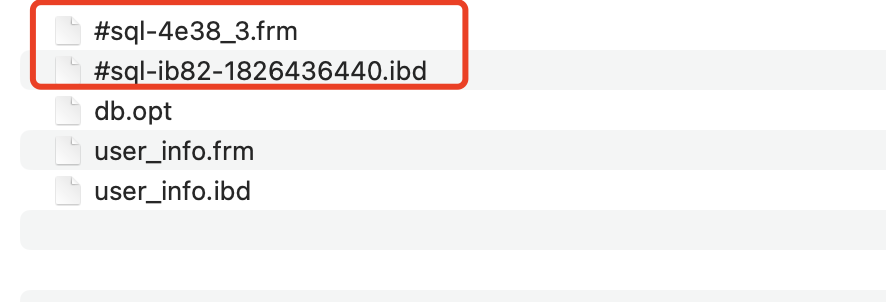
也会生成临时文件,只不过是InnoDB生成的,当然,frm文件是MySQL层生成,而另外一个ibd文件则是InnoDB生成的,我还发现,如果采用INPLACE算法,是不会像COPY算法那样每次从原始表查一行数据,然后插一行数据到临时表的,至于InnoDb是怎么将原始表数据复制到临时表的,肯定采用了效率更高的方式,只不过我还没研究清楚,这里就先不介绍了。
不过可以肯定的是,采用INPLACE算法效率会更高,一方面由InnoDB自身复制数据肯定比COPY算法那样由MySQL层调用InnoDB查询和插入数据的接口来复制数据效率要高,另外一方面就是元数据锁的使用了。
我相信大家都听过这样的结论:如果采用COPY算法,DDL在复制数据的过程中,DML操作是会被阻塞的,而如果采用INPLACE算法,DDL在复制数据的过程中,DML操作是不会阻塞的,这也是为什么叫做Online DDL,表示DDL的过程中,可以在线同时执行DML操作。
真的是这样吗?我们来测测。
COPY算法会阻塞select吗?
我做了一个实验,表结构是这样的:
CREATE TABLE `user_info` (`id` int,`name` varchar(255),`phone` varchar(45) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
用存储过程模拟插入数据:
CREATE DEFINER=`root`@`%` PROCEDURE `InsertUserInfo`(IN num_records INT)
BEGINDECLARE i INT DEFAULT 1;DECLARE phone_prefix CHAR(3) DEFAULT '123';DECLARE phone_suffix CHAR(8) DEFAULT '';DECLARE name VARCHAR(255);WHILE i <= num_records DOSET phone_suffix = LPAD(i, 8, '0');SET name = CONCAT('User_', i);INSERT INTO user_info (id, name, phone)VALUES (i, name, CONCAT(phone_prefix, phone_suffix));SET i = i + 1;END WHILE;
END
调用存储过程:
call my_db.InsertUserInfo(1000000);
打开三个连接:
- 连接1用来开启事务执行select语句
- 连接2用来进行DDL
- 连接3用来查看元数据情况
先用连接2进行DDL操作,删除表中的phone字段,先测试COPY算法:
alter table user_info drop column phone, ALGORITHM=COPY, LOCK=SHARED;
注意,使用COPY算法时,LOCK只能是SHARED,不能是NONE,不然MySQL会提示你要用SHARED。
然后用连接3查看元数据锁情况,没有PENDDING,因为现在只有连接2,线程id为78,在使用user_info表:

然后用连接1开启事务并执行查询:
begin;
select * from user_info;
注意,是能查出结果的!是能查出结果的!是能查出结果的!
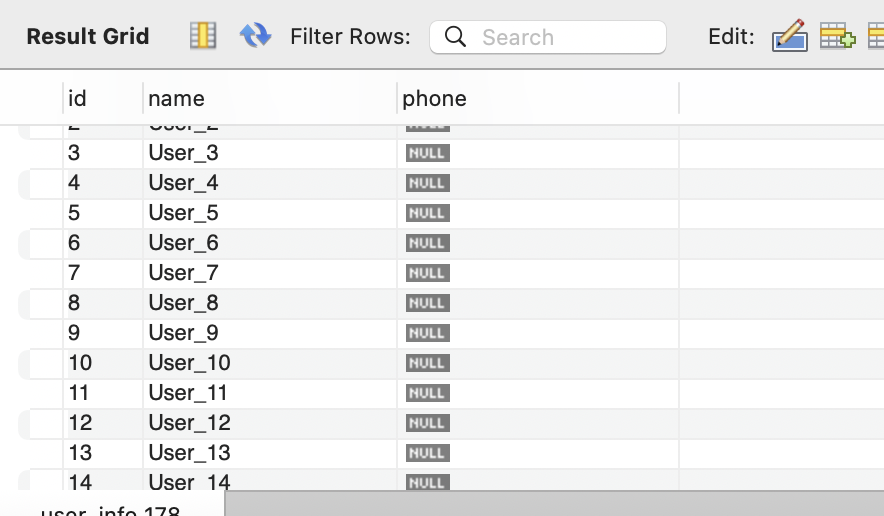
但是!等了很久之后,它始终能查出phone字段,难道DDL操作一直没执行完(DDL操作是在删除phone字段)?
并不是,我们用连接3查看元数据锁,发现78线程对user_info多加了一把元数据锁,而且是EXCLUSIVE类型的,而且是PENDDING的:

78线程就是DDL操作的线程,也就代表DDL线程被阻塞了,为什么会被阻塞呢?
因为连接1的事务在执行select的时候,给user_info加了一把SHARED_READ的元数据锁,但是事务一直没有提交,SHARED_READ元数据锁一直没有释放,而连接2的DDL操作在数据复制完了之后需要修改元数据,因此需要给user_info加EXCLUSIVE类型的元数据锁,这个时候就阻塞了,从而导致DDL操作一直没有完成,从而导致连接1的select的查询结果一直没有发生变化,此时我们也可以看一下文件的情况:
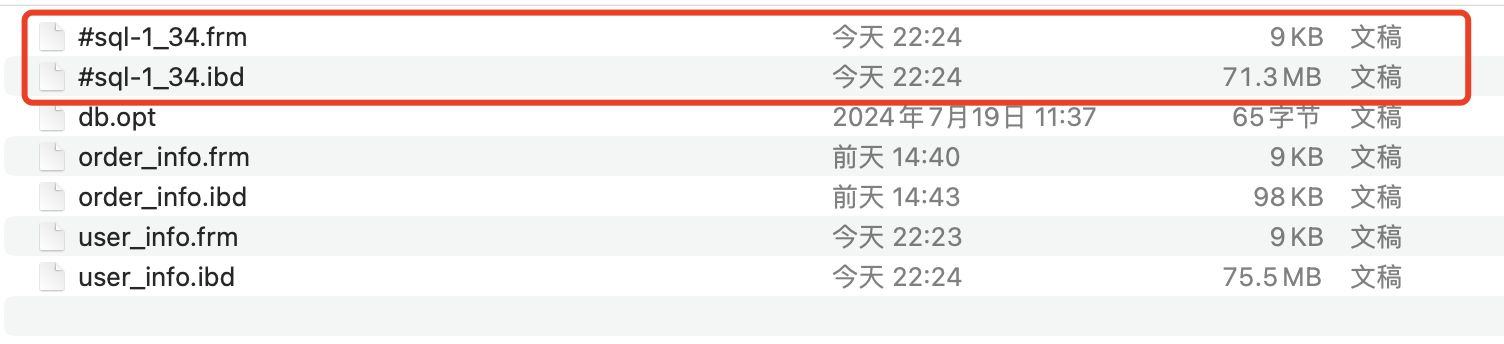
发现临时文件确实已经创建,并且数据也确实已经复制完成了,注意临时ibd文件的大小。
因此,现在只要连接1提交事务,整个过程就不会阻塞了,连接1提交之后,连接2的DDL操作才会真正结束,此后连接1再查询数据时,才不会查找phone字段。
因此,可以得出结论,COPY算法的DDL在数据复制过程中,并不会阻塞查询操作,但是由于最后阶段会加EXCLUSIVE类型的元数据锁,从而导致DDL操作可能会阻塞(比如连接1的事务一直不提交),一直完成不了。
因此如果有长事务,尽管是查询操作,也可能会导致DDL操作阻塞,所以要尽量避免长事务。
也就是说,select如果一直不提交,会阻塞DDL,反过来,DDL操作复制数据之后都会需要修改元数据,需要加EXCLUSIVE类型的元数据锁,也可能会阻塞select操作,因此我们只能说,DDL操作的数据复制过程中不会阻塞select,不能说DDL整个操作不会阻塞select。
INPLACE算法会阻塞select吗?
再来看看INPLACE算法,首先,INPLACE算法的执行速度要快很多,在不产生锁冲突的情况下,COPY算法删除字段:
alter table user_info drop column phone, ALGORITHM=COPY, LOCK=SHARED;
需要执行17秒左右。
而INPLACE算法:
alter table user_info drop column phone, ALGORITHM=INPLACE, LOCK=NONE;
只需要执行3秒左右。
这效率不是一般的高。
经过上面同样的测试步骤,发现INPLACE算法DDL在复制数据过程中,也不会阻塞select查询,但是在数据复制完之后,也会加EXCLUSIVE类型的锁,按上面同样的步骤,也会出现同样的元数据锁情况:

而文件的情况也类似:
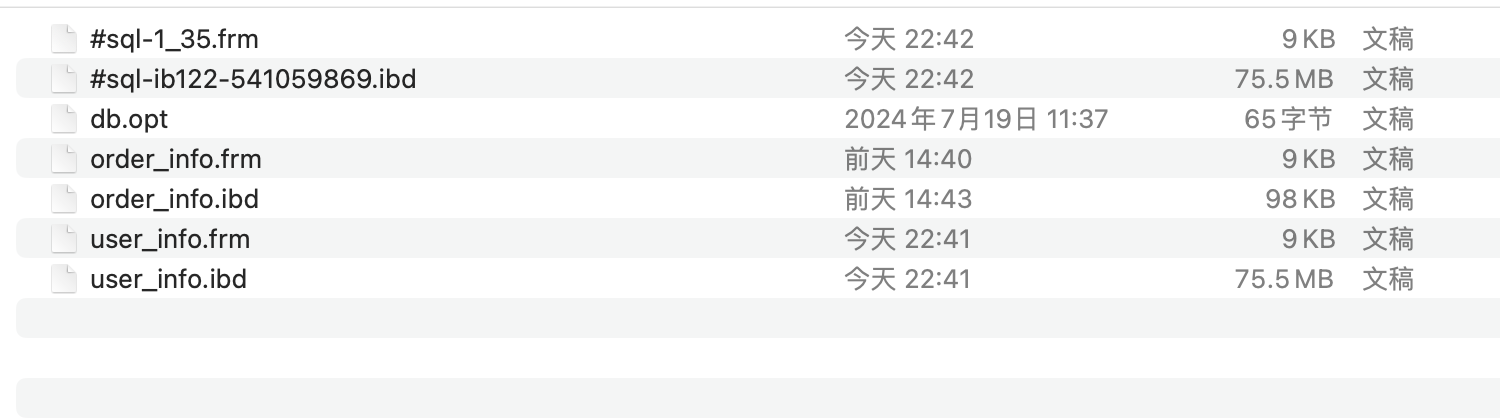
也是数据复制完了,但临时文件一直在,就是因为DDL操作最后被阻塞了,和COPY算法类似,只有连接1提交事务,整个DDL过程才会结束。
从这个测试看,COPY算法和INPLACE算法,只有效率上的不同,在数据复制过程中都可以查询数据,但是查询事务如果一直不提交,则会阻塞DDL操作,因为DDL操作的最后需要修改元数据,会给表加EXCLUSIVE类型的锁,从而和查询事务的SHARED_READ类型的锁冲突,导致DDL操作阻塞。
注意,我说的是数据复制过程中不会阻塞select查询,数据复制的前面步骤和后面步骤其实都会给表加EXCLUSIVE类型的锁(时间比较短),从而可能导致短暂的阻塞select查询
那假如是不是查询语句呢,而是insert、update、delete这些DML语句呢?
COPY算法会阻塞DML操作吗?为什么?
先测试COPY算法的DDL操作,先利用连接2执行:
alter table user_info drop column phone, ALGORITHM=COPY, LOCK=SHARED;
这个语句,需要执行一段时间(表里的数据增加到了200万),在这个过程中,用连接1执行:
begin;
insert into user_info values(3000001, 'zhangfei');
发现insert语句会直接阻塞。
连接3查看元数据锁的情况:
SELECT * FROM performance_schema.metadata_locks;

79线程是DDL线程,81线程是insert语句的线程,加的是SHARED_WRITE类型的锁,状态是PENDING,因此insert语句阻塞了,因此看出,在使用COPY算法执行DDL过程中,就算是数据复制过程中,其他连接都不能执行insert语句,同样,我也测了update和delete,和insert语句一样,都是加的SHARED_WRITE类型的锁,所以都会阻塞,因此COPY算法的DDL,不仅数据复制慢,而且过程中还导致其他事务不能执行DML操作,只能执行select。
INPLACE算法会阻塞DML操作吗?为什么?
采用同样的流程,来测试INPLACE算法。
先用连接2执行INPLACE算法的DDL操作:
alter table user_info drop column phone, ALGORITHM=INPLACE, LOCK=NONE;
然后用连接1执行insert、update、delete操作:
begin;
update user_info set name = '111' where id = 1;
insert into user_info values(3000011, 'zhangfei', '123');
delete from user_info where id = 1;
会发现和COPY算法确实不一样,此时连接1是能执行这些DML操作的,这就是Online的意思,如果使用INPLACE算法进行DDL,那么在数据复制过程中,其他连接可以同时进行DML操作。
但是和select查询一样,如果DML操作的事务一直不提交,那么DDL操作也一直无法完成,因为DDL操作在数据复制完了之后,需要修改元数据,从而会加EXCLUSIVE类型的元数据锁,而其他连接,不管是执行select读操作,还是执行insert、update、delete这些写操作,都会加SHARED_READ或SHARED_WRITE类的元数据锁,而事务一直不提交,那么锁就一直不释放,从而导致DDL操作在执行完数据复制操作之后,EXCLUSIVE类型的锁加不成功,导致DDL操作完成不了。
COPY算法和INPLACE算法有什么相同点和不同点?
最后,再总结一遍:
- 对于COPY算法和INPLACE算法的DDL操作,如果另外一个连接执行的是select查询,那么两种算法除开数据复制效率的差别之外,没有其他差别,都能查到数据。
- 对于COPY算法的DDL操作,如果另外一个连接执行的是insert、update、delete等写操作,则这些写操作会阻塞,直到DDL操作完成
- 对于INPLACE算法的DDL操作,如果另外一个连接执行的insert、update、delete等写操作,这些写操作不会阻塞
长事务和Online DDL会产生什么影响?
不管是COPY算法还是INPLACE算法,只要DDL操作复制数据结束之后,DDL操作都需要修改元数据,从而都需要给元数据加EXCLUSIVE类型的锁,因此其他连接如果一直不提交事务,就会导致DDL操作一直获取不到EXCLUSIVE类型元数据锁,也就会导致DDL操作一直完成不了,因此大家在进行DDL操作时,就算是用INPLACE算法,最好也在业务低峰期,这样DDL操作能尽快完成。
Online DDL什么情况下会导致锁表?
特别要注意,当DDL操作给表加了EXCLUSIVE类型的元数据锁之后,假如来了一个新连接4,它执行最简单的select查询都是执行不了的,因为它需要加SHARED_READ类型的元数据锁,SHARED_READ和EXCLUSIVE类型的元数据锁是冲突的。
也就是可能会出现以下“锁表”的情况:
- 连接2先执行DDL操作(不管是COPY还是INPLACE算法)
- 连接1在DDL操作过程中执行了select、insert、update、delete等操作,但一直不提交,一直占用着SHARED_READ或SHARED_WRITE类型的锁
- 连接2的DDL操作数据复制执行完了,需要加EXCLUSIVE类型的锁,但是只能阻塞
- 连接3来执行select、insert、update、delete等操作,需要加SHARED_READ或SHARED_WRITE类型的锁,此时就会阻塞,导致SQL执行不了,转圈圈
这种情况就比较严重了,因此一定要尽快让连接1的事务提交,不然就会一直卡着,整个表都无法处理请求,看上去就是“锁表”了。
总结
最后,再总结一下,凡事要用到表的时候,就会给表加元数据锁,只不过不同操作加的不同类型的元数据锁,不同类型的元数据锁之间可能兼容,可能冲突。
比如select、insert、update、delete这些操作,只需要读表的元数据,因此会给表加SHARED类型的元数据锁,而很多DDL操作需要修改表的元数据,比如添加字段,因此需要加EXCLUSIVE类型的锁,EXCLUSIVE和SHARED是不兼容的,所以可能存在,DML和DML之间的元数据锁不会冲突,但是DML和DDL,DDL和DDL之间的元数据锁会产生冲突。
而DML和DDL之间,就是通常说的Online DDL,表示DDL的数据复制期间,其他事务可以正常执行DML,但是数据复制完了之后仍然会跟DML产生冲突。
因此,系统中一定尽量避免比较长事务,比如慢查询,如果在DDL期间遇到了慢查询,那么DDL整个操作就得等待慢查询执行结束才会完成,而如果DDL操作一直不结束,就相当于一直给表加了EXCLUSIVE类型的锁,导致“锁表”,一旦“锁表”,其他新事务针对这个表的任何SQL都无法执行了(我测了select * 和 select count(*)都不能执行,大家可以再试试别的)。
好啦,MySQL是真难啊,希望我分析清楚了,觉得文章还可以,就帮忙点赞、分享、收藏一下,感谢!
关注我,我是大都督周瑜,公众号:IT周瑜,持续分享市面上没有的技术干货。