可观测性是指收集信息(跟踪、日志、指标),以提高性能、可靠性和可用性为目标。很少有人能确定其中一个事件的根本原因。通常情况下,当我们将这些信息关联起来形成叙述时,我们就会有更好的理解。从一开始,MinIO 不仅将精力集中在性能和可扩展性上,还专注于可观察性。MinIO 有一个内置的端点 /minio/v2/metrics/cluster,Prometheus 可以从中抓取和收集指标。您还可以将事件发布到 Kafka,并触发警报和其他进程来运行,这些进程依赖于 MinIO 中执行的操作。在上一篇博客中,我们在一个非常高的层面上讨论了可观察性:在介绍层面上的一万英尺视图。在这篇文章中,我们将更深入地探讨可观测性的每个不同功能,并了解如何使用它们来使生产级监控准备好开箱即用。
概述
查看集群的整体状态,包括已用磁盘总数、纠删码设置和驱动器设置等。

数据
向下钻取到特定的磁盘池,查看可能正在修复的驱动器。
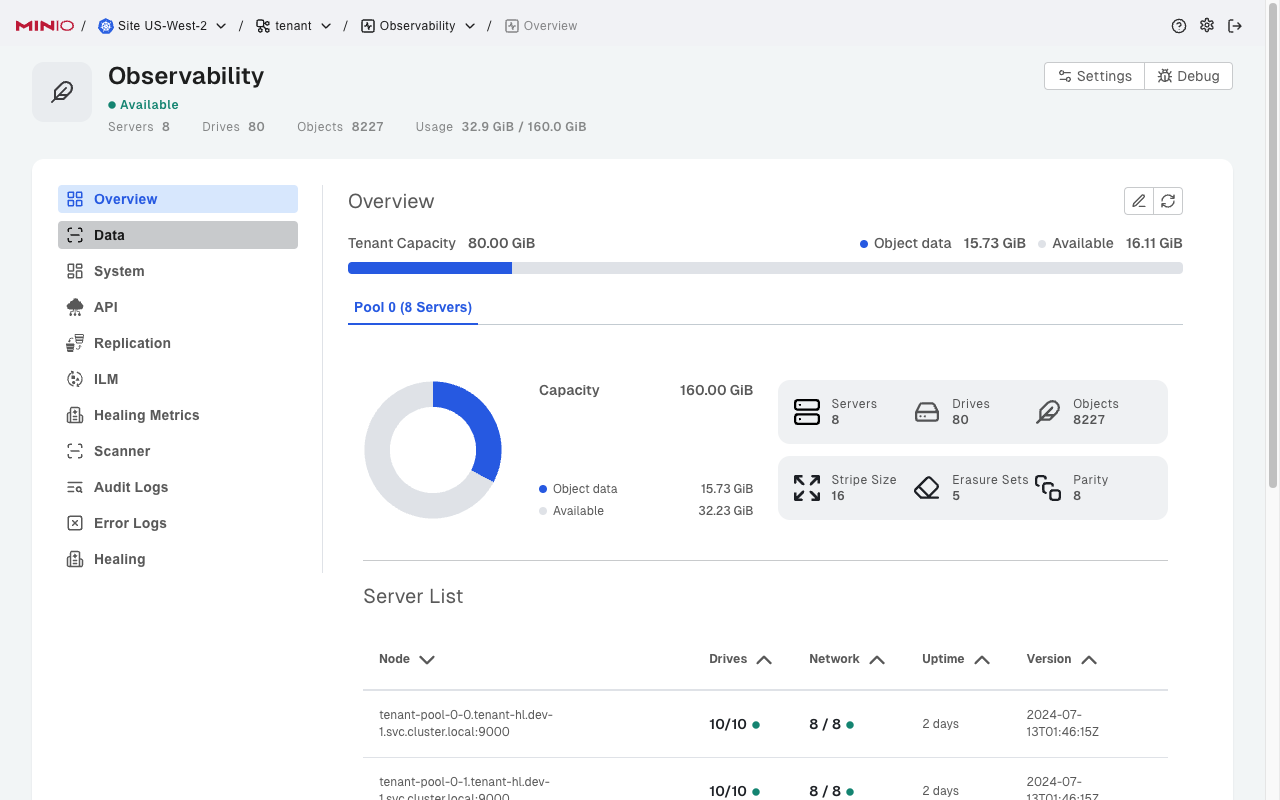
系统
CPU、内存、磁盘和网络的总体集群指标。
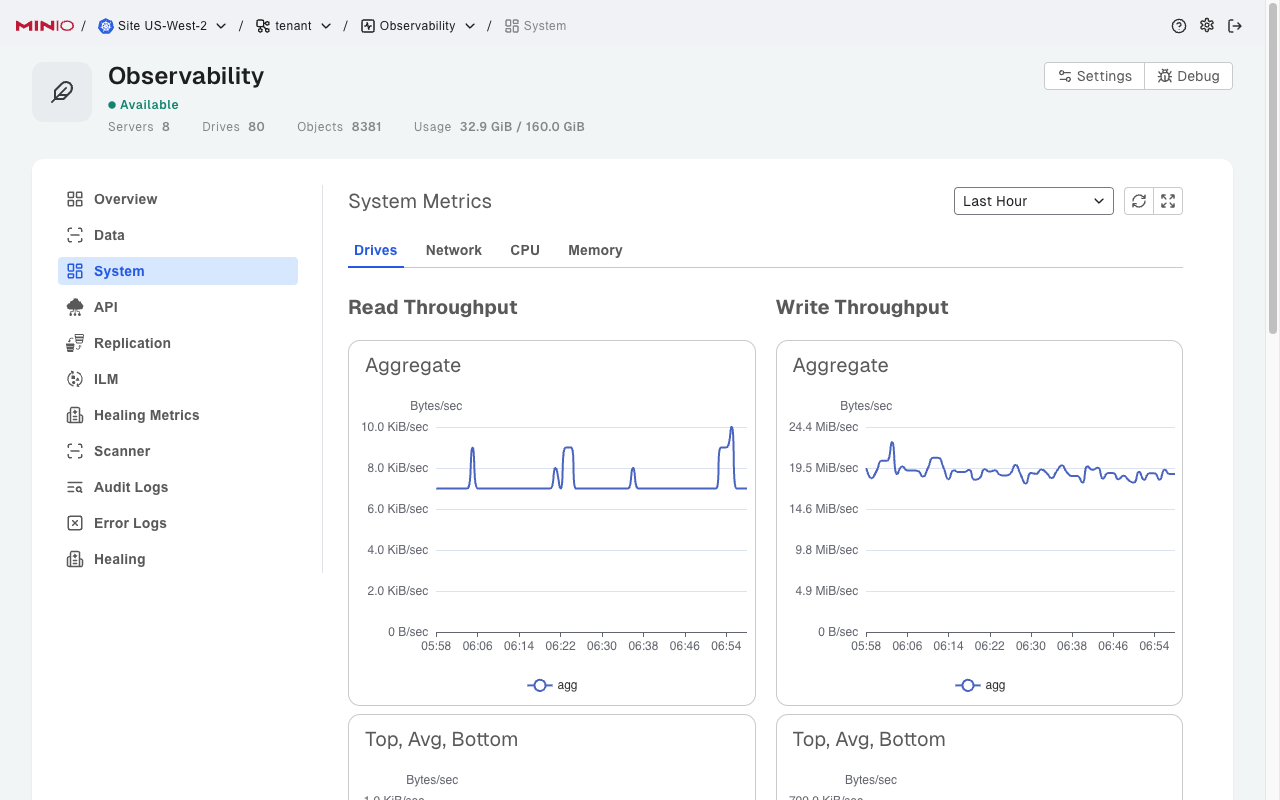
API 应用程序接口
有大量的 S3 调用针对集群。谨慎的做法是监视这些内容,以确保没有故障或延迟。这可能意味着在某个地方会出现更大的问题。
复制
启用复制后,可以跟踪所有与复制相关的状态,例如剩余要复制的对象和复制速度等。
ILM
过去,我们讨论过 MinIO 可用于使用集成生命周期管理 (ILM) 的不同层,现在您可以详细监控其进度。
治愈指标
如果任何磁盘出现故障或数据损坏,MinIO 会自动启动修复过程。这可以进行详细监控。
扫描器
当扫描对象进行各种操作时,这些指标会在此处显示。
监控是关键
可观察性是多方面的;您通常必须检查跟踪、指标和日志的组合,以确定根本原因。您可以使用混沌工程工具(例如 Gremlin、ChaosMonkey、我们自己的 MinIO Warp 等)来分解您的系统并观察指标中的模式。例如,也许您正在收集 HTTP 请求状态,通常,您一直看到 200 秒,但突然间,您看到 500 秒的峰值。你去看一下日志,你注意到最近进行了一次部署,或者一个数据库因维护而停机。或者,如果您正在监控对象存储性能指标,则可以将任何服务器端问题与此数据相关联。正是这些类型的事件往往会造成最大的痛苦,在这些情况下获得可见性至关重要。